[机器学习] Coursera ML笔记 - 逻辑回归(Logistic Regression)
引言
机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归、逻辑回归、Softmax回归、神经网络和SVM等等,主要学习资料来自Standford Andrew Ng老师在Coursera的教程以及UFLDL Tutorial,Stanford CS231n等在线课程和Tutorial,同时也参考了大量网上的相关资料(在后面列出)。
前言
本文主要介绍逻辑回归的基础知识,文章小节安排如下:
1)逻辑回归定义
2)假设函数(Hypothesis function)
3)决策边界(Decision Boundary)
4)代价函数(Cost Function)
5)优化方法
逻辑回归定义
简单来说,
逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等。
注意,这里用的是“可能性”,而非数学上的“概率”,logisitc回归的结果并非数学定义中的概率值,不可以直接当做概率值来用。该结果往往用于和其他特征值加权求和,而非直接相乘。
那么逻辑回归与线性回归是什么关系呢?
逻辑回归(Logistic Regression)与线性回归(Linear Regression)都是一种广义线性模型(generalized linear model)。逻辑回归假设因变量 y 服从伯努利分布,而线性回归假设因变量 y 服从 高斯分布。
因此与线性回归有很多相同之处,去除Sigmoid映射函数的话,算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
机器学习中的任何算法都有着数学基础,有着不同的前提假设和对应的约束。因此如果想要深入的掌握机器学习算法,必须要捡起数学课本,包括统计、概率、微积分等。
假设函数(Hypothesis function)
逻辑回归的假设函数形式如下:
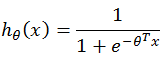
这个函数称为Sigmoid函数,也称为逻辑函数(Logistic function),其函数曲线如下:
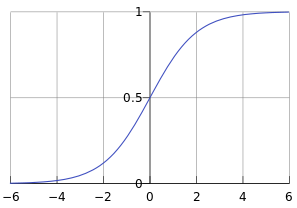
从上图可以看到sigmoid函数是一个s形的曲线,它的取值在[0, 1]之间,在远离0的地方函数的值会很快接近0/1。这个性质使我们能够以概率的方式来解释。
一个机器学习的模型,实际上是把决策函数限定在某一组条件下,这组限定条件就决定了模型的假设空间。当然,我们还希望这组限定条件简单而合理。而逻辑回归模型所做的假设是:
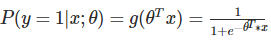
这里的 g(h) 是上边提到的 sigmoid 函数,相应的决策函数为:
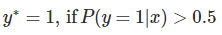
选择0.5作为阈值是一个一般的做法,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
决策边界(Decision Boundary)
决策边界,也称为决策面,是用于在N维空间,将不同类别样本分开的平面或曲面。
首先看Andrew Ng老师课程上的两张图:
线性决策边界:

决策边界:
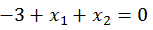
非线性决策边界:

决策边界:
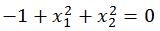
上面两张图很清晰的解释了什么是决策边界,决策边界其实就是一个方程,在逻辑回归中,决策边界由theta’X=0定义。
要注意理解假设函数和决策边界函数的区别与联系。决策边界是假设函数的属性,由假设函数的参数决定。
在逻辑回归中,假设函数(h=g(z))用于计算样本属于某类别的可能性;决策函数(h=1(g(z)>0.5))用于计算(给出)样本的类别;决策边界(θ^Tx=0)是一个方程,用于标识出分类函数(模型)的分类边界。
代价函数(Cost Function)
线性回归中的代价函数:
![线性回归代价函数]](https://img-blog.csdn.net/20160409205240533)
线性回归中的代价函数看上去很好理解,但却不能用于逻辑回归,原因如下:
如果我们使用这个代价值形式,J(θ)会变成参数θ的非凸函数,因为在逻辑回归中,H(θ)是一个Sigmoid函数,其曲线如下:
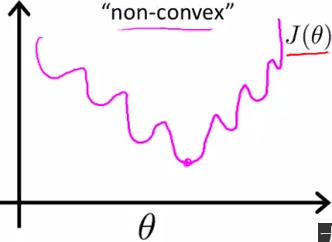
该函数是一个非凸函数,有很多局部最优值。如果你把梯度下降法用在一个这样的函数上,不能保证它会收敛到全局最小值。
相应地我们希望我们的代价函数J(θ)是一个凸函数,是一个单弓形函数,如下:
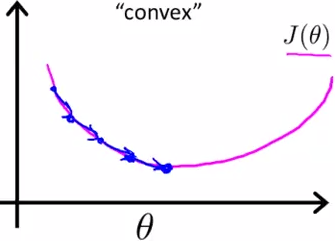
如果对它使用梯度下降法,我们可以保证梯度下降法会收敛到该函数的全局最小值。
由于H(θ)是一个sigmoid函数,导致J(θ)成为一个非凸函数,因此,我们需要另外找到一个不同的代价函数,它是凸函数,使得我们可以使用很好的算法,如梯度下降法,而且能保证找到全局最小值。
因此,我们采用如下的形式计算样本的代价值:
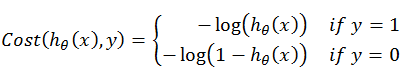
逻辑回归中的代价函数:
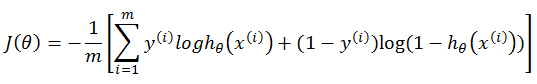
补充资料:极值 和 最优化问题
所谓极值,简单地说,是指一群同类量中的最大量(或最小量).对于极值问题的研究,历来被视为一个引人入胜的课题.波利亚说过:“尽管每个人都有他自己的 问题,我们可以注意到,这些问题大多是些极大或极小问题.我们总希望以尽可能低的代价来达到某个目标,或者以一定的努力来获得尽可能大的效果,或者在一定 的时间内做最大的功,当然,我们还希望冒最小的风险。我相信数学上关于极大和极小的问题,之所以引起我们的兴趣,是因为它能使我们日常生活中的问题理想 化.”波利亚,《数学与猜想》,第一卷,第133页我们将看到,许多实际问题和数学问题,都可归结为形形色色的极值问题,才能得到统一地解决.
优化方法
在逻辑回归中,依然使用梯度下降法对代价函数进行优化,完整形式如下:

注意:
逻辑回归和线性回归问题中,梯度下降算法的形式看上去是一致的(更新参数的规则看起来基本相同),但实际上两者是完全不同的,因为假设函数是不同的,需要特别注意这一点。
其向量化实现(vectorized implementation)如下:
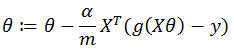

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)