注意力机制在推荐模型中的应用——AFM、DIN、DIEN
“注意力机制”来源于人类最自然的选择性注意的习惯。最典型的例子是用户在浏览网页时,会选择性地注意页面的特定区域,忽视其他区域。正是基于这样的现象,在建模过程中考虑注意力机制对预测结果的影响,往往会取得不错的收益。近年来,注意力机制广泛应用于深度学习的各个领域,无论是在自然语言处理、语音识别还是计算机视觉领域,注意力模型都取得了巨大的成功。从2017年开始,推荐领域也开始尝试将注意力机制引入模型之中
“注意力机制”来源于人类最自然的选择性注意的习惯。最典型的例子是用户在浏览网页时,会选择性地注意页面的特定区域,忽视其他区域。正是基于这样的现象,在建模过程中考虑注意力机制对预测结果的影响,往往会取得不错的收益。近年来,注意力机制广泛应用于深度学习的各个领域,无论是在自然语言处理、语音识别还是计算机视觉领域,注意力模型都取得了巨大的成功。从2017年开始,推荐领域也开始尝试将注意力机制引入模型之中,这其中影响力较大的工作是由浙江大学提出的AFM和由阿里巴巴提出的DIN。
AFM
AFM模型可以被认为NFM模型的延续。在NFM模型中,不同域的特征Embedding向量经过特征交叉池化层的交叉,将各交叉特征向量进行“加和”,输入最后由多层神经网络组成的输出层。问题的关键在于加和池化 (Sum Pooling )操作,它相当于“一视同仁”地对待所有交叉特征,不考虑不同特征对结果的影响程度,事实上消解了大量有价值的信息。
这里“注意力机制”就派上了用场,它基于假设——不同的交叉特征对于结果的影响程度不同,举例来说,如果应用场景是预测一位男性用户是否购买一款键盘的可能性,那么“性别=男且购买历史包含鼠标”这一交叉特征,很可能比“性别= 男且用户年龄=30”这一交叉特征更重要,模型投人了更多的“注意力”在前面的特征上。
具体地说,AFM模型引入注意力机制是通过在特征交叉层和最终的输出层之间加入注意力网络(Attention Net)实现的。AFM的模型结构图如图所示,
同NFM一样,AFM的特征交叉过程同样采用了元素积操作,
AFM加入注意力得分后的池化过程入下图所示
AFM模型使用了一个在两两特征交叉层(Pair-wise Interaction Layer)和池化层之间的注意力网络来生成注意力得分。该注意力网络的结构是一个简单的单全连接层加softmax输出层的结构,其数学形式入下所示。
其中要学习的模型参数就是特征交叉层到注意力网络全连接层的权重矩阵 W,偏置向量b,以及全连接层到softmax输出层的权重向量h。注意力网络将与 整个模型一起参与梯度反向传播的学习过程,得到最终的权重参数。
AFM是研究人员从改进模型结构的角度出发进行的一次有益尝试。它与具体的应用场景无关。但阿里巴巴在其深度学习推荐模型中引人注意力机制,则 是一次基于业务观察的模型改进,下面介绍阿里巴巴在业界非常知名的推荐模型——DIN。
DIN—引入注意力机制的深度学习网络
DIN 模型的应用场景是阿里最典型的电商广告推荐, DIN 模型本质上是一个点击率预估模型。
下图是 DIN 的基础模型 Base Model。我们可以看到,Base Model 是一个典型的 Embedding MLP 的结构。它的输入特征有用户属性特征(User Proflie Features)、用户行为特征(User Behaviors)、候选广告特征(Candidate Ad)和场景特征(Context Features)。
这里我们重点关注用户的行为特征和候选广告特征,也就是图中彩色的部分。
我们可以清楚地看到,用户行为特征是由一系列用户购买过的商品组成的,也就是图上的 Goods 1 到 Goods N,而每个商品又包含了三个子特征,也就是图中的三个彩色点,其中红色代表商品 ID,蓝色是商铺 ID,粉色是商品类别 ID。同时,候选广告特征也包含了这三个 ID 型的子特征,因为这里的候选广告也是一个阿里平台上的商品。
阿里的 Base Model 把三个 ID 转换成了对应的 Embedding。由于用户的行为序列是一组商品的序列,这个序列可长可短,为了把这一组商品的 Embedding 处理成一个长度固定的 Embedding ,阿里使用 SUM Pooling 层直接把这些商品的 Embedding 叠加起来,然后再把叠加后的 Embedding 跟其他所有特征的连接结果输入 MLP。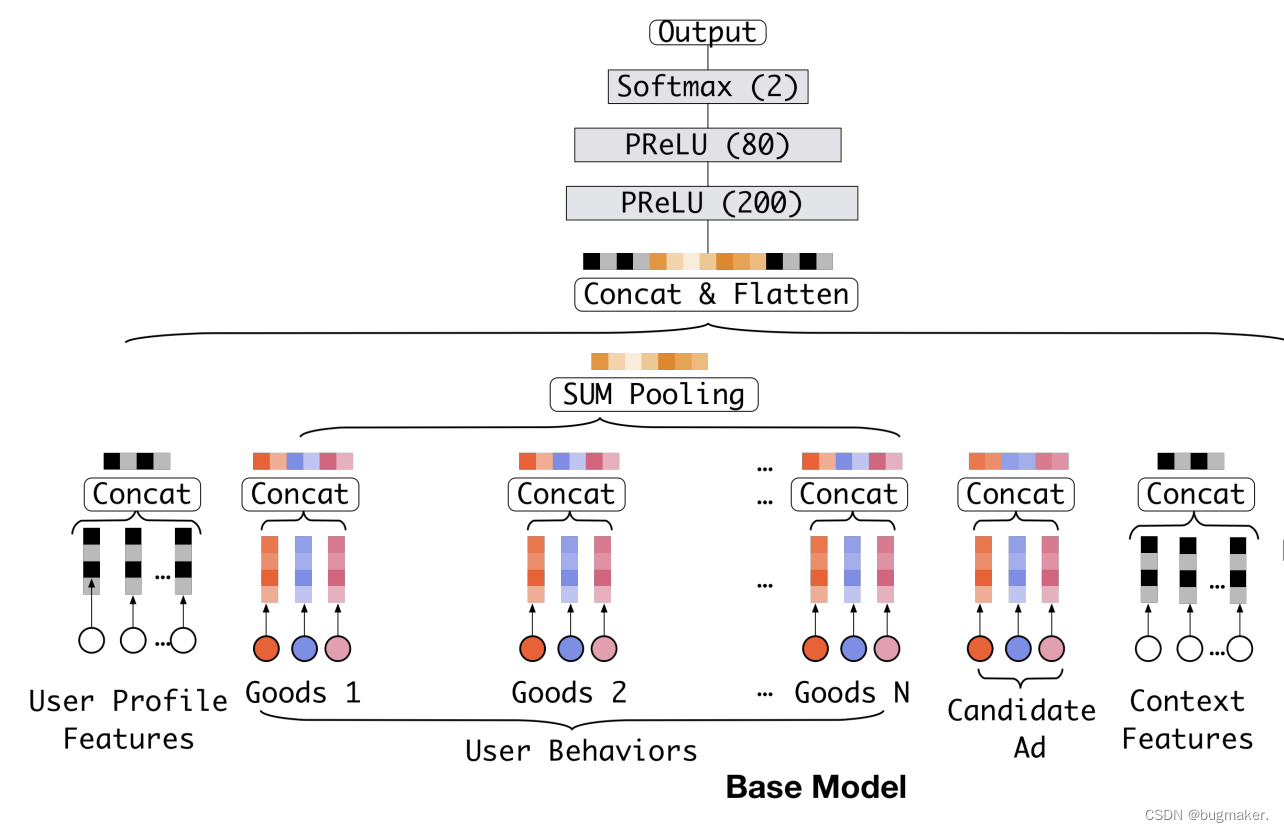
这个时候问题来了,SUM Pooling 的 Embedding 叠加操作其实是把所有历史行为一视同仁,没有任何重点地加起来,这其实并不符合我们购物的习惯。阿里正是在 Base Model 的基础上,把注意力机制应用在了用户的历史行为序列的处理上,从而形成了 DIN 模型。
我们可以从下面的 DIN 模型架构图中看到,与 Base Model 相比,DIN 为每个用户的历史购买商品加上了一个激活单元(Activation Unit),这个激活单元生成了一个权重,这个权重就是用户对这个历史商品的注意力得分,权重的大小对应用户注意力的高低。
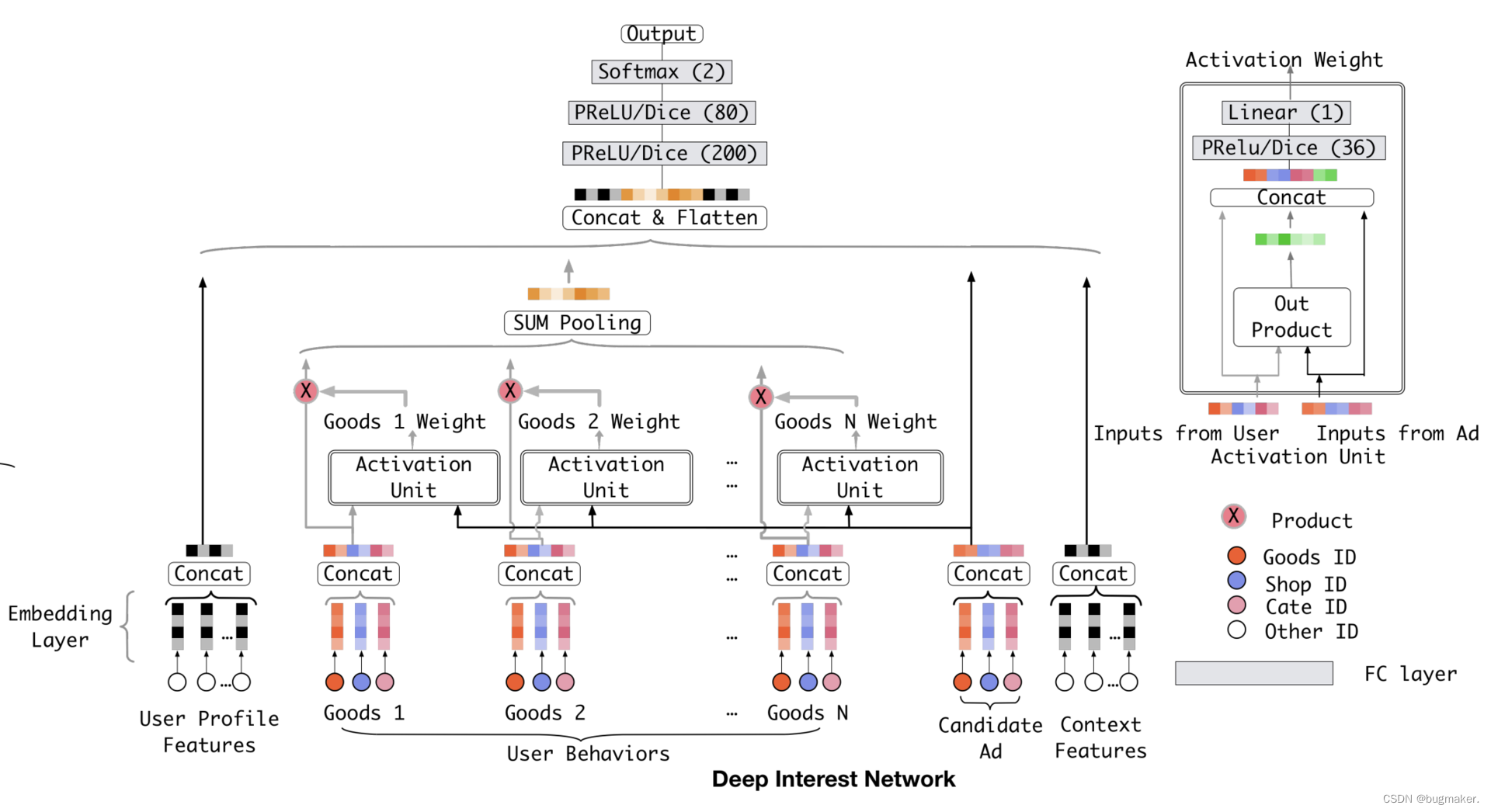
这个所谓的激活单元,到底是怎么计算出最后的注意力权重的呢?一起来看看图右上角激活单元的详细结构。
它的输入是当前这个历史行为商品的 Embedding,以及候选广告商品的 Embedding。我们把这两个输入 Embedding,与它们的外积结果连接起来形成一个向量,再输入给激活单元的 MLP 层,最终会生成一个注意力权重,这就是激活单元的结构。简单来说,激活单元就相当于一个小的深度学习模型,它利用两个商品的 Embedding,生成了代表它们关联程度的注意力权重。
模型实现
import tensorflow as tf
# Training samples path, change to your local path
training_samples_file_path = tf.keras.utils.get_file("trainingSamples.csv")
# Test samples path, change to your local path
test_samples_file_path = tf.keras.utils.get_file("testSamples.csv")
# load sample as tf dataset
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=12,
label_name='label',
na_value="0",
num_epochs=1,
ignore_errors=True)
return dataset
# split as test dataset and training dataset
train_dataset = get_dataset(training_samples_file_path)
test_dataset = get_dataset(test_samples_file_path)
# Config
RECENT_MOVIES = 5 # userRatedMovie{1-5}
EMBEDDING_SIZE = 10
# define input for keras model
inputs = {
'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),
'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),
'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),
'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),
'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),
'userRatedMovie2': tf.keras.layers.Input(name='userRatedMovie2', shape=(), dtype='int32'),
'userRatedMovie3': tf.keras.layers.Input(name='userRatedMovie3', shape=(), dtype='int32'),
'userRatedMovie4': tf.keras.layers.Input(name='userRatedMovie4', shape=(), dtype='int32'),
'userRatedMovie5': tf.keras.layers.Input(name='userRatedMovie5', shape=(), dtype='int32'),
'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),
'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),
'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),
'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),
'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),
'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),
'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),
'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),
}
# movie id embedding feature
#movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
#movie_emb_col = tf.feature_column.embedding_column(movie_col, EMBEDDING_SIZE)
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, EMBEDDING_SIZE)
# genre features vocabulary
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
# user genre embedding feature
user_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="userGenre1",
vocabulary_list=genre_vocab)
user_genre_emb_col = tf.feature_column.embedding_column(user_genre_col, EMBEDDING_SIZE)
# item genre embedding feature
item_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="movieGenre1",
vocabulary_list=genre_vocab)
item_genre_emb_col = tf.feature_column.embedding_column(item_genre_col, EMBEDDING_SIZE)
'''
candidate_movie_col = [tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001,default_value=0))]
recent_rate_col = [
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_identity(key='userRatedMovie1', num_buckets=1001,default_value=0)),
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_identity(key='userRatedMovie2', num_buckets=1001,default_value=0)),
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_identity(key='userRatedMovie3', num_buckets=1001,default_value=0)),
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_identity(key='userRatedMovie4', num_buckets=1001,default_value=0)),
tf.feature_column.indicator_column(tf.feature_column.categorical_column_with_identity(key='userRatedMovie5', num_buckets=1001,default_value=0)),
]
'''
candidate_movie_col = [ tf.feature_column.numeric_column(key='movieId', default_value=0), ]
recent_rate_col = [
tf.feature_column.numeric_column(key='userRatedMovie1', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie2', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie3', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie4', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie5', default_value=0),
]
# user profile
user_profile = [
user_emb_col,
user_genre_emb_col,
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev'),
]
# context features
context_features = [
item_genre_emb_col,
tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
]
candidate_layer = tf.keras.layers.DenseFeatures(candidate_movie_col)(inputs)
user_behaviors_layer = tf.keras.layers.DenseFeatures(recent_rate_col)(inputs)
user_profile_layer = tf.keras.layers.DenseFeatures(user_profile)(inputs)
context_features_layer = tf.keras.layers.DenseFeatures(context_features)(inputs)
# Activation Unit
movie_emb_layer = tf.keras.layers.Embedding(input_dim=1001,output_dim=EMBEDDING_SIZE,mask_zero=True)# mask zero
user_behaviors_emb_layer = movie_emb_layer(user_behaviors_layer)
candidate_emb_layer = movie_emb_layer(candidate_layer)
candidate_emb_layer = tf.squeeze(candidate_emb_layer,axis=1)
repeated_candidate_emb_layer = tf.keras.layers.RepeatVector(RECENT_MOVIES)(candidate_emb_layer)
activation_sub_layer = tf.keras.layers.Subtract()([user_behaviors_emb_layer,
repeated_candidate_emb_layer]) # element-wise sub
activation_product_layer = tf.keras.layers.Multiply()([user_behaviors_emb_layer,
repeated_candidate_emb_layer]) # element-wise product
activation_all = tf.keras.layers.concatenate([activation_sub_layer, user_behaviors_emb_layer,
repeated_candidate_emb_layer, activation_product_layer], axis=-1)
activation_unit = tf.keras.layers.Dense(32)(activation_all)
activation_unit = tf.keras.layers.PReLU()(activation_unit)
activation_unit = tf.keras.layers.Dense(1, activation='sigmoid')(activation_unit)
activation_unit = tf.keras.layers.Flatten()(activation_unit)
activation_unit = tf.keras.layers.RepeatVector(EMBEDDING_SIZE)(activation_unit)
activation_unit = tf.keras.layers.Permute((2, 1))(activation_unit)
activation_unit = tf.keras.layers.Multiply()([user_behaviors_emb_layer, activation_unit])
# sum pooling
user_behaviors_pooled_layers = tf.keras.layers.Lambda(lambda x: tf.keras.backend.sum(x, axis=1))(activation_unit)
# fc layer
concat_layer = tf.keras.layers.concatenate([user_profile_layer, user_behaviors_pooled_layers,
candidate_emb_layer, context_features_layer])
output_layer = tf.keras.layers.Dense(128)(concat_layer)
output_layer = tf.keras.layers.PReLU()(output_layer)
output_layer = tf.keras.layers.Dense(64)(output_layer)
output_layer = tf.keras.layers.PReLU()(output_layer)
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(output_layer)
model = tf.keras.Model(inputs, output_layer)
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
# evaluate the model
test_loss, test_accuracy, test_roc_auc, test_pr_auc = model.evaluate(test_dataset)
print('\n\nTest Loss {}, Test Accuracy {}, Test ROC AUC {}, Test PR AUC {}'.format(test_loss, test_accuracy,
test_roc_auc, test_pr_auc))
# print some predict results
predictions = model.predict(test_dataset)
for prediction, goodRating in zip(predictions[:12], list(test_dataset)[0][1][:12]):
print("Predicted good rating: {:.2%}".format(prediction[0]),
" | Actual rating label: ",
("Good Rating" if bool(goodRating) else "Bad Rating"))
DIN模型与AFM模型相比,是一次更典型的改进深度学习网络 的尝试,而且由于出发点是具体的业务场景,也给了推荐工程师更多实质性的启 发。
DIEN
阿里巴巴2019年正式提出了DIN模型的演化版本——DIEN。其创新在于用序列模型模拟了用户兴趣的进化过程。
(1) 它加强了最近行为对下次行为预测的影响。
(2) 序列模型能够学习到购买趋势的信息。
DIEN模型的架构
基于引进“序列”信息的动机,阿里巴巴对DIN模型进行了改进,形成了 DIEN模型的结构。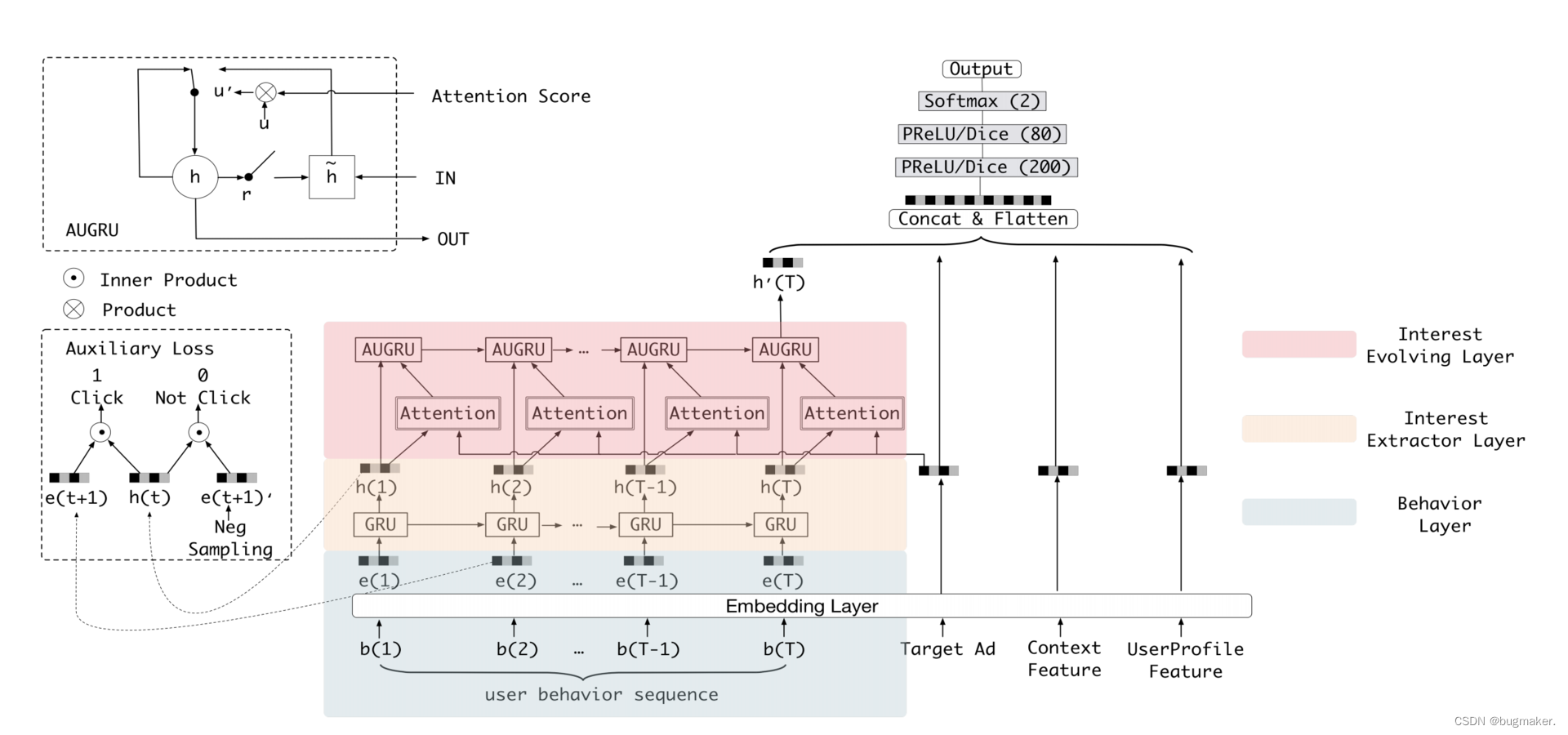
如图所示,模型仍是输入层+Embedding层+连接层+多层全连接神经网络+输出层的整体架构。图中彩色的“兴趣进化网络”被认为是一种用户兴趣的Embedding方法,它最终的输出是这个用户兴趣向量。DIEN模型的创新点在于如何构建“兴趣进化网络”。兴趣进化网络分为三层,从下至上依次是:
(1 )行为序列层(Behavior Layer,浅绿色部分):其主要作用是把原始的id 类行为序列转换成Embedding行为序列。
(2 )兴趣抽取层(Interest Extractor Layer,米黄色部分):其主要作用是通过模拟用户兴趣迁移过程,抽取用户兴趣。
(3 )兴趣进化层(Interest Evolving Layer,浅红色部分):其主要作用是通过 在兴趣抽取层基础上加人注意力机制,模拟与当前目标广告相关的兴趣进化过程。
在兴趣进化网络中,行为序列层的结构与普通的Embedding层是一致的,模拟用户兴趣进化的关键在于“兴趣抽取层”和“兴趣进化层”。
兴趣抽取层的结构
兴趣抽取层的基本结构是GRU ( Gated Recurrent Unit,门循环单元)网络。 相比传统的序列模型RNN,GRU解决了RNN的梯度消失问题。与LSTM相比,GRU的参数数量更少,训练收敛速度更快,因此成了DIEN序列模型的选择。
经过由GRU组成的兴趣抽取层后,用户的行为向量b(t)被进一步抽象化, 形成了兴趣状态向量理论h(t),在兴趣状态向量序列的基础上,GRU网络已经可以做出下一个兴趣状态向量的预测,但DIEN却进一步设置了兴趣进化层, 这是为什么呢?
兴趣进化层的结构
DIEN兴趣进化层相比兴趣抽取层最大的特点是加入了注意力机制。这一特点与DIN的一脉相承。兴趣进化层注意力得分的生成过程与DIN完全一致,都是当前状态向量与目标广告向量进行互作用的结果。也就是说,DIEN在模拟兴趣进化的过程中,需要考虑与目标广告的相关性。在兴趣抽取层之上再加上兴趣进化层就是为了更有针对性地模拟与目标广告相关的兴趣进化路径。
兴趣进化层完成注意力机制的引入是通过AUGRU (GRU with AttentionalUpdate gate,基于注意力更新门的GRU)结构,AUGRU在原GRU的更新门(updategate)的结构上加人了注意力得分,具体形式如下所示。
模型实现
import pandas as pd
import tensorflow as tf
from tensorflow.python.ops import math_ops
import numpy as np
import random
# Training samples path, change to your local path
training_samples_file_path = tf.keras.utils.get_file("trainingSamples.csv",)
# Test samples path, change to your local path
test_samples_file_path = tf.keras.utils.get_file("testSamples.csv",)
def get_dataset_with_negtive_movie(path,batch_size,seed_num):
tmp_df = pd.read_csv(path)
tmp_df.fillna(0,inplace=True)
random.seed(seed_num)
negtive_movie_df=tmp_df.loc[:,'userRatedMovie2':'userRatedMovie5'].applymap( lambda x: random.sample( set(range(0, 1001))-set([int(x)]), 1)[0] )
negtive_movie_df.columns = ['negtive_userRatedMovie2','negtive_userRatedMovie3','negtive_userRatedMovie4','negtive_userRatedMovie5']
tmp_df=pd.concat([tmp_df,negtive_movie_df],axis=1)
for i in tmp_df.select_dtypes('O').columns:
tmp_df[i] = tmp_df[i].astype('str')
if tf.__version__<'2.3.0':
tmp_df = tmp_df.sample( n= batch_size*( len(tmp_df)//batch_size ) ,random_state=seed_num )
dataset = tf.data.Dataset.from_tensor_slices( ( dict(tmp_df)) )
dataset = dataset.batch(batch_size)
return dataset
train_dataset = get_dataset_with_negtive_movie(training_samples_file_path,12,seed_num=2020)
test_dataset = get_dataset_with_negtive_movie(test_samples_file_path,12,seed_num=2021)
# Config
RECENT_MOVIES = 5 # userRatedMovie{1-5}
EMBEDDING_SIZE = 10
# define input for keras model
inputs = {
'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),
'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),
'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),
'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),
'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),
'userRatedMovie2': tf.keras.layers.Input(name='userRatedMovie2', shape=(), dtype='int32'),
'userRatedMovie3': tf.keras.layers.Input(name='userRatedMovie3', shape=(), dtype='int32'),
'userRatedMovie4': tf.keras.layers.Input(name='userRatedMovie4', shape=(), dtype='int32'),
'userRatedMovie5': tf.keras.layers.Input(name='userRatedMovie5', shape=(), dtype='int32'),
'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),
'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),
'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),
'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),
'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),
'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),
'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),
'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),
'negtive_userRatedMovie2': tf.keras.layers.Input(name='negtive_userRatedMovie2', shape=(), dtype='int32'),
'negtive_userRatedMovie3': tf.keras.layers.Input(name='negtive_userRatedMovie3', shape=(), dtype='int32'),
'negtive_userRatedMovie4': tf.keras.layers.Input(name='negtive_userRatedMovie4', shape=(), dtype='int32'),
'negtive_userRatedMovie5': tf.keras.layers.Input(name='negtive_userRatedMovie5', shape=(), dtype='int32'),
'label':tf.keras.layers.Input(name='label', shape=(), dtype='int32')
}
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, EMBEDDING_SIZE)
# genre features vocabulary
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
# user genre embedding feature
user_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="userGenre1",
vocabulary_list=genre_vocab)
user_genre_emb_col = tf.feature_column.embedding_column(user_genre_col, EMBEDDING_SIZE)
# item genre embedding feature
item_genre_col = tf.feature_column.categorical_column_with_vocabulary_list(key="movieGenre1",
vocabulary_list=genre_vocab)
item_genre_emb_col = tf.feature_column.embedding_column(item_genre_col, EMBEDDING_SIZE)
candidate_movie_col = [ tf.feature_column.numeric_column(key='movieId', default_value=0), ]
# user behaviors
recent_rate_col = [
tf.feature_column.numeric_column(key='userRatedMovie1', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie2', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie3', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie4', default_value=0),
tf.feature_column.numeric_column(key='userRatedMovie5', default_value=0),
]
negtive_movie_col = [
tf.feature_column.numeric_column(key='negtive_userRatedMovie2', default_value=0),
tf.feature_column.numeric_column(key='negtive_userRatedMovie3', default_value=0),
tf.feature_column.numeric_column(key='negtive_userRatedMovie4', default_value=0),
tf.feature_column.numeric_column(key='negtive_userRatedMovie5', default_value=0),
]
# user profile
user_profile = [
user_emb_col,
user_genre_emb_col,
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev'),
]
# context features
context_features = [
item_genre_emb_col,
tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
]
label =[ tf.feature_column.numeric_column(key='label', default_value=0), ]
candidate_layer = tf.keras.layers.DenseFeatures(candidate_movie_col)(inputs)
user_behaviors_layer = tf.keras.layers.DenseFeatures(recent_rate_col)(inputs)
negtive_movie_layer = tf.keras.layers.DenseFeatures(negtive_movie_col)(inputs)
user_profile_layer = tf.keras.layers.DenseFeatures(user_profile)(inputs)
context_features_layer = tf.keras.layers.DenseFeatures(context_features)(inputs)
y_true = tf.keras.layers.DenseFeatures(label)(inputs)
# Activation Unit
movie_emb_layer = tf.keras.layers.Embedding(input_dim=1001,output_dim=EMBEDDING_SIZE,mask_zero=True)# mask zero
user_behaviors_emb_layer = movie_emb_layer(user_behaviors_layer)
candidate_emb_layer = movie_emb_layer(candidate_layer)
negtive_movie_emb_layer = movie_emb_layer(negtive_movie_layer)
candidate_emb_layer = tf.squeeze(candidate_emb_layer,axis=1)
user_behaviors_hidden_state=tf.keras.layers.GRU(EMBEDDING_SIZE, return_sequences=True)(user_behaviors_emb_layer)
class attention(tf.keras.layers.Layer):
def __init__(self, embedding_size=EMBEDDING_SIZE, time_length=5, ):
super().__init__()
self.time_length = time_length
self.embedding_size = embedding_size
self.RepeatVector_time = tf.keras.layers.RepeatVector(self.time_length)
self.RepeatVector_emb = tf.keras.layers.RepeatVector(self.embedding_size)
self.Multiply = tf.keras.layers.Multiply()
self.Dense32 = tf.keras.layers.Dense(32,activation='sigmoid')
self.Dense1 = tf.keras.layers.Dense(1,activation='sigmoid')
self.Flatten = tf.keras.layers.Flatten()
self.Permute = tf.keras.layers.Permute((2, 1))
def build(self, input_shape):
pass
def call(self, inputs):
candidate_inputs,gru_hidden_state=inputs
repeated_candidate_layer = self.RepeatVector_time(candidate_inputs)
activation_product_layer = self.Multiply([gru_hidden_state,repeated_candidate_layer])
activation_unit = self.Dense32(activation_product_layer)
activation_unit = self.Dense1(activation_unit)
Repeat_attention_s=tf.squeeze(activation_unit,axis=2)
Repeat_attention_s=self.RepeatVector_emb(Repeat_attention_s)
Repeat_attention_s=self.Permute(Repeat_attention_s)
return Repeat_attention_s
attention_score=attention()( [candidate_emb_layer, user_behaviors_hidden_state])
class GRU_gate_parameter(tf.keras.layers.Layer):
def __init__(self,embedding_size=EMBEDDING_SIZE):
super().__init__()
self.embedding_size = embedding_size
self.Multiply = tf.keras.layers.Multiply()
self.Dense_sigmoid = tf.keras.layers.Dense( self.embedding_size,activation='sigmoid' )
self.Dense_tanh =tf.keras.layers.Dense( self.embedding_size,activation='tanh' )
def build(self, input_shape):
self.input_w = tf.keras.layers.Dense(self.embedding_size,activation=None,use_bias=True)
self.hidden_w = tf.keras.layers.Dense(self.embedding_size,activation=None,use_bias=False)
def call(self, inputs,Z_t_inputs=None ):
gru_inputs,hidden_inputs = inputs
if Z_t_inputs==None:
return self.Dense_sigmoid( self.input_w(gru_inputs) + self.hidden_w(hidden_inputs) )
else:
return self.Dense_tanh( self.input_w(gru_inputs) + self.hidden_w(self.Multiply([hidden_inputs,Z_t_inputs]) ))
class AUGRU(tf.keras.layers.Layer):
def __init__(self,embedding_size=EMBEDDING_SIZE, time_length=5):
super().__init__()
self.time_length = time_length
self.embedding_size = embedding_size
self.Multiply = tf.keras.layers.Multiply()
self.Add=tf.keras.layers.Add()
def build(self, input_shape):
self.R_t = GRU_gate_parameter()
self.Z_t = GRU_gate_parameter()
self.H_t_next = GRU_gate_parameter()
def call(self, inputs ):
gru_hidden_state_inputs,attention_s=inputs
initializer = tf.keras.initializers.GlorotUniform()
AUGRU_hidden_state = tf.reshape(initializer(shape=(1,self.embedding_size )),shape=(-1,self.embedding_size ))
for t in range(self.time_length):
r_t= self.R_t( [gru_hidden_state_inputs[:,t,:], AUGRU_hidden_state] )
z_t= self.Z_t( [gru_hidden_state_inputs[:,t,:], AUGRU_hidden_state] )
h_t_next= self.H_t_next( [gru_hidden_state_inputs[:,t,:], AUGRU_hidden_state] , z_t )
Rt_attention =self.Multiply([attention_s[:,t,:] , r_t])
AUGRU_hidden_state = self.Add( [self.Multiply([(1-Rt_attention),AUGRU_hidden_state ] ), self.Multiply([Rt_attention ,h_t_next ] )])
return AUGRU_hidden_state
augru_emb=AUGRU()( [ user_behaviors_hidden_state ,attention_score ] )
concat_layer = tf.keras.layers.concatenate([ augru_emb, candidate_emb_layer,user_profile_layer,context_features_layer])
output_layer = tf.keras.layers.Dense(128)(concat_layer)
output_layer = tf.keras.layers.PReLU()(output_layer)
output_layer = tf.keras.layers.Dense(64)(output_layer)
output_layer = tf.keras.layers.PReLU()(output_layer)
y_pred = tf.keras.layers.Dense(1, activation='sigmoid')(output_layer)
class auxiliary_loss_layer(tf.keras.layers.Layer):
def __init__(self,time_length=5 ):
super().__init__()
self.time_len = time_length-1
self.Dense_sigmoid_positive32 = tf.keras.layers.Dense(32,activation='sigmoid')
self.Dense_sigmoid_positive1 = tf.keras.layers.Dense(1,activation='sigmoid')
self.Dense_sigmoid_negitive32 = tf.keras.layers.Dense(32,activation='sigmoid')
self.Dense_sigmoid_negitive1 = tf.keras.layers.Dense(1,activation='sigmoid')
self.Dot = tf.keras.layers.Dot(axes=(1, 1))
self.auc =tf.keras.metrics.AUC()
def build(self, input_shape):
pass
def call(self, inputs,alpha=0.5):
negtive_movie_t1,postive_movie_t0,movie_hidden_state,y_true,y_pred=inputs
#auxiliary_loss_values = []
positive_concat_layer=tf.keras.layers.concatenate([ movie_hidden_state[:,0:4,:], postive_movie_t0[:,1:5,:] ])
positive_concat_layer=self.Dense_sigmoid_positive32( positive_concat_layer )
positive_loss = self.Dense_sigmoid_positive1(positive_concat_layer)
negtive_concat_layer=tf.keras.layers.concatenate([ movie_hidden_state[:,0:4,:], negtive_movie_t1[:,:,:] ])
negtive_concat_layer=self.Dense_sigmoid_negitive32( negtive_concat_layer )
negtive_loss = self.Dense_sigmoid_negitive1(negtive_concat_layer)
auxiliary_loss_values = positive_loss + negtive_loss
final_loss = tf.keras.losses.binary_crossentropy( y_true, y_pred )-alpha* tf.reduce_mean( tf.reduce_sum( auxiliary_loss_values,axis=1 ))
self.add_loss(final_loss, inputs=True)
self.auc.update_state(y_true, y_pred )
self.add_metric(self.auc.result(), aggregation="mean", name="auc_value")
return final_loss
auxiliary_loss_value=auxiliary_loss_layer()( [ negtive_movie_emb_layer,user_behaviors_emb_layer,user_behaviors_hidden_state,y_true,y_pred] )
model = tf.keras.Model(inputs=inputs, outputs=[y_pred,auxiliary_loss_value])
model.compile(optimizer="adam")
# train the model
model.fit(train_dataset, epochs=5)
# evaluate the model
test_loss, test_roc_auc = model.evaluate(test_dataset)
print('\n\nTest Loss {}, Test ROC AUC {},'.format(test_loss, test_roc_auc))
model.summary()
# print some predict results
predictions = model.predict(test_dataset)
for prediction, goodRating in zip(predictions[0][:12], list(test_dataset)[0]):
print("Predicted good rating: {:.2%}".format(prediction[0]),
" | Actual rating label: ",
("Good Rating" if bool(goodRating) else "Bad Rating"))
序列模型对推荐系统的启发
由于序列模型具备强大的时间序列的表达能力,使其非常适合预估用户经过一系列行为后的下一次动作。事实上,不仅阿里巴巴在电商模型上成功运用了序列模型,YouTube、 Netflix 等视频流媒体公司也已经成功的在其视频推荐模型中应用了序列模型,用于预测用户的下次观看行为(next watch)。但在工程实现上需要注意:序列模型比较高的训练复杂度,以及在线上推断 过程中的串行推断,使其在模型服务过程中延迟较大,这无疑增大了其上线的难 度,需要在工程上着重优化。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)