【大数据实验】熟悉常用的 HBase 操作
实验目的理解 HBase 在 Hadoop 体系结构中的角色熟练使用 HBase 操作常用的 Shell 命令熟悉 HBase操作常用的 Java API实验平台操作系统:Ubuntu 16.04Hadoop 版本:3.1.3HBase 版本:2.2.2JDK 版本:1.8Java IDE:Eclipse实验内容和要求1.编程实现以下指定功能,并用 Hadoop 提供的 HBase Shell 命
文章目录
实验目的
- 理解 HBase 在 Hadoop 体系结构中的角色
- 熟练使用 HBase 操作常用的 Shell 命令
- 熟悉 HBase操作常用的 Java API
实验平台
- 操作系统:Ubuntu 16.04
- Hadoop 版本:3.1.3
- HBase 版本:2.2.2
- JDK 版本:1.8
- Java IDE:Eclipse
注:实验需要开启hbase服务,开启顺序为先Hadoop → Hbase,关闭顺序为Hbase → Hadoop
实验内容和要求
1. 编程实现以下指定功能,并用 Hadoop 提供的 HBase Shell 命令完成相同任务:
(1) 列出 HBase 所有的表的相关信息,例如表名
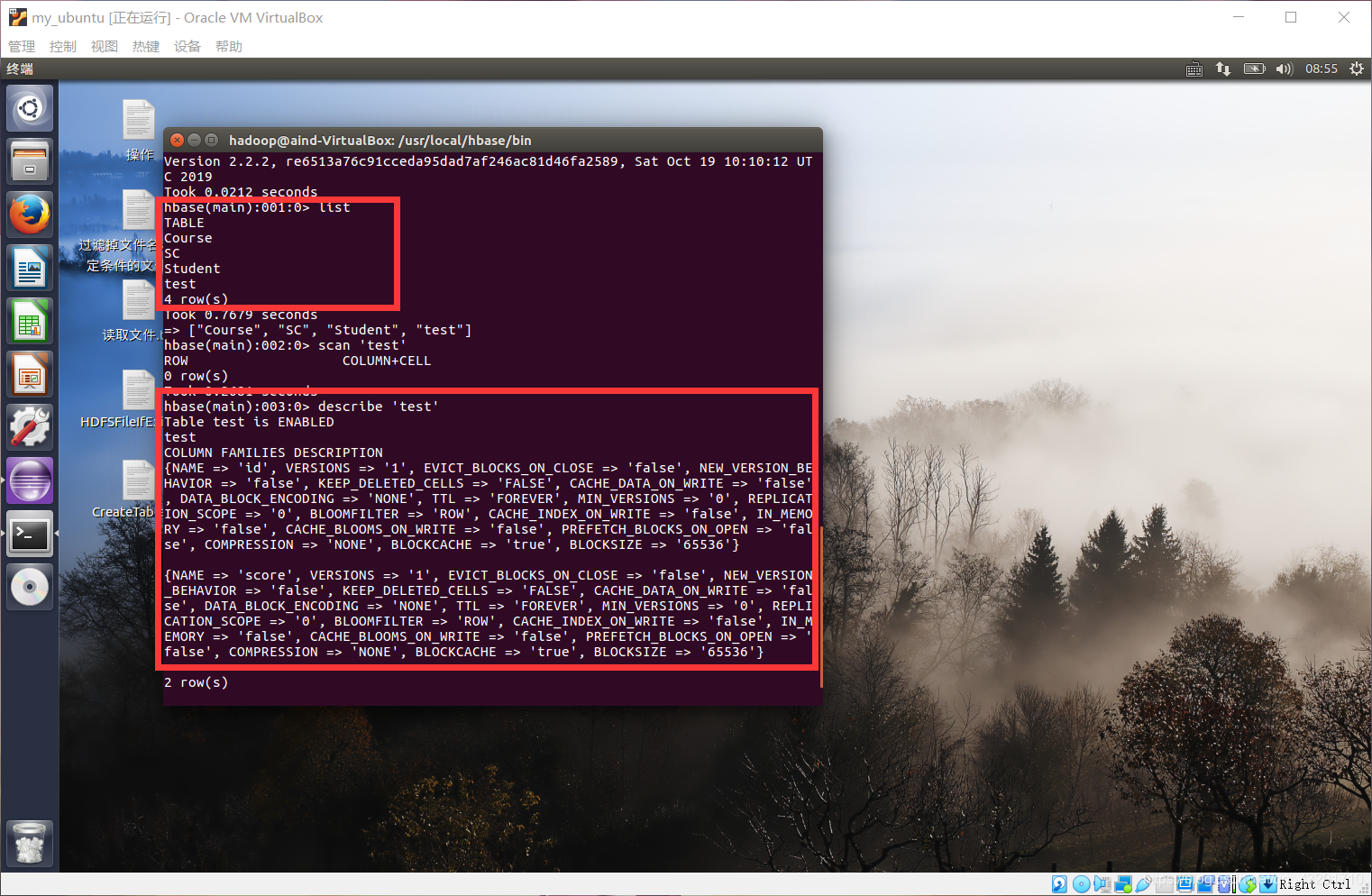
hbase(main):001:0> list
(2) 在终端打印出指定的表的所有记录数据
查看记录数据:
hbase(main):001:0> scan '表名'
查看表的信息:
hbase(main):001:0> describe '表名'
(3) 向已经创建好的表添加和删除指定的列族或列
添加列族或列:
hbase(main):001:0> alter '表名','NAME'=>'列名'
删除列族或列:
hbase(main):001:0> alter '表名','NAME'=>'列名',METHOD=>'delete'
(4) 清空指定的表的所有记录数据
hbase(main):001:0> drop '表名'
(5) 统计表的行数
hbase(main):001:0> count '表名'
2.现有以下关系型数据库中的表和数据,要求将其转换为适合于 HBase 存储的表并插入数据:
学生表:
| 学号 | 姓名 | 性别 | 年龄 |
|---|---|---|---|
| 2015001 | Zhangsan | male | 23 |
| 2015002 | Mary | female | 22 |
| 2015003 | Lisi | male | 24 |
课程表:
| 课程号 | 课程名 | 学分 |
|---|---|---|
| 123001 | Math | 2.0 |
| 123002 | Computer Science | 5.0 |
| 123003 | English | 3.0 |
选课表:
| 学号 | 课程号 | 成绩 |
|---|---|---|
| 2015001 | 123001 | 86 |
| 2015001 | 123003 | 69 |
| 2015002 | 123002 | 77 |
| 2015002 | 123003 | 99 |
| 2015003 | 123001 | 98 |
| 2015003 | 123002 | 95 |
创建三个表格
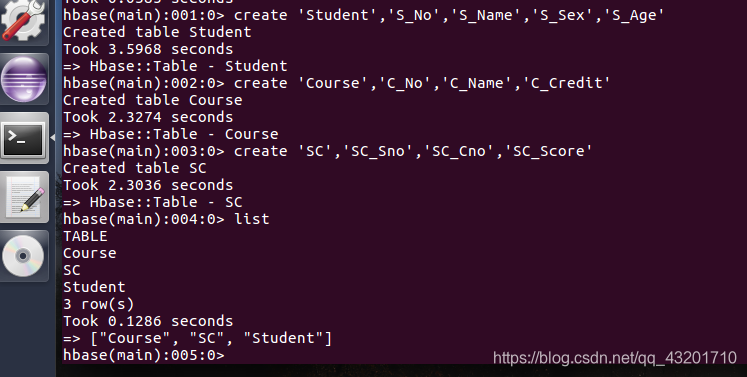
‘Student’表中添加数据
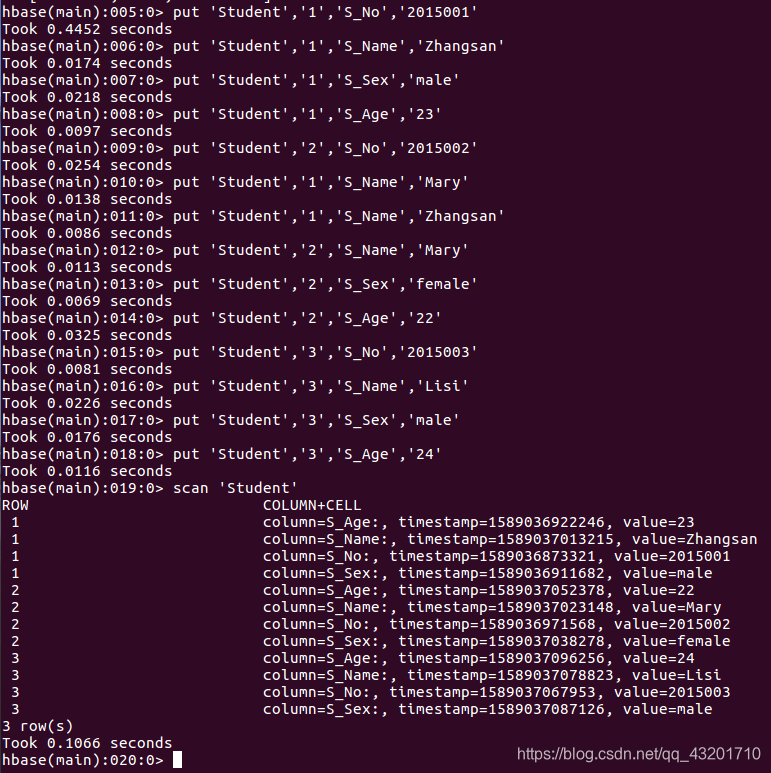
‘Course’表中添加数据
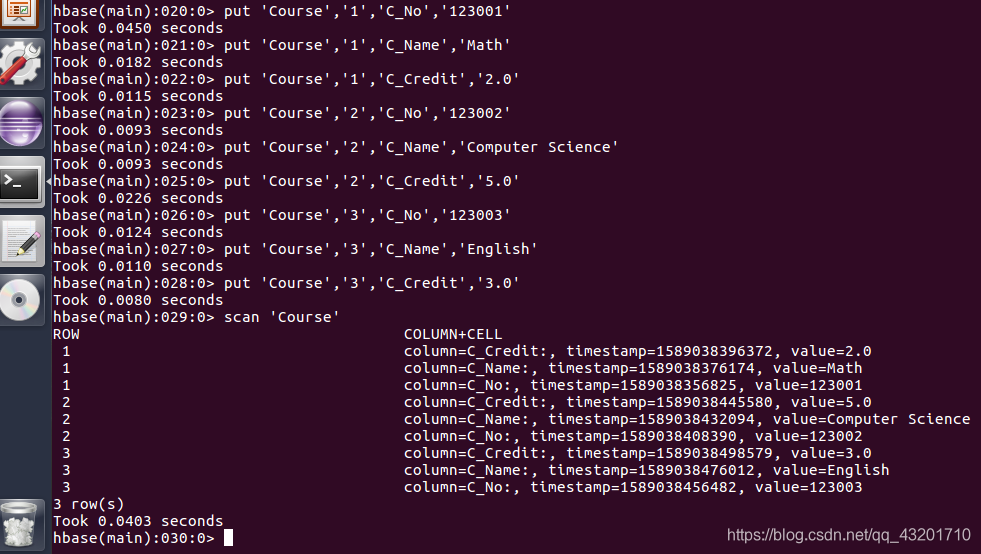
‘SC’表中添加数据
同时,请编程完成以下指定功能:
(1)createTable(String tableName, String[] fields)
创建表,参数 tableName 为表的名称,字符串数组 fields 为存储记录各个域名称的数组。要求当 HBase 已经存在名为 tableName 的表的时候,先删除原有的表,然后再创建新的表。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class CreateTable {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void init(){//建立连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch(IOException e){
e.printStackTrace();
}
}
public static void close(){//关闭连接
try{
if(admin != null){
admin.close();
}
if(connection != null){
connection.close();
}
}catch(IOException e){
e.printStackTrace();
}
}
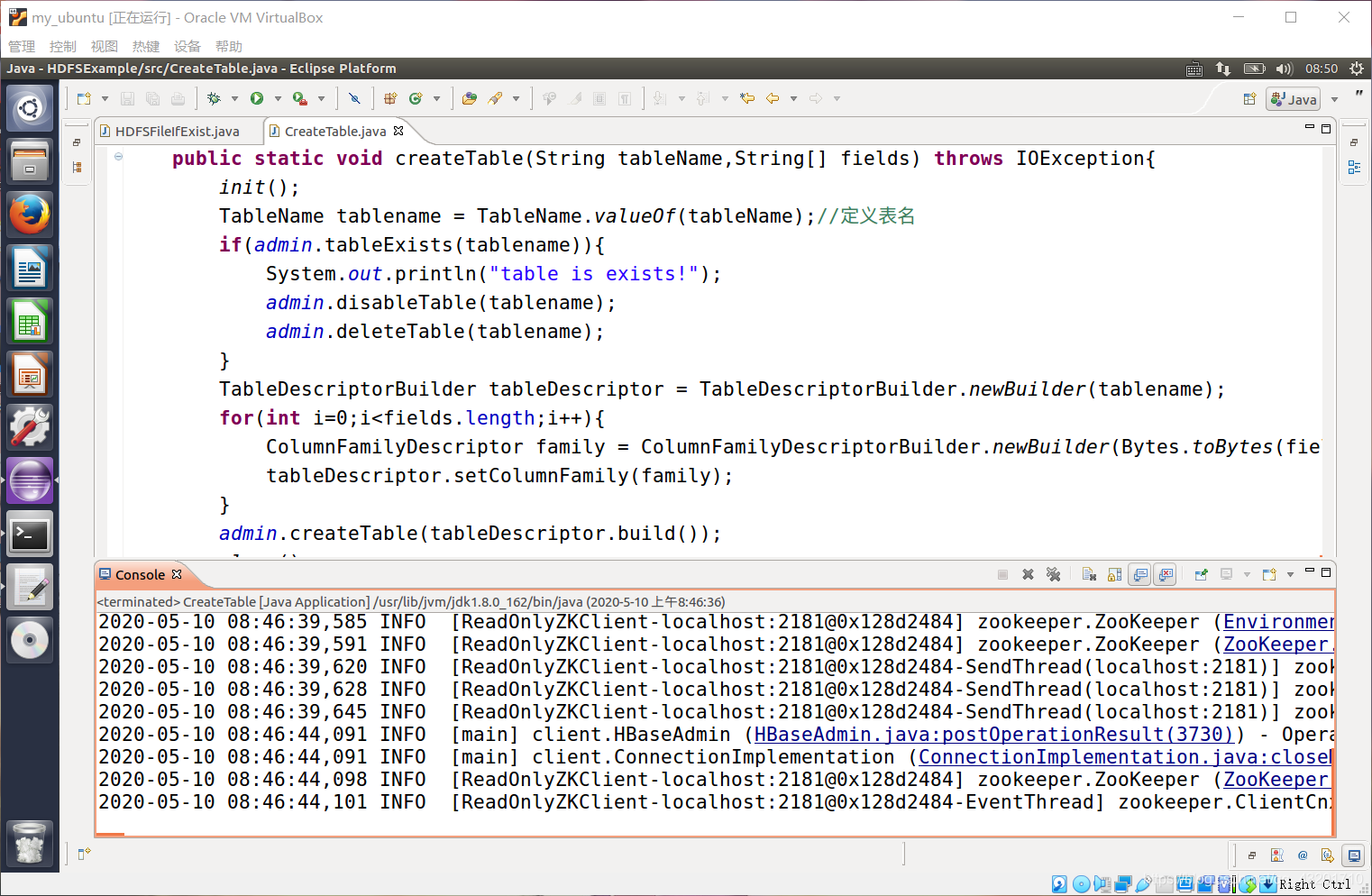
public static void createTable(String tableName,String[] fields) throws IOException{
init();
TableName tablename = TableName.valueOf(tableName);//定义表名
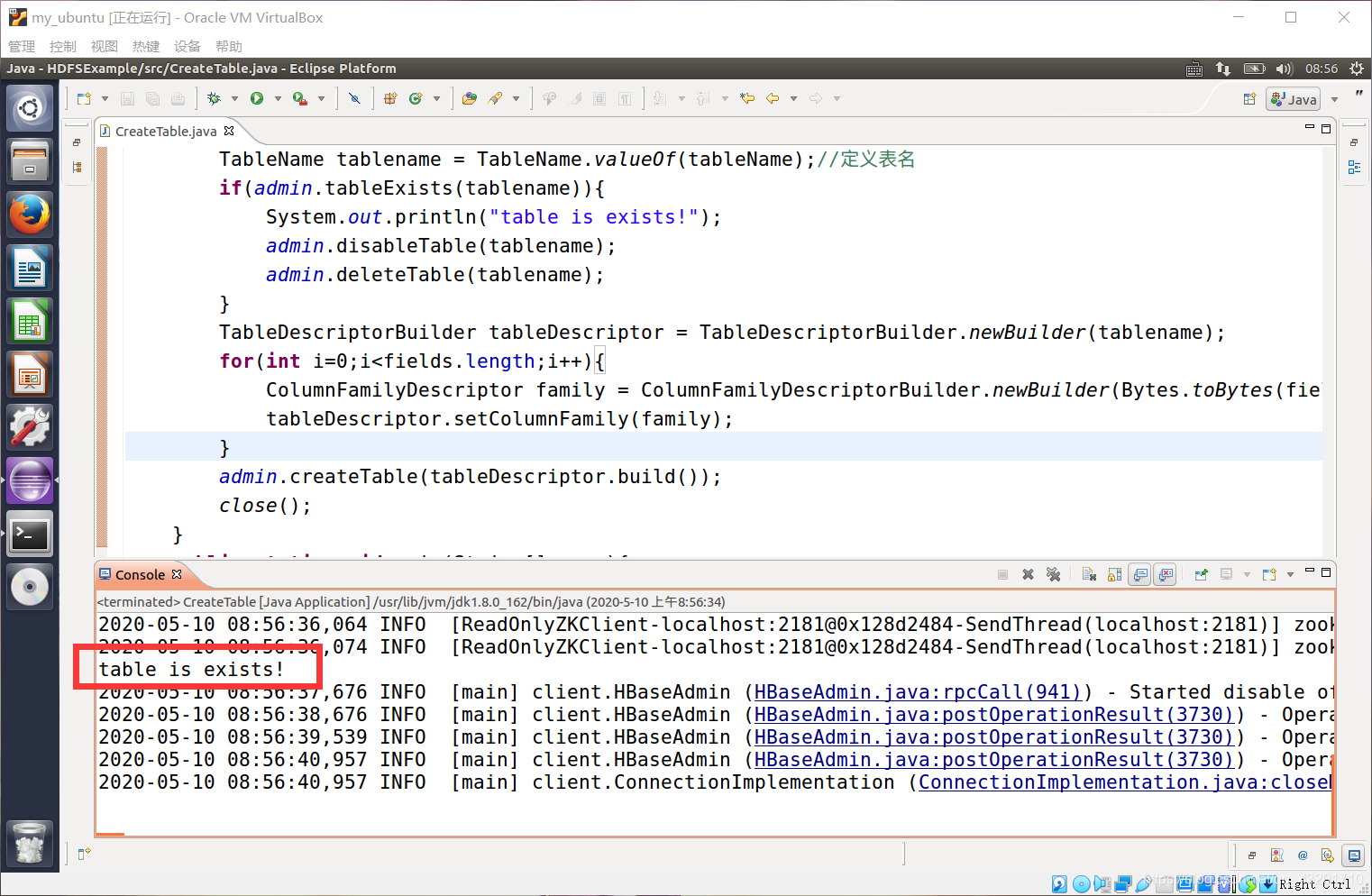
if(admin.tableExists(tablename)){
System.out.println("table is exists!");
admin.disableTable(tablename);
admin.deleteTable(tablename);
}
TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tablename);
for(int i=0;i<fields.length;i++){
ColumnFamilyDescriptor family = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(fields[i])).build();
tableDescriptor.setColumnFamily(family);
}
admin.createTable(tableDescriptor.build());
close();
}
public static void main(String[] args){
String[] fields = {"id","score"};
try{
createTable("test",fields);
}catch(IOException e){
e.printStackTrace();
}
}
}
(2)addRecord(String tableName, String row, String[] fields, String[] values)
向表 tableName、行 row(用 S_Name 表示)和字符串数组 fields 指定的单元格中添加对应的数据 values。其中 fields 中每个元素如果对应的列族下还有相应的列限定符的话,用 “columnFamily:column”表示。例如,同时向“Math”、“Computer Science”、“English” 三列添加成绩时,字符串数组 fields 为{“Score:Math”,“Score:Computer Science”, “Score:English”},数组 values 存储这三门课的成绩。
当向表添加数据时,我们需要一个Put对象,在Put对象之前我们需要获取Table对象,这样才能对指定的表进行操作
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
public class addRecord {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void init(){//建立连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch(IOException e){
e.printStackTrace();
}
}
public static void close(){//关闭连接
try{
if(admin != null){
admin.close();
}
if(connection != null){
connection.close();
}
}catch(IOException e){
e.printStackTrace();
}
}
public static void addRecord(String tableName,String row,String[] fields,String[] values) throws IOException{
init();//连接Hbase
Table table = connection.getTable(TableName.valueOf(tableName));//表连接
Put put = new Put(row.getBytes());//创建put对象
for(int i=0;i<fields.length;i++){
String[] cols = fields[i].split(":");
if(cols.length == 1){
put.addColumn(fields[i].getBytes(),"".getBytes(),values[i].getBytes());
}
else{
put.addColumn(cols[0].getBytes(),cols[1].getBytes(),values[i].getBytes());
}
table.put(put);//向表中添加数据
}
close();//关闭连接
}
public static void main(String[] args){
String[] fields = {"Score:Math","Score:Computer Science","Score:English"};
String[] values = {"90","90","90"};
try{
addRecord("grade","S_Name",fields,values);
}catch(IOException e){
e.printStackTrace();
}
}
}
由于没有创建这个表,所以只贴出代码,不再实验。
(3)scanColumn(String tableName, String column)
浏览表 tableName 某一列的数据,如果某一行记录中该列数据不存在,则返回 null。要求当参数 column 为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;当参数 column 为某一列具体名称(例如“Score:Math”)时,只需要列出该列的数据。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class scanColumn {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void init(){//建立连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch(IOException e){
e.printStackTrace();
}
}
public static void close(){//关闭连接
try{
if(admin != null){
admin.close();
}
if(connection != null){
connection.close();
}
}catch(IOException e){
e.printStackTrace();
}
}
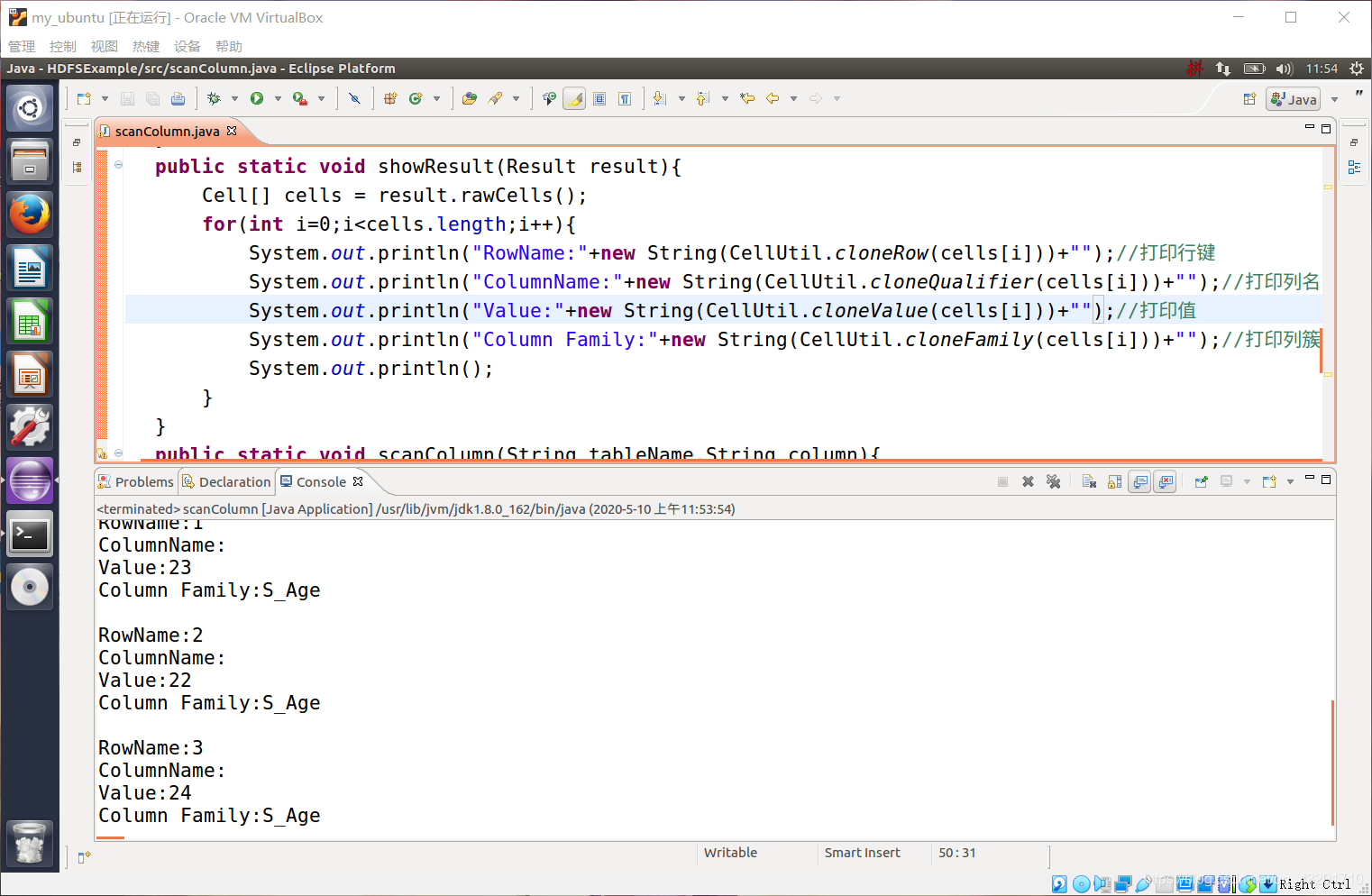
public static void showResult(Result result){
Cell[] cells = result.rawCells();
for(int i=0;i<cells.length;i++){
System.out.println("RowName:"+new String(CellUtil.cloneRow(cells[i])));//打印行键
System.out.println("ColumnName:"+new String(CellUtil.cloneQualifier(cells[i])));//打印列名
System.out.println("Value:"+new String(CellUtil.cloneValue(cells[i])));//打印值
System.out.println("Column Family:"+new String(CellUtil.cloneFamily(cells[i])));//打印列簇
System.out.println();
}
}
public static void scanColumn(String tableName,String column){
init();
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(column));
ResultScanner scanner = table.getScanner(scan);
for(Result result = scanner.next();result != null;result = scanner.next()){
showResult(result);
}
} catch (IOException e) {
e.printStackTrace();
}
finally{
close();
}
}
public static void main(String[] args){
scanColumn("Student","S_Age");
}
}
(4)modifyData(String tableName, String row, String column)
修改表 tableName,行 row(可以用学生姓名 S_Name 表示),列 column 指定的单元格的数据。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
public class modifyData {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void init(){//建立连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch(IOException e){
e.printStackTrace();
}
}
public static void close(){//关闭连接
try{
if(admin != null){
admin.close();
}
if(connection != null){
connection.close();
}
}catch(IOException e){
e.printStackTrace();
}
}
public static void modifyData(String tableName,String row,String column,String value) throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(row.getBytes());
String[] cols = column.split(":");
if(cols.length == 1){
put.addColumn(column.getBytes(),"".getBytes(), value.getBytes());
}
else{
put.addColumn(cols[0].getBytes(), cols[1].getBytes(), value.getBytes());
}
table.put(put);
close();
}
public static void main(String[] args){
try{
modifyData("Student","1","S_Name","Tom");
}
catch(Exception e){
e.printStackTrace();
}
}
}
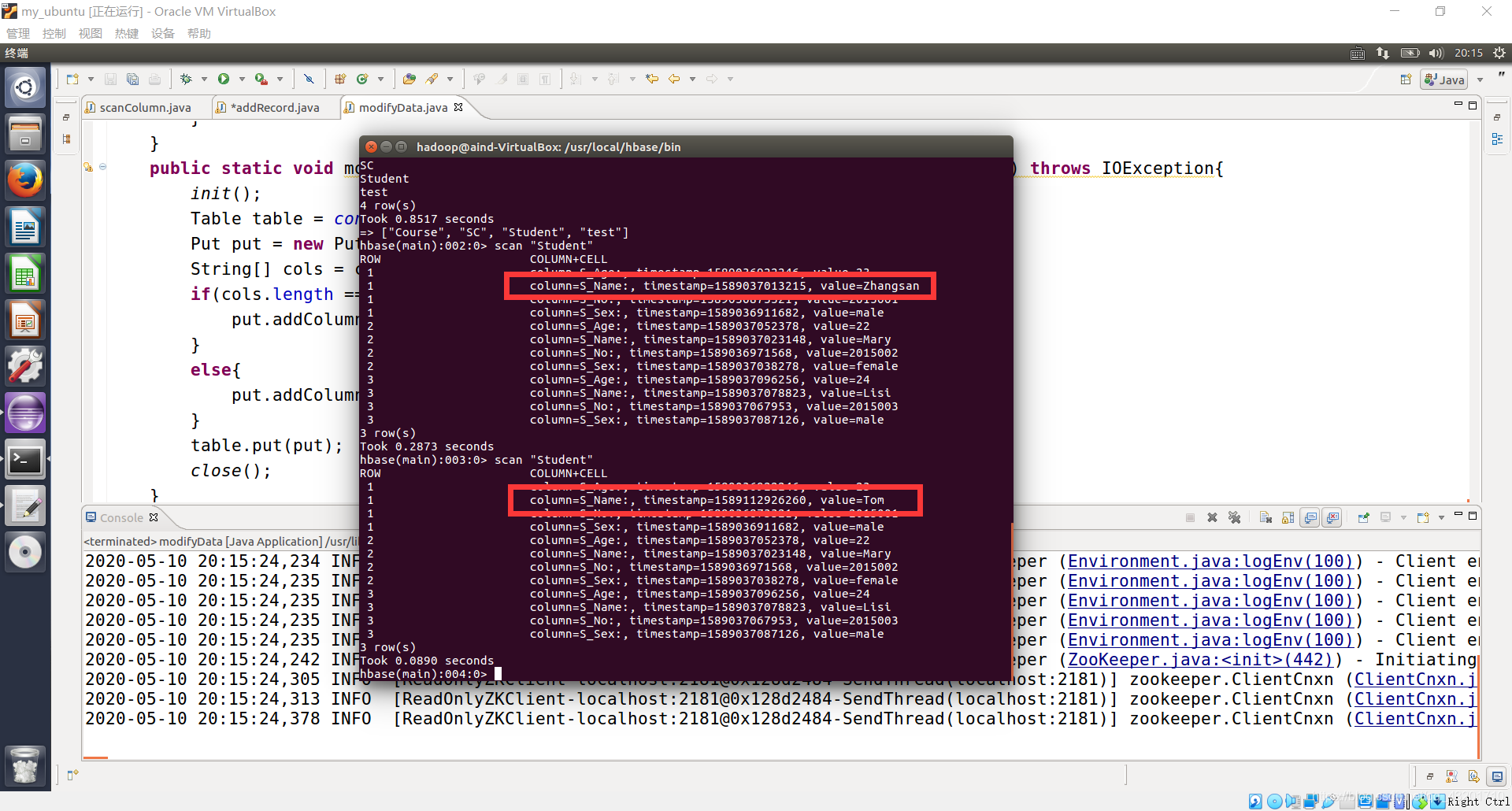
(5)deleteRow(String tableName, String row)
删除表 tableName 中 row 指定的行的记录。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Table;
public class deleteRow {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void init(){//建立连接
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch(IOException e){
e.printStackTrace();
}
}
public static void close(){//关闭连接
try{
if(admin != null){
admin.close();
}
if(connection != null){
connection.close();
}
}catch(IOException e){
e.printStackTrace();
}
}
public static void deleteRow(String tableName,String row) throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(row.getBytes());
table.delete(delete);
close();
}
public static void main(String[] args){
try{
deleteRow("Student","3");
}catch(Exception e){
e.printStackTrace();
}
}
}
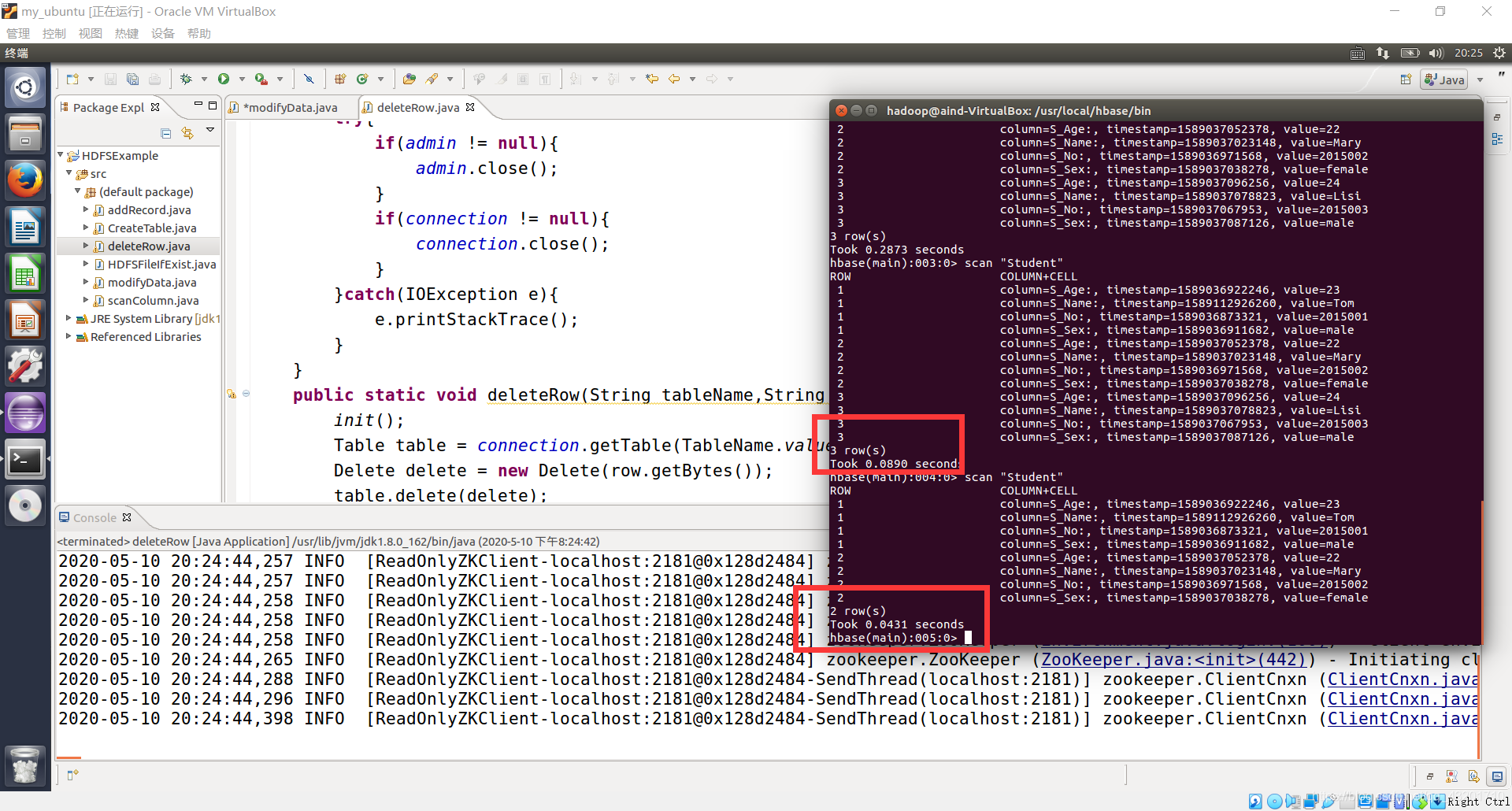
3. 利用 HBase 和 MapReduce 完成如下任务:
假设 HBase 有 2 张表,表的逻辑视图及部分数据如下所示:
| 书名(bookName) | 价格(price) |
|---|---|
| Database System Concept | 30$ |
| Thinking in Java | 60$ |
| Data Mining | 25$ |
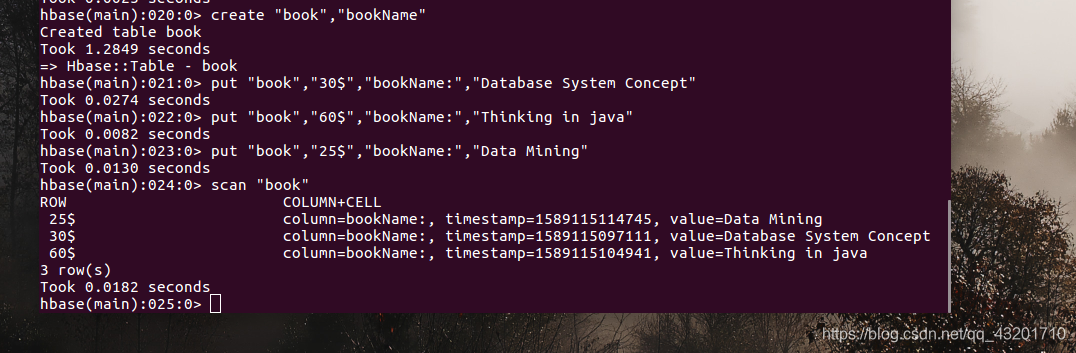
创建表格
create "book","bookName
添加数据put "book","30$","bookName:","Database System Concept"put "book","60$","bookName:","Thinking in Java "put "book","25$","bookName:","Data Mining "
查看表格scan "book"//表格默认根据keyRows按字典顺序排序

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 57
57 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)