AI基本知识浅谈
一、定义人工智能是什么,目前还没有统一的标准。在2021年深圳市人工智能协会的《2021年人工智能发展白皮书》中描述到:人工智能是指研究、模拟人类智能理论、方法、技术及应用系统的一门技术科学,其使机器人代替人类实现认知、识别、分析、决策 等功能,本质是对人的意识与思想信息过程的模拟。【信息来源深圳市人工智能协会】百度百科解释为:用于研究、开发用于模拟、延伸和扩展人的智能理论、方法、技术及应用系统的
一、定义
人工智能是什么,目前还没有统一的标准。在2021年深圳市人工智能协会的《2021年人工智能发展白皮书》中描述到:人工智能是指研究、模拟人类智能理论、方法、技术及应用系统的一门技术科学,其使机器人代替人类实现认知、识别、分析、决策 等功能,本质是对人的意识与思想信息过程的模拟。【信息来源深圳市人工智能协会】
百度百科解释为:用于研究、开发用于模拟、延伸和扩展人的智能理论、方法、技术及应用系统的一门新的科学技术。研究内容包括机器人、语音识别、图像识别、自然语言处理和专家系统等【信息来源百度百科】
相对于上面各平台的解释,国家互联网信息办公室的解释相对通熟易懂些:人工智能就是希望机器能人工智能是研究开发能够模拟、延伸和扩展人类智能的理论、方法、技术及应用系统的一门新的技术科学,研究目的是促使智能机器会听(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说(语音合成、人机对话等)、会思考(人机对弈、定理证明等)、会学习(机器学习、知识表示等)、会行动(机器人、自动驾驶汽车等)。【信息来源中华人民共和国国家互联网信息办公室】
人工智能也可以 理解为高阶的数据分析,同样需要算法、算力与数据。
二、发展历史

【信息来源中华人民共和国国家互联网信息办公室(整理)】
人工智能重大事件:
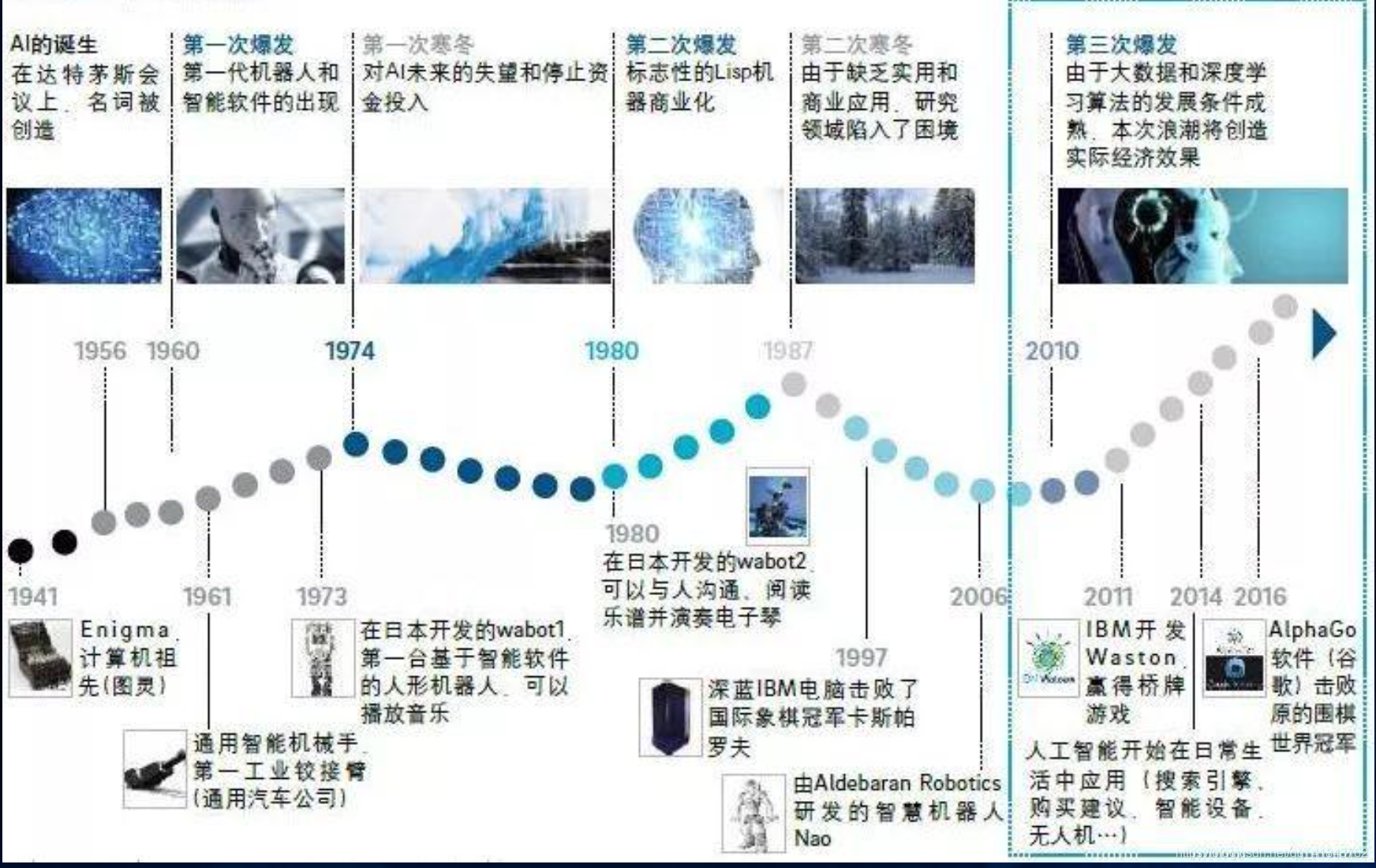
人工智能从一开始的“不可用”、“不好用”到“可以用的”的技术突破,未来还存在很大的发展进步空间。
三、算法
十年前,算法算力是人工智能的重点与难点,但现在随着各大厂的模型开源,数据与特征工程才是决定项目效果的上限,而优化算法与算力只是无限接近这个上限。下面对人工智能算法进行简简单介绍些:
1、监督学习
监督学习可以理解为模拟考试,有试题(数据)、有参考答案(标签、特征),也就是提前告诉你什么题目该怎么做,告诉你对错,然后训练模型,对以后的未知数据按照已有的标准给出决策。这类算法在分类、回归模型中广泛应用。
1.1、强化学习
强化学习也需要标签,只是这里的标签不再只是简单的对与错,而是通过激励机制(分数的正负与大小)进行惩罚,需要机器不断学习,最终的目的是得到标签的最高分。
1.2、深度学习
深度学习是机器学习的一个重要分支,其优点是善于处理高维、大量的数据。是一个自动学习特征的方法。传统的监督学习是人工去大标签,费时费力、且没有规律可循。而深度学习就是机器自动来学习特征,相当机器大标签,然后机器再运用这些标签特征信息来训练模型,输入结果。
1.3、迁移学习
重新训练模型需要花费很大的时间和人力成本,但考虑到大部分数据或任务存在关联性,迁移学习可以把已经训练好的模型参数迁移到新的模型中,加快模型优化效率,而不是像大多数网络模型一样需要重零开始训练模型。
2、无监督学习
相对于有监督学习,无监督学习就是没答案,让你自己摸索。简单粗暴一点解释就是没有特征也想分类,这类算法在聚类模型中应用比较多。
四、项目流程
人工智能项目流程大体上分为5大步骤。数据预处理、特征工程、算法与建模、评估与分析、部署与应用。
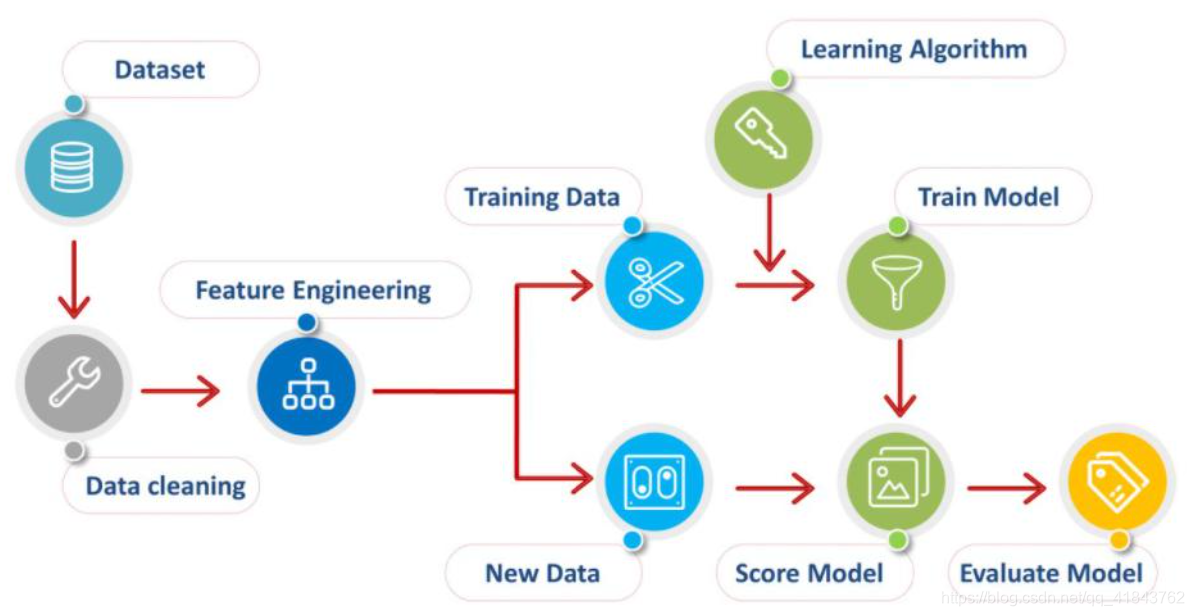
1、数据预处理
数据预处理可以理解为数据清洗,去除脏数据:如异常值、无差异值、NULL等。
2、特征工程
特征提取,也就是给数据设定标签,这是项目的最耗时耗力的一部分,大约占据项目全部时间的70%,特征工程的优劣往往决定着整个效果的上限,是当前人工智能的重点难点。
3、算法与建模
根据业务的需求挑选合适的算法,当前各大厂都提供开源算法,很多项目都是直接套用就是。所以这并不是项目的重点与难点,算法的挑选与模型训练的好坏只能是无限逼近项目效果的上限。
4、评估与分析
这也是比较花时间的一环节,需要不断的调整、迭代与更新。
5、部署与应用
部署需要不仅仅要考虑技术、还有考虑硬件设备与成本等。很多模型在服务器上相对容易,但是在嵌入式设备上就会出现很多bug。
五、经典模型
传统的人工智能模型有十多个,但只从神经网络出现后,它们很多都开始消失于大家的视野,这里仅简单介绍下其中5大曾经风靡一时的经典算法,其中有些算法现在很多工程师依旧在使用。
1、树模型
简单一点理解,树模型就是多层分类。因为其解释好,是神经网络无法替代的一点,现在8层以上的机器学习算法都给予树模型。
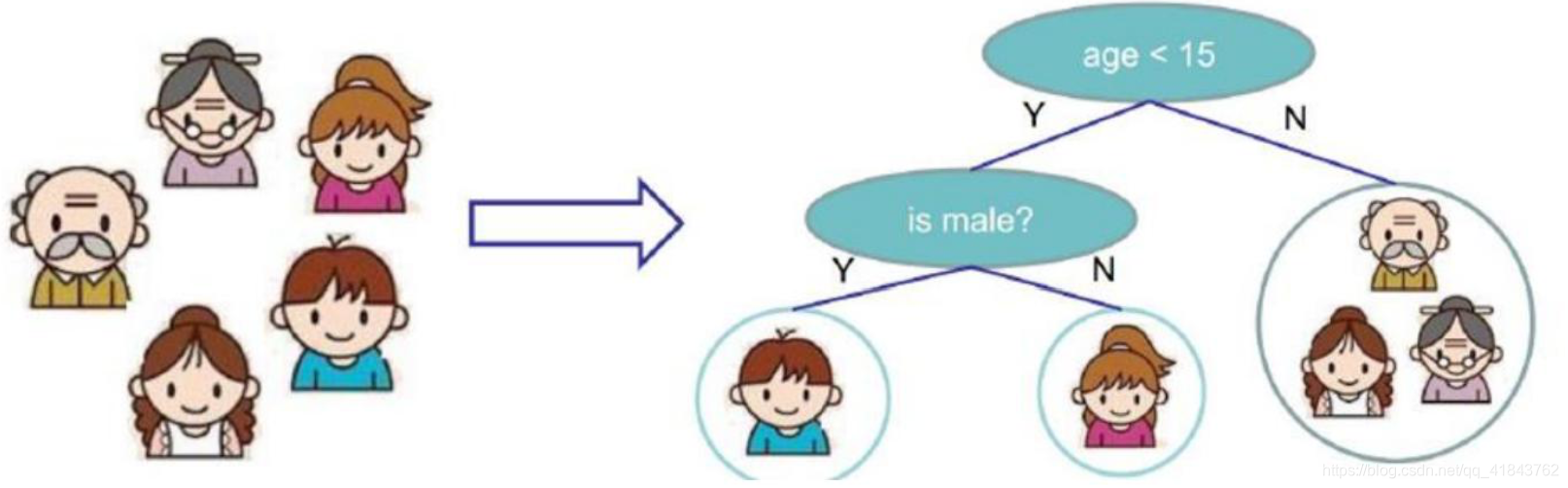
其特点:
1.1、简单实用、可直接套用模型
1.2、具有很强的可视化效果,这也代表其具有很强的解析与分析能力
1.3、泛化能力强,适用于很多模型
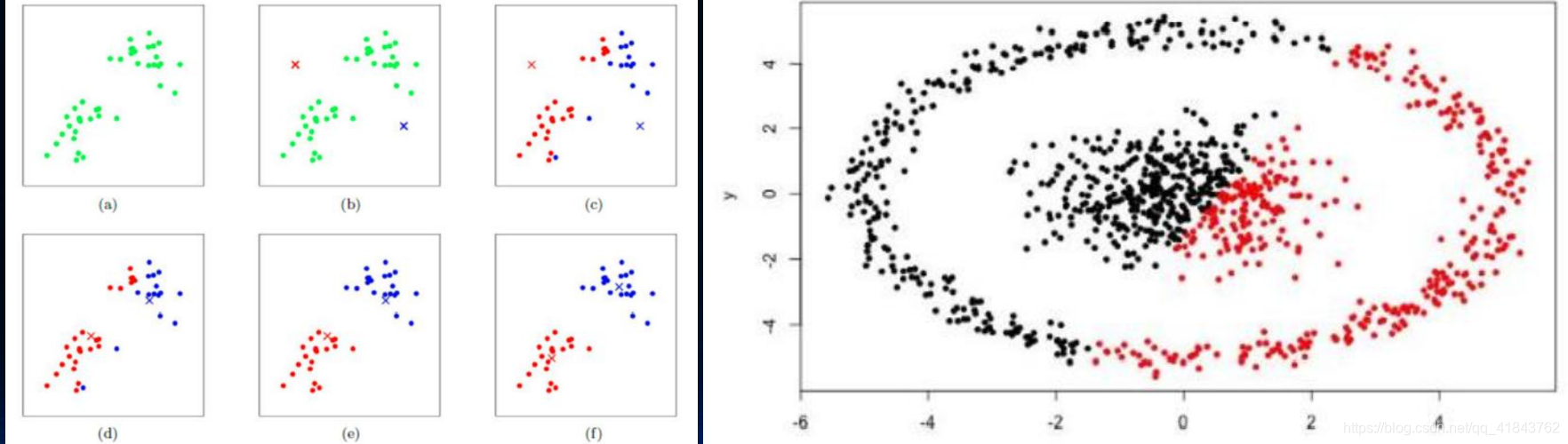
2、聚类模型
聚类模型(DBSCAN)前面也有聚类的相关介绍,也就是事先没有添加标签,希望模型自己给输入的数据进行分类。
这类模型可解释差,输入数据后,直接给出结果,至于为什么这样,大家都不知道。它的强项是异常数据监测。
3、集成模型
集成模型,根据字面意思就是一起上,不会听从个别结果,而是根据“大家”的反馈择优选择。
如分类问题遵从少数听从多数原理;回归问题反馈平均值。
4、支持向量机
十年前,支持向量机曾火遍大江南北,概念也是蛮高级和新颖的。
处理逻辑:当低维数据处理碰到问题时,可以把低维数据映射到高维处理。听着可能有点蒙圈,比如说我们要划分三维空间上的点,如果从二维空间上去划分,可能有点难度,但是你从三维空间去划分时,就显得简单明了,且可解释性良好。
如此类推,二维信息解释不通,映射到三维,三维信息解释不通,映射到四维......
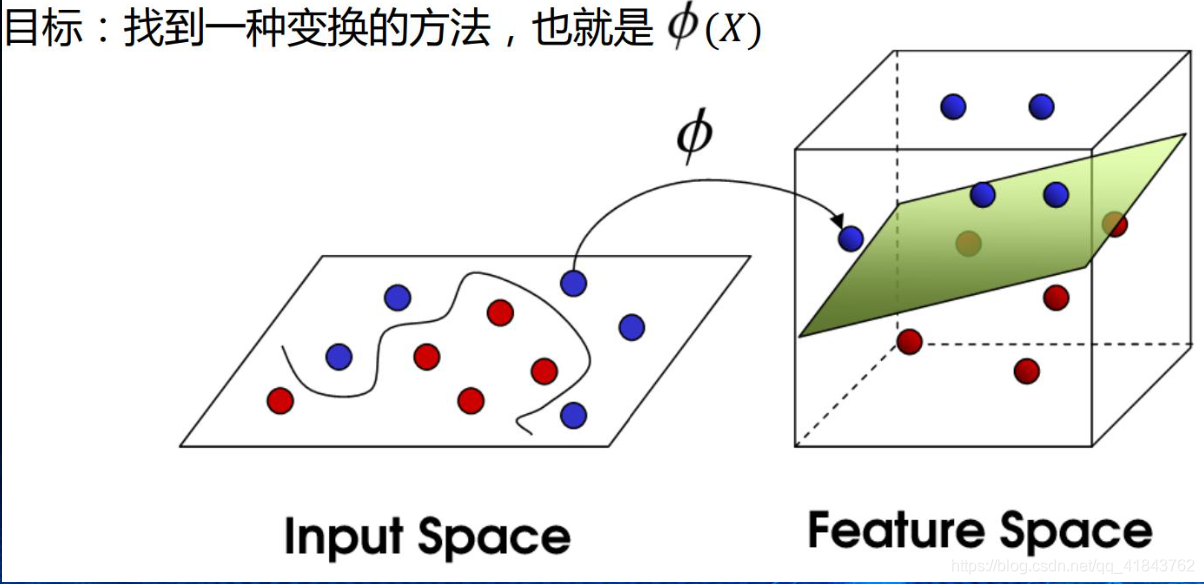
5、贝叶斯模型
贝叶斯模型是一个注重先验知识的模型。比如你有天去赌场,一开始去还不敢开赌,那就先观察几局吧,你坚持跟踪了10位朋友,结果发现他们都是赢钱的。按一般的模型算法,你把这一批原始数据和结果输入机器,它会告诉你赢钱的几率时100%。但你的之前的生活经验告诉你,赌博是十赌九输的,所以你现在开赌,输的可能性还是90%。
这就是典型的贝叶斯模型理论,它来源于我们高中数据概率论,但它忽略了先验知识也是有针对性的。
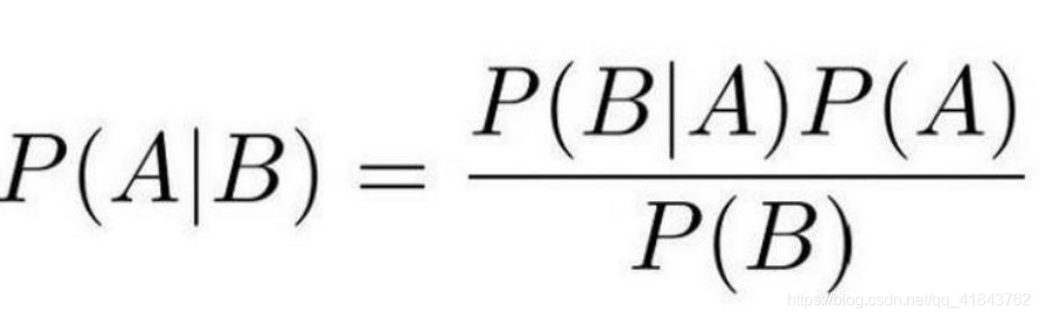
如小明每天早上6点起床背书,考试能得100分,如果7点起来,那么她的考试智能60分。所以机器得到的先验知识:是6点起床可以考100分,7点起床只能得60分。殊不知那只是针对小明有效,换成小红,人家习惯晚上背书,早上7点起床也能考100分。
现在的情况是贝叶斯模型比较适用于文本任务,其他领域应用较少。
六、应用场景
1、数据分析
数据分析更多强调的是人为,可依靠已有的业务知识人为的设定某些关键指标,如销售额、利润率、日活跃、交易量等。再去数据库查询获取数据制成可视化报表,然后再人为的分析业务结果并作出相对应的决策,整个过程都是人为在主导。
2、数据挖掘
如果说数据分析更多注重“我认为”、在数据挖掘中则是“机器认为”。
当把原始数据输入后,机器会自动分析业务好坏的效果与哪些因素有光,这些相关因素中,哪些影响比较大,哪些可有可无(即这些因素的权重值与偏置值),当然这个过程,特征过程是必不可少的。

数据挖掘是当下最热门的领域之一,工艺参数化(如工业制造中,零件的好坏与哪些因素火步骤有关,以后专攻这方面的改进,相对于传统的靠有经验工程师用“感觉”判断相对靠谱很多),很多业务决策都靠它。
3、特征工程
特征工程前面也有过介绍,就是给原始数据大标签。特征工程决定结果的上限,而算法模型的调优只能是无限的逼近这个上限值。
它也是最耗时、最烧脑的环节,基本全靠人工干苦力活来解决。
4、量化交易
量化交易主要分析序列问题,如时间序列,但实际运用中,有些项目效果变得很不靠谱,股票K线图,那是因为大家忽略了一点:时间序列是根据历史数据来预测未来数据,然后再根据预测的结果继续预测更远的未来。这里需要保证一点就是未来数据与历史数据的分布趋势相吻合香型。而股票存在态度异常因素:如国家政策、黑天鹅事件......而这些因素对股票趋势有着重大的影响。因为量化交易在股票K线图的运用上效果是不可信的,只能提供参考价值。
5、风控领域
知识图谱在这方面运用比较多,机器学习的不仅仅是独立的样本数据,它们之间的关系也可以。它的本质还是建模,但是一个相对综合的领域,多方面去评价用户信息。
6、工业制造
现阶段存在大量的传统工业转型案例,很大程度上来源于AI在工业制造的运用。如:
新能源企业:机器学习模型寻找合适的电解质材料,今儿设计与加工,优化性能
汽车企业:机器学习建模碰撞测试,寻找合适的车型设计指标
化工企业:机器学习建模安全识别,实时监控安全问题
车间流水线:智能识别,缺陷检测等,替代大量人工操作

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)