HMM算法在语音识别中的应用——算法学习
总体框架输入Treat acoustic(听觉的) input O as sequence of individual observationsO=o1,o2,...,otO=o_1,o_2,...,o_t结果Define sentence as a sequence of wordsW=w1,w2,...,wnW=w_1,w_2,...,w_n判断模型最大概率:W=arg maxW∈L
·
总体框架
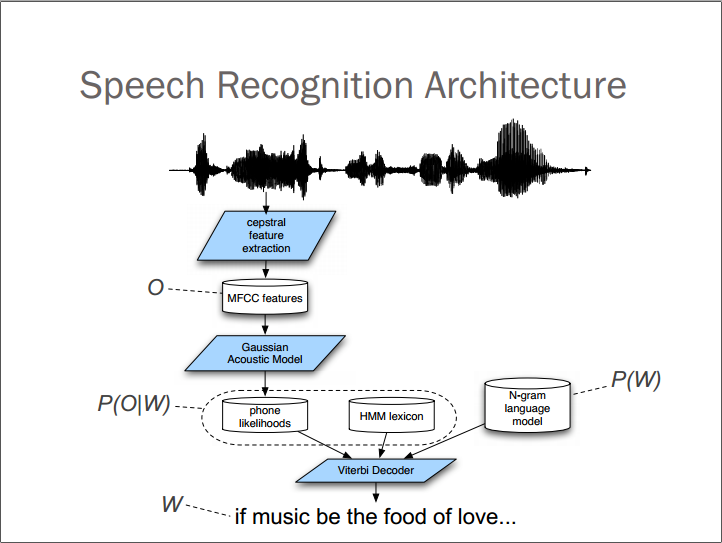
输入
Treat acoustic(听觉的) input O as sequence of individual observations
O=o1,o2,...,ot
结果
Define sentence as a sequence of words
W=w1,w2,...,wn
判断模型
- 最大概率: W=arg maxW∈L P(W|O)
- 贝叶斯: W=arg maxW∈L P(O|W)P(W)P(O)
- 化简:由于
P(O)
对所有
W
一样,
W=arg maxW∈L P(O|W)P(W)
模型
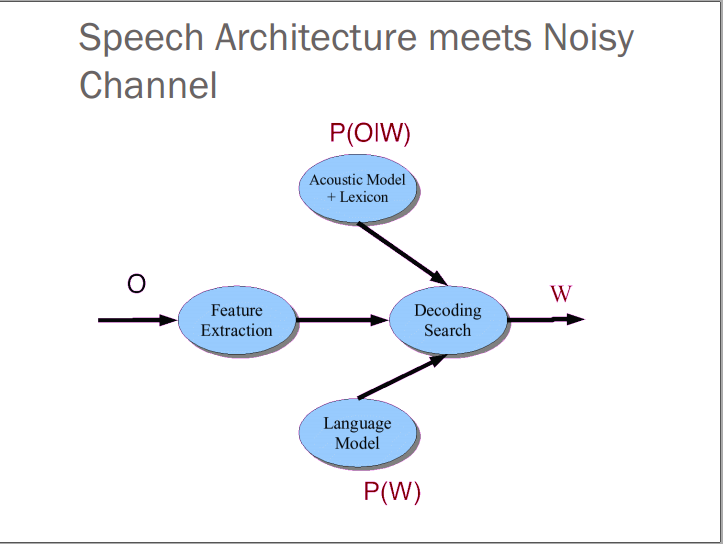
- Feature Extraction: 39 “MFCC” features
- Acoustic Model: Gaussians for computing p(o|q)
Lexicon(词典)/Pronunciation(发音) Model: HMM, what phones can follow each other
- Language Model: N-grams for computing p(wi|wi−1)
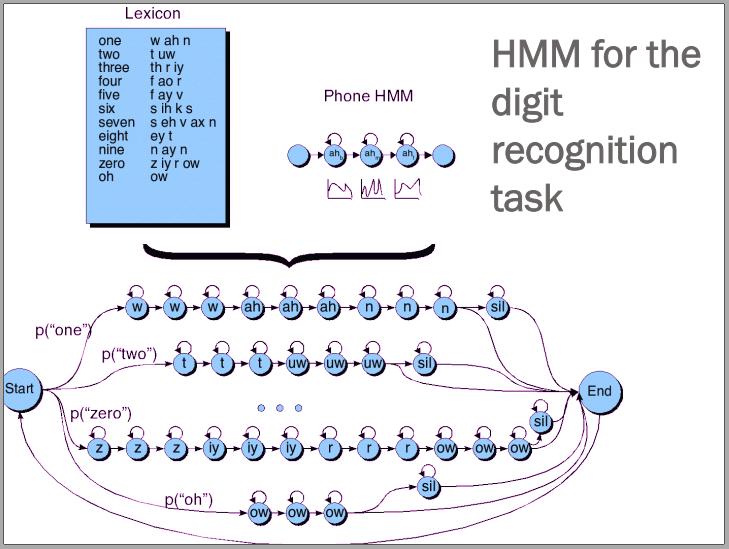
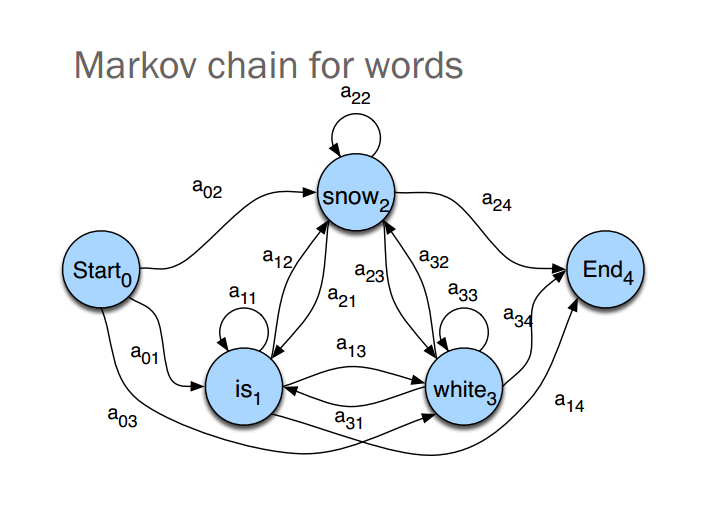
markov chian
- states: Q=q1,q2,...,qN , qt is the state at time t.
- transition probability:
A=[a11,a12,...,aNN]
- aij is the probability of trasition from i to j.
- aij=P(qt−1=i|qt=j)
- ∑Nj=1aij=1 , for i∈[1,N]
- markov assumption:
- P(qi|q1q2...qi−1)=P(qi|qi−1)
- initial status
- πi=P(q1=i)
- ∑Nj=1πj=1
hidden markov chian

three problem

thrid problem



以上所有内容从以下附件中抽取

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)