解决几乎任何机器学习问题(完整翻译)
解决几乎任何机器学习问题(完整翻译)英文原文:Approaching (Almost) Any Machine Learning ProblemKaggle团队| 07.21.2016Kaggle大师Abhishek Thakur最初在2016年7月18日在这里发表了这篇文章。一个数据科学家每天处理大量的数据。有人说,超过60-70%的时间花在了数据清理,数据转移和
解决几乎任何机器学习问题(完整翻译)
英文原文:Approaching (Almost) Any Machine Learning Problem
Kaggle团队| 07.21.2016

Kaggle大师Abhishek Thakur最初在2016年7月18日在这里发表了这篇文章。
一个数据科学家每天处理大量的数据。有人说,超过60-70%的时间花在了数据清理,数据转移和数据采集上,使得机器学习模型可以应用于这些数据。这篇文章的重点是第二部分,即应用机器学习模型,包括预处理步骤。这篇文章讨论的流水线是我参加过的一百多次机器学习比赛的结果。必须指出的是,这里的讨论非常普遍,但非常有用,也可能存在非常复杂的方法,由专业人士练习。
我们将使用python!
数据
在应用机器学习模型之前,必须将数据转换为表格形式。这整个过程是最耗时,最困难的过程,如下图所示

然后将机器学习模型应用于表格数据。表格数据是在机器学习或数据挖掘中表示数据的最常用方式。我们有一个数据表,包含不同数据样本或X和标签的行。标签可以是单栏或多栏,具体取决于问题的类型。我们将用X来表示数据,用y来表示标签。
标签的类型
标签定义了问题,可以是不同的类型,如:
•单列,二进制值(分类问题,一个样本只属于一个类,只有两个类)
•单列,实际值(回归问题,仅预测一个值)
•多列,二进制值(分类问题,一个样本属于一个类,但有两个以上的类)
•多列,实际值(回归问题,多值预测)
•多标签(分类问题,一个样本可以属于几个类)
评估指标
对于任何类型的机器学习问题,我们必须知道我们将如何评估我们的结果,或评估指标或目标是什么。例如,如果存在偏斜的二元分类问题,我们通常选择受试者工作特征曲线(ROC AUC或简称AUC)下的面积。在多标签或多类分类问题的情况下,我们在处理回归问题的情况下一般选择分类交叉熵或多类对数损失和均方误差(categorical cross-entropy or multiclass log loss and mean squarederror)。
我不会详细讨论不同的评估指标,因为我们可以有很多不同的类型,这取决于问题。
库
要开始使用机器学习库,首先安装基本的和最重要的,比如numpy和scipy。
•查看和执行数据操作:pandas(http://pandas.pydata.org/)
•对于各种机器学习模型:scikit-learn(http://scikit-learn.org/stable/)
•最好的梯度提升库:xgboost(https://github.com/dmlc/xgboost)
•对于神经网络:keras(http://keras.io/)
•绘制数据:matplotlib(http://matplotlib.org/)
•监视进度:tqdm(https://pypi.python.org/pypi/tqdm)
我不使用Anaconda(https://www.continuum.io/downloads)。这很容易,为你做一切,但我想要更多的自由。这是你的选择。
机器学习框架
2015年,我提出了一个自动机器学习的框架,这个框架还在开发之中,很快就会发布。对于本文,同样的框架将是基础。框架如下图所示:
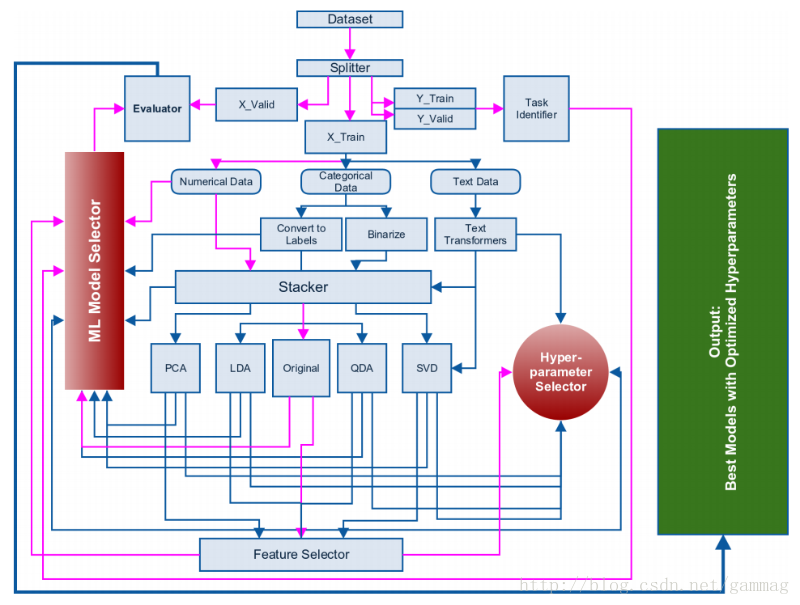
图:A. Thakur和A. Krohn-Grimberghe,AutoCompete:机器学习竞赛框架,AutoML研讨会,2015年机器学习国际会议。
在上面显示的框架中,粉红色的线代表最常用的路径。在我们提取并将数据缩减为表格格式之后,我们可以继续构建机器学习模型。
第一步是确定问题。这可以通过查看标签来完成。必须知道问题是二元分类,多类还是多标签分类还是回归问题。在我们发现问题后,我们将数据分成两个不同的部分,一个训练集和一个验证集,如下图所示。
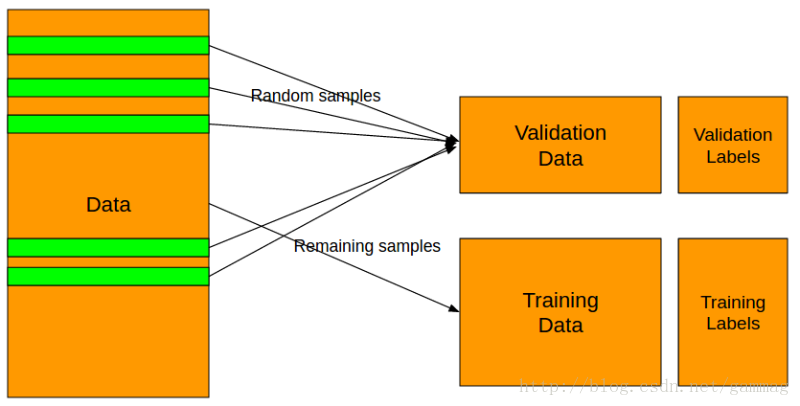
将数据分解为训练和验证集“必须”根据标签进行。在任何分类问题的情况下,使用抽样分割。在python中,你可以使用scikit-learn很容易地做到这一点。

在回归任务的情况下,简单的K折分割(K-Ford)就足够了。然而,有些复杂的方法往往会保持标签的分布对于训练和验证都是一样的,这留给读者练习。

在上面的例子中,我选择了eval_size或验证集的大小作为完整数据的10%,但是可以根据数据的大小选择这个值。
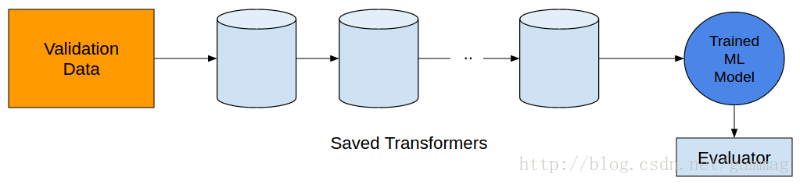
数据拆分完成后,将这些数据保留,不要触摸它。必须保存在训练集上应用的任何操作,然后应用于验证集。在任何情况下,验证集都不应该与训练集一起使用。这样做虽然会得到非常好的评估分数,让用户高兴,但将会建立一个严重过拟合的无用模型。
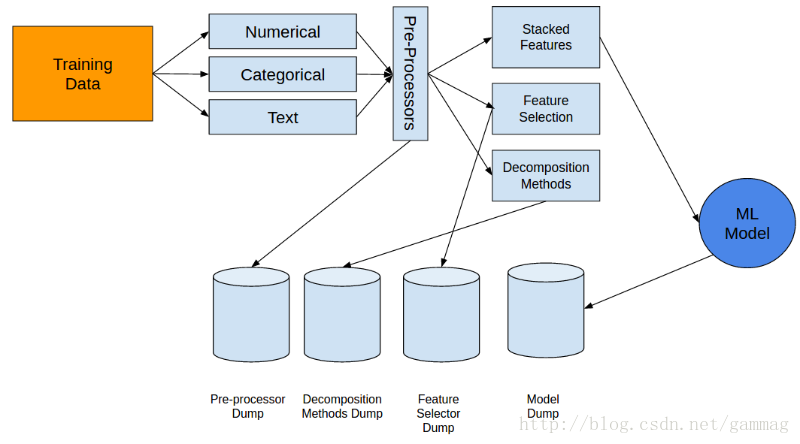
下一步是识别数据中的不同变量。通常有三种类型的变量需要我们处理。也就是说,数值变量,分类变量和其中包含文本的变量。让我们以流行的泰坦尼克号数据集(https://www.kaggle.com/c/titanic/data)为例。

在这里,survival就是标签。我们已经在上一步中将训练数据中的标签分开了。然后,我们有pclass,sex,embarked。这些变量具有不同的类别,因此它们是分类变量。像age,sibsp,parch等变量是数值变量。name是一个包含文本数据的变量,但我不认为这是预测survival的有用变量。
首先分开数值变量。这些变量不需要任何类型的处理,因此我们可以开始对这些变量应用规范化和机器学习模型。
有两种方法可以处理分类数据:
•将分类数据转换为标签

•将标签转换为二进制变量(独热编码one-hot-encoding)

请记住先使用LabelEncoder将类别转换为数字,然后再应用OneHotEncoder。
因为泰坦尼克号的数据没有文本变量的好例子,所以我们来制定处理文本变量的一般规则。我们可以将所有的文本变量合并为一个,然后使用一些对文本数据起作用的算法并将其转换为数字。

然后我们可以使用CountVectorizer或TfidfVectorizer:


TfidfVectorizer的性能比大多数时候都要好,我已经看到TfidfVectorizer的下列参数几乎都是在工作。

如果您仅在训练集上应用这些向量化器,请确保将其转储到硬盘驱动器,以便稍后在验证集上使用它。

接下来,我们来到堆垛机模块(Stacker)。堆垛机模块不是模型堆垛机,而是特征堆垛机。上述处理步骤之后的不同特征可以使用堆叠器模块进行组合。

你可以水平堆叠所有的功能之前,通过使用numpy的堆叠或sparse的堆叠进行进一步处理,这取决于你是否有密集或稀疏的功能。

如果还有其他处理步骤,例如pca或特征选择,我们也可以通过FeatureUnion模块来实现(我们将在本文稍后的部分中介绍分解和特征选择)。

一旦我们把这些特征叠加在一起,我们可以开始应用机器学习模型。在这个阶段只有你应该去的模型应该是基于集成树的模型。这些模型包括:
- RandomForestClassifier
- RandomForestRegressor
- ExtraTreesClassifier
- ExtraTreesRegressor
- XGBClassifier
- XGBRegressor
我们不能将线性模型应用于上述特征,因为它们没有被标准化。要使用线性模型,可以使用scikit-learn中的Normalizer或StandardScaler。
这些规范化方法只适用于密集的特征,如果应用于稀疏特征则不会给出非常好的结果。是的,可以在不使用均值(参数:with_mean = False)的情况下将StandardScaler应用于稀疏矩阵。
如果上面的步骤给出了一个“好”的模型,我们可以去优化超参数,如果没有,我们可以去下面的步骤和改进我们的模型。

为了简单起见,我们将忽略LDA和QDA转换。对于高维数据,通常使用PCA来分解数据。对于图像以10-15个组件开始,只要结果的质量大大提高,就增加这个数量。对于其他类型的数据,我们最初选择50-60个组件(只要我们可以处理数字数据,我们倾向于避免PCA)。

对于文本数据,在将文本转换为稀疏矩阵之后,进行奇异值分解(SVD)。可以在scikit-learn中找到称为TruncatedSVD的SVD变体。

通常用于TF-IDF或计数的SVD组件的数量在120-200之间。以上任何数字都可能会提高性能,但不会大幅度降低计算能力。
在评估模型的进一步性能之后,我们转向数据集的缩放,以便我们也可以评估线性模型。然后可以将归一化或缩放的特征发送到机器学习模型或特征选择模块。

有多种方法可以实现特征选择。最常见的方式之一是贪婪的功能选择(向前或向后)。在贪心特征选择中,我们选择一个特征,训练一个模型,并在固定的评估指标上评估模型的性能。我们不断地添加和删除功能,并在每一步记录模型的性能。然后我们选择具有最佳评估分数的特征。以AUC作为评估指标的贪婪特征选择的一个实现可以在这里找到:https://github.com/abhishekkrthakur/greedyFeatureSelection。必须指出的是,这个实现并不完美,必须根据需要进行修改/修改。
其他更快速的特征选择方法包括从模型中选择最佳特征。我们既可以查看logit模型的系数,也可以训练一个随机森林来选择最佳特征,然后在其他机器学习模型中使用它们。

请记住保持较少的估计量和最小的超参数优化,以免过度使用。
使用渐变增强机器也可以实现特征选择。如果我们在scikit-learn中使用xgboost而不是GBM的实现,这是很好的,因为xgboost更快更灵活。

我们也可以使用RandomForestClassifier / RandomForestRegressor和xgboost来进行稀疏数据集的特征选择。
从正向稀疏数据集中选择特征的另一个流行方法是基于chi-2的特征选择,我们也在scikit-learn中实现了这一点。

在这里,我们使用chi2和SelectKBest从数据中选择20个特征。这也成为我们想要优化的超参数来改进我们的机器学习模型的结果。
不要忘记保存在任何步骤中使用任何种类的转换状态数据。您将需要他们评估验证集上的性能。
下一步(或中级)的主要步骤是模型选择+超参数优化。
我们通常在选择机器学习模型的过程中使用以下算法:
- Classification:
- Random Forest
- GBM
- Logistic Regression
- Naive Bayes
- Support Vector Machines
- k-Nearest Neighbors
- Regression
- Random Forest
- GBM
- Linear Regression
- Ridge
- Lasso
- SVR
我应该优化哪些参数?我如何选择最接近最好的参数?这些是大多数人想到的几个问题。如果没有大量数据集的不同模型+参数的经验,就无法得到这些问题的答案。也有经验的人不愿意分享他们的秘密。幸运的是,我也有相当多的经验,我愿意放弃一些东西。

RS * =不能说出适当的值,要对这些超参数进行随机搜索。
在我看来,严格地说我的意见是,上述模式将超越任何其他模式,我们不需要评估任何其他模型。
再次强调记住保存转换状态数据:
上述规则和框架在我处理的大多数数据集中表现都非常好。当然,这个任务也很复杂。没有什么是完美的,我们继续改进我们学到的东西。就像机器学习一样。
有任何疑问与我联系:abhishek4 [at] gmail [dot] com
个人简历
Abhishek Thakur, 比赛大师.
Abhishek Thakur是Searchmetrics公司数据科学团队的高级数据科学家。在Searchmetrics,Abhishek致力于一些最有趣的数据驱动研究,应用机器学习算法,并从海量数据中获取需要大量数据的整理,清理,特征工程以及机器学习模型的构建和优化。
他在空闲时间喜欢参加机器学习比赛,参加过100多场比赛。他的研究兴趣包括自动机器学习,深度学习,超参数优化,计算机视觉,图像分析和检索以及模式识别。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)