【Learning Notes】PLDA(Probabilistic Linear Discriminant Analysis)
PLDA 是一个概率生成模型,最初是为解决人脸识别和验证问题而被提出[3,5],之后也被广泛应用到声纹识别等模式识别任务中。学者从不同的动机出发,提出了多种 PLDA 算法,文献[2] 在统一的框架下比较了三种 PLDA 算法变种(standard[3,6], simplified[4], two-covariance[5,8]),并在说话人识别任务上比较了它们的性能差异。本文讨论的 PLDA..
PLDA 是一个概率生成模型,最初是为解决人脸识别和验证问题而被提出[3,5],之后也被广泛应用到声纹识别等模式识别任务中。学者从不同的动机出发,提出了多种 PLDA 算法,文献[2] 在统一的框架下比较了三种 PLDA 算法变种(standard[3,6], simplified[4], two-covariance[5,8]),并在说话人识别任务上比较了它们的性能差异。
本文讨论的 PLDA 主要是基于文献 [5] 中提出的 PLDA(即 two-covariance PLDA),这也是 Kaldi 中采用的算法。
本文 1 节简单介绍 LDA,只对 PLDA 算法感兴趣的读者可以跳过。
1. LDA
1.1 基本 LDA
线性判别分析(Linear Discriminant Analysis, LDA)[1] 是一种线性分类技术。LDA 假设数据服从高斯分布,并且各类的协方差相同。
如果各类的先验概率为 π k \pi_k πk( ∑ k π k = 1 \sum_k \pi_k = 1 ∑kπk=1),则各类数据的概率分布为:
p ( x ∣ k ) ∼ N ( μ k , Σ ) p(x|k) \sim N(\mu_k, \Sigma) p(x∣k)∼N(μk,Σ)
观测到数据后,类别的后验为:
p ( k ∣ x ) = p ( x ∣ k ) π k p ( x ) p(k|x) = \frac{p(x|k)\pi_k}{p(x)} p(k∣x)=p(x)p(x∣k)πk
为了对数据进行分类,比较后验的似然比:
ln p ( k ∣ x ) p ( l ∣ x ) = ln p ( x ∣ k ) p ( x ∣ l ) + ln π k π l = ln π k π l − 1 2 ( μ k − μ l ) T Σ − 1 ( μ k + μ l ) + x T Σ − 1 ( μ k − μ l ) \ln \frac{p(k|x)}{p(l|x)} = \ln \frac{p(x|k)}{p(x|l)} + \ln \frac{\pi_k}{\pi_l} = \ln \frac{\pi_k}{\pi_l} - \frac{1}{2} (\mu_k - \mu_l)^T\Sigma^{-1} (\mu_k + \mu_l) + x^T\Sigma^{-1}(\mu_k - \mu_l) lnp(l∣x)p(k∣x)=lnp(x∣l)p(x∣k)+lnπlπk=lnπlπk−21(μk−μl)TΣ−1(μk+μl)+xTΣ−1(μk−μl)
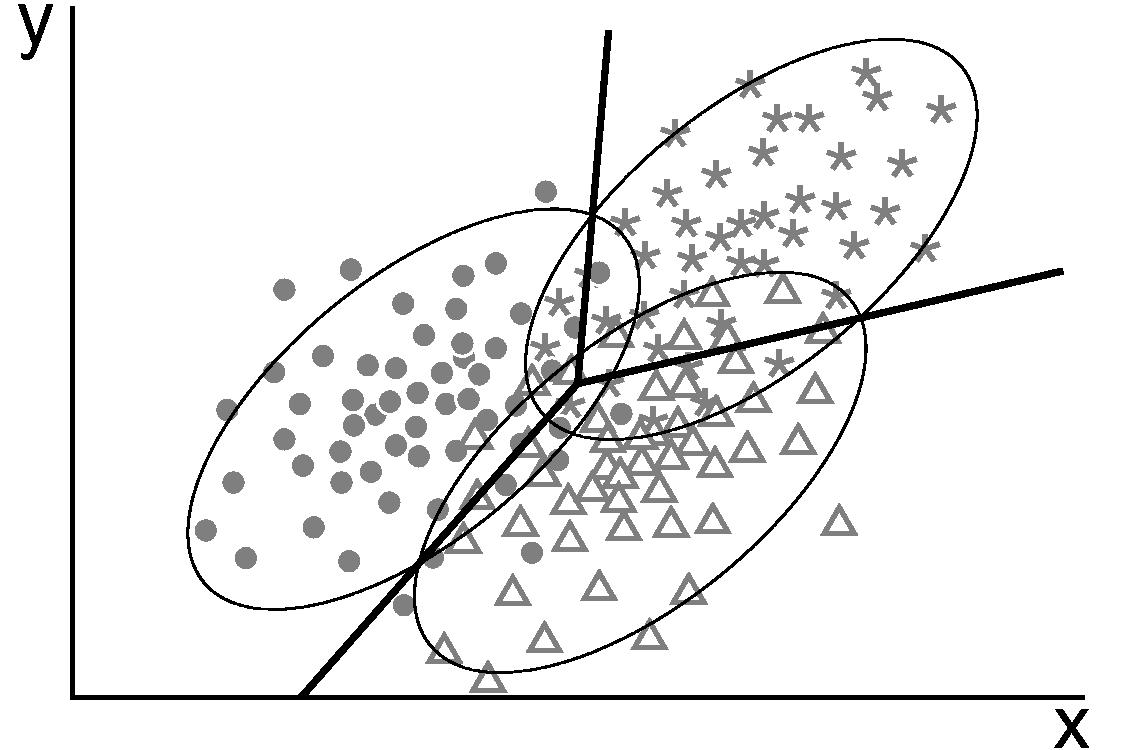
由于假设协方差相同,因此似然比是关于输入 x x x 的线性函数。LDA 用一系列超平面划分数据空间,进而完成分类。图1 示意了LDA 构建的分类决策平面。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JYC7GbMm-1584004092763)(http://www.ucl.ac.uk/~ucfbpve/papers/VermeeschGCubed2006/figures/discriminant.jpg)]
图1. LDA 分类示意【src】
如果允许各类的协方差不同,则决策面是二次的,称为二次判别分析(QDA(Quadratic Discriminant Analysis,QDA)。
这种基本的 LDA 的参数估计非常简单直接:
- π ^ k = n k N \hat \pi_k = \frac{n_k}{N} π^k=Nnk,其中 N = ∑ i = 1 K n i N = \sum_{i=1}^K n_i N=∑i=1Kni
- μ ^ k = 1 n k ∑ i = 1 n k x k i \hat \mu_k = \frac{1}{n_k}\sum_{i=1}^{n_k} x_{ki} μ^k=nk1∑i=1nkxki
- Σ ^ = 1 N − K ∑ k = 1 K ∑ i = 1 n k ( x k i − μ ^ k ) ( x k i − μ ^ k ) T \hat \Sigma = \frac{1}{N-K} \sum_{k=1}^K \sum_{i=1}^{n_k} (x_{ki} - \hat \mu_k)(x_{ki} - \hat \mu_k)^T Σ^=N−K1∑k=1K∑i=1nk(xki−μ^k)(xki−μ^k)T
1.2 降维 LDA
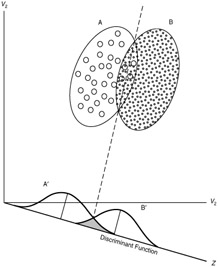
基本的 LDA 可能并不吸引人。LDA 得到广泛应用的一个重要原因是,它可以用来对数据进行降维。

图2. LDA 投影 【src】
以两分类为例(图2),如果将数据沿着决策线(超平面)的方向投影,投影(降维)后不影响数据的分类结果,因为,非投影方向的各类的均值和(协)方差相同,并不能为分类提供有效信息。
一般地,对于 K K K 个类别的分类问题,对于分类有效的信息集中在 K − 1 K-1 K−1 维的子空间上。即基于 LDA 的假设,数据可以从原来的 d d d 维降为 K − 1 K-1 K−1 维(假设 K − 1 < = d K-1 <= d K−1<=d)。投影方向的计算可以参见[1]第4章。
1.3 类内方差与类间方差
对于 LDA 降维还有另一种解释来自 Fisher:对于原数据 X,寻找一个线性组合 Z = w T X Z = w^T X Z=wTX(低维投影),使得 Z Z Z 的类间方差与类内方差的比值最大。
显然,这样的投影方式使得数据在低维空间最容易区分。我们定义计算类内散布矩阵 (scatter matrix) S w = ∑ k ∑ i ∈ C k ( x i − m k ) ( x i − m k ) T S_w = \sum_k\sum_{i \in \mathcal{C}_k} (\mathbf{x}_i - \mathbf{m}_k)(\mathbf{x}_i - \mathbf{m}_k)^T Sw=∑k∑i∈Ck(xi−mk)(xi−mk)T 和 类间散布矩阵 S b = ∑ k n k ( m k − m ) ( m k − m ) T S_b = \sum_kn_k(\mathbf{m}_k - \mathbf{m})(\mathbf{m}_k - \mathbf{m})^T Sb=∑knk(mk−m)(mk−m)T。其中, m k = 1 n k ∑ i ∈ C k x i m_k = \frac{1}{n_k} \sum_{i \in \mathcal{C}_k} \mathbf{x}_i mk=nk1∑i∈Ckxi 为第 k k k 类样本均值, m = 1 N ∑ k ∑ i ∈ C k x i m = \frac{1}{N} \sum_k\sum_{i \in \mathcal{C}_k} \mathbf{x}_i m=N1∑k∑i∈Ckxi 为全部样本均值。
有些文献中, S b S_b Sb 定义为 ∑ k ( m k − m ) ( m k − m ) T \sum_k(\mathbf{m}_k - \mathbf{m})(\mathbf{m}_k - \mathbf{m})^T ∑k(mk−m)(mk−m)T。当各类数量均衡时,两种定义是等价的。
为此,我们需要优化瑞利熵(Rayleigh Quotient)[1]。
w = a r g m a x w w T S b w w T S w w \mathbf{w} = \underset{\mathbf{w}}{\mathrm{argmax}}\ \frac{\mathbf{w}^T S_b \mathbf{w}}{\mathbf{w}^T S_w \mathbf{w}} w=wargmax wTSwwwTSbw
等价的
w = a r g m a x w w T S b w \mathbf{w} = \underset{\mathbf{w}}{\mathrm{argmax}}\ \mathbf{w}^T S_b \mathbf{w} w=wargmax wTSbw
s . t . w T S w w = 1 s.t. \mathbf{w}^T S_w \mathbf{w} = 1 s.t.wTSww=1
这是一个广义特征值问题。具体地,上式可以用拉格朗日乘数求解,即寻找下式的极值:
w T S b w − λ ( w T S w w − 1 ) \mathbf{w}^T S_b \mathbf{w} - \lambda (\mathbf{w}^T S_w \mathbf{w} - 1) wTSbw−λ(wTSww−1)
求导后得到:
S b w = λ S w w S_b\mathbf{w} = \lambda S_w\mathbf{w} Sbw=λSww
如果 S w S_w Sw 可逆,则有:
S w − 1 S b w = λ w S_w^{-1} S_b\mathbf{w} = \lambda \mathbf{w} Sw−1Sbw=λw
即我们只需求解矩阵 S w − 1 S b S_w^{-1} S_b Sw−1Sb 的特征向量,保留特征值最大前 k k k(不一定是 K − 1 K - 1 K−1)个特征向量(列向量)即可以得到 W W W( d d d 行, k k k 列)。
类内-类间方差的视角更加通用,首先,它并不需要假设数据分布服从高斯且协方差相同;其次,降维的维度不再依赖类别数目。
2. PLDA
同 LDA 一样,各种 PLDA 都将数据之间的差异分解为类内差异和类间差异,但是从概率的角度进行建模。这里,我们按照 [5] 的思路,介绍所谓 two-covariance PLDA。
假设数据 x \mathbf{x} x 满足如下概率关系:
p ( x ∣ y ) = N ( x ∣ y , Φ w ) p(\mathbf{x}|\mathbf{y}) = \mathcal{N}(\mathbf{x}|\mathbf{y}, \Phi_w) p(x∣y)=N(x∣y,Φw)
p ( y ) = N ( y ∣ m , Φ b ) p(\mathbf{y}) = \mathcal{N}(\mathbf{y}|\mathbf{m}, \Phi_b) p(y)=N(y∣m,Φb)
LDA 假设各类中心服从离散分布,离散中心的个数固定,是训练数据中已知的类别数;PLDA 假设各类中心服从一个连续分布(高斯分布)。因此,PLDA 能够扩展到未知类别,从而用于未知类别的识别与认证。
这里要求协方差矩阵 Φ w \Phi_w Φw 是正定的对称方阵,反映了类内(within-class)的差异; Φ b \Phi_b Φb 是半正定 的对称方阵,反映了类间(between-class)的差异。因此,PLDA 建模了数据生成的过程,并且同时 LDA 一样,显式地考虑了类内和类间方差。
为了推断时方便,下面推导 PLDA 的一种等价表示。
根据线性代数的基础知识, Φ w \Phi_w Φw 和 Φ b \Phi_b Φb 可以同时合同对角化(simultaneous diagonalization by congruence),即存在可逆矩阵 V V V,使得 V T Φ b V = Ψ V^T\Phi_bV=\Psi VTΦbV=Ψ( Ψ \Psi Ψ 为对角阵)且 V T Φ w V = I V^T\Phi_wV = I VTΦwV=I( I I I 是单位矩阵)。对角化方法见第 4 节。
基于上述说明,PLDA 的等价表述为:
x = m + A u \mathbf{x} = \mathbf{m} + A\mathbf{u} x=m+Au
其中,
u ∼ N ( ⋅ ∣ v , I ) \mathbf{u} \sim \mathcal{N}(\cdot|\mathbf{v}, I) u∼N(⋅∣v,I)
v ∼ N ( ⋅ ∣ 0 , Ψ ) \mathbf{v} \sim \mathcal{N}(\cdot|0, \Psi) v∼N(⋅∣0,Ψ)
A = V − 1 A = V^{-1} A=V−1
u \mathbf{u} u 是数据空间在投影空间的对应投影点。 Ψ \Psi Ψ 反映了类间(between-class); I I I 反映了类内(within-class)的差异的差异(这里被规一化为单位矩阵)。
3. 基于 PLDA 的推断
对于每一个观测数据 x \mathbf{x} x 我们都可以计算对应的 u = A − 1 ( x − m ) \mathbf{u} = A^{-1}(\mathbf{x} - \mathbf{m}) u=A−1(x−m)。 PLDA 的推断都在投影空间中进行。
给定观一组同类的测数据 u 1 , … , n \mathbf{u}_{1,\dots,n} u1,…,n, v \mathbf{v} v 的后验概率分布为(参见 4.2.1):
p ( v ∣ u 1 , … , n ) = N ( v ∣ n Ψ n Ψ + I u ˉ , Ψ n Ψ + I ) p(\mathbf{v}|\mathbf{u}_{1,\dots,n}) = \mathcal{N}(\mathbf{v}|\frac{n\Psi}{n\Psi + I} \mathbf{\bar u}, \frac{\Psi}{n\Psi + I}) p(v∣u1,…,n)=N(v∣nΨ+InΨuˉ,nΨ+IΨ)
其中, u ˉ = 1 n ∑ i = 1 n u i \mathbf{\bar u} = \frac{1}{n}\sum_{i=1}^n\mathbf{u}_i uˉ=n1∑i=1nui。
因此,对于未知数据点 u p \mathbf{u}^p up 以及某类的若干数据点 u 1 , … , n g \mathbf{u}^g_{1,\dots,n} u1,…,ng(i.i.d.), u p \mathbf{u}^p up 属于该类的似然值:
p ( u p ∣ u 1 , … , n g ) = N ( n Ψ n Ψ + I u ˉ g , Ψ n Ψ + I + I ) p(\mathbf{u}^p|\mathbf{u}^g_{1,\dots,n}) = \mathcal{N}(\frac{n\Psi}{n\Psi + I} \mathbf{\bar u}^g, \frac{\Psi}{n\Psi + I} + I) p(up∣u1,…,ng)=N(nΨ+InΨuˉg,nΨ+IΨ+I)
ln p ( u p ∣ u 1 , … , n g ) = C − 1 2 ( u p − n Ψ n Ψ + I u ˉ g ) T ( Ψ n Ψ + I + I ) − 1 ( u p − n Ψ n Ψ + I u ˉ g ) − 1 2 ln ∣ Ψ n Ψ + I + I ∣ \ln p(\mathbf{u}^p|\mathbf{u}^g_{1,\dots,n}) = C - \frac{1}{2} (\mathbf{u}^p - \frac{n\Psi}{n\Psi + I} \mathbf{\bar u}^g)^T (\frac{\Psi}{n\Psi + I} + I)^{-1}(\mathbf{u}^p - \frac{n\Psi}{n\Psi + I} \mathbf{\bar u}^g) -\frac{1}{2}\ln |\frac{\Psi}{n\Psi + I} + I| lnp(up∣u1,…,ng)=C−21(up−nΨ+InΨuˉg)T(nΨ+IΨ+I)−1(up−nΨ+InΨuˉg)−21ln∣nΨ+IΨ+I∣
其中, C = − 1 2 d ln 2 π C = -\frac{1}{2}d\ln 2\pi C=−21dln2π 是与数据无关的常量, d d d 是数据的维度。特殊的, u p \mathbf{u}^p up 不属于任何已知类的概率为:
p ( u p ∣ ∅ ) = N ( u p ∣ 0 , Ψ + I ) p(\mathbf{u}^p|\emptyset) = \mathcal{N}(\mathbf{u}^p|0, \Psi + I) p(up∣∅)=N(up∣0,Ψ+I)
ln p ( u p ∣ ∅ ) = C − 1 2 u p T ( Ψ + I ) − 1 u p − 1 2 ln ∣ Ψ + I ∣ \ln p(\mathbf{u}^p|\emptyset) = C - \frac{1}{2} \mathbf{u}^{pT} (\Psi + I)^{-1} \mathbf{u}^p -\frac{1}{2}\ln |\Psi + I| lnp(up∣∅)=C−21upT(Ψ+I)−1up−21ln∣Ψ+I∣
由于 Ψ \Psi Ψ 是对角阵,因此上式中各个协方差也都是对角阵,因此,似然和对数似然都很容易求得。
利用 PLDA 进行识别(recognition)方法如下::
i = a r g m a x i ln p ( u p ∣ u 1 , … , n g i ) i = \underset{i}{\mathrm{argmax}}\ \ln p(\mathbf{u}^p|\mathbf{u}^{g_i}_{1,\dots,n}) i=iargmax lnp(up∣u1,…,ngi)
对于认证问题(verification),可以计算其似然比:
R = p ( u p ∣ u 1 , … , n g ) p ( u p ∣ ∅ ) R = \frac{p(\mathbf{u}^p|\mathbf{u}^g_{1,\dots,n})}{p(\mathbf{u}^p|\emptyset)} R=p(up∣∅)p(up∣u1,…,ng)
或似然比对数(log likelihood ratio):
ln R = ln p ( u p ∣ u 1 , … , n g ) − ln p ( u p ∣ ∅ ) \ln R = \ln p(\mathbf{u}^p|\mathbf{u}^g_{1,\dots,n}) - \ln p(\mathbf{u}^p|\emptyset) lnR=lnp(up∣u1,…,ng)−lnp(up∣∅)
适当的选定阈值 T T T,当 R > T R > T R>T 判定 u \mathbf{u} u 与已知数据属于同一个类别,反之则不是。
这里介绍的 two-covariance PLDA 并没有学习一个低维空间投影[2],这一点不同 于LDA 及 standard PLDA 和 simplified PLDA。作为近似手段,可以在投影空间中,丢弃 Ψ \Psi Ψ 中对角元素较小的若干维度对应的值。
4. PLDA 参数估计
PLDA 中,我们需要估计的参数包括 A A A、 Ψ \Psi Ψ 和 m \mathbf{m} m。
4.1 直接求解
对于 K K K 类共 N N N 个训练数据 ( x 1 , … , x N ) (x_1,\dots,x_N) (x1,…,xN)。如果每类样本数量相等,都为 n k = N / K n_k = N / K nk=N/K,则参数有解析的估计形式 [5]。
- 计算类内散布矩阵 (scatter matrix) S w = 1 N ∑ k ∑ i ∈ C k ( x i − m k ) ( x i − m k ) T S_w = \frac{1}{N} \sum_k\sum_{i \in \mathcal{C}_k} (\mathbf{x}_i - \mathbf{m}_k)(\mathbf{x}_i - \mathbf{m}_k)^T Sw=N1∑k∑i∈Ck(xi−mk)(xi−mk)T 和 类间散布矩阵 S b = 1 N ∑ k n k ( m k − m ) ( m k − m ) T S_b = \frac{1}{N}\sum_kn_k(\mathbf{m}_k - \mathbf{m})(\mathbf{m}_k - \mathbf{m})^T Sb=N1∑knk(mk−m)(mk−m)T。其中, m k = 1 n k ∑ i ∈ C k x i m_k = \frac{1}{n_k} \sum_{i \in \mathcal{C}_k} \mathbf{x}_i mk=nk1∑i∈Ckxi 为第 k k k 类样本均值, m = 1 N ∑ k ∑ i ∈ C k x i m = \frac{1}{N} \sum_k\sum_{i \in \mathcal{C}_k} \mathbf{x}_i m=N1∑k∑i∈Ckxi 为全部样本均值。
- 计算 S w − 1 S b S_w^{-1}S_b Sw−1Sb 的特征向量 w 1 , … , d w_{1,\dots,d} w1,…,d,每个特征向量为一列,组成矩阵 W W W。计算对角阵 Λ b = W T S b W \Lambda_b = W^TS_bW Λb=WTSbW, Λ w = W T S w W \Lambda_w = W^TS_wW Λw=WTSwW。
- 计算 A = W − T ( n n − 1 Λ w ) 1 / 2 A = W^{-T} (\frac{n}{n-1}\Lambda_w)^{1/2} A=W−T(n−1nΛw)1/2, Ψ = max ( 0 , n − 1 n ( Λ b / Λ w ) − 1 n ) \Psi = \max(0, \frac{n-1}{n}(\Lambda_b/\Lambda_w) - \frac{1}{n}) Ψ=max(0,nn−1(Λb/Λw)−n1)。
- 如果将维度从原数据的 d d d 维低到 d ′ d^\prime d′ 维,则保留 Ψ \Psi Ψ 的前 d ′ d^\prime d′ 大的对角元素,将其余置为零。在进行推断时,仅使用 u = A − 1 ( x − m ) \mathbf{u} = A^{-1}(\mathbf{x}-\mathbf{m}) u=A−1(x−m) 非零对角无素对应的 d ′ d^\prime d′ 个元素。
如果各类数据的数量不一致,则上述算法只能求得近似的参数估计。
4.2 期望最大化方法(EM)
这里先列出算法流程,具体推导见下文:
输入: K K K 类 d d d 维数据,第 k k k 个类别包含 n k n_k nk 个样本,记 x k i ∈ R d , 1 ≤ k ≤ K x_{ki} \in R^{d}, 1 \le k \le K xki∈Rd,1≤k≤K 为 第 k k k 个类别的第 i i i 个样本点。
输出: d × d d \times d d×d 对称矩阵 Φ w \Phi_w Φw, d × d d \times d d×d 对称矩阵 Φ b \Phi_b Φb, d d d 维向量 m m m。
- 计算统计量, N = ∑ k = 1 K n k N = \sum_{k=1}^K n_k N=∑k=1Knk, f k = ∑ i = 1 n k x k i f_k = \sum_{i=1}^{n_k} x_{ki} fk=∑i=1nkxki, m = 1 N ∑ k f k m = \frac{1}{N}\sum_k f_{k} m=N1∑kfk, S = ∑ k ∑ i x k i x k i T S = \sum_k \sum_i x_{ki}x_{ki}^T S=∑k∑ixkixkiT
- 随机初始化 Φ w \Phi_w Φw, Φ b \Phi_b Φb, m m m
- 重复如下步骤至到满足终止条件:
- 3.1 对每一个类别,计算: Φ ^ = ( n Φ w − 1 + Φ b − 1 ) − 1 \hat \Phi = (n\Phi^{-1}_w + \Phi_b^{-1})^{-1} Φ^=(nΦw−1+Φb−1)−1, y = Φ ^ ( Φ b − 1 m + Φ w − 1 f ) y = \hat \Phi (\Phi_b^{-1} m + \Phi_w^{-1} f) y=Φ^(Φb−1m+Φw−1f), y y t = Φ ^ + y y T yyt = \hat \Phi + y y^T yyt=Φ^+yyT
- 3.2 聚合计算结果: R = ∑ k n k ⋅ y y t k R = \sum_k n_k \cdot yyt_k R=∑knk⋅yytk, T = ∑ k y k f k T T = \sum_k y_k f_k^T T=∑kykfkT, P = ∑ k Φ ^ k P = \sum_k\hat \Phi_k P=∑kΦ^k, E = ∑ k ( y k − m ) ( y k − m ) T E =\sum_k (y_k - m)(y_k - m)^T E=∑k(yk−m)(yk−m)T
- 3.3 更新: Φ w = 1 N ( S + R − ( T + T T ) ) \Phi_w = \frac{1}{N} (S + R - (T + T^T)) Φw=N1(S+R−(T+TT)), Φ b = 1 K ( P + E ) \Phi_b = \frac{1}{K}(P + E) Φb=K1(P+E)
上述算法基本与[2]所列的 two-covariance 算法相同,不过这里我们直接使用全局均值做为 m m m 的估计。如果各类别的样本量相同,则两种方法是等价,实现比较见代码。具体公式的差异见下文。
基于 Φ w \Phi_w Φw 和 Φ b \Phi_b Φb 可以计算出 Ψ \Psi Ψ 和 A − 1 A^{-1} A−1。对角化的方法在 4.1 节算法的2、3步已经给出[5]。
首先,计算 Φ w − 1 Φ b \Phi_w^{-1}\Phi_b Φw−1Φb 的特征向量 w 1 , … , d w_{1,\dots,d} w1,…,d,每个特征向量为一列,组成矩阵 W W W。则有:
Λ b = W T Φ b W \Lambda_b = W^T \Phi_b W Λb=WTΦbW
Λ w = W T Φ w W \Lambda_w = W^T \Phi_w W Λw=WTΦwW
显然
I = Λ w − 1 / 2 Λ w Λ w − 1 / 2 = Λ w − 1 / 2 W T Φ w W Λ w − 1 / 2 I = \Lambda_w^{-1/2}\Lambda_w \Lambda_w^{-1/2} = \Lambda_w^{-1/2} W^T \Phi_w W \Lambda_w^{-1/2} I=Λw−1/2ΛwΛw−1/2=Λw−1/2WTΦwWΛw−1/2
则:
Ψ = Λ b Λ w − 1 \Psi = \Lambda_b \Lambda_w^{-1} Ψ=ΛbΛw−1
V = W Λ w − 1 / 2 V = W \Lambda_w^{-1/2} V=WΛw−1/2
A − 1 = V T = Λ w − 1 / 2 W T A^{-1} = V^T = \Lambda_w^{-1/2} W^T A−1=VT=Λw−1/2WT
这里我们首先通过 EM 算法估计 m m m、 Φ b \Phi_b Φb 和 Φ w \Phi_w Φw。在基础上,我们可以根据上面的公式计算 A − 1 A^{-1} A−1 及 Ψ \Psi Ψ,从而完成 PLDA 模型的训练。
Kaldi 中基于期望最大化方法(EM)实现了 PLDA 的参数( Φ b \Phi_b Φb 和 Φ w \Phi_w Φw)估计。
文献 [2] (算法2 及附录 B) 给出了估计 Φ w \Phi_w Φw 和 Φ b \Phi_b Φb 的算法流程,并给出实现代码。
4.2.1 隐变量 y y y 的后验分布
EM 算法的优化目标为:
Q ( θ ∣ θ ( t − 1 ) ) = E y ∣ x , θ ( t − 1 ) ln p ( x , y ∣ θ ) Q(\theta|\theta^{(t-1)}) = \mathbb{E}_{y|x,\theta^{(t-1)}} \ln p(x, y|\theta) Q(θ∣θ(t−1))=Ey∣x,θ(t−1)lnp(x,y∣θ)
因此我们需要知道 y y y 的后验分布。
回顾 PLDA 的假设:
p ( x ∣ y ) = N ( x ∣ y , Φ w ) p(\mathbf{x}|\mathbf{y}) = \mathcal{N}(\mathbf{x}|\mathbf{y}, \Phi_w) p(x∣y)=N(x∣y,Φw)
p ( y ) = N ( y ∣ m , Φ b ) p(\mathbf{y}) = \mathcal{N}(\mathbf{y}|\mathbf{m}, \Phi_b) p(y)=N(y∣m,Φb)
给定某类的 n n n 个数据 x 1 , … , n x_{1,\dots,n} x1,…,n,则 y y y 的后验分布可以为:
p ( y ∣ x 1 , … , n ) = p ( x 1 , … , n ∣ y ) p ( y ) / p ( x 1 , … , n ) ∝ p ( x 1 , … , n ∣ y ) p ( y ) p(y|x_{1,\dots,n}) = p(x_{1,\dots,n}|y)p(y) / p(x_{1,\dots,n}) \propto p(x_{1,\dots,n}|y)p(y) p(y∣x1,…,n)=p(x1,…,n∣y)p(y)/p(x1,…,n)∝p(x1,…,n∣y)p(y)
后验为两个高斯分布的乘积,因此也服从高斯。因此,我们只需要计算均值向量和方差矩阵,即可以确定后验分布。
ln p ( y ∣ x 1 , … , n ) = ln p ( x 1 , … , n ∣ y ) + ln p ( y ) = ∑ i ln p ( x i ∣ y ) + ln p ( y ) = C − 0.5 ∑ i y T Φ w − 1 y + ∑ i x i T Φ w − 1 y − 0.5 y T Φ b − 1 y + m T Φ b − 1 y \ln p(y|x_{1,\dots,n}) = \ln p(x_{1,\dots,n}|y) + \ln p(y) = \sum_i \ln p(x_i|y) + \ln p(y) = C - 0.5 \sum_i y^T \Phi_w^{-1} y + \sum_i x_i^T \Phi_w^{-1} y - 0.5 y^T \Phi_b^{-1} y + m^T \Phi_b^{-1} y lnp(y∣x1,…,n)=lnp(x1,…,n∣y)+lnp(y)=i∑lnp(xi∣y)+lnp(y)=C−0.5i∑yTΦw−1y+i∑xiTΦw−1y−0.5yTΦb−1y+mTΦb−1y
整理 y y y 的二次项为 0.5 y T ( n Φ w − 1 + Φ b − 1 ) y 0.5 y^T (n\Phi^{-1}_w + \Phi_b^{-1}) y 0.5yT(nΦw−1+Φb−1)y,对比高斯分布的二次项系数,后验的协方差矩阵为:
Φ ^ = ( n Φ w − 1 + Φ b − 1 ) − 1 \hat \Phi = (n\Phi^{-1}_w + \Phi_b^{-1})^{-1} Φ^=(nΦw−1+Φb−1)−1
记均值为 m ^ \hat m m^,则高斯分布的一次项为:
y T Φ ^ − 1 m ^ y^T \hat \Phi^{-1} \hat m yTΦ^−1m^
整理上面的一次式有:
y T ( Φ b − 1 m + Φ w − 1 ∑ i x i ) y^T (\Phi_b^{-1} m + \Phi_w^{-1} \sum_i x_i) yT(Φb−1m+Φw−1i∑xi)
对比两式,令 f = ∑ i x i f = \sum_i x_i f=∑ixi
m ^ = Φ ^ ( Φ b − 1 m + Φ w − 1 f ) \hat m = \hat \Phi (\Phi_b^{-1} m + \Phi_w^{-1} f) m^=Φ^(Φb−1m+Φw−1f)
综上,后验分布为:
p ( y ∣ x 1 , … , n ) ∼ N ( m ^ , Φ ^ ) p(y|x_{1,\dots,n}) \sim \mathcal{N}(\hat m, \hat \Phi) p(y∣x1,…,n)∼N(m^,Φ^)
4.2.2 E step
根据上面的推导有:
Φ ^ = ( n Φ w − 1 + Φ b − 1 ) − 1 \hat \Phi = (n\Phi^{-1}_w + \Phi_b^{-1})^{-1} Φ^=(nΦw−1+Φb−1)−1
m ^ = Φ ^ ( Φ b − 1 m + Φ w − 1 f ) \hat m = \hat \Phi (\Phi_b^{-1} m + \Phi_w^{-1} f) m^=Φ^(Φb−1m+Φw−1f)
根据后验概率,易得如下期望:
E [ y ] = m ^ = Φ ^ ( Φ b − 1 m + Φ w − 1 f ) \mathbb{E}[y] = \hat m = \hat \Phi (\Phi_b^{-1} m + \Phi_w^{-1} f) E[y]=m^=Φ^(Φb−1m+Φw−1f)
E [ y y T ] = Φ ^ + E [ y ] E [ y ] T \mathbb{E}[yy^T] = \hat \Phi + \mathbb{E}[y] \mathbb{E}[y]^T E[yyT]=Φ^+E[y]E[y]T
EM 优化目标可以改写为:
Q ( θ ∣ θ ( t − 1 ) ) = E y ∣ x , θ ( t − 1 ) ln p ( x , y ∣ θ ) = E y ∣ x , θ ( t − 1 ) ln p ( x ∣ y , θ ) + E y ∣ θ ( t − 1 ) ln p ( y ∣ θ ) Q(\theta|\theta^{(t-1)}) = \mathbb{E}_{y|x,\theta^{(t-1)}} \ln p(x, y|\theta) = \mathbb{E}_{y|x,\theta^{(t-1)}} \ln p(x|y, \theta) + \mathbb{E}_{y|\theta^{(t-1)}} \ln p(y|\theta) Q(θ∣θ(t−1))=Ey∣x,θ(t−1)lnp(x,y∣θ)=Ey∣x,θ(t−1)lnp(x∣y,θ)+Ey∣θ(t−1)lnp(y∣θ)
显然,右式第一项只包含参数 Φ w \Phi_w Φw,第二项只包含 Φ b \Phi_b Φb 及 m m m。因此,我们可以将优化目标分为独立的两部分。
4.2.3 M step for Φ w \Phi_w Φw
对于参数 Φ w \Phi_w Φw,EM 的最大化目标函数为:
Q 1 = E y [ ln p ( x ∣ y ) ] = E y [ ∑ i ln p ( x i ∣ y ) ] Q_1 = \mathbb{E}_{y}[\ln p(x|y)] = \mathbb{E}_{y}[\sum_i \ln p(x_i|y)] Q1=Ey[lnp(x∣y)]=Ey[i∑lnp(xi∣y)]
对 x i x_i xi 有:
ln p ( x i ∣ y ) = C − 0.5 ln ∣ Φ w ∣ − 0.5 ( x i − y ) T Φ w − 1 ( x i − y ) = C − 0.5 ln ∣ Φ w ∣ − 0.5 x i T Φ w − 1 x i − 0.5 y T Φ w − 1 y + 0.5 x i T Φ w − 1 y + 0.5 y T Φ w − 1 x i \ln p(x_i|y) = C - 0.5 \ln|\Phi_w| - 0.5 (x_i - y)^T \Phi_w^{-1} (x_i - y) = C - 0.5 \ln|\Phi_w| -0.5 x_i^{T} \Phi_w^{-1} x_i -0.5 y^{T} \Phi_w^{-1} y + 0.5 x_i^T \Phi_w^{-1} y + 0.5 y^T \Phi_w^{-1} x_i lnp(xi∣y)=C−0.5ln∣Φw∣−0.5(xi−y)TΦw−1(xi−y)=C−0.5ln∣Φw∣−0.5xiTΦw−1xi−0.5yTΦw−1y+0.5xiTΦw−1y+0.5yTΦw−1xi
E y [ ln p ( x i ∣ y ) ] = C − 0.5 ln ∣ Φ w ∣ − 0.5 x i T Φ w − 1 x i − 0.5 t r ( E [ y y T ] Φ w − 1 ) + 0.5 x i T Φ w − 1 E [ y ] + 0.5 E [ y ] T Φ w − 1 x i \mathbb{E}_{y}[\ln p(x_i|y)] = C - 0.5 \ln|\Phi_w| -0.5 x_i^{T} \Phi_w^{-1} x_i -0.5 \mathrm{tr} (\mathbb{E}[yy^T] \Phi_w^{-1}) + 0.5 x_i^T \Phi_w^{-1} \mathbb{E}[y] + 0.5 \mathbb{E}[y]^T \Phi_w^{-1} x_i Ey[lnp(xi∣y)]=C−0.5ln∣Φw∣−0.5xiTΦw−1xi−0.5tr(E[yyT]Φw−1)+0.5xiTΦw−1E[y]+0.5E[y]TΦw−1xi
利用矩阵求导的知识[11],并注意到 Φ w \Phi_w Φw 和 E [ y y T ] \mathbb{E}[yy^T] E[yyT] 都是对称矩阵,于是有:
∂ ∂ Φ w E y [ ln p ( x ∣ y ) ] = − 0.5 n Φ w − 1 + 0.5 Φ w − 1 S Φ w − 1 + 0.5 n Φ w − 1 E [ y y ] T Φ w − 1 − 0.5 Φ w − 1 f E [ y ] T Φ w − 1 − 0.5 Φ w − 1 E [ y ] f T Φ w − 1 \frac{\partial}{\partial \Phi_w} \mathbb{E}_{y}[\ln p(x|y)] = -0.5 n \Phi_w^{-1} + 0.5 \Phi_w^{-1} S \Phi_w^{-1} + 0.5n \Phi_w^{-1}\mathbb{E}[yy]^T\Phi_w^{-1} - 0.5\Phi_w^{-1} f \mathbb{E}[y]^T\Phi_w^{-1} - 0.5\Phi_w^{-1} \mathbb{E}[y] f^T\Phi_w^{-1} ∂Φw∂Ey[lnp(x∣y)]=−0.5nΦw−1+0.5Φw−1SΦw−1+0.5nΦw−1E[yy]TΦw−1−0.5Φw−1fE[y]TΦw−1−0.5Φw−1E[y]fTΦw−1
其中, S = ∑ i x i x i T , f = ∑ i x i S = \sum_i x_i x_i^T, f = \sum_i x_i S=∑ixixiT,f=∑ixi。令上式为零,求得:
n Φ w = S + n E [ y y T ] − ( T + T T ) n\Phi_w = S + n\mathbb{E}[yy^T] - (T + T^T) nΦw=S+nE[yyT]−(T+TT)
其中, T = E [ y ] f T T = \mathbb{E}[y] f^T T=E[y]fT
根据这个类别数据, Φ w \Phi_w Φw 的估计为:
Φ w = 1 n [ S + n E [ y y T ] − ( T + T T ) ] \Phi_w =\frac{1}{n}[S + n\mathbb{E}[yy^T] - (T + T^T)] Φw=n1[S+nE[yyT]−(T+TT)]
上面的推导是基于一个类别的数据,如果我们有 K K K 类,对依赖类别的变量加上相应的下标,则有:
∑ k = 1 K n k Φ w = ∑ k = 1 K S k + n k E [ y k y k T ] − ( T k + T k T ) \sum_{k=1}^K n_k \Phi_w = \sum_{k=1}^K S_k + n_k \mathbb{E}[y_ky_k^T] - (T_k + T_k^T) k=1∑KnkΦw=k=1∑KSk+nkE[ykykT]−(Tk+TkT)
根据所有类别数据的信息, Φ w \Phi_w Φw 的估计公式为:
Φ w = 1 N ( S g + R g − ( T g + T g T ) ) \Phi_w = \frac{1}{N} (S_g + R_g - (T_g + T_g^T)) Φw=N1(Sg+Rg−(Tg+TgT))
其中,
S g = ∑ k = 1 K S k = ∑ k = 1 K ∑ j = 1 n k x k j x k j T S_g = \sum_{k=1}^K S_k = \sum_{k=1}^K \sum_{j=1}^{n_k} x_{kj}x_{kj}^T Sg=k=1∑KSk=k=1∑Kj=1∑nkxkjxkjT
T g = ∑ k = 1 K T k = ∑ k = 1 K E [ y k ] f k T T_g = \sum_{k=1}^K T_k = \sum_{k=1}^K \mathbb{E}[y_k] f_k^T Tg=k=1∑KTk=k=1∑KE[yk]fkT
R g = ∑ k = 1 K n k E [ y k y k T ] R_g = \sum_{k=1}^K n_k \mathbb{E}[y_ky_k^T] Rg=k=1∑KnkE[ykykT]
4.2.4 M step for Φ b \Phi_b Φb 及 m m m
对于参数 Φ b \Phi_b Φb 和 m m m,EM 的最大化目标函数为:
Q 2 = E y [ ln p ( y ) ] = ∑ k = 1 K E y k [ ln p ( y k ) ] Q_2 = \mathbb{E}_{y}[\ln p(y)] = \sum_{k=1}^K \mathbb{E}_{y_k}[\ln p(y_k)] Q2=Ey[lnp(y)]=k=1∑KEyk[lnp(yk)]
对 y k y_k yk 有:
ln p ( y k ) = C − 0.5 ln ∣ Φ b ∣ − 0.5 ( y k − m ) T Φ w − 1 ( y k − m ) = C − 0.5 ln ∣ Φ b ∣ − 0.5 y k T Φ b − 1 y k − 0.5 m T Φ b − 1 m + 0.5 y k T Φ b − 1 m + 0.5 m T Φ b − 1 y k \ln p(y_k) = C - 0.5 \ln|\Phi_b| - 0.5 (y_k - m)^T \Phi_w^{-1} (y_k - m) = C - 0.5 \ln|\Phi_b| -0.5 y_k^{T} \Phi_b^{-1} y_k -0.5 m^{T} \Phi_b^{-1} m + 0.5 y_k^T \Phi_b^{-1} m + 0.5 m^T \Phi_b^{-1} y_k lnp(yk)=C−0.5ln∣Φb∣−0.5(yk−m)TΦw−1(yk−m)=C−0.5ln∣Φb∣−0.5ykTΦb−1yk−0.5mTΦb−1m+0.5ykTΦb−1m+0.5mTΦb−1yk
E y [ ln p ( x i ) ] = C − 0.5 ln ∣ Φ b ∣ − 0.5 t r ( E [ y y T ] Φ b − 1 ) − 0.5 m T Φ b − 1 m + 0.5 E [ y ] T Φ b − 1 m + 0.5 m T Φ b − 1 E [ y ] \mathbb{E}_{y}[\ln p(x_i)] = C - 0.5 \ln|\Phi_b| -0.5 \mathrm{tr} (\mathbb{E}[yy^T] \Phi_b^{-1}) -0.5 m^{T} \Phi_b^{-1} m + 0.5 \mathbb{E}[y]^T \Phi_b^{-1} m + 0.5 m^T \Phi_b^{-1} \mathbb{E}[y] Ey[lnp(xi)]=C−0.5ln∣Φb∣−0.5tr(E[yyT]Φb−1)−0.5mTΦb−1m+0.5E[y]TΦb−1m+0.5mTΦb−1E[y]
a) m m m 的估计
类似于4.2.3,我们有:
∂ ∂ m E y [ ln p ( y ) ] = ∑ k − m T Φ b − 1 + E [ y ] T Φ b − 1 \frac{\partial}{\partial m} \mathbb{E}_{y}[\ln p(y)] = \sum_k -m^T \Phi_b^{-1} + \mathbb{E}[y]^T\Phi_b^{-1} ∂m∂Ey[lnp(y)]=k∑−mTΦb−1+E[y]TΦb−1
令上式为零,求得:
m = 1 K ∑ k E [ y k ] m = \frac{1}{K} \sum_k \mathbb{E}[y_k] m=K1k∑E[yk]
由于各类数量可能不均衡,可以加权[2]:
m = 1 N ∑ k n k E [ y k ] m = \frac{1}{N} \sum_k n_k\mathbb{E}[y_k] m=N1k∑nkE[yk]
此时,如果各类别数量相同,将 E [ y ] = Φ ^ ( Φ b − 1 m + Φ w − 1 f ) \mathbb{E}[y] = \hat \Phi (\Phi_b^{-1} m + \Phi_w^{-1} f) E[y]=Φ^(Φb−1m+Φw−1f) 代入上式有:
m = 1 N ∑ k = 1 K f k = 1 N ∑ k = 1 K ∑ i = 1 n k x k i m = \frac{1}{N} \sum_{k=1}^K f_k = \frac{1}{N} \sum_{k=1}^K \sum_{i=1}^{n_k} x_{ki} m=N1k=1∑Kfk=N1k=1∑Ki=1∑nkxki
即 m m m 是已知数据的全局均值,不需要迭代。在 Kaldi 的实现中,不论各类数量,都直接使用全局均值做为 m m m 的估计。
b) Φ b \Phi_b Φb 的估计
对 Φ b \Phi_b Φb 求导得:
∂ ∂ Φ b E y k [ ln p ( y k ) ] = − 0.5 Φ b − 1 + 0.5 Φ b − 1 E [ y k y k T ] Φ b − 1 + 0.5 Φ b − 1 m m T Φ b − 1 − 0.5 Φ b − 1 E [ y k ] m T Φ b − 1 − 0.5 Φ b − 1 m E [ y k ] T Φ b − 1 \frac{\partial}{\partial \Phi_b} \mathbb{E}_{y_k}[\ln p(y_k)] = -0.5 \Phi_b^{-1} + 0.5 \Phi_b^{-1} \mathbb{E}[y_k y_k^T] \Phi_b^{-1} + 0.5\Phi_b^{-1}mm^T\Phi_b^{-1} - 0.5 \Phi_b^{-1} \mathbb{E}[y_k]m^T \Phi_b^{-1} - 0.5 \Phi_b^{-1} m \mathbb{E}[y_k]^T \Phi_b^{-1} ∂Φb∂Eyk[lnp(yk)]=−0.5Φb−1+0.5Φb−1E[ykykT]Φb−1+0.5Φb−1mmTΦb−1−0.5Φb−1E[yk]mTΦb−1−0.5Φb−1mE[yk]TΦb−1
令上式为零,求得更新公式:
Φ b = E [ y k y k T ] + m m T − E [ y k ] m T − m E [ y k T ] \Phi_b = \mathbb{E}[y_k y_k^T] + mm^T - \mathbb{E}[y_k]m^T - m \mathbb{E}[{y_k}^T] Φb=E[ykykT]+mmT−E[yk]mT−mE[ykT]
注意到 E [ y y T ] = Φ ^ + E [ y ] E [ y ] T \mathbb{E}[yy^T] = \hat \Phi + \mathbb{E}[y] \mathbb{E}[y]^T E[yyT]=Φ^+E[y]E[y]T,则有:
Φ b = 1 K ∑ k ( Φ ^ k + ( E [ y k ] − m ) ( E [ y k ] − m ) T ) \Phi_b = \frac{1}{K} \sum_k(\hat \Phi_k +(\mathbb{E}[y_k] - m)(\mathbb{E}[y_k] - m)^T) Φb=K1k∑(Φ^k+(E[yk]−m)(E[yk]−m)T)
如果考虑各类之间的权重,则有:
Φ b = 1 ∑ k w k ∑ k w k ( Φ ^ k + ( E [ y k ] − m ) ( E [ y k ] − m ) T ) \Phi_b = \frac{1}{\sum_{k}w_k} \sum_k w_k (\hat \Phi_k +(\mathbb{E}[{y_k}] - m)(\mathbb{E}[{y_k}] - m)^T) Φb=∑kwk1k∑wk(Φ^k+(E[yk]−m)(E[yk]−m)T)
而如果我们使用 m = 1 N ∑ k n k E [ y k ] m = \frac{1}{N} \sum_k n_k\mathbb{E}[y_k] m=N1∑knkE[yk] 估计 m m m,则综合所有类别数据,并按照数据量加权,有[2]:
Φ b = 1 N R g − m m T \Phi_b = \frac{1}{N} R_g - mm^T Φb=N1Rg−mmT
References
- Hastie et al. The Elements of Statistical Learning.
- Sizov et al. Unifying Probabilistic Linear Discriminant Analysis Variants in Biometric Authentication.
- Prince & Elder. Probabilistic Linear Discriminant Analysis for Inferences About Identity.
- Kenny et al. Bayesian Speaker Verification with Heavy Tailed Priors.
- Ioffe. Probabilistic Linear Discriminant Analysis.
- Shafey et al. A Scalable Formulation of Probabilistic Linear Discriminant Analysis: Applied to Face Recognition.
- Hastie & Tibshirani. Discriminant Analysis by Gaussaian Mixtures.
- Brummer & De Villiers et al. The Speaker Partitioning Problem.
- Jiang et al. PLDA Modeling in I-vector and Supervector Space for Speaker Verification.
- Brummer et al. EM for Probabilistic LDA.
- Petersen & Petersen. The Matrix Cookbook.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
{kind=link}
所有评论(0)