使用 Web Speech API 在浏览器中朗读文本
使用 Web Speech API 在浏览器中朗读文本开发者布道者 TwilioPhil Nash的这篇文章或这里是公共 Te 文章的日文版。Web Speech API有两个功能:语音合成(语音阅读)和语音识别(语音到文本的转换)。SpeechSynthesis API允许您在浏览器中选择语音并大声朗读任何文本。无论是应用程序中的语音警报还是网站上 Autopilot 驱动的聊天机器人的使用,W
Web Speech API有两个功能:语音合成(语音阅读)和语音识别(语音到文本的转换)。SpeechSynthesis API允许您在浏览器中选择语音并大声朗读任何文本。
无论是应用程序中的语音警报还是网站上 Autopilot 驱动的聊天机器人的使用,Web Speech API 都具有增强 Web 界面的巨大潜力。本节介绍如何在 Web 应用程序中执行语音朗读。
必要的东西
SpeechSynthesis 要了解 API 并构建此应用程序,您需要执行以下操作:
- 现代浏览器(此 API 受主要桌面和移动浏览器支持)
- 文本编辑器
准备好后,创建一个工作目录并将此 HTML 文件和此 CSS 文件下载到该目录。style.css确保这些文件在同一个文件夹中并且具有 CSS 文件的名称。当您在浏览器中打开 HTML 文件时,您将看到以下内容:
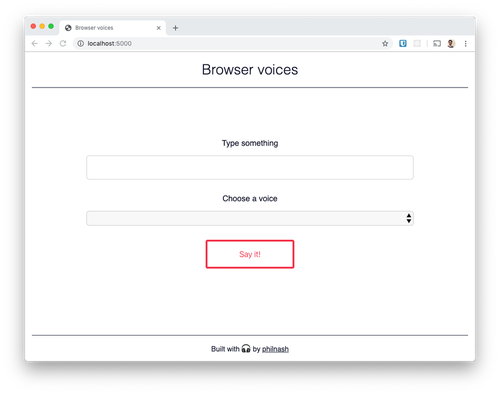
现在,让我们使用这个 API 在浏览器中朗读。
语音合成API
在您开始使用这个小应用程序之前,让我们尝试使用浏览器的开发工具大声朗读。在任意网页上打开开发工具控制台并输入以下代码。
speechSynthesis.speak(new SpeechSynthesisUtterance("Hello, this is your browser speaking."));
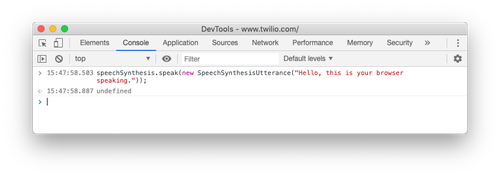
浏览器以默认语音显示“您好,这是您的浏览器正在讲话。 ”。让我们稍微改变一下。
在上面的示例中,SpeechSynthesisUtterance我们创建了一个包含要读取的文本的文本,并将其语音命令传递给speechSynthesis对象的speak方法。这将使语音命令排队以供阅读并在浏览器中开始阅读。如果speak您向该方法发送多个语音命令,它们将被依次读出。
现在让我们使用下载的启动代码将其转换为一个小应用程序,输入文本朗读并在浏览器中选择语音。
Web 应用程序中的语音合成
使用文本编辑器打开下载的 HTML 文件。首先,连接表单,以便在提交后大声朗读您输入的文本。稍后将添加选择音频的功能。
在 HTML 底部的<script>标签中DOMContentLoaded,监听事件并为所需元素选择一些引用。
<script>
window.addEventListener('DOMContentLoaded', () => {
const form = document.getElementById('voice-form');
const input = document.getElementById('speech');
});
</script>
然后监听表单上的提交事件,获取事件发生时输入的文本。从该文本SpeechSynthesisUtterance创建speechSynthesis.speak并将其传递给。最后,清空输入框并等待读取下一个文本。
<script>
window.addEventListener('DOMContentLoaded', () => {
const form = document.getElementById('voice-form');
const input = document.getElementById('speech');
form.addEventListener('submit', event => {
event.preventDefault();
const toSay = input.value.trim();
const utterance = new SpeechSynthesisUtterance(toSay);
speechSynthesis.speak(utterance);
input.value = '';
});
});
</script>
在浏览器中打开 HTML 并在输入中输入任何文本。此时<select>可以忽略该框。此框将在下一节中使用。输入“ Say it ”,然后在浏览器中听到朗读的短语。
在浏览器中朗读的文本就是这么简单,但是如果要选择语音呢?让我们在页面上设置一个可用音频列表的下拉列表,以便您可以选择它。
选择阅读文本的声音
<select>您需要获取对页面上元素的引用并初始化一些将用于存储可用和当前使用的音频的变量。将此添加到脚本的顶部。
```js hl_lines = 5 6 7
`````
接下来,我们需要捕获具有可用音频信息的 select 元素。创建一个新函数来执行此操作。这是因为它可以被多次调用(稍后会详细介绍)。speechSynthesis.getVoices()调用返回可用对象。SpeechSynthesisVoice
除了添加语音选项外,还需要检测当前选择的语音。如果您选择了音频,您currentVoice可以在对象中看到它。如果未选中,则voice.default属性可以检测默认音频。
let voices;
let currentVoice;
const populateVoices = () => {
const availableVoices = speechSynthesis.getVoices();
voiceSelect.innerHTML = '';
availableVoices.forEach(voice => {
const option = document.createElement('option');
let optionText = `${voice.name} (${voice.lang})`;
if (voice.default) {
optionText += ' [default]';
if (typeof currentVoice === 'undefined') {
currentVoice = voice;
option.selected = true;
}
}
if (currentVoice === voice) {
option.selected = true;
}
option.textContent = optionText;
voiceSelect.appendChild(option);
});
voices = availableVoices;
};
form.addEventListener('submit', event => { //... })
populateVoice可以立即调用。有些浏览器在加载音频页面后立即返回音频列表,但其他浏览器需要异步加载音频列表。加载完成后,将发出“声音已更改”事件。但是,某些浏览器不发布此事件。
populateVoices立即调用并将其设置为“voiceschanged”事件的回调以适应所有可能的场景。
voices = availableVoices;
};
populateVoices();
speechSynthesis.onvoiceschanged = populateVoices;
form.addEventListener('submit', event => { //... })
});
</script>
请重新加载页面。<select>该元素包含所有可用的音频(包括音频支持的语言)。稍后我们将讨论如何选择和使用音频。
监听 select 元素的“change”事件,并在事件发生时使用<select>元素的select 。selectedIndexcurrentVoice
populateVoices();
speechSynthesis.onvoiceschanged = populateVoices;
voiceSelect.addEventListener('change', event => {
const selectedIndex = event.target.selectedIndex;
currentVoice = voices[selectedIndex];
});
form.addEventListener('submit', event => { //... })
});
接下来,为了将特定语音与特定语音命令一起使用,您需要将创建的语音命令设置为语音。
form.addEventListener('submit', event => {
event.preventDefault();
const toSay = input.value.trim();
const utterance = new SpeechSynthesisUtterance(toSay);
utterance.voice = currentVoice;
speechSynthesis.speak(utterance);
input.value = '';
});
});
</script>
请重新加载页面并选择其他语音或阅读进行检查。
附加信息:构建可视化朗读指示器
现在我们已经构建了一个可以使用各种声音的语音合成功能,让我们添加另一个有趣的功能。许多由朗读命令发出的事件允许来自应用程序的语音响应。作为这个小应用程序的点睛之笔,让我们在浏览器读取语音时显示动画。我已经为动画添加了CSS。要启用此功能,<main>您需要在浏览器说话时向元素添加“说话”类。
<main>获取脚本顶部的元素引用。
<script>
window.addEventListener('DOMContentLoaded', () => {
const form = document.getElementById('voice-form');
const input = document.getElementById('speech');
const voiceSelect = document.getElementById('voices');
let voices;
let currentVoice;
const main = document.getElementsByTagName('main')[0];
您现在可以收听语音命令的开始和结束事件以添加或删除“说话”类。但是,如果我在动画中间删除类,动画不会平滑淡出。为此,必须使用“animationiteration”事件监听动画迭代结束,然后删除该类。
form.addEventListener('submit', event => {
event.preventDefault();
const toSay = input.value.trim();
const utterance = new SpeechSynthesisUtterance(toSay);
utterance.voice = currentVoice;
utterance.addEventListener('start', () => {
main.classList.add('speaking');
});
utterance.addEventListener('end', () => {
main.addEventListener(
'animationiteration',
() => main.classList.remove('speaking'),
{ once: true }
);
});
speechSynthesis.speak(utterance);
input.value = '';
});
});
</script>
现在,阅读开始时背景会闪烁蓝色,并在语音命令结束时停止闪烁。
大声朗读以扩展浏览器的可能性
在本文中,我解释了如何从Web Speech API启动和操作Speech Synthesis API。此应用程序的所有代码都在 GitHub 上,您可以在 Glitch 上查看和编辑它。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)