深度学习笔记(五) 代价函数的梯度求解过程和方法
作为自己的笔记系列,方便自己查阅和理解。1)什么是梯度梯度本意是一个向量(矢量)当某一函数在某点处沿着该方向的方向导数取得该点处的最大值,即函数在该点处沿方向变化最快,变化率最大(为该梯度的模)。在二元函数的情形,设函数z=f(x,y)在平面区域D内具有一阶连续偏导数,则对于每一点P(x,y)∈D,都可以定出一个向量(δf/x)*i+(δf/y)*j
作为自己的笔记系列,方便自己查阅和理解。
(百度百科)
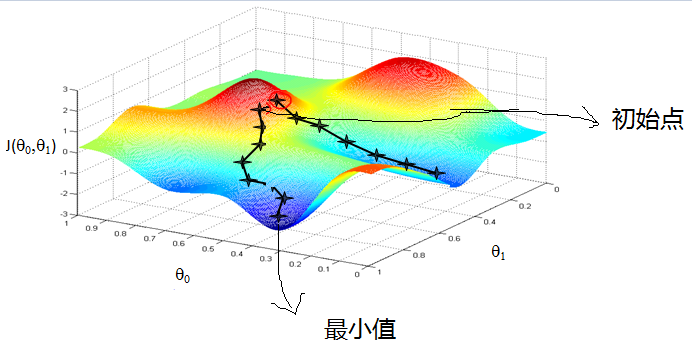
首先我们给θ一个初试值,然后向着让J(θ)变化最大的方向更新θ的取值,如此迭代。公式如下:
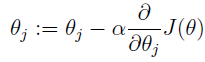
公式中α称为步长(learning rate),它控制θ每次向J(θ)变小的方向迭代时的变化幅度。J(θ)对θ的偏导表示J(θ)变化最大的方向。由于求的是极小值,因此梯度方向是偏导数的反方向。求解一下这个偏导,过程如下:
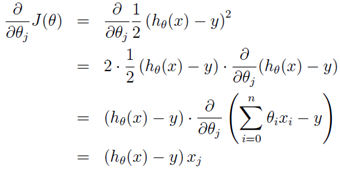
那么θ的迭代公式就变为:
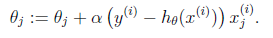
4)常用方法
这部分全部来源于:http://blog.csdn.net/qq_21460525/article/details/70146665
目标:min f(x)
核心思想:负梯度方向是使函数值下降最快的方向,在迭代的每一步根据负梯度的方向更新x的值,从而求得最小的f(x)。因此我们的目标就转变为求取f(x)的梯度。
a)全局最优梯度下降
当f(x)是凸函数的时候,用梯度下降的方法取得的最小值是全局最优解,但是在计算的时候,需要在每一步(xk处)计算梯度,它每更新一个参数都要遍历完整的训练集,其代码表示如下:
for i in range(nb_epochs):params_grad = evaluate_gradient(loss_function, data, params)params = params - learning_rate * params_grad
b)SGD随机梯度下降
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差并更新参数
for i in range(nb_epochs):np.random.shuffle(data)for example in data:params_grad = evaluate_gradient(loss_function, example, params)params = params - learning_rate * params_grad
for i in range(nb_epochs):np.random.shuffle(data)for batch in get_batches(data, batch_size=50):params_grad = evaluate_gradient(loss_function, batch, params)params = params - learning_rate * params_grad
但是,需要注意的是因为这里也存在样本选择的随机性,学习速率应该要逐渐减小,同时上述方法并不能保证好的收敛性。主要存在的挑战有:
- 选择适当的学习率可能很困难。 太小的学习率会导致收敛性缓慢,而学习速度太大可能会妨碍收敛,并导致损失函数在最小点波动。
- 使用学习率计划:尝试在训练期间调整学习率。 比如根据预先制定的规则缓慢的降低学习速率,或者当每次迭代之间的偏导差异已经低于某个阈值时,就降低学习速率。但是这里面的学习速率更新规则,以及阈值都是需要预先设定的,因此不适应于所有的数据集。
- 此外,使用梯度更新的方法会导致所有参数都用学习速率更新。但是当训练集数据是稀疏的,或者特征的频率是不同的,我们可能不希望它们更新到同样的程度,因此使用相同的学习速率会导致那些很少出现的特征有较大的变化。
- 在求取那些高度非凸的误差函数的最小值时,我们应该避免陷入局部最优解,实验表明,最困难的不是从局部最优而是鞍点,鞍点就是沿着某一个方向他是稳定的,沿着另一个方向不稳定,既不是最小点也不是最大点。这会使得该点在所有维度上梯度为0,让SGD难以逃脱。
基于上述问题,又有了如下更多的优化策略!
d) momentum
上述SGD和MBGD算法都存在样本选择的随机性,因此含有较多的噪声,而momentum能解决上述噪声问题,尤其在面对小而较多噪声的梯度时,它往往能加速学习速率。
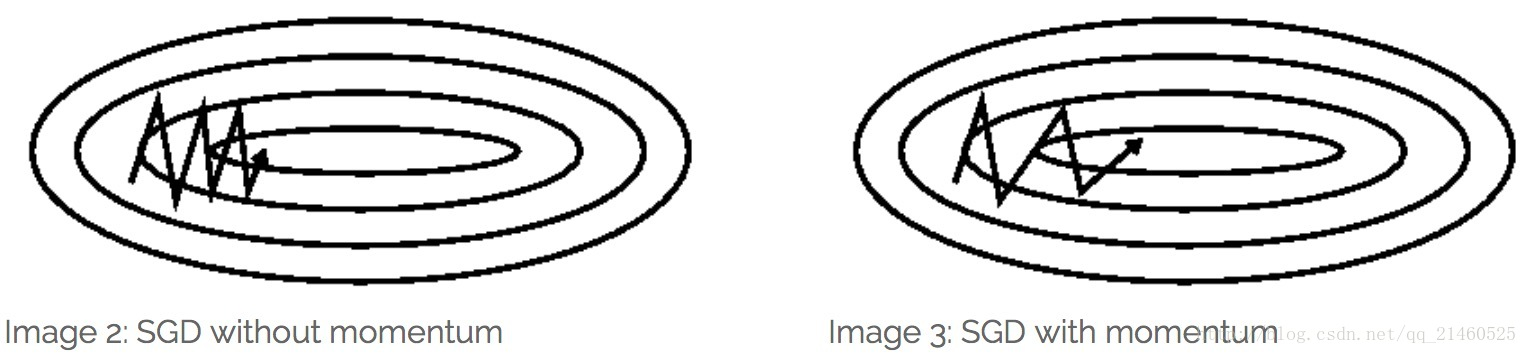
核心思想:Momentum借用了物理中的动量概念,即前几次的梯度也会参与运算。为了表示动量,引入了一个新的变量v(velocity)。v是之前的梯度的累加,但是每回合都有一定的衰减。
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,并更新速度v和参数θ:
- ĝ ←+1m∇θ∑iL(f(xi;θ),yi)
- v←αv−ϵĝ
- θ←θ+v
其中参数α表示每回合速率v的衰减程度.同时也可以推断得到,如果每次迭代得到的梯度都是g,那么最后得到的v的稳定值为 ϵ∥g∥/1−α
也就是说,Momentum最好情况下能够将学习速率加速1/1−α倍.一般α的取值为0.9或者更小。当然,也可以让α的值随着时间而变化,一开始小点,后来再加大.不过这样一来,又会引进新的参数.
特点:
本质上来说,就和我们把球从山上退下来一样,球的速度会越来越快。和我们的参数更新一样,当方向一致时,动量项会增加;当方向不一致时,动量项会降低。
即:
前后梯度方向一致时,能够加速学习
前后梯度方向不一致时,能够抑制震荡
e) Nesterov Momentum
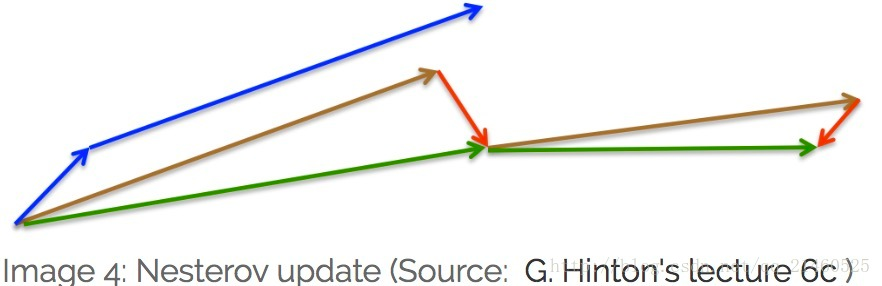
仅仅有一个追求速度的球往山下滚是不能令人满意的,我们需要一个球,它能知道往前一步的信息,并且当山坡再次变陡时他能够减速。因此,带有nesterov的出现了!
在momentum里,先计算当前的梯度(短蓝色线),然后结合以前的梯度执行更新(长蓝色线)。而在nesterov momentum里,先根据事先计算好的梯度更新(棕色),然后在预计的点处计算梯度(红色),结合两者形成真正的更新方向(绿色)。
具体实现:
需要:学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,并更新速度v和参数θ:
ĝ ←+1m∇θ∑iL(f(xi;θ+αv),yi)
v←αv−ϵĝ
θ←θ+v
注意在估算ĝ 的时候,参数变成了θ+αv而不是之前的θ
f) AdaGrad
AdaGrad可以自动变更学习速率,只是需要设定一个全局的学习速率ϵ,但是这并非是实际学习速率,实际的速率是与以往参数的模之和的开方成反比的.也许说起来有点绕口,不过用公式来表示就直白的多:
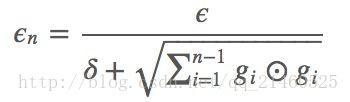
其中δ是一个很小的常亮,大概在10−7,防止出现除以0的情况.
核心思想:对于频繁出现的参数使用更小的更新速率,对于不频繁出现的参数使用更大的更新速率。
正因为如此,该优化函数脚适用于稀疏的数据,比如在Google从YouTube视频上识别猫时,该优化函数大大提升了SGD的鲁棒性。在训练GloVe词向量时该优化函数更加适用。
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量
在SGD中,我们对所有参数进行同时更新,这些参数都使用同样的学习速率。
比图用gt,i表示在t时间点,对i参数求得的偏导。
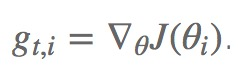
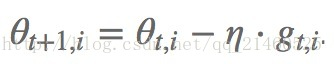
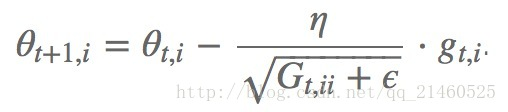
能够实现学习率的自动更改。如果这次梯度大,那么学习速率衰减的就快一些;如果这次梯度小,那么学习速率衰减的就慢一些。
缺点:
最大的缺点在于分母中那个G是偏导的累积,随着时间的推移,分母会不断的变大,最后会使得学习速率变的非常小,而此时会使得模型不再具备学习其他知识的能力。
经验表明,在普通算法中也许效果不错,但在深度学习中,深度过深时会造成训练提前结束。因为它到后面的衰减可能越来越慢,然后就提前结束了。为了解决提前结束的问题,引入了如下的算法:Adadelta!RMSprop!
Adadelta
adadelta是adagrad的延伸,不同于adadelta将以前所有的偏导都累加起来,adadelta控制了累加的范围到一定的窗口中。
但是,并非简单的将窗口大小设置并且存储,我们是通过下式动态改变的上述的G:
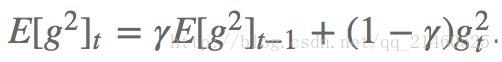
因此以前的:
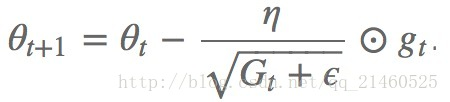
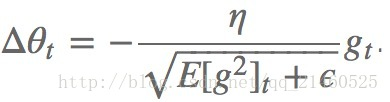
RMSprop
RMSProp通过引入一个衰减系数,让r每回合都衰减一定比例,类似于Momentum中的做法。(我觉得和Adadelta没啥区别)
具体实现:
需要:全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ,衰减速率ρ
中间变量: 梯度累计量r(初始化为0)
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r,再根据r和梯度计算参数更新量
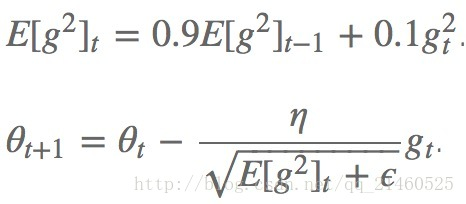
算法的提出者建议如上式所示,gamma取0.9,学习速率为0.001
优点:
相比于AdaGrad,这种方法很好的解决了深度学习中过早结束的问题
适合处理非平稳目标,对于RNN效果很好
缺点:
又引入了新的超参,衰减系数ρ
依然依赖于全局学习速率
Adam
Adam(Adaptive Moment Estimation)是另外一种给每个参数计算不同更新速率的方法,其本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。它和上述的adadelta和RMSprop一样,都存储了以前的偏导平方衰减平均值,此外,它还存储以前的偏导衰减平均值。
具体实现:
需要:步进值 ϵ, 初始参数 θ, 数值稳定量δ,一阶动量衰减系数ρ1, 二阶动量衰减系数ρ2
其中几个取值一般为:δ=10−8,ρ1=0.9,ρ2=0.999
中间变量:一阶动量s,二阶动量r,都初始化为0
每步迭代过程:
1. 从训练集中的随机抽取一批容量为m的样本{x1,…,xm},以及相关的输出yi
2. 计算梯度和误差,更新r和s,再根据r和s以及梯度计算参数更新量
其中的Mt和Vt分别表示平均值角度和非中心方差角度的偏导。
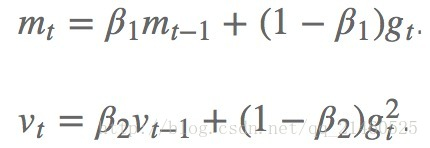
才方法的作者建议 β1取0.9, β2取0.999 ,ϵ取10-8。并且声称Adam在实践中比其他的自适应算法有更好的表现。
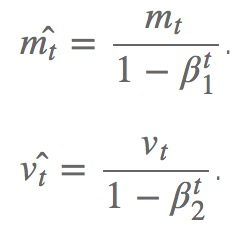
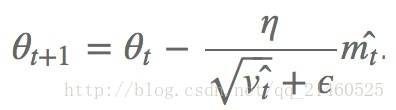
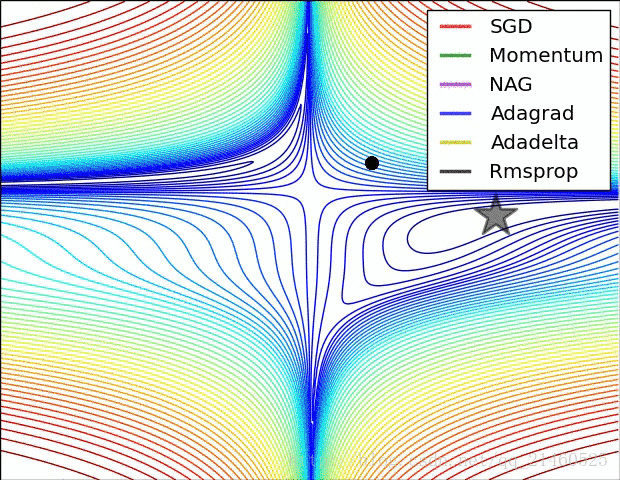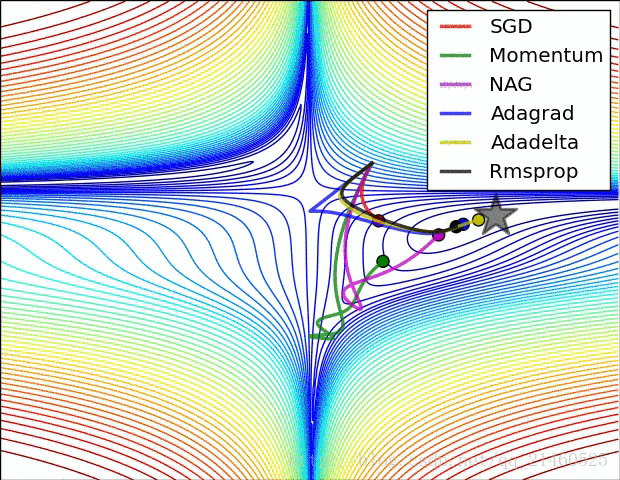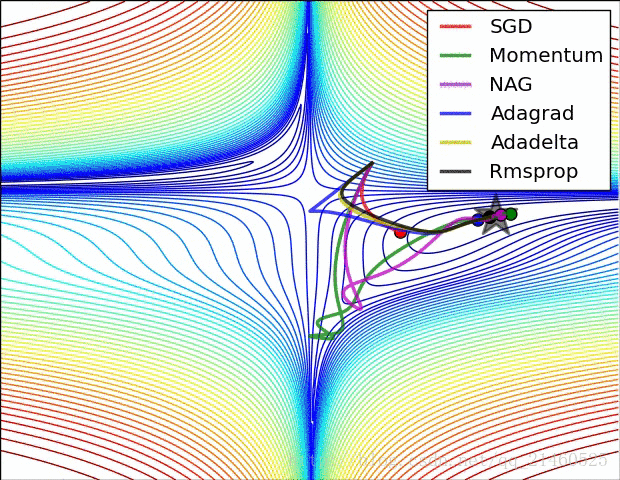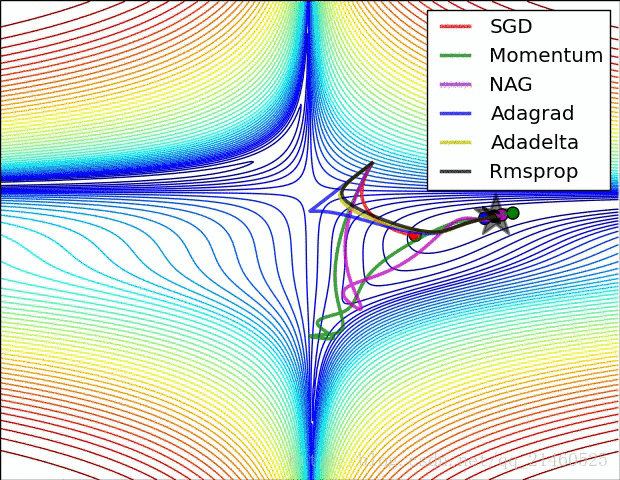
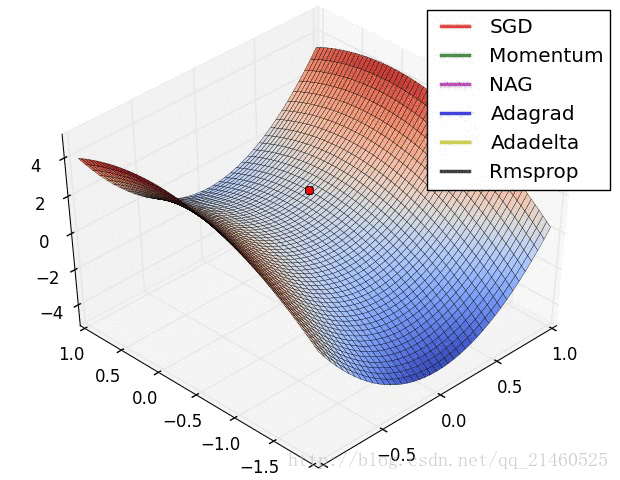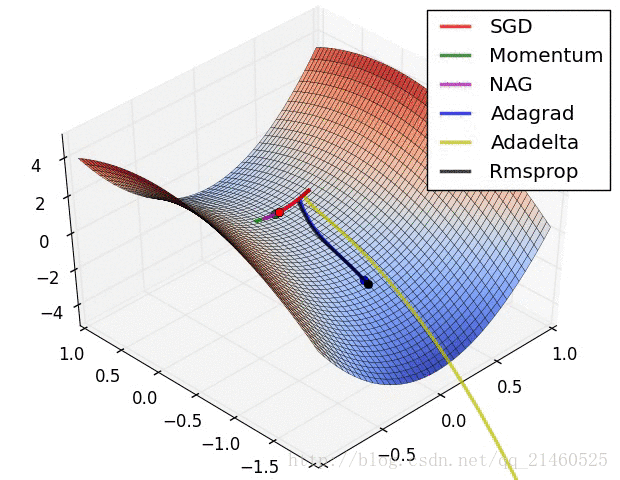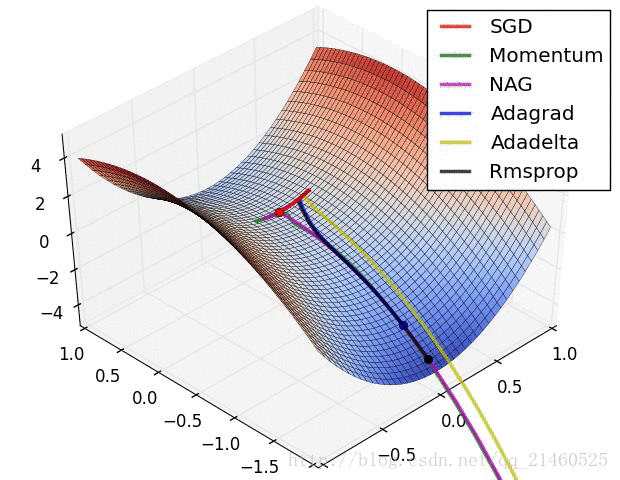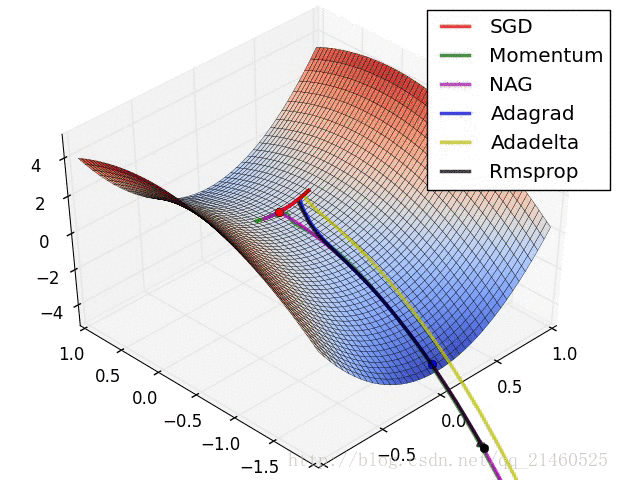
让我们来可视化的看看它们的表现:
比较一下速度:
比较一下在鞍点的性能:
三、如何选择
- 如果你的数据很稀疏,那应该选择有自适应性的优化函数。并且你还可以减少调参的时间,用默认参数取得好的结果。
- RMSprop是adagrad的一个拓展,旨在解决它提前结束的问题。
- 而RMSprop和Adadelta类似,只是adadelta采用了RMS的方法更新参数。
- 在RMSprop基础上增加了偏差校正和momentum,形成了Adam。
- 综上,RMSprop、Adadelta、Adam都是类似的。
- Kingma【Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13.】的实验表示,偏差校正使得Adam在优化到后面梯度变的稀疏的时候使得其优化性能最好。
- 所以,可能Adam是最好的优化函数。
- 所以,如果你希望你的训练能变的更快,或者你要训练的是一个复杂的深度的网络,尽量选择自适应的优化函数。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)