Python 学习笔记(三):文件,高级特性,枚举,正则表达式,模块
Python 文件I/O打印到屏幕print语句,此函数把你传递的表达式转换成一个字符串表达式读取键盘输入ython提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:raw_inputinputraw_input函数aw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符):#!/usr/bin/python# -
Python 文件I/O
打印到屏幕
print语句,此函数把你传递的表达式转换成一个字符串表达式
读取键盘输入
ython提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
- raw_input
- input
raw_input函数
aw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符):
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = raw_input("请输入:");
print "你输入的内容是: ", str当我输入”Hello Python!”,它的输出如下:
请输入:Hello Python!
你输入的内容是: Hello Python!input函数
nput([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
str = input("请输入:");
print "你输入的内容是: ", str这会产生如下的对应着输入的结果:
请输入:[x*5 for x in range(2,10,2)]
你输入的内容是: [10, 20, 30, 40]打开和关闭文件
Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:
-
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
-
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
-
buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
不同模式打开文件的完全列表:

File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:

如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "wb")
print "文件名: ", fo.name
print "是否已关闭 : ", fo.closed
print "访问模式 : ", fo.mode
print "末尾是否强制加空格 : ", fo.softspace以上实例输出结果:
文件名: foo.txt
是否已关闭 : False
访问模式 : wb
末尾是否强制加空格 : 0close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "wb")
print "文件名: ", fo.name
# 关闭打开的文件
fo.close()以上实例输出结果:
文件名: foo.txtwrite()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "wb")
fo.write( "www.runoob.com!\nVery good site!\n");
# 关闭打开的文件
fo.close()上述方法会创建foo.txt文件,并将收到的内容写入该文件,并最终关闭文件。如果你打开这个文件,将看到以下内容:
$ cat foo.txt
www.runoob.com!
Very good site!read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count]);
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
例子:
这里我们用到以上创建的 foo.txt 文件。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10);
print "读取的字符串是 : ", str
# 关闭打开的文件
fo.close()以上实例输出结果:
读取的字符串是 : www.runoobremove()方法
你可以用remove()方法删除文件,需要提供要删除的文件名作为参数。
例子:
下例将删除一个**已经存在的文件**test2.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")文件定位
tell()方法告诉你文件内的当前位置;换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
就用我们上面创建的文件foo.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10);
print "读取的字符串是 : ", str
# 查找当前位置
position = fo.tell();
print "当前文件位置 : ", position
# 把指针再次重新定位到文件开头
position = fo.seek(0, 0);
str = fo.read(10);
print "重新读取字符串 : ", str
# 关闭打开的文件
fo.close()以上实例输出结果:
读取的字符串是 : www.runoob
当前文件位置 : 10
重新读取字符串 : www.runoobPython里的目录
所有文件都包含在各个不同的目录下,不过Python也能轻松处理。os模块有许多方法能帮你创建,删除和更改目录。
mkdir()方法
可以使用os模块的mkdir()方法在当前目录下创建新的目录们。你需要提供一个包含了要创建的目录名称的参数。
语法:
os.mkdir("newdir")
例子:
下例将在当前目录下创建一个新目录test。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 创建目录test
os.mkdir("test")chdir()方法
可以用chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称。
语法:
os.chdir("newdir")
例子:
下例将进入”/home/newdir”目录。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir")getcwd()方法:
getcwd()方法显示当前的工作目录。
语法:
os.getcwd()
例子:
下例给出当前目录:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 给出当前的目录
os.getcwd()rmdir()方法
rmdir()方法删除目录,目录名称以参数传递。
在删除这个目录之前,它的所有内容应该先被清除。
语法:
os.rmdir(‘dirname’)
例子:
以下是删除” /tmp/test”目录的例子。目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
# 删除”/tmp/test”目录
os.rmdir( "/tmp/test" )切片
取一个list或tuple的部分元素是非常常见的操作。比如,一个list如下:
>>> L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
取前3个元素,应该怎么做?
对这种经常取指定索引范围的操作,用循环十分繁琐,因此,Python提供了切片(Slice)操作符,能大大简化这种操作。
>>> L[0:3]
['Michael', 'Sarah', 'Tracy']
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
>>> L[:3]
['Michael', 'Sarah', 'Tracy']
类似的,既然Python支持L[-1]取倒数第一个元素,那么它同样支持倒数切片,试试:
>>> L[-2:]
['Bob', 'Jack']
>>> L[-2:-1]
['Bob']
甚至什么都不写,只写[:]就可以原样复制一个list:
>>> L[:]
[0, 1, 2, 3, ..., 99]
字符串’xxx’也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:
>>> 'ABCDEFG'[:3]
'ABC'
>>> 'ABCDEFG'[::2]
'ACEG'
列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
如果要生成[1x1, 2x2, 3x3, …, 10x10]怎么做?方法一是循环:
>>> L = []
>>> for x in range(1, 11):
... L.append(x * x)
...
>>> L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来,十分有用,多写几次,很快就可以熟悉这种语法。
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> for k, v in d.items():
... print(k, '=', v)
...
y = B
x = A
z = C
使用@property
Python内置的@property装饰器就是负责把一个方法变成属性调用的:
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value@property的实现比较复杂,我们先考察如何使用。把一个getter方法变成属性,只需要加上@property就可以了,此时,@property本身又创建了另一个装饰器@score.setter,负责把一个setter方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
>>> s = Student()
>>> s.score = 60 # OK,实际转化为s.set_score(60)
>>> s.score # OK,实际转化为s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!注意到这个神奇的@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的。
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2015 - self._birth上面的birth是可读写属性,而age就是一个只读属性,因为age可以根据birth和当前时间计算出来。
枚举类
Enum可以把一组相关常量定义在一个class中,且class不可变,而且成员可以直接比较。
为这样的枚举类型定义一个class类型,然后,每个常量都是class的一个唯一实例。Python提供了Enum类来实现这个功能:
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
这样我们就获得了Month类型的枚举类,可以直接使用Month.Jan来引用一个常量,或者枚举它的所有成员:
for name, member in Month.__members__.items():
print(name, '=>', member, ',', member.value)
Python正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
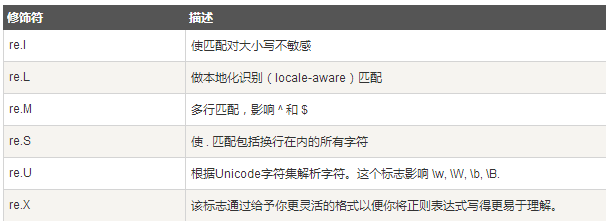
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’/t’,等价于’//t’)匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
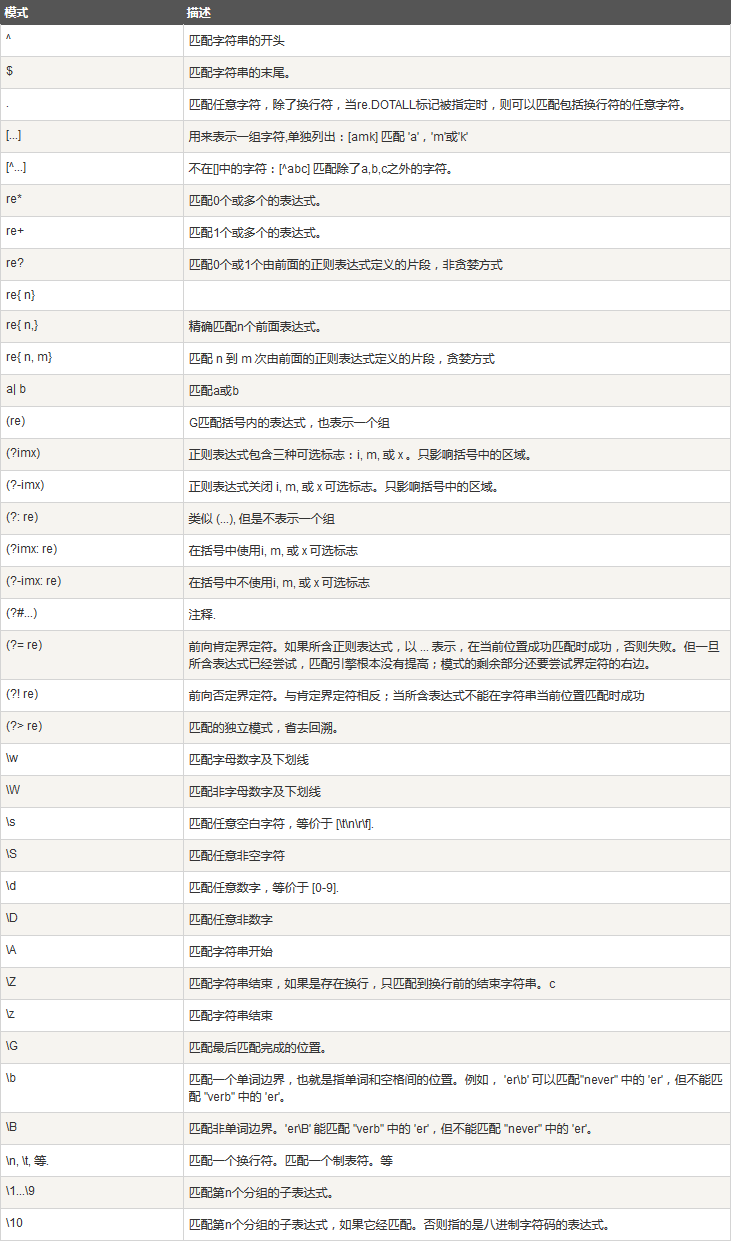
正则表达式实例
字符匹配

字符类
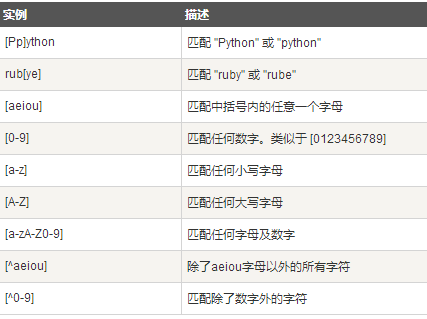
特殊字符类
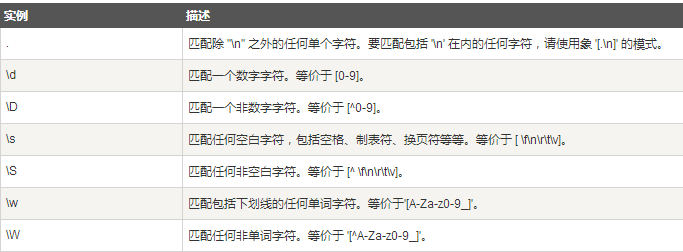
re.match函数
e.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法
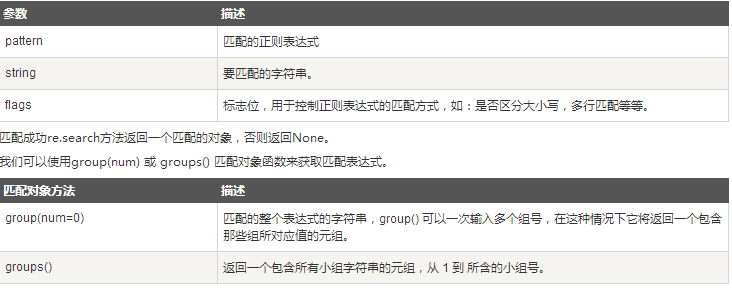
re.match(pattern, string, flags=0)
函数参数说明

实例
实例 1
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配输出结果为:
(0, 3)
None
实例 2:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"执行结果
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarterre.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法
re.search(pattern, string, flags=0)
函数参数说明
实例
实例 1:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
# 不在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) 输出结果为:
(0, 3)
实例 2:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"执行结果如下:
searchObj.group() : Cats are smarter than dogs
searchObj.group(1) : Cats
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
实例:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print "search --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"运行结果如下
No match!!
search --> matchObj.group() : dogs
re.split
可以使用re.split来分割字符串,如:re.split(r’\s+’, text);将字符串按空格分割成一个单词列表。
re.findall
re.findall可以获取字符串中所有匹配的字符串。
如:re.findall(r’\w*oo\w*’, text);获取字符串中,包含’oo’的所有单词。
re.compile
可以把正则表达式编译成一个正则表达式对象。可以把那些经常使用的正则表达式编译成正则表达式对象,这样可以提高一定的效率。
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
regex = re.compile(r'\w*oo\w*')
#查找所有包含'oo'的单词
print regex.findall(text)
#将字符串中含有'oo'的单词用[]括起来。
print regex.sub(lambda m: '[' + m.group(0) + ']', text)检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法
re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。
可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
实例:
#!/usr/bin/python
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print "Phone Num : ", num
# Remove anything other than digits
num = re.sub(r'\D', "", phone)
print "Phone Num : ", num执行结果如下:
Phone Num : 2004-959-559
Phone Num : 2004959559
模块
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。点这里查看Python的所有内置函数。
你也许还想到,如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名,比如mycompany,按照如下目录存放:
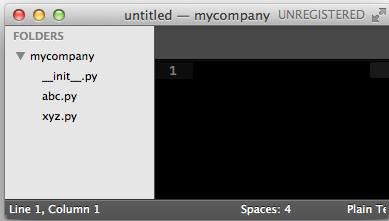
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,abc.py模块的名字就变成了mycompany.abc,类似的,xyz.py的模块名变成了mycompany.xyz。
请注意,每一个包目录下面都会有一个init.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。init.py可以是空文件,也可以有Python代码,因为init.py本身就是一个模块,而它的模块名就是mycompany。
安装第三方模块
在Python中,安装第三方模块,是通过包管理工具pip完成的。
如果你正在使用Mac或Linux,安装pip本身这个步骤就可以跳过了。
如果你正在使用Windows,请参考安装Python一节的内容,确保安装时勾选了pip和Add python.exe to Path。
在命令提示符窗口下尝试运行pip,如果Windows提示未找到命令,可以重新运行安装程序添加pip。
注意:Mac或Linux上有可能并存Python 3.x和Python 2.x,因此对应的pip命令是pip3。
现在,让我们来安装一个第三方库——Python Imaging Library,这是Python下非常强大的处理图像的工具库。不过,PIL目前只支持到Python 2.7,并且有年头没有更新了,因此,基于PIL的Pillow项目开发非常活跃,并且支持最新的Python 3。
一般来说,第三方库都会在Python官方的pypi.python.org网站注册,要安装一个第三方库,必须先知道该库的名称,可以在官网或者pypi上搜索,比如Pillow的名称叫Pillow,因此,安装Pillow的命令就是:
pip install Pillow耐心等待下载并安装后,就可以使用Pillow了。
有了Pillow,处理图片易如反掌。随便找个图片生成缩略图:
>>> from PIL import Image
>>> im = Image.open('test.png')
>>> print(im.format, im.size, im.mode)
PNG (400, 300) RGB
>>> im.thumbnail((200, 100))
>>> im.save('thumb.jpg', 'JPEG')其他常用的第三方库还有MySQL的驱动:mysql-connector-python,用于科学计算的NumPy库:numpy,用于生成文本的模板工具Jinja2,等等。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)