python 文件游标以及 re 中的 match,sub(具体示例)
如下图所示:文件out_plink.ped文件myData.txt要达到的目的:将文件myData.txt的第一列纯数字提取出来,再按照文件out_plink.ped的顺序重新排列myData.txt中的各行。实现代码如下:#!/usr/bin/env python#coding:utf-8import redef sort_pheno():f_txt = open('myDat
如下图所示:
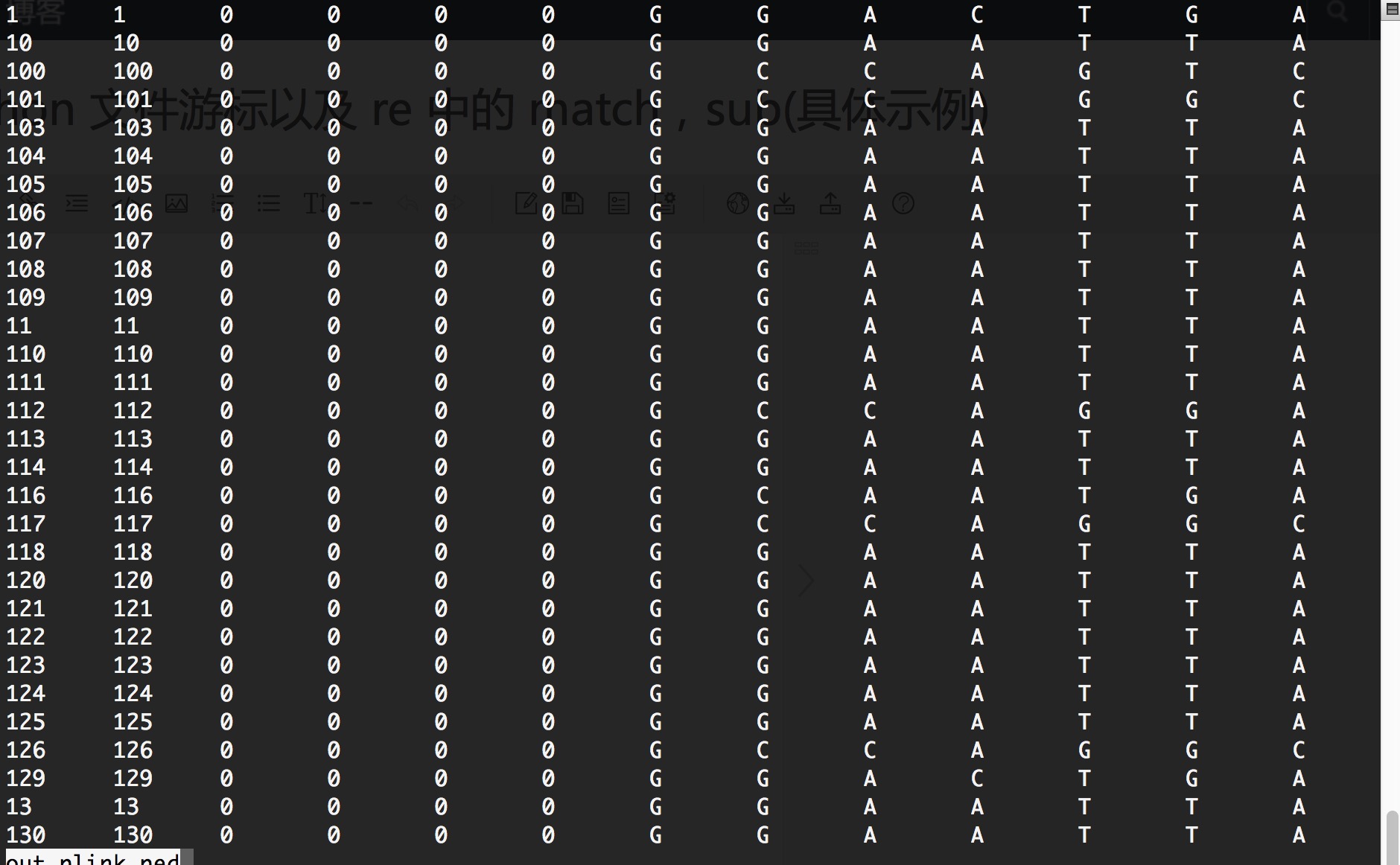
文件out_plink.ped
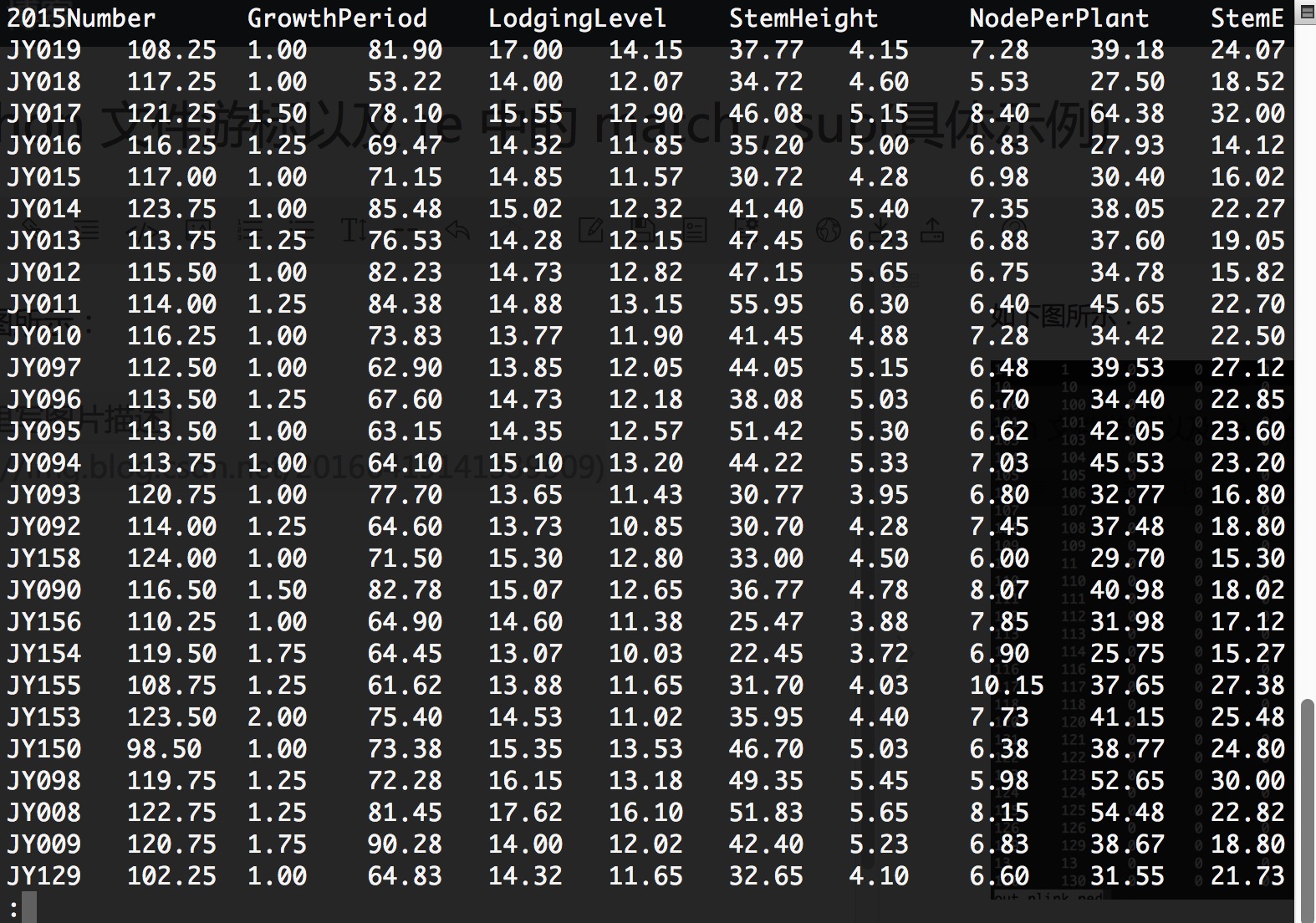
文件myData.txt
要达到的目的:将文件myData.txt的第一列纯数字提取出来,再按照文件out_plink.ped的顺序重新排列myData.txt中的各行。
实现代码如下:
#!/usr/bin/env python
#coding:utf-8
import re
def sort_pheno():
f_txt = open('myData.txt','r')
f_ped = open('out_plink.ped','r')
f_new_txt = open('new.txt','w')
tag = 0
for each_line_ped in f_ped.readlines():
m_ped = re.match(r'\d+',each_line_ped)
first_number_ped = m_ped.group(0)
for each_line_txt in f_txt.readlines():
if each_line_txt.find('Number') != -1 and tag == 0 :
f_new_txt.write(each_line_txt)
tag = tag + 1
else:
each_line_txt = re.sub(r'JY[0]*','',each_line_txt,1)
m_txt = re.match(r'\d+',each_line_txt)
first_number_txt = m_txt.group(0)
if first_number_txt == first_number_ped:
f_new_txt.write(each_line_txt)
f_txt.seek(0,0)
f_txt.close()
f_ped.close()
f_new_txt.close()
if __name__ == '__main__':
sort_pheno()代码知识点解析:
(1)if each_line_txt.find(‘Number’) != -1:
find()函数:查找不到指定字符串,返回-1。
(2)each_line_txt=re.sub(r’JY[0]*’,”,each_line_txt,1):
re.sub(pattern,repl,string,count)函数:该句实现的功能是将myData.txt文件中的每行第一个字符串前面的“JY”和不参与组成数字的“0”去掉,其中,参数count=1表示只处理一个这样的模式串。
(3)m_txt = re.match(r’\d+’,each_line_txt);first_number_txt = m_txt.group(0) :
re.match(pattern,string)与group()函数:该句实现的功能是将文件每行行首的数字取出来赋值给指定变量。
match()函数只检测RE是不是在string的开始位置匹配,也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。
group()函数示例:
import re
a = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456a、正则表达式中的三组括号把匹配结果分成三组,
group() 同group(0)就是匹配正则表达式整体结果
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分;
b、没有匹配成功的,re.search()返回None;
c、当然郑则表达式中没有括号,group(1)肯定不对了
(4)f_txt.seek(0,0):该句表示文件指针重新回到文件头。
file.seek()方法标准格式是:seek(offset,whence=0)
offset:开始的偏移量,也就是代表需要移动偏移的字节数;whence:给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)