Python爬虫实战:批量图片数据采集(女生定制篇)
Python爬虫实战:批量图片数据采集(女生定制篇)效果展示工具准备项目思路解析简易源码分析效果展示工具准备数据来源: 喃仁图开发环境:win10、python3.7开发工具:pycharm、Chrome项目思路解析解析网页详情页面地址获取首页的跳转链接和图片标题发送请求进入详情页面提取到准确的图片url地址接下来保存图片大功告成!!!!!!!!!简易源码分析#!/usr/bin/env pyth
·

效果展示
工具准备
数据来源: 喃仁图
开发环境:win10、python3.7
开发工具:pycharm、Chrome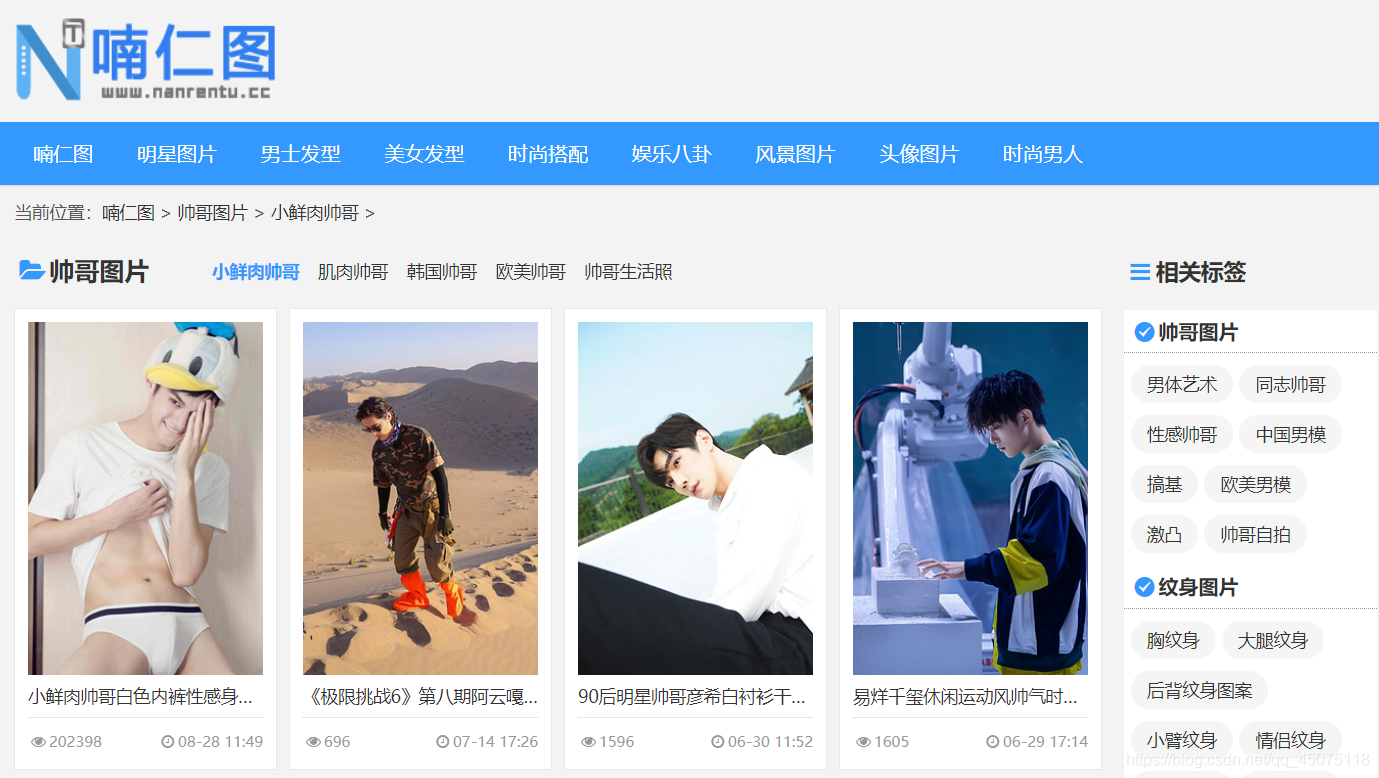
项目思路解析
解析网页详情页面地址
获取首页的跳转链接和图片标题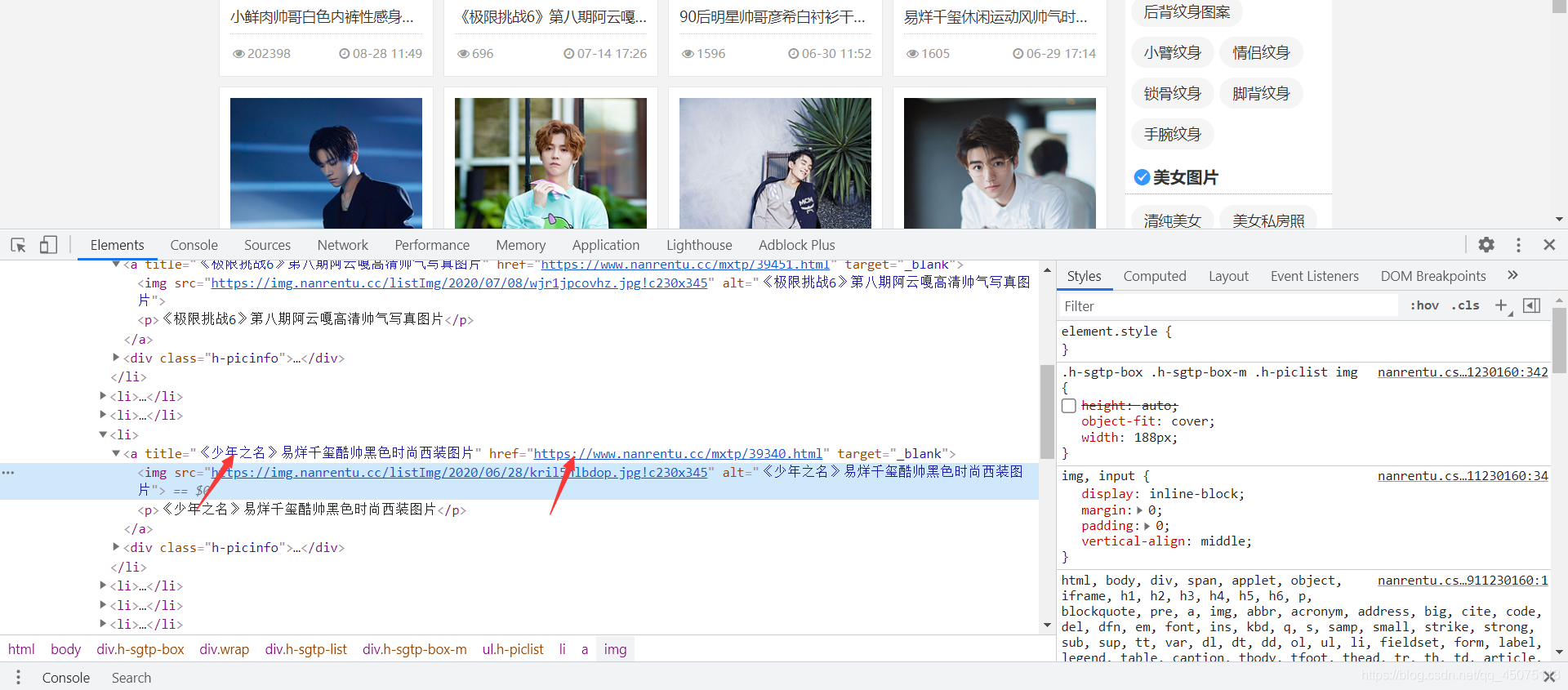
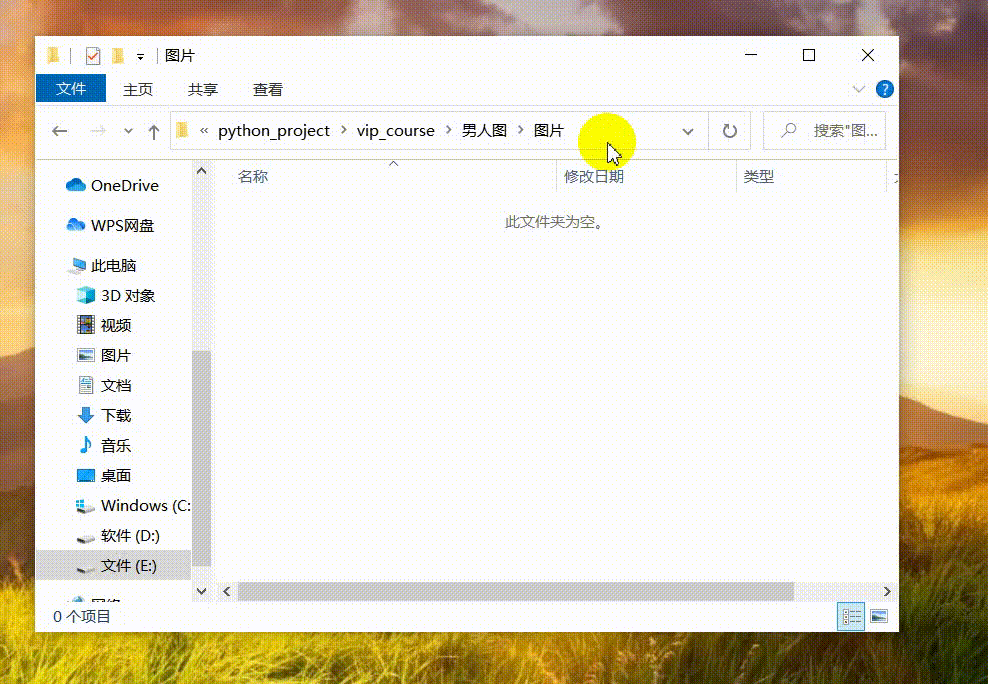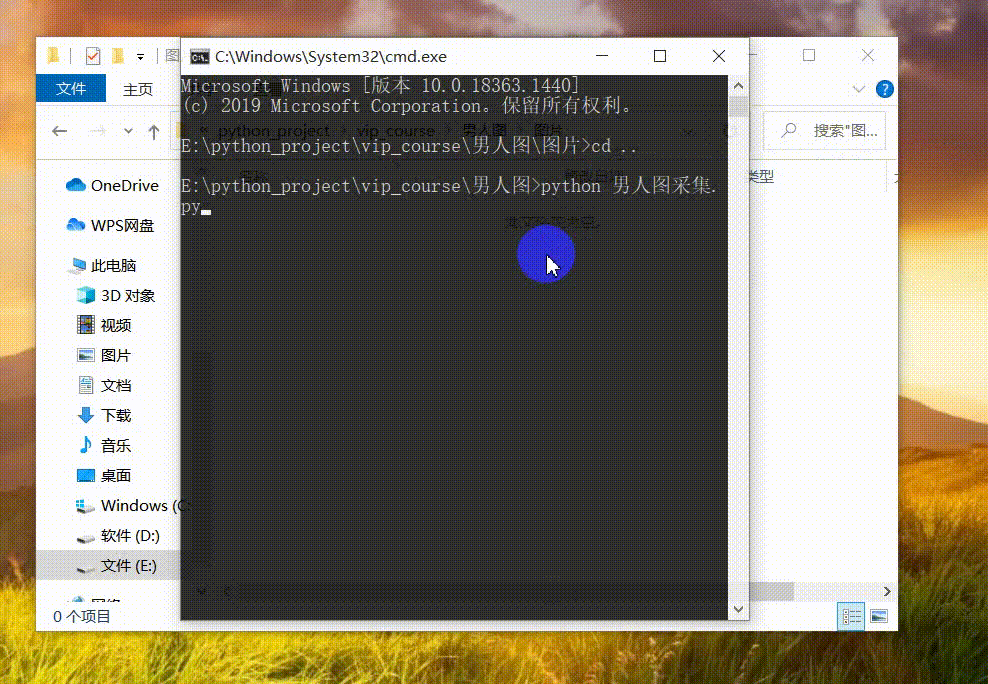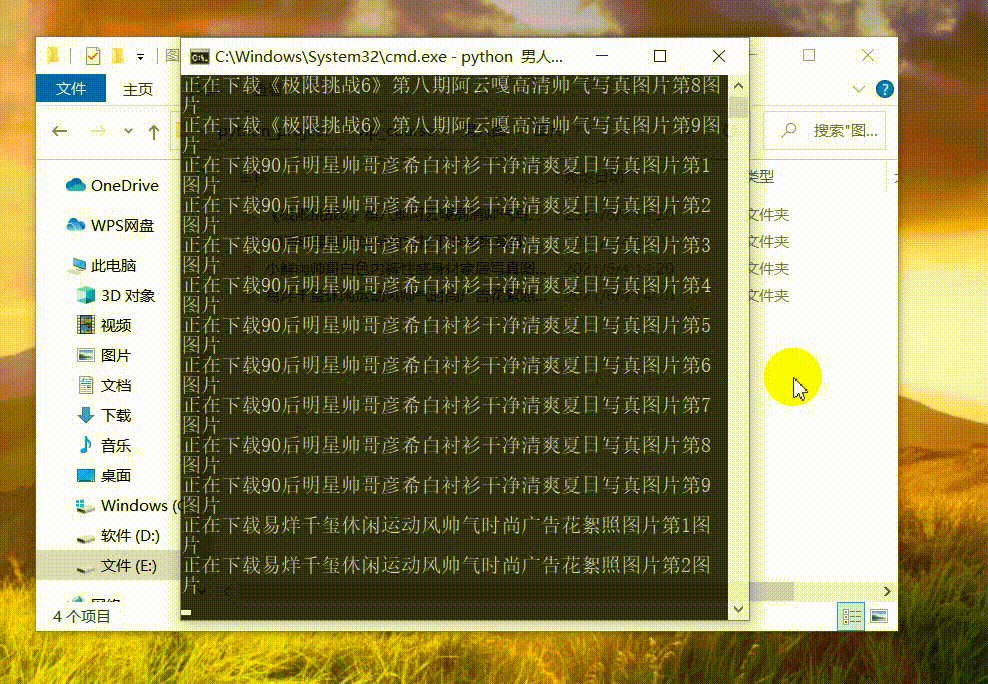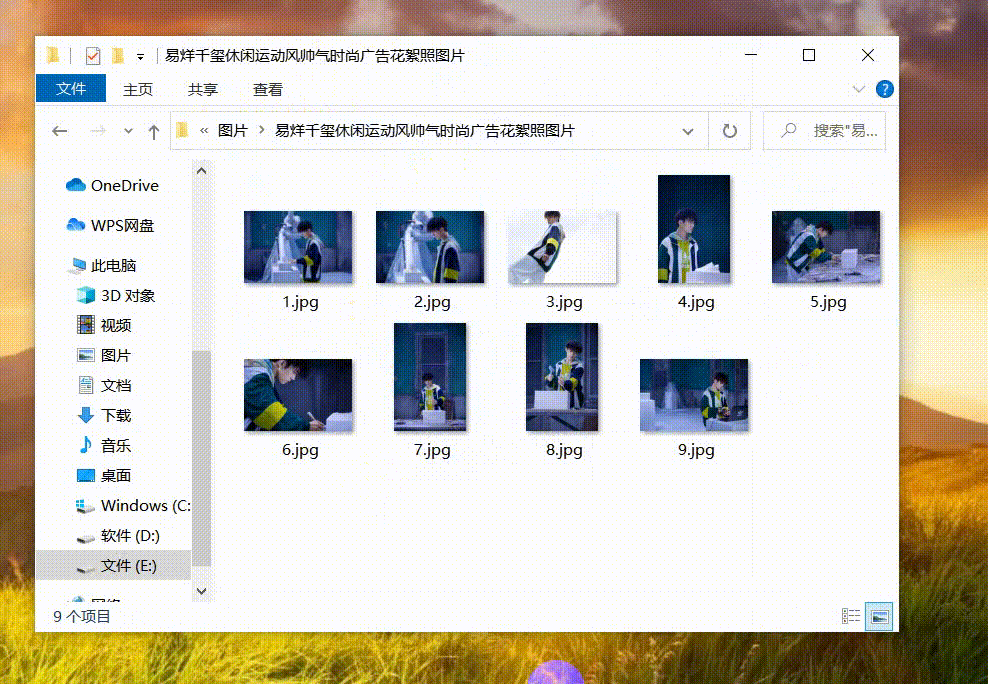
发送请求进入详情页面提取到准确的图片url地址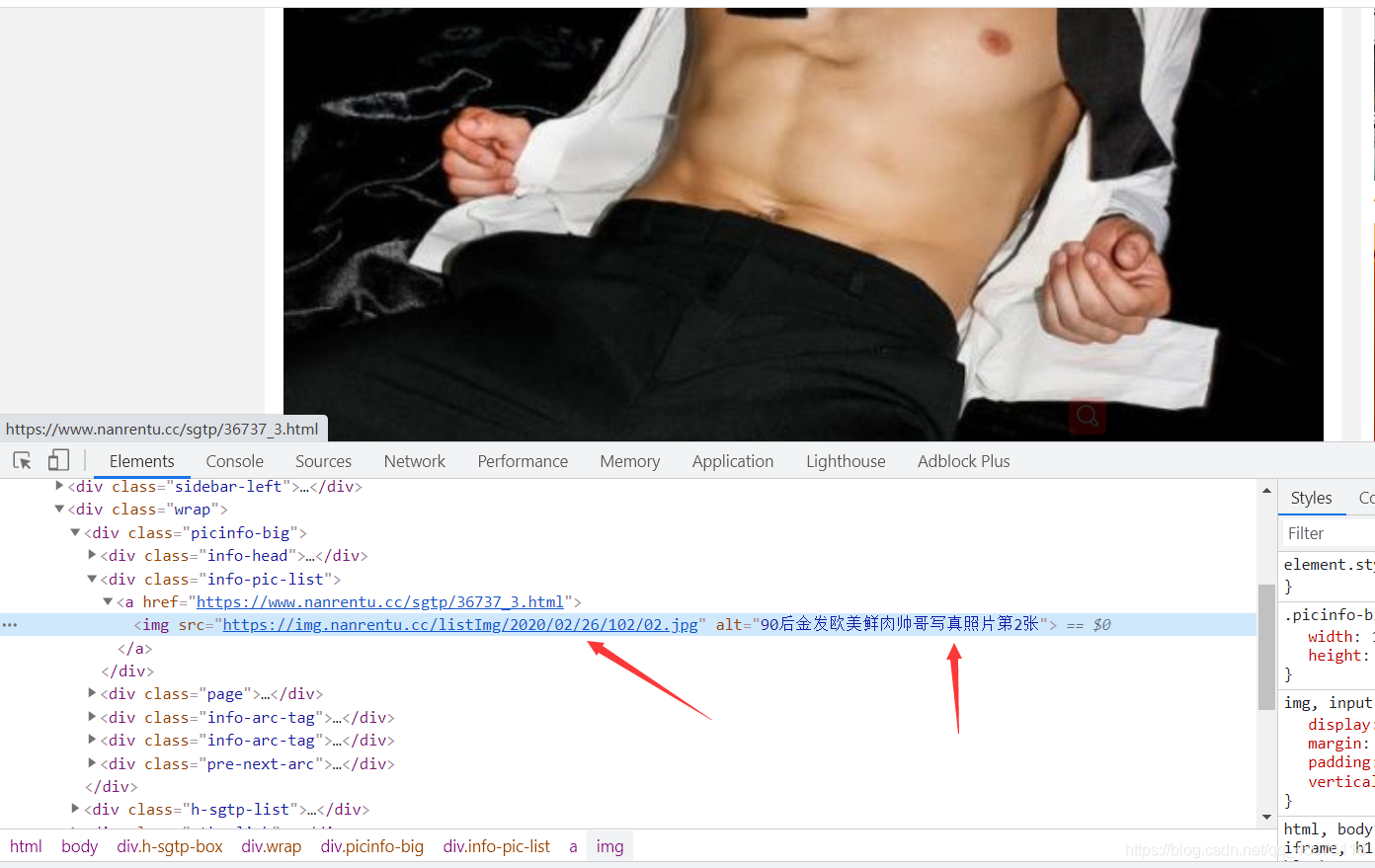
接下来保存图片大功告成!!!!!!!!!
简易源码分析
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : BaiChuan
# @File : 男人图采集.py
import os
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
def get_img_url(url):
response = requests.get(url)
# print(response.text)
info_list = re.findall('<a title="(.*?)" href="(.*?)" target="_blank"> ', response.text)
# url_list = re.findall('<a title=".*?" href="(.*?)" target="_blank"> ', response.text)
# print(data)
for info in info_list:
title = info[0]
path = '图片/' + title
if not os.path.exists(path):
os.mkdir(path)
new_url = info[1].split(".html")[0] + "_{}" + ".html"
num = 1
for i in range(1, 10):
res = requests.get(new_url.format(i), headers=headers)
# print(res.text)
img_url_list = re.findall('><img src="(.*?)" alt=".*?" /></a>', res.text)
if not img_url_list:
break
for img_url in img_url_list:
result = requests.get(img_url, headers=headers).content
with open(path + "/" + str(num) + ".jpg", "wb")as f:
f.write(result)
print("正在下载{}第{}图片".format(title, num))
num += 1
if __name__ == '__main__':
for i in range(1, 2):
url = "https://www.nanrentu.cc/sgtp/xxrsg_{}.html".format(i)
get_img_url(url)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)