Web开发须知的浏览器内幕 缓存与存储篇(1)
本文禁止转载,由UC浏览器内部出品。
0.前言
大纲
浏览器缓存和存储相关的功能分为四类:
- 加载流程
- Memory Cache
- Application Cache(简称AppCache)
- HTTP Cache
- Cookie Storage
- Javascript API
- Web Storage
- Indexed Database
- File API
- Cache Storage(Service Worker的核心功能)
- Filesystem API
- Quota Management API
- 前进后退
- Page Cache(Back-Forward Cache)
- History
- 保存网页
术语表
| 英文 | 中文意思 | 解释 |
|---|---|---|
| Resource | 资源 | 所有的网络文件都称为资源,HTML文档、CSS、javascript、图片等 |
| Loader | 加载器 | 浏览器中负责加载资源的模块 |
| net module/library | 网络库 | 负责网络IO的模块,可简单理解为HTTP协议的实现者 |
| Layout Engine | 排版引擎 | 负责HTML解析和加载控制的模块,在WebKit时期,它被称为渲染引擎Render Engine |
1. Cache综述
浏览器排版引擎中负责加载资源流程的模块,我们称之为Loader。在Chromium中,Loader被更细化为负责控制由HTML标准(包括HTML标签和Javascript)发起的各种资源加载过程,实际的网络IO由专门的网络模块负责,而在网络模块和Loader之间还有一层叫做fetch。fetch仍属于排版引擎,和网络模块之间是隔开层次的。对前端来说仅需知道fetch里面包含Memory Cache作为第一级缓存。Loader是依次按不同条件从Memory Cache、AppCache、HTTP Cache里获取已缓存的资源的,拿不到才会去下一种Cache里找。
// javascript伪码描述的加载过程
function loadResource(request) {
CookieStorage.addCookieIfMatch(request);
if (MemoryCache.containsValidCache(request)) {
return MemoryCache.fetch(request);
} else if (request.isFromAppCache) {
if (AppCache.containsValidCache(request)) {
return AppCache.fetch(request);
} else {
return AppCache.loadFromNetworkThenStore(request);
}
} else if (HttpCache.containsValidCache(request)) {
return HttpCache.fetch(request);
} else {
return NetworkTransaction.fetch(request);
}
}其中,Memory Cache缓存的数据是始终保存在内存中的,AppCache和HTTP Cache都是在磁盘中。这个设计就是模仿CPU-内存-磁盘外存这三者。
磁盘属于外部设备,CPU不能直接访问硬盘上的数据,要先将硬盘上的数据读取到内存,然后CPU访问内存上的数据。Loader和CPU一样,无论是从网络还是从磁盘缓存加载,得到的数据都先组织好放在内存再继续其它操作。后续如果还要操作这些资源,就可能是直接访问内存中的备份,以达到极高的性能。
HTTP Cache如其名,属于HTTP(S)协议的数据流缓存,是排版引擎外的网络模块的一部分,数据存于磁盘。AppCache和HTTP Cache在磁盘缓存这部分的实现是一样的,只是根据规范而有不同的进出条件。从规范也可知,优先判断是否走AppCache。
下面是Cache中的数据流:
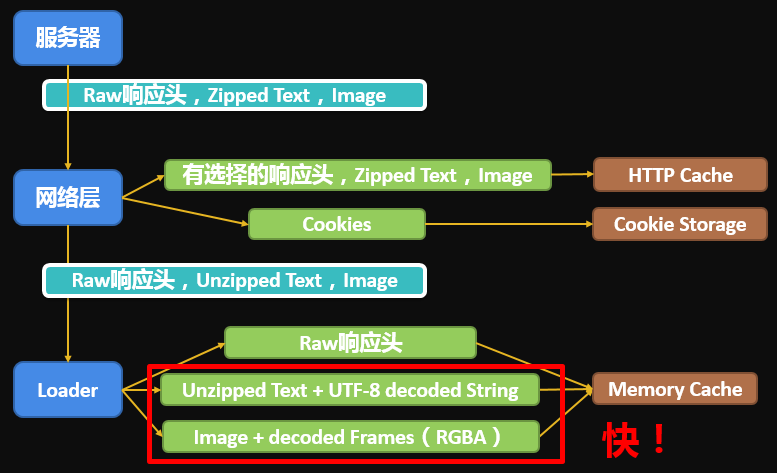
(不好意思,图懒得搞得好看些)
从图中可以看到,Memory Cache会连同解码后的数据一同缓存,所以特别地快。
由于AppCache是由HTML标签里的manifest属性来操控的,属主动行为,所以暂不在Cache这一章中叙述。
无论哪种Cache,都是以URL为key做映射关系来判断是否缓存有响应数据。
在隐身窗口,Chromium是不会把任何资源写入磁盘的,所有的信息都放在内存中。但是其它浏览器,为了追求一定的用户体验,会使用HTTP Cache来存取部分资源。这就要求有一定的算法,既能保护隐私又能复用缓存。
2 Memory Cache
综述
Memory Cache不是任何规范要求这么做的,是浏览器的优化,但为了实现规范又自然而然需要这么做。因为浏览器窗口随时可能需要重绘,例如改变窗口大小、改变滚动条位置或JS修改DOM等,那么当前网页的所有资源都必须保留在内存中才能迅速响应,也就是不跳出当前网页,其所有资源都需要缓存在内存中。把这种缓存按一定算法在超出需要的时期仍保留,就成了Memory Cache。
因为Memory Cache仍属于排版引擎,数据可以被Loader直接使用,所以是最高效的Cache。根据HTTP协议,如果资源被设置成很快过期,那么过期以后即使Memory Cache存有备份,还是会向下一级Cache索取资源的。
除了过期,缓存是否可用还有一些条件,例如:method和body相同、安全政策相同(允许使用Cookie或凭证与否)、大部分的Header相同等。还有其它一些考虑,不一一列出了,但基本都有相关的规范来描述,且随着HTML5功能的增加还在扩充中。稍微一提是,如果这个资源Revalidation后仍可用(HTTP GET 304),也还是用内存的缓存,不是先淘汰再从磁盘拿。
Chromium的代码参考:
RawResource::canReuse()
ResourceFetcher::determineRevalidationPolicy()
内容
缓存的是原始数据和解码后数据。其中文本经过了UTF-8解码,图片会被解码成RGBA序列。
容量
Memory Cache的实现中有个重要的概念:当前页面用到的资源称为活动资源,离开当前页面后,在新页面没用到的资源都变成非活动资源。Memory Cache是对非活动资源是有限制的,容量为8MB,这包括原始数据和解码后的数据。对活动资源则无任何限制,并不会说不可见就释放掉。所以普通的无限滚动网页迟早会用尽内存,导致浏览器卡顿甚至crash。前端需要做的一个改进就是动态释放元素。当元素距离可视区域较远时,移出DOM Tree且无任何引用。或者简单地把img标签的src属性改名为src-src(可随意)属性即可。
淘汰
淘汰算法:LRU-SP(Size-adjusted and Popularity-aware extension to Least Recently Used),即加入资源大小的考虑再进行“最近使用”淘汰。可参考此文
http://www.is.kyusan-u.ac.jp/~chengk/pub/papers/compsac00_A07-07.pdf
命中率
无论哪种Cache,命中率都是性能指标之一。对Memory Cache来说即非活动资源被使用的比例。从前面几节的信息可知,命中率的自然增长一般需要用户持续在同一个网站内浏览,因为同网站的资源复用率最高,例如引用的jQuery URL都一样。
从这点出发可知,中小网站引用大流量网站的资源CDN是有一定的加速效果的。(CDN参考 http://www.jq22.com/cdn/)
按照统计,命中资源中的比例:图片 > JS > CSS。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)