[Video Transformer] TimeSformer: Is Space-Time Attention All You Need for Video Understanding?
论文:https://arxiv.org/pdf/2102.05095.pdf代码:https://github.com/lucidrains/TimeSformer-pytorch参考博客:https://mp.weixin.qq.com/s/E43AaQEcr2_Nm4FqcXXM7gaccept: ICML2021author: Facebook AIInput clips:H*W*3*F从
论文:https://arxiv.org/pdf/2102.05095.pdf
代码: https://github.com/lucidrains/TimeSformer-pytorch
参考博客: https://mp.weixin.qq.com/s/E43AaQEcr2_Nm4FqcXXM7g
accept: ICML2021
author: Facebook AI
Input clips:H*W*3*F
从原视频中取出的F帧RGB视频帧,size H*W。
Decomposition into patches:
将每一帧视频分割成N个无交叠的patch,size P*P,N= HW / P^2 .
Linear embedding
对输入进行线性映射,并加上learnable positional embedding
Query-Key-Value computation
本文提出的transformer包括 L encoding blocks
在每个encoding block中,对每个patch计算QKV:
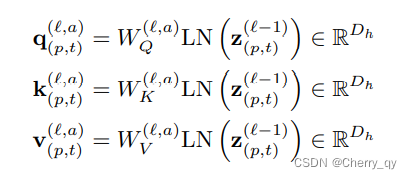
a代表attention head的index
Dh表示每个head的维度
p=1..N
t=1..F
Self-attention computation
通过点乘计算自注意力
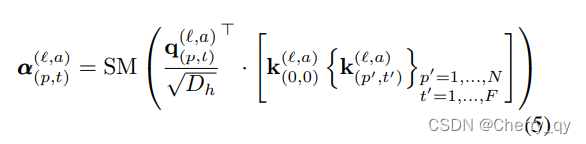
SM代表softmax
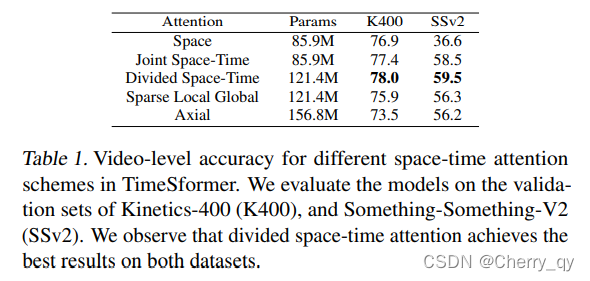
注意力仅在单一维度上进行计算(spatial or temporal)

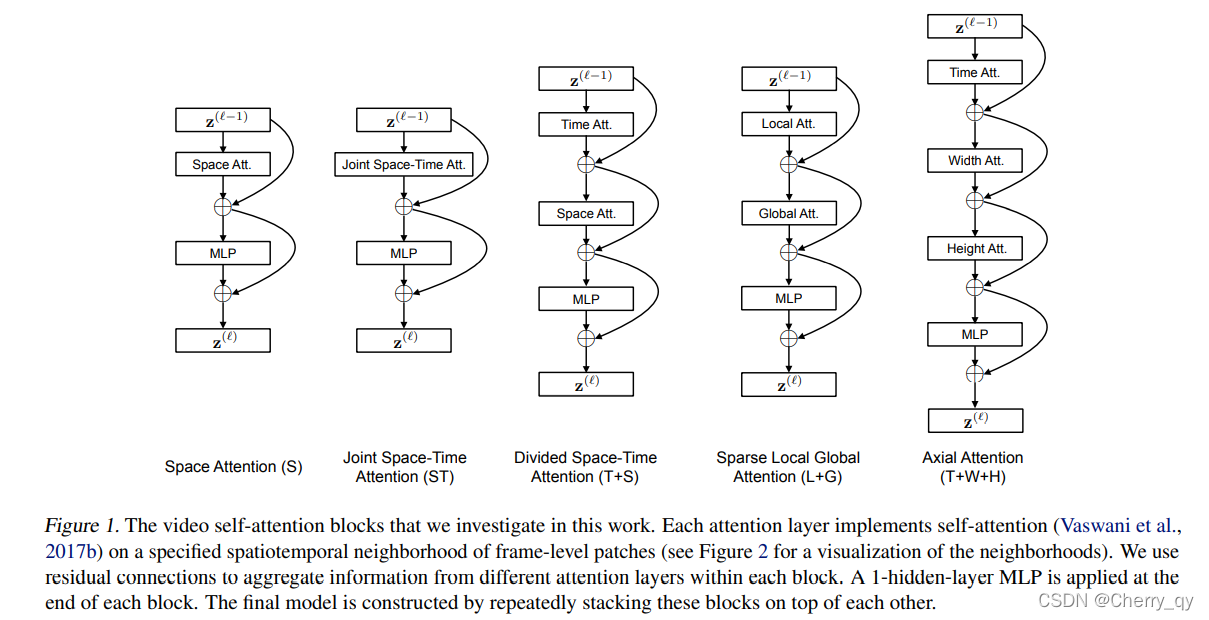
Space-Time Self-Attention Models
Divided Space-Time attention:
时间和空间注意力被分别交替应用
在time attention 中,每个图像patch仅和其余帧在对应位置提取出的图像patch进行 attention操作。
在space attention 中,这个图像patch仅和同一帧的提取出的图像patch进行 attention操作。

- Sparse Local Global Attention (L+G) 这个attention文章只做了简单的描述,没有给出相关代码实现,这里参考了Generating Long Sequences with Sparse Transformers( https://mp.weixin.qq.com/s/E43AaQEcr2_Nm4FqcXXM7g ),做一个简单的解释。
Sparse Self-Attention合并Local和Atrous,除了相对距离不超过k的,相对距离为k的倍数的注意力都为0,这样Attention就有了"局部紧密相关和远程稀疏相关"的特性。
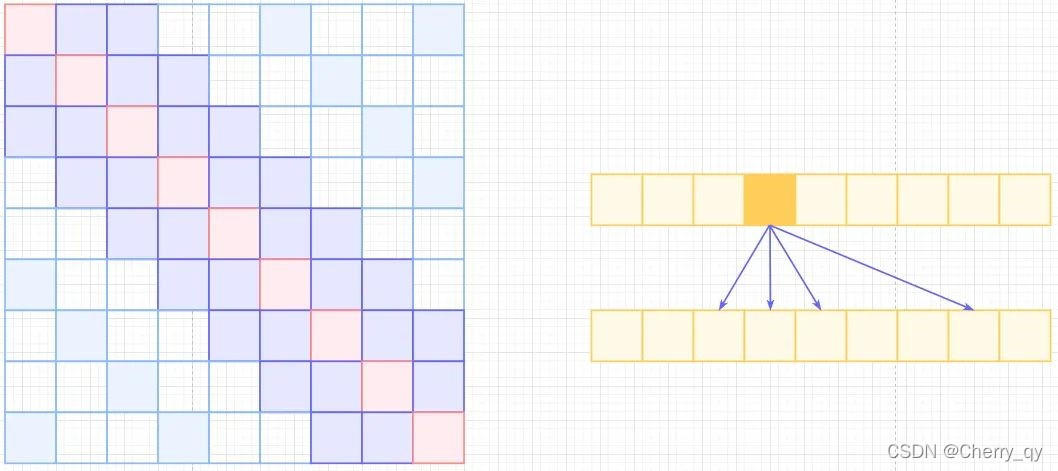
本文中,local attention只考虑F* H/2 * W/2的patches,也就是每个patch只考虑1/4图像区域近邻的patches,其他忽略。
而本文中的global attention是采用2的stride来在temporal维度和HW维度上进行patches的滑窗计算。与sparse self-attention不同点在于,sparse local global attention先计算local再计算global。

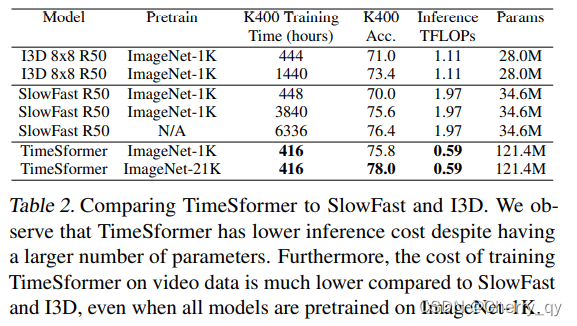
(1) TimeSformer, operating on 8×224×224 video clips
(2) TimeSformer-HR, a high spatial resolution variant , operates on 16 × 448 × 448 video clips
(3) TimeSformer-L, a long-range configuration,operates on 96 × 224 × 224 video clips with frames sampled at a rate of 1/4.
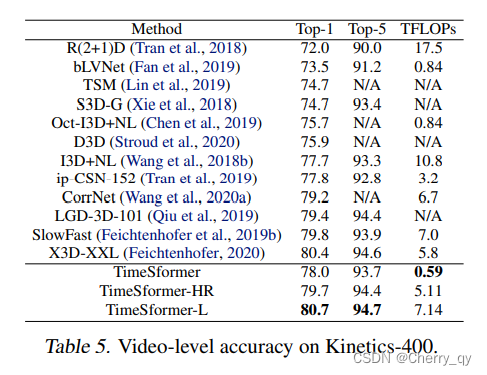
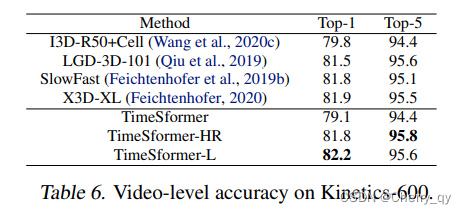
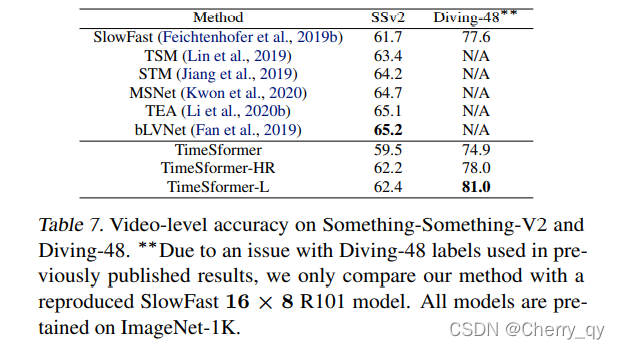
Long-Term Video Modeling
中长视频数据集:HowTo100M
包含了1M左右的视频,包括 23K 种类别的人类活动,视频长度平均在7min。
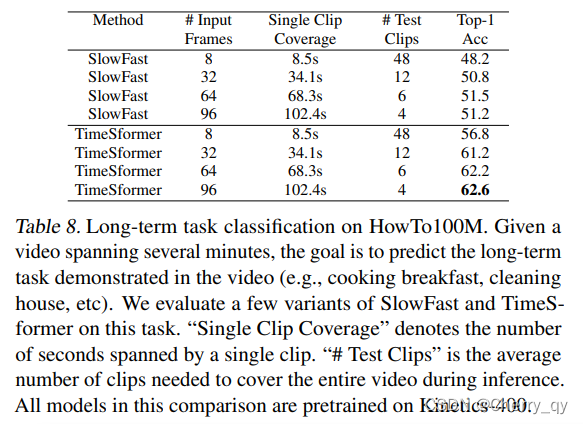
Test clips代表inference时cover 整个视频所需要的平均clip数量

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)