线性判别分析_Fisher 线性判别分析
Note: 将 Fisher 判别分析放入非参这一部分框架来讲,原因是在Fisher判别分析里同样没有假设数据的分布形式,而是以基于投影后的数据形态的Fisher指标作为优化线性模型的依据。 1. Background and Motivation 在统计学习的模式识别问题中,我们常常会遇到一个令人头疼的问题:维数灾难。50-100维,已经算是一个高维问题了。从参数估计的方法来看,我们对高维数据的
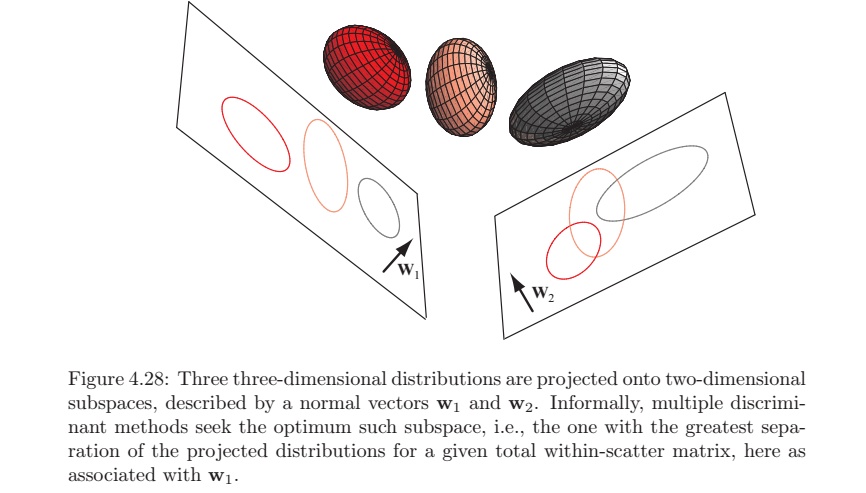
Note: 将 Fisher 判别分析放入非参这一部分框架来讲,原因是在Fisher判别分析里同样没有假设数据的分布形式,而是以基于投影后的数据形态的Fisher指标作为优化线性模型的依据。
1. Background and Motivation
在统计学习的模式识别问题中,我们常常会遇到一个令人头疼的问题:维数灾难。50-100维,已经算是一个高维问题了。从参数估计的方法来看,我们对高维数据的联合概率分布知之甚少,尤其是多维特征间有依赖关系时,我们更是难以给出一个合理的分布假设;从非参估计的角度来看,维数灾难对估计所需样本的体量提出了巨大的挑战。那么怎么去应对这样的高维数据呢?
机器学习往往假设这些高维特征是具有相关性,或是冗余的。他们的数据结构往往可以嵌入在某个低维的空间中。因此,解决高维特征的一种经典思路是对原有的高维数据进行降维,希望新的低维空间(
2. Basic idea
在没有训练数据类标信息的情况下,PCA 降维将尽可能地寻找最优的子空间来表达原数据的结构特征;
在有监督的情况下,Fisher 线性判别分析 (LDA, Linear Discriminative Analysis) 则是一种经典的方法。我们往往希望找到一个针对数据
这一最优投影方向
3. Fisher LDA: 二分类问题
(1) Basic idea
我们从二分类问题开始讨论,这时候我们将原
对于得到的低维投影,我们希望不同类别地投影能尽可能的区分开来,而同一类别的投影尽可能地靠近。下图中,右边的投影向量就优于左边的投影向量,因为它的投影
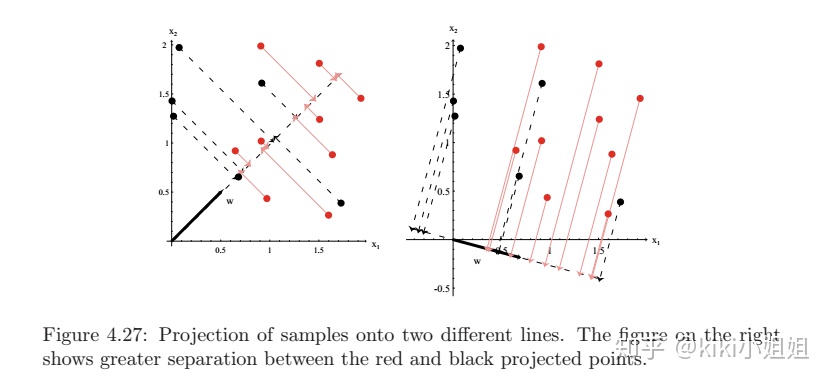
一方面,为了使得不同类别地投影能尽可能的区分开来,我们考虑这两类的样本均值,
我们希望这两类的样本均值尽可能地背离, 即
另一方面,为了使得同一类别的投影尽可能地靠近,我们考虑类内样本的散度,
综上,Fisher 判别分析的目标是,
(2) Derivation
我们将
其中,
具体推导过程如下:
而 类间散度为:
其中,
这一问题转化为
通过Fisher 判别分析,我们通过向量
4. Fisher LDA的优缺点:
(1)优点: Fisher LDA 在有监督的情况下,最大化地保留了分类信息,这一分类信息由一个非参指标,Fisher 指标来衡量。
(2)缺点: Fisher LDA 只能将数据降到
参考文献:
Duda R O, Hart P E. Pattern recognition and scene analysis[J]. 1973.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)