电力项目中大数据技术的典型应用
典型业务场景
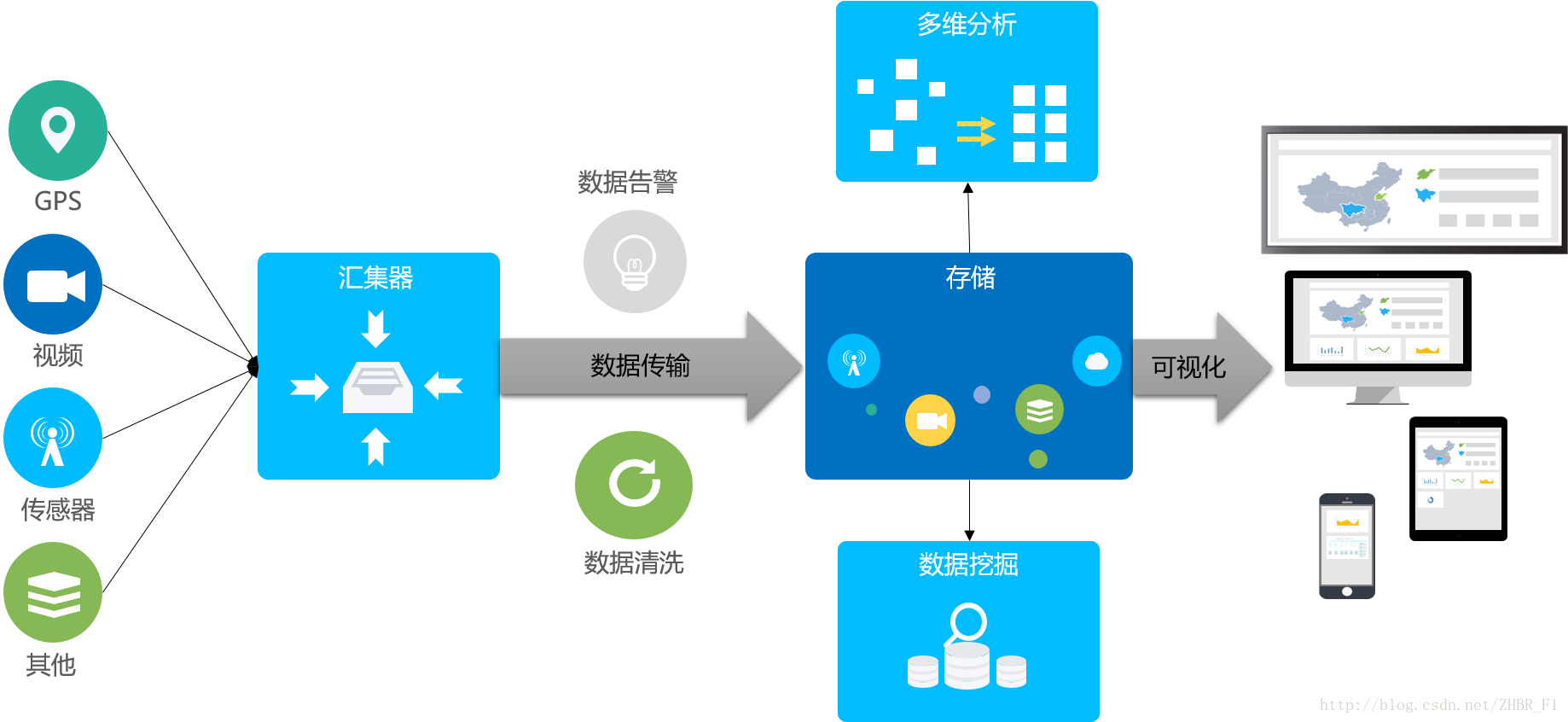
在电力行业项目甚至大多数工业项目中,都会涉及到对传感器等设备的采集数据进行存储和处理这一典型的业务场景,具体流程为:
- 将传感器的采集数据汇集到前置的汇集器
- 前置的汇集器将实时数据数据传输到数据处理中心
- 数据处理中心对传输过来的实时数据进行实时的清洗和告警
- 将实时数据和告警、计算数据一并存入持久化存储
- 对持久化存储中的数据进行多维分析与数据挖掘
- 对持久化存储中的数据进行可视化展示
如图所示:
可用技术
根据采集数据接入和处理这一典型的业务场景,我们针对每个环节列举了一些常用的技术。
数据传输
由于实际情况下,可能存在多个数据源,所以需要使用消息队列对实时数据进行汇总,这样可以实现数据生产与消费之间的解耦。除了解耦外,消息队列还提供了流量削峰的功能,以防止异常的流量过大导致下游处理程序崩溃。
常见的消息队列如下:
- RabbitMQ
- ZeroMQ
- ActiveMQ
- Kafka
实时处理
实时处理传统的方式是使用Java程序,当数据量较大的时候可以考虑使用流处理框架。常见的实时处理方式如下:
- Java程序
- Apache Storm
- Apache Samza
- Spark Streaming
- Apache Flink
数据落地
对于大量采集数据的写入,使用关系型数据库性能肯定是达不到要求的。可以考虑使用分布式数据库或分布式文件系统。常用的持久化存储如下:
- 实时数据库(比如pi,庚顿)
- Apache HBase
- OpenTSDB
- Cassandra
- Hive /HDFS
离线处理
除了可以用普通Java程序进行离线处理,还可以使用批处理方式的数据处理框架进行处理,常用的数据处理方式如下:
- Java程序
- MapReduce
- Spark
在线分析
对数据进行在线分析需要提供SQL或类SQL接口。常用的在线分析工具如下:
- Apache Hive
- Spark SQL
- Presto
列举了每个环节的可选的技术之后,我们来结合两个具体案例浅谈一下在这种典型业务场景下的技术选型。
配用电系统采集数据处理
这个实例是某配用电系统中设备采集数据处理部分,主要采用Java程序的方式来进行数据处理。结构图如下: 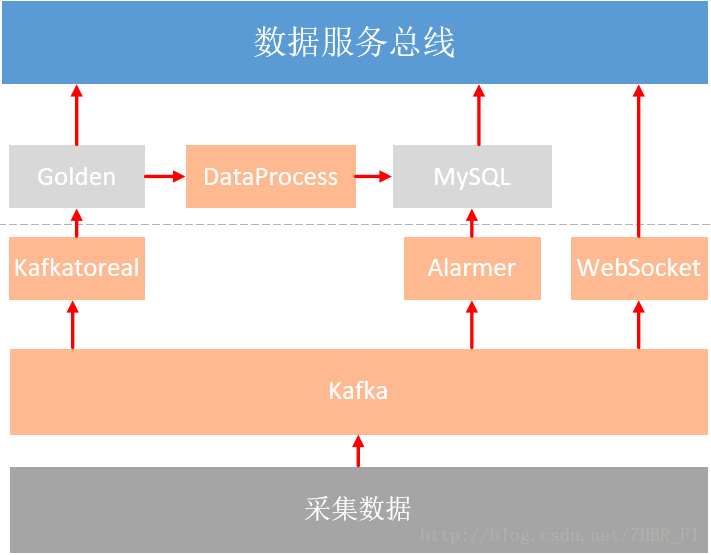
将采集上来的数据存入消息队列中,经过不同的处理程序处理过后存入持久化存储并提供给上层调用。
设计思路
消息队列——Apache Kafka
由于实际情况下,可能存在多个数据源,所以需要使用消息队列对实时数据进行汇总,这样可以实现数据生产与消费之间的解耦。除了解耦外,消息队列还提供了流量削峰的功能,以防止异常的流量过大导致下游处理程序崩溃。
常见的消息队列如下:
- RabbitMQ
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了Broker构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。 - ZeroMQ
ZeroMQ号称最快的消息队列系统,尤其针对大吞吐量的需求场景。但是ZeroMQ仅提供非持久性的队列,也就是说如果down机,数据将会丢失。 - ActiveMQ
ActiveMQ是Apache下的一个子项目。 类似于ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于RabbitMQ,它少量代码就可以高效地实现高级应用场景。 - Kafka
由linkedin公司开发的分布式消息队列,最初被设计用来传输日志信息。具有持久化存储、高吞吐、分布式、自动均衡负载、与Hadoop等大数据技术结合较好等特性。
由于设备的实时数据量非常大,对消息队列的吞吐率和读写速度有着较高要求。Kafka虽然没有实现JMS规范,但是在吞吐率和读写速度方面“吊打”其他MQ,所以本次测试中选用Kafka作为实时数据传输的消息队列。
实时数据存储——庚顿
在工业项目中,实时数据库被大量应用与传感器等设备的采集数据的存储,比较著名的实时数据库有OSIsoft公司的PI ,Wonderware公司的Industrial SQL等,不过价格都较为昂贵。基于成本和性能的综合考量,我们使用了国内的实时数据库庚顿(Golden)。
统计数据——MySQL
在项目中需要将实时数据定时进行计算和统计,提供给上层业务进行查询。统计数据我们选择了用MySQL进行存储。
处理程序
在配用电系统中,采集数据处理模块全部的处理逻辑全部在普通Java程序中实现。下面简述每个处理程序的主要逻辑。
- KafkaToReal
KafkaToReal模块主要将Kafka中的实时数据存入实时数据库中。
- Alamer
拉取Kafka中的数据进行计算,根据特定的告警规则触发告警,并将告警信息写入Kafka和MySQL中。
- DataProcess
定时对实时数据库中的数据进行计算,并将结果存入MySQL中。
- WebSocket
拉取Kafka中的实时数据,并向注册了推送服务的Web页面推送实时数据。
未来的问题
目前这套技术选型已经很好的完成了当前的项目需求,但是从长远的目光看,随着数据量的增长,这套数据处理技术存在一个比较大的问题:难以横向扩展。即随着数据量的增长,不能简单的依靠增加服务器数量的而完成处理能力的增长。这也推动了我们进行下一个例子中的那些大数据技术的研究。
而既然存在难以横向扩展的问题,为什么我们还要选用当前这套技术选型呢?主要原因有二:
- 数据量不大
当前数据量并未达到单机无法处理的级别,采用当前技术选型完全可以处理。 - 降低人力成本
引入大数据技术将提升开发的复杂度,提升开发成本。而且维护大数据集群也会给运维人员造成较大的困难。
在这里也体现了我们进行技术选型时的思路:杀鸡不用牛刀。当单机可以处理的时候,尽量使用单机处理技术。当简单的技术可以实现的时候,尽量不引入复杂技术。
风电场机组采集数据处理
业务需求
- 将采集到的设备的实时数据存入持久化存储
- 对数值超出上下限的测点进行实时告警
- 计算采集数据不同时间段内的均值,一并存入持久化存储
- 对持久存储中的数据提供类SQL查询
技术选型
根据以上需求,大数据组提出了使用Apache Kafka、Apache Spark等技术的解决方案,如图所示:
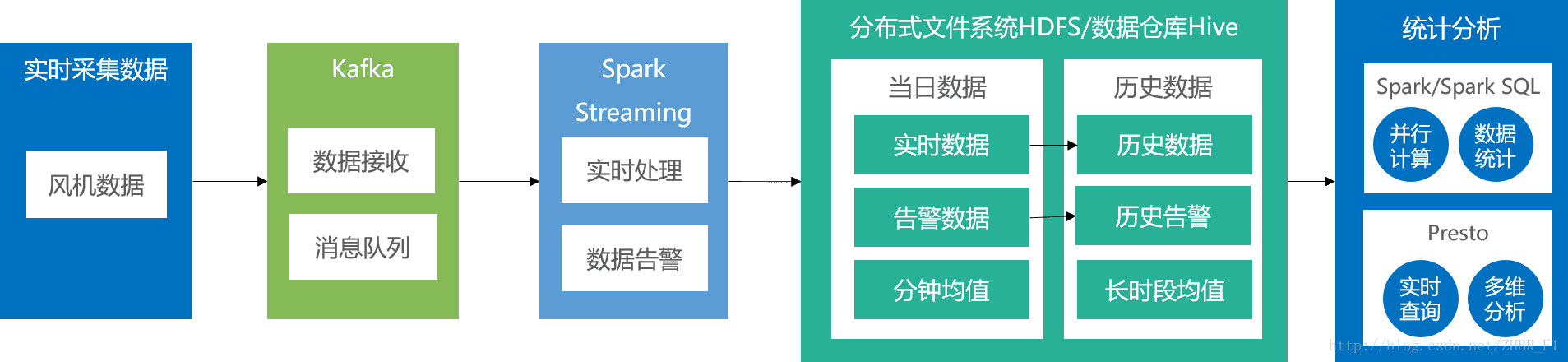
测试结果
- 实时数据落地:流处理框架负责实时数据落地、实时告警和分钟均值计算。实际可以处理每秒2600台设备。
- 离线SQL查询:使用Presto进行count查询,实际运行时间 <50s。
测试的详细细节请参考我的另一篇博客:使用大数据技术处理风电场机组采集数据
设计思路
消息队列——Apache Kafka
同上个例子。
数据处理框架——Apache Spark
数据处理框架被用来对海量数据进行处理。按照处理数据的方式和时效性,处理框架分为批处理框架和流处理框架,下面简单介绍它们的适用场景:
- 批处理框架
批处理框架主要用于计算数据量巨大,而对时延要求不高的数据。目前真正海量的数据(比如TB甚至PB级)只能选择批处理框架来处理。 - 流处理框架
流处理框架所能处理的数据量不如批处理框架大,一般认为精确度也没有批处理框架高。但是流处理框架的时效性很好,可以实时或近实时的展示处理结果。
接下来分别介绍几种常用的数据处理框架
批处理框架
- Apache Hadoop(MapReduce)
Hadoop是专用于批处理的处理框架,特点是可以部署在廉价的集群上,具有高容错性。不同于其他处理框架对于内存较大的需求,Hadoop计算时会消耗较多的硬盘资源,但由于硬盘资源是服务器上最廉价的资源,所以使用Hadoop的成本较低。但缺点是计算较慢。
流处理框架
- Apache Storm
Storm是经典的流处理框架,处理方式是逐项处理,可以实现毫秒级延迟,但不支持原生的时间窗口。虽然使用Trident可以以微批次的方式实现时间窗口,但性能会受到较大影响。 - Apache Samza
同Kafka一样由linkedin公司开发并开源,底层使用Kafka的存储和数据管理方式,自身仅提供API。同Storm一样可以逐项处理。优点是与Kafka紧密结合,很适合有多个团队需要使用(但相互之间并不一定紧密协调)不同处理阶段的多个数据流。
混合框架:批处理+流处理
除了批处理框架和流处理框架,还有一种框架即可以进行批处理,也可以进行流处理,它们被称为混合框架。混合框架主要有Spark和Flink。
- Apache Spark
Spark的批处理方式类似于MapReduce,但Spark提供了更加友好的编程模型,执行效率也更加高效。不过与此同时Spark需求更多的内存资源,所以硬件成本相对Hadoop更高。
Spark的流处理库称为Spark Streaming,Spark Streaming采用微批次(micro-batch)架构,即把一小段时间内的数据流当做一个批次来处理。这样做的缺点是只能实现秒级延迟,但优点是支持原生的时间窗口。 - Apache Flink
同为混合框架的Flink与之前介绍的Spark在思想上有本质的不同——Spark把流当做一个个微批次来处理,而Flink则把批处理当成有限的流来处理。由于Flink流处理优先的架构,所以Flink更适合于大量流处理和少量批处理的应用场景。
由于测试中需要同时使用流处理框架(实时告警、分钟均值计算)和批处理框架(小时均值、日均值、月均值),所以优先选择混合处理框架。Flink是新型的处理框架,目前还没有大型企业成功的商用案例,而Spark相比Flink更成熟,社区也更加活跃,所以选用Spark作为实时计算和离线计算的数据处理框架。
持久化存储——HDFS
HDFS全称为Hadoop Distributed File System(Hadoop分布式文件系统)。HDFS可以部署在廉价的服务器集群上,并且具有可以横向扩展、高容错、高吞吐等特点,非常适合大规模数据集的应用场景。事实上,HDFS是最主流的开源分布式文件存储系统。因为其高吞吐量、支持快速写入的特点,非常适合大量实时数据落地。
在测试过程中,我们分别尝试过HBase、OpenTSDB、Cassandra等数据库,发现落地性能均不理想,最后选择了HDFS。
数据仓库——Apache Hive
由Facebook研发并开源。Apache Hive是一个构建在Hadoop基础设施之上的数据仓库,可以使用类SQL语言HQL对HDFS/HBase上的数据进行查询。值得注意的是,Hive本身并不存储数据,数据仍然是存储在HDFS上的,Hive只是将HDFS上的数据以结构化表的形式呈现出来,在此项目中主要用来提供查询所需的元数据。
OLAP引擎——Presto
Presto与Hive一样,同样由Facebook公司研发并开源。使用Hive的元数据,提供类SQL方式查询。因为支持海量数据灵活的查询方式,通常用于即席查询。由于优化了查询引擎,其查询速度通常是Hive的十倍以上。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)