(究极01)Scrapy练习第三辑-贯穿GitHub
实在花了不小心思了,最近还有3件事等我去完成,这次先做到这!首先我做的是爬取GitHub上的用户信息,所以流程图如下:贴上GitHubSpider.py:#coding:utf-8#!/usr/bin/env python#author:Z0fr3y#update:2015-10-7#version:2.4#name:GitHubSpider#运行scrapy crawl githu
实在花了不小心思了,最近还有3件事等我去完成,这次先做到这!
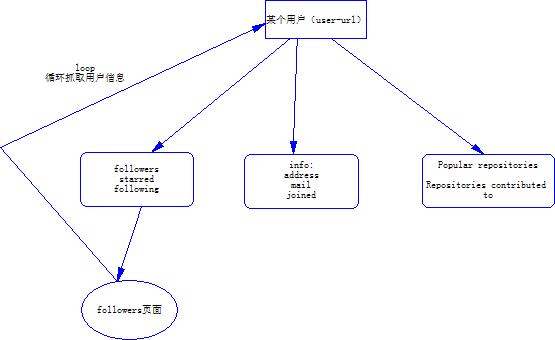
首先我做的是爬取GitHub上的用户信息,所以流程图如下:
贴上GitHubSpider.py:
#coding:utf-8
#!/usr/bin/env python
#author:Z0fr3y
#update:2015-10-7
#version:2.4
#name:GitHubSpider
#运行scrapy crawl github
import urllib
from scrapy import Request
from scrapy.spider import Spider
from scrapy.selector import Selector
#from scrapy.spiders import CrawlSpider, Rule
from GitHub.items import Github_Item
import pymongo
import sys
import os
reload (sys)
sys.setdefaultencoding("utf-8")#这句话让爬到的内容是utf-8的
#PROJECT_DIR = os.path.abspath(os.path.dirname(__file__))#返回绝对路径(#返回文件路径)
host="https://github.com"
global a
a=1
global b#抓取了多少人
b=0
global c#想抓取几人信息
c=10
global f_newlist#文件名(不包含后缀),避免重复爬取。
f_newlist=[]
class GithubSpider(Spider):
"""
爬取GitHub网站中用户信息
"""
name = 'github'
allowed_domains = ['github.com']
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "zh-CN,zh;q=0.8",
"Connection": "keep-alive",
"Content-Type":" application/x-www-form-urlencoded",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36",
}
start_urls = ["https://github.com/1st1",]#GitHub下随便哪个人的主页
#def __init__(self,category=None,*args,**kwargs):
#super(GithubSpider,self).__init__(*args,**kwargs)
def getfile(self):#获取文件名(不包含后缀)
path = r'GitHub\media\people'
f_list = os.listdir(path)
print f_list
global f_newlist
for i in range(0,len(f_list)):
l,b=os.path.splitext(f_list[i])#将名与后缀分开
f_newlist.append(l)
return f_newlist
def parse(self,response):
print "~"*60+"start"
print response.url
people_mainpage=Selector(response)
self.getfile()
global f_newlist
people=Github_Item()#以下是爬取用户的详细信息
people_profile=people_mainpage.xpath('//div[@class="column one-fourth vcard"]')
people['image_urls'] = people_profile.xpath('a[1]/img/@src').extract()
x1=people_profile.xpath('h1/span[@class="vcard-fullname"]/text()').extract()
if x1==[]:#避免fullname为空
people['fullname']="None"
else:
people['fullname']=x1[0]
for i in range(0,len(f_newlist)):#如果名字与已存在的txt文件一致,就选择不爬取,跳到第一个主页的followers页面,从新爬取。
if (people['fullname']==f_newlist[i]):
yield Request(url="https://github.com/1st1/followers",callback=self.parse_two,dont_filter=True)
x2=people_profile.xpath('h1/span[@class="vcard-username"]/text()').extract()[0]
if x2==[]:
people['username']="None"
else:
people['username']=x2[0]
x3=people_profile.xpath('//li/@title').extract()
if x3==[]:
people['organization']="None"
else:
people['organization']=x3[0]
x4=people_profile.xpath('//a[@class="email"]/text()').extract()
if x4==[]:
people['mail']="None"
else:
people['mail']=x4[0]
people['joined']=people_profile.xpath('//time[@class="join-date"]/text()').extract()[0]
people['followers']=people_profile.xpath('div[@class="vcard-stats"]/a[1]/strong[@class="vcard-stat-count"]/text()').extract()[0]
people['starred']=people_profile.xpath('div[@class="vcard-stats"]/a[2]/strong[@class="vcard-stat-count"]/text()').extract()[0]
people['following']=people_profile.xpath('div[@class="vcard-stats"]/a[3]/strong[@class="vcard-stat-count"]/text()').extract()[0]
popular_repo=people_mainpage.xpath('//div[@class="columns popular-repos"]/div[@class="column one-half"][1]')
people['popular_repos']=" "
for i in range(1,6):#这是popular_repos数据
people['popular_repos']=people['popular_repos']+" "+' '.join(popular_repo.xpath('div/ul[@class="boxed-group-inner mini-repo-list"]/li['+str(i)+']/a/span[2]/span/text()').extract())
repo_contribution=people_mainpage.xpath('//div[@class="columns popular-repos"]/div[@class="column one-half"][2]')
people['repo_contributions']=" "
for i in range(1,6):#这是repo_contributions数据
people['repo_contributions']=people['repo_contributions']+" "+' '.join(repo_contribution.xpath('div/ul[@class="boxed-group-inner mini-repo-list"]/li['+str(i)+']/a/span[2]/span[1]/text()').extract())+"/"+' '.join(repo_contribution.xpath('div/ul[@class="boxed-group-inner mini-repo-list"]/li['+str(i)+']/a/span[2]/span[2]/text()').extract())
followers_page=host+''.join(people_mainpage.xpath('//a[@class="vcard-stat"][1]/@href').extract())
xxxx=people
#'../media.people/'GitHub\media\people
fh=open('GitHub/media/people/'+people['fullname']+'.txt','w')
fh.write(str(xxxx))#将爬取下来的信息保存到文件
fh.close()
global b
global c
if b<c:
b+=1
print str(b)+" "+ "people Detail information"
yield Request(url=followers_page,callback=self.parse_followers,dont_filter=True)
print "~"*60+"over"
if (b<=c):
yield people
def parse_followers(self,response):
print "~"*60+"parse_followers"
print response.url
people_parse_one=Selector(response)
followers_parse_one_link=host+''.join(people_parse_one.xpath('//ol[@class="follow-list clearfix"]/li[1]/a/@href').extract())
print followers_parse_one_link
yield Request(url=followers_parse_one_link,callback=self.parse_one,dont_filter=True)
def parse_one(self,response):
print "~"*60+"parse_one_start"
print response.url
people_parse_one=Selector(response)
x=people_parse_one.xpath('//div[@class="vcard-stats"]/a[1]/strong[@class="vcard-stat-count"]/text()').extract()
#print "x=:"+x[0]
#y=int(''.join([str(t) for t in x]))
#print "y=:"+y
print "x=:"
print x
if (x!= ["0"]):
print "followers is not 0 ....Go to--->"
yield Request(url=response.url,callback=self.parse,dont_filter=True)
else:
yield Request(url="https://github.com/1st1/followers",callback=self.parse_two,dont_filter=True)
def parse_two(self,response):
print "~"*60+"parse_two_start"#主页面人的followers页
print response.url
people_parse_two=Selector(response)
global a
a+=1
print "global a: "
print a
if (a<10):
followers_parse_two_link=host+''.join(people_parse_two.xpath('//ol[@class="follow-list clearfix"]/li['+str(a)+']/a/@href').extract())
yield Request(url=followers_parse_two_link,callback=self.parse,dont_filter=True)
# 网上yield解释(模模糊糊的):生成器
# 任何使用yield的函数都称之为生成器
# def count(n):
# while n > 0:
# yield n #生成值:n
# n -= 1
# 使用yield,可以让函数生成一个序列
# 该函数返回的对象类型是"generator",通过该对象连续调用next()方法返回序列值。
# c = count(5)
# c.next()
# >>> 5
# c.next()
# >>>4 这里有个点,就是用户1–>关注者1—>用户2—->关注者2
如果用户1–>关注者1—>用户1—->关注者1这样不停的循环呢?。。
这里我利用到了保存文件名的方法,将用户信息保存到文件(以用户的名字命名),如果下次抓取的用户的名字和文件名一样,则会停止,跳转到之前用户1的关注者2的页面。这样避免死循环
item.py:
class Github_Item(scrapy.Item):
fullname = scrapy.Field()
username = scrapy.Field()
organization = scrapy.Field()
mail = scrapy.Field()
joined = scrapy.Field()
followers = scrapy.Field()
starred = scrapy.Field()
following = scrapy.Field()
popular_repos = scrapy.Field()
repo_contributions = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
pass
对了除了用户信息
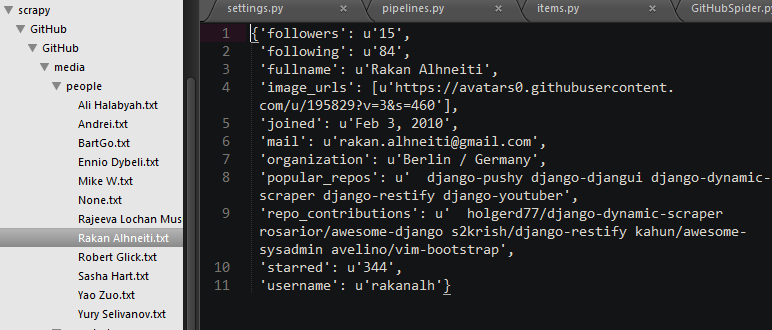
还有用户头像下载pipelines.py:
就按照官方文档来吧,我也一样的。…….
这里我只测试了10几个人的信息,不想搞太多…….
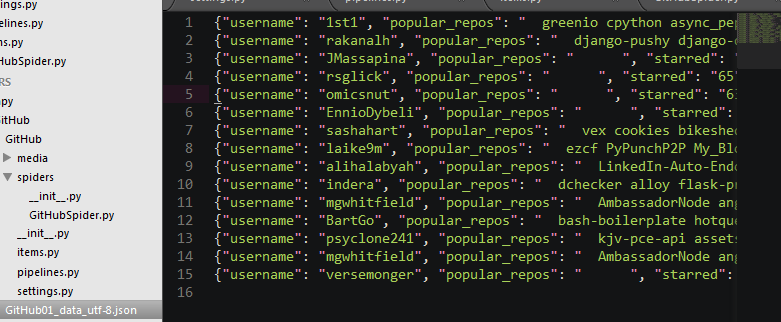
下载下来的图片:
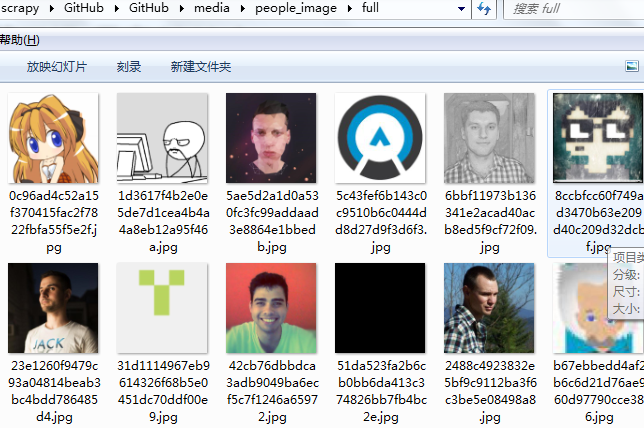
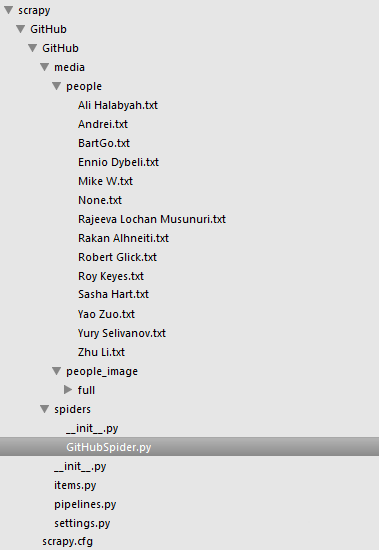
项目结构:
and
注意到这里图片是hash值,而我在网上找了很多改名的方法,都不行。。。。。下次再折腾吧
对了,我试着保存到MongoDB数据库中,没成功,总是GitHub.pipelines.MongoDBpipeline出错,但是我把主代码(GitHubSpider.py里面代码) 移植到我之前写的GitHub爬虫中,MongoDB数据是有响应的,并且帮我保存到好好的。。…….我就郁闷了 难道重新创建爬虫写,再连接MongoDB就连不上呢? 郁闷。。。。。。。。。。。。。。。。。。。。。。。
刚打完上面那几段字,再测试了下 发现连上了。。。。。:
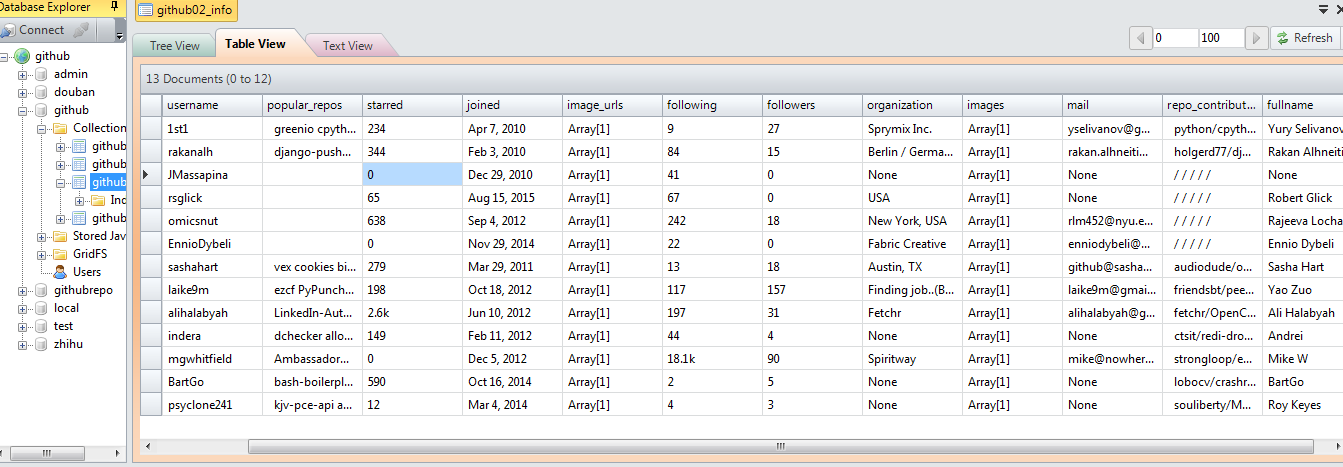
那个Array[1]里面是有数据的 类似[“https://avatars3.githubusercontent.com/u/239003?v=3&s=460“]
OK了。大三真闲,没课。(但尼玛我的事为何还这么多呢?)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)