模式识别和机器学习实战-K近邻算法(KNN)- Python实现 - 鸢尾花种类预测
本篇文章来源于机器学习实战训练的一道题目,主要使用KNN算法实现,有以下几个要求:1.分割鸢尾花的训练集和测试集进行训练和测试2.自己设计函数对测试集进行测试3.要求输出错误率4.可以使用matplotlib设计不同k值下的错误率图表
前言
本篇文章来源于机器学习实战训练的一道题目,主要使用KNN算法实现,有以下几个要求:
1.分割鸢尾花的训练集和测试集进行训练和测试
2.自己设计函数对测试集进行测试
3.要求输出错误率
4.可以使用matplotlib设计不同k值下的错误率图表
具体的数据文件和代码,在如下链接里:模式识别与机器学习实战 - KNN算法的python实现 -数据集和源码
1.导入数据
收集到鸢尾花的数据存储在Iris.csv文件里,如图所示:
第一列为序号,第二到第五列为鸢尾花的4个属性,最后一行为鸢尾花种类。
代码实现,编写函数将样本数据存储为矩阵;测试集采用等比例划分的方式
from numpy import *
from os import listdir
import operator
import xlrd
#导入Excel文本中的数据
#参数file_location为文件名,flag为训练集和测试集的标志,horatio是划分比例
def filematrix(file_location,flag,horatio):
f=open(file_location)
arrayolines=f.readlines()
arrayolines.pop(0) # 第一行不读入,因为第一行是字符串
if flag==0: # flag = 0是测试集
numberlines=int(len(arrayolines)*horatio)
else: # flag = 1 是训练集
numberlines=int(len(arrayolines)*(1-horatio))
returnMat = zeros((numberlines,4)) # 需要放回的数据集,先用zeros创建,行数是样本数
classlabelvector=[]
index=0
indey=0
for line in arrayolines:
if horatio==0: #比例为0,即全为训练集或全为测试集
line=line.strip()
listfromline=line.split(',')
returnMat[index,:]=list(map(lambda x : float(x), listfromline[1:5]))
if listfromline[-1]=="Iris-setosa":#花名先用数字代替
classlabelvector.append(1)
if listfromline[-1]=='Iris-versicolor':
classlabelvector.append(2)
if listfromline[-1]=='Iris-virginica':
classlabelvector.append(3)
#比例不为0,又flag = 0 为测试集
elif flag==0 and index%(int(1/horatio))==0: # 等比例划分测试集
line=line.strip()
listfromline=line.split(',')
returnMat[indey,:]=list(map(lambda x : float(x), listfromline[1:5]))
if listfromline[-1]=="Iris-setosa":
classlabelvector.append(1)
if listfromline[-1]=='Iris-versicolor':
classlabelvector.append(2)
if listfromline[-1]=='Iris-virginica':
classlabelvector.append(3)
indey+=1
#比例不为0,又flag = 1 为训练集
elif flag==1 and index%(int(1/horatio))!=0: # 除了测试集,剩下的就为训练集
line=line.strip()
listfromline=line.split(',')
returnMat[indey,:]=list(map(lambda x : float(x), listfromline[1:5]))
if listfromline[-1]=="Iris-setosa":#花名先变成数字代替
classlabelvector.append(1)
if listfromline[-1]=='Iris-versicolor':
classlabelvector.append(2)
if listfromline[-1]=='Iris-virginica':
classlabelvector.append(3)
indey+=1
index+=1 # index记录行数
return returnMat,classlabelvector #返回数据集和标签集
2.数据归一化
我们发现,SepalLengthCm和PetalWidthCm这两个特征的数据大小相差太多了,那么数据大的特征将严重影响其它特征,那么此时就需要让这比值同等重要,此时就需要用到数据归一化;
使用公式:newvalue=(oldvalue-min)/(max-min)
#数据归一化
def autonorm(dataset):
minval=dataset.min(0)
maxval=dataset.max(0)
ranges=maxval-minval
normdataset=zeros(shape(dataset))
m= dataset.shape[0] #行数
normdataset=dataset-tile(minval,(m,1))
normdataset=normdataset/tile(ranges,(m,1))
return normdataset #得到归一化的样本集
3.分类算法的实现
输入参数为 inx(新的样本特征向量) 、 dataset(已知的训练集)、 labels(训练集的标签)、k值
#knn分类方法
def classif(inx,dataset,labels,k) :
datasetsize=dataset.shape[0]
diffmat=tile(inx,(datasetsize,1))-dataset
DiffMat = diffmat**2
sqDistances = DiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies = distances.argsort()
classcount={}
for i in range(k):
vote=labels[sortedDistIndicies[i]]
classcount[vote]=classcount.get(vote,0)+1
sortedclasscount =sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return sortedclasscount[0][0],classcount
4.错误率输出
# 花名的字符串和数字转换函数
def flower_name(number):
if number==1:
return "Iris-setosa"
if number==2:
return "Iris-versicolor"
if number==3:
return "Iris-virginica"
#检验,输出错误率
def datingclassTest(k):
horatio=0.2 # 训练集和测试集的划分比例
Testdatamat,Testdatalabels=filematrix("Iris.csv",0,horatio) # 样本和标签
TestnormMat=autonorm(Testdatamat) # 归一化的数据集
m=TestnormMat.shape[0] # 测试集样本数
Traindatamat,Traindatalabels=filematrix("Iris.csv",1,horatio)
TrainnormMat=autonorm(Traindatamat)
n=TrainnormMat.shape[0] # 训练集样本数
errorcount=0.0 # 错误个数
for i in range(m):
classresult=classif(TestnormMat[i,:],TrainnormMat[0:n,:],Traindatalabels[0:n],k)
# 从0到m的是测试集,而0到n是已知的训练集,后面的标签也是对应训练集的标签
print("识别出的种类是: %s, 真实的种类是: %s" % (flower_name(classresult[0]), flower_name(Testdatalabels[i])))
if (classresult[0] != Testdatalabels[i]):
errorcount+=1.0
print ("错误率是: %f" % (errorcount/float(m)))
print("错误的个数: %d"%int(errorcount))
# 输出k=3时的分类结果和错误率
datingclassTest(3)
结果如图:
5. 图像可视化
显示两个特征之间的关系
import matplotlib
import matplotlib.pyplot as plt
#显示两数据集的分布
def showimage():
AllDataMat, AllLabels = filematrix("D:\\Desktop\\Iris.csv", 1, 0)#这样可以读全数据
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(AllDataMat[:,2], AllDataMat[:,3], 15.0*array(AllLabels), 15.0*array(AllLabels))
plt.xlabel('PetalLengthCm')
plt.ylabel('PetalWidthCm')
plt.show()
fig2 = plt.figure()
ax2 = fig2.add_subplot(111)
ax2.scatter(AllDataMat[:,0], AllDataMat[:,1], 15.0*array(AllLabels), 15.0*array(AllLabels))
plt.xlabel('SepalLengthCm')
plt.ylabel('SepalWidthCm')
plt.show()
showimage()
得到结果:特征PetalLengthCm和PetalWidthCm之间还是可以很好的区分出三个种类的
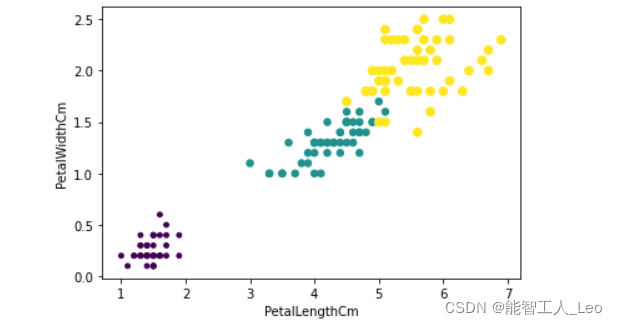
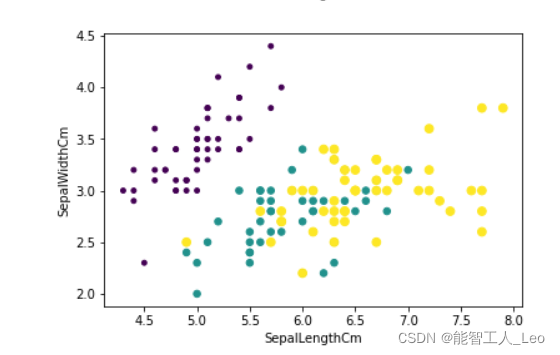
在特征SepalLengthCm和SepalWidthCm之间,就可以发现绿色和黄色区域混在一起,种类不是那么好区分
6.不同k值下的错误率图表
重新编写一个函数datingclassTest_new , 在horatio=0.5 时 (训练集和测试集的比例改成1:1) 统计不同k值下的错误率分布
#输出不同k下的错误率
def datingclassTest_new(k):
horatio=0.5 #训练集和测试集的比例改成1:1
Testdatamat,Testdatalabels=filematrix("Iris.csv",0,horatio)
TestnormMat=autonorm(Testdatamat)
m=TestnormMat.shape[0] # 测试集样本数
Traindatamat,Traindatalabels=filematrix("Iris.csv",1,horatio)
TrainnormMat=autonorm(Traindatamat)
n=TrainnormMat.shape[0] # 训练集样本数
errorcount=0.0 # 错误个数
for i in range(m):
classresult=classif(TestnormMat[i,:],TrainnormMat[0:n,:],Traindatalabels[0:n],k)
if (classresult[0] != Testdatalabels[i]):
errorcount+=1.0
print ("在K=%d下的错误率是: %f" % (k,errorcount/float(m)))
print("错误的个数: %d"%int(errorcount))
return errorcount/float(m) # 返回错误率
y = []
for i in range(1,10):
y.append(datingclassTest_new(i))
fig = plt.figure()
ax = fig.add_subplot(111)
x = [i for i in range(1,10)]
plt.bar(x, y, align = 'center')
plt.xlabel(' K',)
plt.ylabel('Error rate')
plt.title('K graph')
plt.show()
运行结果如下图:
可知在划分比例0.5时(测试集和训练集1:1) , k=2 或 8 的错误率最低
总结
- 能不能再改进一下训练集和测试集的划分方式?例如交叉验证等
- 在KNN分类算法里面加入距离权重,分类时采用的“投票法”加上权重:距离远的标签在分类时所占的比例小,距离近的标签在分类时所占的比例大
from numpy import *
from os import listdir
import operator
import xlrd
def filematrix(file_location,flag,horatio):#导入Excel文本中的数据
f=open(file_location)
arrayolines=f.readlines()
arrayolines.pop(0)#第一行不读入
if flag==0:
numberlines=int(len(arrayolines)*horatio)#flag=0是测试集的样本数
else:
numberlines=int(len(arrayolines)*(1-horatio))
returnMat = zeros((numberlines,4))
classlabelvector=[]
index=0
indey=0
for line in arrayolines: #原因是第一行的字符串无法变成小数
if horatio==0:
line=line.strip()
listfromline=line.split(',')
returnMat[index,:]=list(map(lambda x : float(x), listfromline[1:5]))
if listfromline[-1]=="Iris-setosa":#花名先变成数字代替
classlabelvector.append(1)
if listfromline[-1]=='Iris-versicolor':
classlabelvector.append(2)
if listfromline[-1]=='Iris-virginica':
classlabelvector.append(3)
elif flag==0 and index%(int(1/horatio))==0:
line=line.strip()
listfromline=line.split(',')
returnMat[indey,:]=list(map(lambda x : float(x), listfromline[1:5]))
if listfromline[-1]=="Iris-setosa":#花名先变成数字代替
classlabelvector.append(1)
if listfromline[-1]=='Iris-versicolor':
classlabelvector.append(2)
if listfromline[-1]=='Iris-virginica':
classlabelvector.append(3)
indey+=1
elif flag==1 and index%(int(1/horatio))!=0:
line=line.strip()
listfromline=line.split(',')
returnMat[indey,:]=list(map(lambda x : float(x), listfromline[1:5]))
if listfromline[-1]=="Iris-setosa":#花名先变成数字代替
classlabelvector.append(1)
if listfromline[-1]=='Iris-versicolor':
classlabelvector.append(2)
if listfromline[-1]=='Iris-virginica':
classlabelvector.append(3)
indey+=1
index+=1
return returnMat,classlabelvector #返回数据集和标签集
def autonorm(dataset):#数据归一化
minval=dataset.min(0)
maxval=dataset.max(0)
ranges=maxval-minval
normdataset=zeros(shape(dataset))
m= dataset.shape[0] #行数
normdataset=dataset-tile(minval,(m,1))
normdataset=normdataset/tile(ranges,(m,1))
return normdataset #得到归一化的样本集
def classif(inx,dataset,labels,k) :#knn分类方法
datasetsize=dataset.shape[0]
diffmat=tile(inx,(datasetsize,1))-dataset
DiffMat = diffmat**2
sqDistances = DiffMat.sum(axis=1)
distances=sqDistances**0.5
sortedDistIndicies = distances.argsort()
classcount={}
for i in range(k):
vote=labels[sortedDistIndicies[i]]
classcount[vote]=classcount.get(vote,0)+1
sortedclasscount =sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
return sortedclasscount[0][0],classcount
def flower_name(number):
if number==1:
return "Iris-setosa"
if number==2:
return "Iris-versicolor"
if number==3:
return "Iris-virginica"
def datingclassTest(k):#检验,输出错误率
horatio=0.2#训练集和测试集的比例
Testdatamat,Testdatalabels=filematrix("Iris.csv",0,horatio) #样本和标签
TestnormMat=autonorm(Testdatamat)
m=TestnormMat.shape[0] #测试集样本数
Traindatamat,Traindatalabels=filematrix("Iris.csv",1,horatio) #样本和标签
TrainnormMat=autonorm(Traindatamat)
n=TrainnormMat.shape[0] #训练集样本数
errorcount=0.0 #错误个数
for i in range(m):
classresult=classif(TestnormMat[i,:],TrainnormMat[0:n,:],Traindatalabels[0:n],k) #从0到numTest的是测试集,而numTest到m是已知的训练集,后面的标签也是对应训练集的标签
print("识别出的种类是: %s, 真实的种类是: %s" % (flower_name(classresult[0]), flower_name(Testdatalabels[i])))
if (classresult[0] != Testdatalabels[i]):
errorcount+=1.0
print ("错误率是: %f" % (errorcount/float(m)))
print("错误的个数: %d"%int(errorcount))
'''
# 输出k=3时的分类结果和错误率
datingclassTest(3)
'''
def datingclassTest_new(k):#输出不同k下的错误率
horatio=0.5#训练集和测试集的比例
Testdatamat,Testdatalabels=filematrix("Iris.csv",0,horatio)
TestnormMat=autonorm(Testdatamat)
m=TestnormMat.shape[0] #测试集样本数
Traindatamat,Traindatalabels=filematrix("Iris.csv",1,horatio)
TrainnormMat=autonorm(Traindatamat)
n=TrainnormMat.shape[0] #训练集样本数
errorcount=0.0 #错误个数
for i in range(m):
classresult=classif(TestnormMat[i,:],TrainnormMat[0:n,:],Traindatalabels[0:n],k)
if (classresult[0] != Testdatalabels[i]):
errorcount+=1.0
print ("在K=%d下的错误率是: %f" % (k,errorcount/float(m)))
print("错误的个数: %d"%int(errorcount))
return errorcount/float(m)
# 不同k值下的错误率图表
y = []
for i in range(1,10):
y.append(datingclassTest_new(i))
fig = plt.figure()
ax = fig.add_subplot(111)
x = [i for i in range(1,10)]
plt.bar(x, y, align = 'center')
plt.xlabel(' K',)
plt.ylabel('Error rate')
plt.title('K graph')
plt.show()

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)