中学生人工智能入门学习0基础学习AI人工智能深度学习神经网络
第一章 图像处理Pillow库的安装11.2图象处理基本知识人脸识别语音识别手写数字识别
目录
1.2.1图像的RGB色彩模式......................................................................... 1
1.3.7分离和合并....................................................................................... 10
1.3.9其他内置函数.................................................................................... 11
2.1.1语音识别概念.................................................................................... 32
2.1.2语音识别原理.................................................................................... 32
2.1.3语音识别技术.................................................................................... 33
2.2.3 SpeechLib的使用............................................................................... 36
2.3.1 PocketSphinx的使用.......................................................................... 36
3.3.2图片灰度转换.................................................................................... 41
3.3.3修改图片尺寸.................................................................................... 43
3.4.1 Haar级联的概念................................................................................ 46
3.4.2获取Haar级联数据........................................................................... 46
3.5使用OpenCV进行人脸检测........................................................................ 48
3.5.1静态图像中人脸检测......................................................................... 48
3.5.2视频中的人脸检测............................................................................. 50
3.6.2基于LBPH的人脸识别...................................................................... 53
第四章 基于TensorFlow人工智能实战................................................................... 57
4.1.1神经网络原理.................................................................................... 57
4.2.2双曲正切函数(tanh)....................................................................... 61
4.3.2 TensorFlow的数据流图...................................................................... 64
4.3.4 TensorBoard可视化............................................................................ 66
4.4.1线性回归案例实现............................................................................. 76
4.4.2添加变量显示.................................................................................... 78
4.4.3增加命名空间.................................................................................... 79
4.4.4保存读取模型.................................................................................... 80
4.5.1 MNIST数据集简介............................................................................ 81
4.5.2加载MNIST数据集........................................................................... 82
4.5.3手写数字识别.................................................................................... 83
案例目录
【示例1-4】缩放指定的图片,实现图像每个像素值×2..................................................... 5
【示例1-5】缩放图片为指定的大小................................................................................. 6
【示例1-6】对指定图片剪切和粘贴操作.......................................................................... 7
【示例1-9】图片进行合并和分离操作............................................................................ 10
【示例1-10】图片实现滤镜模糊操作.............................................................................. 11
【示例1-11】使用ImageFilter对指定图片实现滤镜特效.................................................. 12
【示例1-13】使用subtract()函数实现图片合成............................................................... 15
【示例1-14】使用darker()函数实现图片合成.................................................................. 16
【示例1-15】使用lighter()函数实现图片合成.................................................................. 16
【示例1-16】使用multiply()函数实现图片合成............................................................... 17
【示例1-17】使用screen()函数实现图片合成.................................................................. 18
【示例1-18】使用invert()函数实现图片合成................................................................... 18
【示例1-19】使用difference()函数实现图片合成............................................................. 19
【示例1-20】使用ImageEnhance实现图像色彩平衡....................................................... 20
【示例1-21】使用图像点运算实现图像整体变暗、变亮.................................................. 21
【示例1-22】ImageDraw模块实现创建图片的方式来绘图............................................... 23
【示例1-23】ImageDraw模块实现在原图片上绘制......................................................... 24
【示例1-24】ImageFont实现对字体和字型的处理.......................................................... 26
【示例1-28】将图片中的黄色变换成红色....................................................................... 29
【示例2-1】使用pyttsx实现文本转换语音..................................................................... 35
【示例2-2】使用SAPI实现文本转换语音........................................................................ 36
【示例2-3】使用SpeechLib实现文本转换语音................................................................ 36
【示例2-4】使用PocketSphinx实现语音转换文本........................................................... 37
【示例3-2】cvtColor()函数实现图片灰度转换.................................................................. 42
第四章 基于TensorFlow人工智能实战................................................................... 57
【示例4-1】使用matplotlib绘制Sigmoid函数................................................................ 60
【示例4-2】使用matplotlib绘制tanh函数..................................................................... 61
【示例4-3】使用TensorFlow实现加法运算..................................................................... 63
【示例4-6】将数据序列化成events文件........................................................................ 66
【示例4-18】使用TensorFlow来读取数据及标签............................................................ 82
第一章 图像处理
Pillow是Python Imaging Library的简称,是Python语言中最为常用的图像处理库。Pillow库提供了对Python3的支持,为Python3解释器提供了图像处理的功能。通过使用Pillow库,可以方便地使用Python程序对图片进行处理,例如常见的尺寸、格式、色彩、旋转等处理。
通过阅读本章,你可以:
- 了解像素的基础知识
- 掌握如何使用Image模块对图片进行复制、粘贴、裁剪、缩放、旋转等操作
- 掌握如何使用ImageFilter模块实现滤镜功能
- 掌握如何使用ImageChops模块实现图片合成
- 掌握如何使用ImageEnhance模块调整图像的色彩、对比度、亮度和清晰度等
- 掌握如何使用ImageDraw模块在图片上进行绘图
- 掌握如何使用ImageFont模块实现对字体和字型的处理
 1.1 Pillow库的安装
1.1 Pillow库的安装
Pillow库是Python开发者最为常见的图像处理库,它提供了广泛的文件格式支持、强大的图像处理能力,主要包括图像存储、图像显示、格式转换以及基本的图像处理操作等。安装Pillow库的方法与安装Python其他第三方库的方法相同,也可以到Python官方网站下载Pillow库的压缩包。使用pip安装 pillow,执行如下命令:
|
pip install pillow |
1.2图象处理基本知识
1.2.1图像的RGB色彩模式
人类迄今为止任一种事务,肯定有规律。如果某个领域仍然没有突破,只能说还未找到规律。图像的发展史也是遵循了一定规律。如三原色的发现、数字图像理论的发展,都最终让图像处理有了革命性的变化。
RGB三个颜色通道的变化和叠加得到各种颜色,其中:
- R红色,取值范围,0-255
- G绿色,取值范围,0-255
- B蓝色,取值范围,0-255
比如,常见的黄色就是由红色和绿色叠加而来。
红色的RGB表示(255,0,0) 绿色的RGB表示(0,255,0)
蓝色的RGB表示(0,0,255) 黄色的RGB表示(255,255,0)
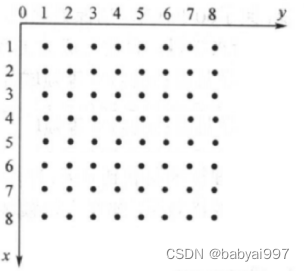
1.2.2像素阵列
数字图像可以看成一个整数阵列,阵列中的元素称为像素(Pixel),见图1-1所示的数字阵列。
图1-1 数字阵列
每个点代表1个像素(Pixel),一个点包含RGB三种颜色。也就是1个像素包含3个字节的信息:(R,G,B)。假如这个像素是红色,则信息是:(255,0,0)。那么,理论上只要操作每个点上的这三个数字,就能实现任何的图形。一幅图像上的所有像素点的信息就完全可以采用矩阵来表示,通过矩阵的运算实现更加复杂的操作。
1.3 Image模块
1.3.1打开和新建
在Pillow库中,通过使用Image模块,可以从文件中加载图像,或者处理其他图像,或者从scratch中创建图像。在对图像进行处理时,首先需要打开要处理的图片。在Image模块中使用函数open()打开一副图片,执行后返回Image类的实例。当文件不存在时,会引发IOError错误。使用函数open()语法格式如下所示:
|
open(fp,mode) |
fp:指打开文件的路径。
mode:可选参数,表示打开文件的方式,通常使用默认值r。
在Image模块中,可以使用函数new()新建图像。具体语法格式如下所示:
|
new(mode,size,color=0) |
mode:图片模式,具体取值如下表。
size:表示图片尺寸,是使用宽和高两个元素构成的元组。
color:默认颜色(黑色)。
表1-1 Pillow库支持的常用图片模式信息
|
mode(模式) |
bands(通道) |
说明 |
|
“1” |
1 |
数字1,表示黑白二值图像,每个像素用0或者1共1位二进制代码表示 |
|
“L” |
1 |
灰度图,每个像素用8位二进制代码表示 |
|
mode(模式) |
bands(通道) |
说明 |
|
“P” |
1 |
索引图,每个像素用8位二进制代码表示 |
|
“RGB” |
3 |
24位真彩图,每个像素用3个字节的二进制代码表示 |
|
“RGBA” |
4 |
“RGB”+透明通道表示,每个像素用4字节的二进制代码表示 |
|
“CMYK” |
4 |
印刷模式图像,每个像素用4字节的二进制代码表示 |
|
“YCbCr” |
3 |
彩色视频颜色隔离模式,每个像素用3个字节的二进制代码表示 |
|
“LAB” |
3 |
lab颜色空间,每个像素用3字节的二进制代码表示 |
|
“HSV” |
3 |
每个像素用3字节的二进制代码表示 |
|
“I” |
1 |
使用整数形式表示像素,每个像素用4字节的二进制代码表示 |
|
“F” |
1 |
使用浮点数形式表示像素,每个像素用4字节的二进制代码表示 |
【示例1-1】使用Image打开图片
|
#导入Image模块 from PIL import Image #打开图片 im=Image.open('bjsxt.png') #显示图片 im.show() #查看图片的信息 print('图像格式:',im.format) print('图像大小,格式是(宽度,高度):',im.size) print('图像宽度:',im.width,'图像高度:',im.height) print('读取坐标在(100,100)处的像素的信息:',im.getpixel((100,100))) |
运行结果如图1-2所示:

图1-2 示例1-1运行效果图
 1.3.2混合
1.3.2混合
- 透明度混合处理
在Pillow库的Image模块中,可以使用函数blend()实现透明度混合处理。具体语法格式如下所示:
|
blend(im1,im2,alpha) |
其中im1、im2指参与混合的图片1和图片2,alpha指混合透明度,取值是0-1。
通过使用函数blend(),可以将im1和im2这两幅图片(尺寸相同)以一定的透明度进行混合。具体混合过程如下:
|
(im1*(1-alpha)+im2*alpha) |
当混合透明度为0时,显示im1原图。当混合透明度alpha取值为1时,显示im2原图片。
【示例1-2】图片透明度混合处理
|
from PIL import Image img1=Image.open('bjsxt.png').convert(mode="RGB") img2=Image.new("RGB",img1.size,"red") # #混合两幅图 Image.blend(img1,img2,alpha=0.5).show() |
运行结果如图1-3所示:

图1-3 示例1-2运行效果图
- 遮罩混合处理
在Pillow库中Image模块中,可以使用函数composite()实现遮罩混合处理。具体语法格式如下所示:
|
composite(im1,im2,mask) |
其中im1和im2表示混合处理的图片1和图片2。mask也是一个图像,mode 可以为“1”,“L”,or “RGBA”,并且大小要和im1、im2一样。
函数composite()的功能是使用mask来混合图片im1和im2,并且要求mask、im1和im2三幅图片的尺寸相同。下面的实例代码演示了使用Image模块实现图片遮罩混合处理的过程。
【示例1-3】图片遮罩混合处理
|
from PIL import Image img1=Image.open('blend1.jpg') img2=Image.open('blend2.jpg') img2=img2.resize(img1.size) r,g,b=img2.split() Image.composite(img2,img1,b).show() |
运行结果如图1-4所示:

图1-4 示例1-3运行效果图
 1.3.3复制和缩放
1.3.3复制和缩放
- 复制图像
在Pillow库的Image模块中,可以使用函数Image.copy()复制指定的图片,这可以用于在处理或粘贴时需要持有源图片。
- 缩放像素
在Pillow库的Image模块中,可以使用函数eval()实现像素缩放处理,能够使用函数fun()计算输入图片的每个像素并返回。使用函数eval()语法格式如下:
|
eval(image,fun) |
其中image表示输入的图片,fun表示给输入图片的每个像素应用此函数,fun()函数只允许接收一个整型参数。如果一个图片含有多个通道,则每个通道都会应用这个函数。
【示例1-4】缩放指定的图片,实现图像每个像素值×2
|
from PIL import Image img=Image.open('img2.jpg') Image.eval(img,lambda i:i*2).show() |
运行结果如图1-5所示:

图1-5 示例1-4运行效果图
- 缩放图像
在Pillow库的Image模块中,可以使用函数thumbnail()原生地缩放指定的图像 。具体语法格式如下:
|
Image.thmbnail(size,resample=3) |
【示例1-5】缩放图片为指定的大小
|
from PIL import Image img=Image.open('img2.jpg') imgb=img.copy() #缩放为指定大小(220,168) imgb.thumbnail((220,168)) imgb.show() |
运行结果如图1-6所示:

图1-6 示例1-5运行效果图
1.3.4粘贴和裁剪
- 粘贴
在Pillow库的Image模块中,函数paste()的功能是粘贴源图像或像素至该图像中。具体语法格式如下:
|
Image.paste(im,box=None,mask=None) |
其中im是源图或像素值;box是粘贴的区域;mask是遮罩。参数box可以分为以下3中情况。
1.(x1,y1):将源图像左上角对齐(x1,y1)点,其余超出被粘贴图像的区域被抛弃。
2.(x1,y1,x2,y2):源图像与此区域必须一致。
3. None:源图像与被粘贴的图像大小必须一致。
- 裁剪图像
在Pillow库的Image模块中,函数crop()的功能是剪切图片中box所指定的区域,具体语法如下:
|
Image.crop(box=None) |
参数box是一个四元组,分别定义了剪切区域的左、上、右、下4个坐标。
【示例1-6】对指定图片剪切和粘贴操作
|
from PIL import Image img=Image.open('bjsxt.png') #复制图片 imgb=img.copy() imgc=img.copy() #剪切图片 region=imgb.crop((5,5,120,120)) #粘贴图片 imgc.paste(region,(30,30)) imgc.show() |
运行结果如图1-7所示:

图1-7 示例1-6运行效果图
 1.3.5图像旋转
1.3.5图像旋转
在Pillow库的Image模块中,函数rotate()的功能返回此图像的副本,围绕其中心逆时针旋转给定的度数。具体语法格式如下:
|
Image.rotate(angle,resample = 0,expand = 0,center = None,translate = None,fillcolor = None ) |
【示例1-7】函数rotate()实现图像旋转
|
from PIL import Image img=Image.open('bjsxt.png') img.rotate(90).show() |
运行结果如图1-8所示:

图1-8 示例1-7运行效果图
1.3.6格式转换
- covert()
在Pillow库的Image模块中,函数convert()的功能是返回模式转换后的图像实例。具体转换的语法格式如下:
|
Image.convert(mode=None,matrix=None,dither=None,palette=0,colors=256) |
其中mode:转换文件的模式,默契支持的模式有“L”、“RGB”“CMYK”;matrix:转使用的矩阵;dither:取值为None切转为黑白图时非0(1-255)像素均为白,也可以设置此参数为FLOYDSTEINBERG。
- transpose()
在Pillow库的Image模块中,函数transpose()函数功能是实现图像格式的转换。具体语法格式如下:
|
Image.transpose(method) |
转换图像后,返回转换后的图像,“method”的取值如下所示:
PIL.Image.FLIP_LEFT_RIGHT:左右镜像。
PIL.Image.FLIP_TOP_BOTTOM :上下镜像。
PIL.Image.ROTATE_90:旋转90。
PIL.Image.ROTATE_180:旋转180。
PIL.Image.ROTATE_270:旋转270。
PIL.Image.TRANSPOSE :颠倒顺序。
【示例1-8】图片进行转换操作
|
from PIL import Image #打开指定的图片 img1=Image.open('bjsxt.png') img2=img1.copy() #convert() img_convert=img2.convert('CMYK') # img_convert.show() #transpose() img_transpose=img2.transpose(Image.ROTATE_90) img_transpose.show() |
运行结果如图1-9所示:

图1-9 示例1-8运行效果图
1.3.7分离和合并
- 分离
在Pillow库的Image模块中,使用函数split()可以将图片分割为多个通道列表。使用函数split()的语法格式如下所示:
|
Image.split() |
- 合并
在Pillow库的Image模块中,使用函数merge()可以将一个通道的图像合并到更多通道图像中。使用函数merge()的语法格式如下所示:
|
Image.merge(mode,bands) |
其中mode指输出图像的模式,bands波段通道,一个序列包含单个带图通道。
【示例1-9】图片进行合并和分离操作
|
from PIL import Image img1=Image.open('blend1.jpg') img2=Image.open('blend2.jpg') img2=img2.resize(img1.size) r1,g1,b1= img1.split() r2,g2,b2= img2.split() tmp=[r1,g2,b1] img = Image.merge("RGB",tmp) img.show() |
运行结果如图1-10所示:

图1-10 示例1-9运行效果图
 1.3.8滤镜
1.3.8滤镜
在Pillow库中的Image模块中,使用函数filter()可以对指定的图片使用滤镜效果,在Pillow库中可以用的滤镜保存在ImageFilter模块中。使用函数filter()的语法格式如下所示:
|
Image.filter(filter) |
通过函数filter(),可以使用给定的滤镜过虑指定的图像,参数“filter”表示滤镜内核。
【示例1-10】图片实现滤镜模糊操作
|
from PIL import Image,ImageFilter #使用函数filter()实现滤镜效果 img=Image.open('bjsxt.png') b=img.filter(ImageFilter.GaussianBlur) b.show() |
运行结果如图1-11所示:

图1-11 示例1-10运行效果图
1.3.9其他内置函数
在Pillow库的Image模块中,还有很多其他重要的内置函数和属性。
常用的属性:
- Image.format:源图像格式。
- Image.mode:图像模式字符串。
- Image.size:图像尺寸。
在Pillow库的Image模块中,其他常用的内置函数如下所示:
- Image.getbands():获取图像每个通道的名称列表,例如RGB图像返回[‘R’,’G’,’B’]。
- Image.getextrema():获取图像最大、最小像素的值。
- Image.getpixel(xy):获取像素点值。
- Image.histogram(mask=None,extrema=None):获取图像直方图,返回像素计数的列表。
- Image.point(function):使用函数修改图像的每个像素。
- Image.putalpha(alpha):添加或替换图像的alpha层。
- Image.save(fp,format=None,**params):保存图片。
- Image.show(title=None,command=None):显示图片。
- Image.transform(size,method,data=None,resample=0,fill=1):变换图像。
- Image.verify():校验文件是否损坏。
- Image.close():关闭文件。
1.4 ImageFilter模块
内置模块ImageFilter实现了滤镜功能,可以用来创建图像特效,或以此效果作为媒介实现进一步处理。
在模块ImageFilter中,提供了一些预定义的滤镜和自定义滤镜函数。其中最为常用的预定义滤镜如下所示:
BLUE:模糊。
CONTOUR:轮廓。
DETAIL:详情。
EDGE_ENHANCE:边缘增强。
EDGE_ENHANCE_MORE:边缘更多增强。
EMBOSS:浮雕。
FIND_EDGES:寻找边缘。
SHARPEN:锐化。
SMOOTH:平滑。
在模块ImageFilter中,常用的自定义滤镜函数如表1-2所示:
表1-2 ImageFilter模块常用的自定义滤镜函数
|
函数名 |
功能 |
|
ImageFilter.GaussianBlur(radius = 2 ) |
高斯模糊 |
|
ImageFilter.UnsharpMask(radius = 2,percent = 150,threshold = 3 ) |
不清晰的掩模滤镜 |
|
ImageFilter.MinFilter(size = 3 ) |
最小值滤波 |
|
ImageFilter.MedianFilter(size = 3 ) |
中值滤波 |
|
ImageFilter.ModeFilter(size = 3 ) |
模式滤波 |
【示例1-11】使用ImageFilter对指定图片实现滤镜特效
|
from PIL import Image,ImageFilter #打开图片 imga=Image.open('img2.jpg') w,h=imga.size #创建图像区域 img_output=Image.new('RGB',(2*w,h)) #将创建的部分粘贴图片 img_output.paste(imga,(0,0)) #创建列表存储滤镜 fltrs=[] fltrs.append(ImageFilter.EDGE_ENHANCE)#边缘强化滤镜 fltrs.append(ImageFilter.FIND_EDGES) #查找边缘滤镜 fltrs.append(ImageFilter.GaussianBlur)#高斯模糊滤镜 for fltr in fltrs: r=imga.filter(fltr) img_output.paste(r,(w,0)) img_output.show() |
运行结果如图1-12、1-13、1-14所示:

图1-12 示例1-11运行边缘强化滤镜效果图

图1-13 示例1-11运行查找边缘滤镜效果图

图1-14 示例1-11运行高斯模糊滤镜效果图
 1.5 ImageChops模块
1.5 ImageChops模块
在Pillow库的内置模块ImageChops中包含了多个用于实现图片合成的函数。这些合成功能是通过计算通道中像素值的方式来实现的。其主要用于制作特效、合成图片等操作。
常用的内置函数如下所示:
相加函数add(),功能是对两张图片进行算术加法运算。具体语法如下所示:
|
ImageChops.add(image1,image2,scale = 1.0,offset = 0 ) |
在合成后图像中的每个像素值,是两幅图像对应像素值依据下面公式进行计算得到的。
|
out = ((image1 + image2) / scale + offset) |
【示例1-12】使用add()实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #对两张图片进行算术加法运算 ImageChops.add(imga,imgb,1,0).show() |
运行结果如图1-15所示:

图1-15 示例1-12运行效果图
减法函数subtract(),功能是对两张图片进行算术减法运算。具体语法如下所示:
|
ImageChops.subtract(image1,image2,scale = 1.0,offset = 0 ) |
在合成后图像中的每个像素值,是两幅图像对应像素值依据下面的公式进行得到的。
|
out = ((image1 - image2) / scale + offset) |
【示例1-13】使用subtract()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #对两张图片进行减法运算 ImageChops.subtract(imga,imgb,1,0).show() |
运行结果如图1-16所示:

图1-16 示例1-13运行效果图
变暗函数darker(),功能是比较两个图片的像素,取两张图片中对应像素的较小值,所以合成时两幅图像中对应位置的暗部分得到保留,而去除亮部分。具体语法如下所示:
|
ImageChops.darker(image1,image2 ) |
像素的计算公式如下所示:
|
out = min(image1, image2) |
【示例1-14】使用darker()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #使用变暗函数darker() ImageChops.darker(imga,imgb).show() |
运行结果如图1-17所示:

图1-17 示例1-14运行效果图
变亮函数lighter(),与变暗函数darker()相反,功能是比较两个图片(逐像素比较),返回一幅新的图片,这幅新的图片是将两张图片中较亮的部分叠加得到的。也就是说,在某一点上,两张图中哪个的值大(亮)则取之。具体语法如下所示:
|
ImageChops.lighter(image1,image2 ) |
函数lighter()与函数darker()的功能相反,计算后得到的图像是两幅图像对应位置的亮部分。像素的计算公式如下所示:
|
out = max(image1, image2) |
【示例1-15】使用lighter()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #使用变亮函数lighter() ImageChops.lighter(imga,imgb).show() |
运行结果如图1-18所示:

图1-18 示例1-15运行效果图
叠加函数multiply(),功能是将两张图片互相叠加。如果用纯黑色与某图片进行叠加操作,就会得到一幅纯黑色的图片。如果用纯白色与图片作叠加,则图片不受影响。具体语法如下所示:
|
ImageChops.multiply(image1,image2 ) |
合成的图像的效果类似两张图片在透明的描图纸上叠放在一起观看的效果。其对应像素的计算公式如下所示:
|
out = image1 * image2 / MAX |
【示例1-16】使用multiply()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #将两张图片相互叠加 ImageChops.multiply(imga,imgb).show() |
运行结果如图1-19所示:

图1-19 示例1-16运行效果图
屏幕函数screen(),功能是先反色后叠加,实现合成图像的效果,就像将两张幻灯片用两台投影机同时投影到一个屏幕上的效果。具体语法如下所示:
|
ImageChops.screen(image1,image2 ) |
其对应像素的计算公式如下所示:
|
out = MAX - ((MAX - image1) * (MAX - image2) / MAX) |
【示例1-17】使用screen()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #实现反色后叠加 ImageChops.screen(imga,imgb).show() |
运行结果如图1-20所示:

图1-20 示例1-17运行效果图
反色函数invert(),类似于集合操作中的求补集,最大值为Max,每个像素做减法,取出反色。在反色时将用255减去一幅图像的每个像素值,从而得到原来图像的反相。也就是说,其表现为“底片”性质的图像。具体语法如下所示:
|
ImageChops.invert(image) |
其对应像素的计算公式如下所示:
|
out = MAX - image |
【示例1-18】使用invert()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #使用反色函数invert() ImageChops.invert(imga).show() |
运行结果如图1-21所示:

图1-21 示例1-18运行效果图
比较函数difference(),可以逐像素做减法操作,计算出绝对值。函数difference()能够两幅图像的对应像素值相减后的图像,对应像素值相同的,则为黑色。函数difference()通常用来找出图像之间的差异。具体语法如下所示:
|
ImageChops.difference(image1,image2 ) |
其对应像素的计算公式如下所示:
|
out = abs(image1 - image2) |
【示例1-19】使用difference()函数实现图片合成
|
from PIL import Image from PIL import ImageChops #打开图片 imga=Image.open('blend1.jpg') imgb=Image.open('blend2.jpg') #使用比较函数difference() ImageChops.difference(imga,imgb).show() |
运行结果如图1-22所示:

图1-22 示例1-19运行效果图
1.6 ImageEnhance模块
 内置的ImageEnhance模块中包含了多个用于增强图像效果的函数,主要用来调整图像的色彩、对比度、亮度和清晰度等,感觉上和调整电视机的显示参数一样。
内置的ImageEnhance模块中包含了多个用于增强图像效果的函数,主要用来调整图像的色彩、对比度、亮度和清晰度等,感觉上和调整电视机的显示参数一样。
在模块ImageEnhance中,所有的图片增强对象都实现一个通用的接口。这个接口只包含如下一个方法。
方法enhance()会返回一个增强的Image对象,参数factor是一个大于0的浮点数,1表示返回原始图片。
当在Python程序中使用模块ImageEnhance增强图像效果时,需要首先创建对应的增强调整器,然后调用调整器输出函数,根据指定的增强系数(小于1表示减弱,大于1表示增强,等于1表示原图不变)进行调整,最后输出调整后的图像。
在模块ImageEnhance中,常用的内置函数如下所示:
- ImageEnhance.Color(image ):功能是调整图像色彩平衡,相当于彩色电视机的色彩调整,实现了上边提到的接口的enhance方法。
- ImageEnhance.Contrast(image ):功能是调整图像对比度,相当于彩色电视机的对比度调整。
- ImageEnhance.Brightness(image ):功能是调整图像亮度。
- ImageEnhance.Sharpness(image ):功能是调整图像清晰度,用于锐化/钝化图片。
锐化操作的factor是0~2之间的一个浮点数。当factor=0时,返回一个模糊的图片对象;当factor=2时,返回一个锐化的图片对象;当factor=1时,返回原始图片对象。
【示例1-20】使用ImageEnhance实现图像色彩平衡
|
from PIL import Image from PIL import ImageChops,ImageEnhance #打开图片 imga=Image.open('blend1.jpg') w,h=imga.size #创建图像区域 img_output=Image.new('RGB',(2*w,h)) #将创建的部分粘贴图片 img_output.paste(imga,(0,0)) #调整图像色彩平衡 nhc=ImageEnhance.Color(imga) for ratio in [0.6,1.8]:#减弱和增强两个系数 b=nhc.enhance(ratio)#增强处理 img_output.paste(b,(w,0))#粘贴修改后的图像 img_output.show() |
运行结果如图1-23、1-24所示:

图1-23 示例1-20运行减弱色彩效果图

图1-24 示例1-20运行增强色彩效果图
【示例1-21】使用图像点运算实现图像整体变暗、变亮
|
from PIL import Image #打开图片 imga=Image.open('blend1.jpg') w,h=imga.size #创建图像区域 img_output=Image.new('RGB',(3*w,h)) #将创建的部分粘贴图片 img_output.paste(imga,(0,0)) imgb=imga.point(lambda i:i*1.3) img_output.paste(imgb,(w,0)) imgc=imga.point(lambda i:i*0.4) img_output.paste(imgc,(2*w,0)) img_output.show() |
执行结果如图1-25所示:

图1-25 示例1-21运行效果图
 1.7 ImageDraw模块
1.7 ImageDraw模块
ImageDraw模块实现了绘图功能。可以通过创建图片的方式来绘制2D图像;还可以在原有的图片上进行绘图,已达到修饰图片或对图片进行注释的目的。
在ImageDraw模块绘图时需要首先创建一个ImageDraw.Draw对象,并且提供指向文件的参数。然后引用创建的Draw对象方法进行绘图。最后保存或直接输出绘制的图像。
|
drawObject=ImageDraw.Draw(black) |
- 绘制直线
|
drawObject.line([x1,y1,x2,y2],fill = None,width = 0,joint = None ) |
表示以(x1,y1)为起始点,以(x2,y2)为终止点画一条直线。[x1,y1,x2,y2]也可以写为(x1,y1,x2,y2)、[(x1,y1),(x2,y2)]等;fill用于设置指定线条颜色;width设置线条的宽度;joint表示一系列线之间的联合类型。它可以是“曲线”。
- 绘制圆弧
|
drawObject.arc([x1,y1,x2,y2],start,end,fill = None,width = 0 ) |
在左上角坐标为(x1,y1),右下角坐标为(x2,y2)的矩形区域内,满圆O内,以start为起始角度,以end为终止角度,截取圆O的一部分圆弧并画出来。如果[x1,y1,x2,y2]区域不是正方形,则在该区域内的最大椭圆中根据角度截取片段。参数fill和width与line方法相同。
- 绘制椭圆
|
drawObject.ellipse([x1,y1,x2,y2],fill = None,outline = None,width = 0 ) |
用法同arc类似,用于画圆(或者椭圆)。outline表示只规定圆的颜色。
- 绘制弦
|
drawObject.chord([x1,y1,x2,y2],start,end,fill = None,outline = None,width = 0 ) |
用法同arc类似,用于画圆中从start到end的弦。fill表示弦与圆弧之间空间用指定颜色填满,设置为outline表示只规定弦线的颜色。
- 绘制扇形
|
drawObject.pieslice([x1,y1,x2,y2],start,end,fill = None,outline = None,width = 0 ) |
用法同elipse类似,用于画起止角度间的扇形区域。fill表示将扇形区域用指定颜色填满,设置为outline表示只用指定颜色描出区域轮廓。
- 绘制多边形
|
drawObject.polygon([x1,y1,x2,y2,....],fill = None,outline = None ) |
根据坐标画多边形,Python会根据第一个参量中的(x,y)坐标对,连接出整个图形。fill表示将多边形区域用指定颜色填满,outline只用于设置指定颜色描出区域轮廓。
- 绘制矩形
|
drawObject.rectangle([x1,y1,x2,y2],fill = None,outline = None,width = 0 ) |
在指定的区域内画一个矩形,(x1,y1)表示矩形左上角的坐标,(x2,y2)表示矩形右下角的坐标。fill用于将矩形区域颜色填满,outline用于描出区域轮廓。
- 绘制文字
|
drawObject.text(position,text,fill = None,font = None,anchor = None,spacing = 0,align =“left”,direction = None,features = None,language = None ) |
在图像内添加文字。其中参数position是一个二元组,用于指定文字左上角的坐标;text表示要写入的文字内容;fill表示文本的颜色;font必须为ImageFont中指定的font类型;spacing 表示行之间的像素数;align表示位置“left”,“center”或“right”;direction 表示文字的方向。它可以是'rtl'(从右到左),'ltr'(从左到右)或'ttb'(从上到下)。
- 绘制点
|
drawObject.point(xy,fill = None ) |
给定坐标处绘制点(单个像素)。
【示例1-22】ImageDraw模块实现创建图片的方式来绘图
|
from PIL import Image,ImageDraw a=Image.new('RGB',(200,200),'white') #新建一幅白色背景的图像 drw=ImageDraw.Draw(a) drw.rectangle((50,50,150,150),outline='red') drw.text((60,60),'First Draw...',fill='green') a.show() |
执行结果如图1-26所示:

图1-26 示例1-22运行效果图
【示例1-23】ImageDraw模块实现在原图片上绘制
|
from PIL import Image, ImageDraw img = Image.open("lena.jpg") draw = ImageDraw.Draw(img) width, height = img.size draw.arc( (0, 0, width-1, height-1), 0, 360, fill='blue') img.save("circle.jpg") |
执行结果如图1-26所示:

图1-26 示例1-23运行效果图
 1.8 ImageFont模块
1.8 ImageFont模块
ImageFont的功能是实现对字体和字型的处理。比较常用的内置函数如下所示:
- load():从指定的文件中加载一种字体,该函数返回对应的字体对象。如果该函数运行失败,那么将产生IOError异常。语法格式如下:
|
ImageFont.load(文件名) |
- load_path():和函数load()一样,但是如果没有指定当前路径,就会从文件sys.path开始查找指定的字体文件。语法格式如下:
|
ImageFont.load_path(文件名) |
- truetype():有两种定义格式。第1种格式的功能是加载一个TrueType或者OpenType字体文件,并且创建一个字体对象。在Windows系统中,如果指定的文件不存在,加载器就会顺便看看Windows的字体目录下它是否存在。语法格式如下:
|
ImageFont.truetype(file,size) |
第2种格式的功能是,加载一个TrueType或者OpenType字体文件,并且创建一个字体对象。通常的编码方式是“unic”(Unicode)、“symb”(MicrosoftSymbol)、“ADOB”(Adobe Standard)、“ADBE”(Adobe Expert)和“armn”(Apple Roman)。语法格式如下:
|
ImageFont.truetype(file,size,encoding=value) |
- load_default():功能是加载一种默认的字体。
|
ImageFont.load_default() |
- getsize():返回给定文本的宽度和高度,返回值是一个二元组。具体语法格式如下:
|
ImageFont.getsize() |
【示例1-24】ImageFont实现对字体和字型的处理
|
from PIL import Image,ImageDraw,ImageFont im = Image.open("bjsxt.png") draw = ImageDraw.Draw(im) ft=ImageFont.truetype('SIMYOU.TTF',16) draw.text((30,30),u'图像处理库PIL',font=ft,fill='red') ft=ImageFont.truetype('C:\\Windows\\Fonts\\SIMLI.TTF',20) draw.text((30,80),u'图像处理库PIL',font=ft,fill='blue') ft=ImageFont.truetype('C:\\Windows\\Fonts\\STXINGKA.TTF',30) draw.text((30,130),u'图像处理库PIL',font=ft,fill='green') im.show() |
执行结果如图1-27所示:

图1-27 示例1-24运行效果图
1.9操作示例
【示例1-25】绘制十字
|
from PIL import Image, ImageDraw im = Image.open("img1.jpg") draw = ImageDraw.Draw(im) draw.line((0, 0) + im.size, fill=128,width=5) draw.line((0, im.size[1], im.size[0], 0), fill=128,width=5) im.show() |
执行结果如图1-28所示:

图1-28 示例1-25运行效果图
【示例1-26】绘制验证码
|
from PIL import Image, ImageFilter, ImageFont, ImageDraw import random width=100 height=100 #最后一个参数是背景颜色,像素默认值 im = Image.new("RGB",(width,height),(255,255,255)) draw = ImageDraw.Draw(im) #获取颜色 def get_color1(): return (random.randint(200, 255), random.randint(200, 255), random.randint(200, 255)) # 获取一个字母或数字 def get_char(): return chr(random.randint(65,90)) #填充每个像素 for x in range(width): for y in range(height): draw.point((x,y),fill=get_color1()) font = ImageFont.truetype('simsun.ttc', 36) for i in range(4): draw.text((10+i*20,50),get_char(),font=font,fill=(255,0,0)) #干扰线 for i in range(2): draw.line(((10,10),(80,80)),fill=(0,255,0),width=3) im.show() |
执行结果如图1-29所示:

图1-29 示例1-26运行效果图
【示例1-27】控制像素生成九宫格
|
from PIL import Image, ImageFilter, ImageFont, ImageDraw width=300;height=300 x,y=0,0 im = Image.new("RGB",(width,height),(255,255,255)) #最后一个参数是背景颜色,像素默认值 draw = ImageDraw.Draw(im) def get_color1(): a = (x//100)+(y//100) if a == 0: return (255,0,0) elif a == 1: return (0,255,255) elif a ==2: return (0,0,255) elif a==3: return (255,255,0) elif a==4: return (255,0,255) else: return (0,0,0) #填充每个像素 for x in range(width): for y in range(height): draw.point((x,y),fill=get_color1()) im.show() |
执行结果如图1-30所示:

图1-30 示例1-27运行效果图
【示例1-28】将图片中的黄色变换成红色
|
from PIL import Image, ImageFilter, ImageFont, ImageDraw im = Image.open("bjsxt.png") draw = ImageDraw.Draw(im) def get_color(oldColor): ''' 如果是黄色(255,255,0),则换算成红色,把绿色通道置为0 可以点击:windows中的画图软件调色板观察黄色的区间。 :return: ''' print(oldColor) if oldColor[0]>60 and oldColor[1]>60: return (oldColor[0],0,oldColor[2]) else: return oldColor for x in range(im.width): for y in range(im.height): draw.point((x,y),fill=get_color(im.getpixel((x,y)))) im.show() |
执行结果如图1-31所示:

图1-31 示例1-28运行效果图
习题
- 选择题
- RGB色彩模式中,默认情况下,不包含一下哪个通道()
- 红色
- 绿色
- 蓝色
- 黄色
- 下面说法错误的是()
- 获取到Image实例之后,可以用这个类的方法来处理和操作图像
- 用open方法打开指定图形
- 在Pyhton图像库支持大量的图片格式,是图像处理和批处理的最佳选择
- 可以使用import pillow来验证pillow库是否安装成功
- 以下什么为图像高度和宽度的像素数量()
- 像素大小
- 分辨率
- 图像大小
- 色彩模式
- 在对图形进行旋转时,下列说法正确的是()
- 角度为正时,将逆时针旋转
- 角度为正时,将顺时针旋转
- 角度为负时,将逆时针旋转
- 旋转方向不受角度正负影响
- 以下属于Python图像处理第三方库的是:
A. mayavi B. TVTK C. pygame D. PIL
二、解答题
- 图片文件大小有哪些因素有关系?
- RGB色彩模式中,RGB分别代表什么?
- 像素和分辨率的关系是什么?
- 常用的图像操作库Image模块的常用功能。
- Image 和array格式如何转换。
三、编码题
- 编写程序,使用pillow库将图片旋转并保存。
- 编写程序,使用pillow库在指定图片中添加文字及水印并保存。
- 编写程序,使用pillow库实现字母验证码图片。
- 编写程序,使用pillow库实现在图片右上角加上红色的数字。
第二章 语音识别
语音识别技术,也被称为自动语音识别,目标是以电脑自动将人类的语音内容转换为相应的文字和文字转换为语音。在这一章,你将会学习到语音—文本和文本—语音转换的重要性。
通过阅读本章,你可以:
- 了解为什么需要将语音转换成文本
- 掌握如何将文本转换为语音
- 掌握如何将语音转换为文本
2.1语音识别简介
2.1.1语音识别概念
语音识别技术就是让智能设备听懂人类的语音。它是一门涉及数字信号处理、人工智能、语言学、数理统计学、声学、情感学及心理学等多学科交叉的科学。这项技术可以提供比如自动客服、自动语音翻译、命令控制、语音验证码等多项应用。近年来,随着人工智能的兴起,语音识别技术在理论和应用方面都取得大突破,开始从实验室走向市场,已逐渐走进我们的日常生活。现在语音识别己用于许多领域,主要包括语音识别听写器、语音寻呼和答疑平台、自主广告平台,智能客服等。
2.1.2语音识别原理
语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。目前,模式匹配原理已经被应用于大多数语音识别系统中。如图2-1是基于模式匹配原理的语音识别系统框图。
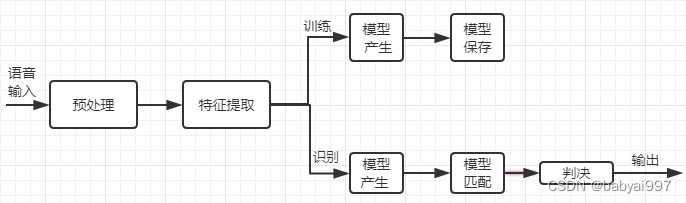
图2-1 语音识别系统框图
一般的模式识别包括预处理,特征提取,模式匹配等基本模块。如图2-1所示首先对输入语音进行预处理,其中预处理包括分帧,加窗,预加重等。其次是特征提取,因此选择合适的特征参数尤为重要。常用的特征参数包括:基音周期,共振峰,短时平均能量或幅度,线性预测系数(LPC),感知加权预测系数(PLP),短时平均过零率,线性预测倒谱系数(LPCC),自相关函数,梅尔倒谱系数(MFCC),小波变换系数,经验模态分解系数(EMD),伽马通滤波器系数(GFCC)等。在进行实际识别时,要对测试语音按训练过程产生模板,最后根据失真判决准则进行识别。常用的失真判决准则有欧式距离,协方差矩阵与贝叶斯距离等。
2.1.3语音识别技术
从语音识别算法的发展来看,语音识别技术主要分为三大类,第一类是模型匹配法,包括矢量量化(VQ) 、动态时间规整(DTW)等;第二类是概率统计方法,包括高斯混合模型(GMM) 、隐马尔科夫模型(HMM)等;第三类是辨别器分类方法,如支持向量机(SVM) 、人工神经网络(ANN)和深度神经网络(DNN)等以及多种组合方法。下面对主流的识别技术做简单介绍:
- 动态时间规整(DTW)
语音识别中,由于语音信号的随机性,即使同一个人发的同一个音,只要说话环境和情绪不同,时间长度也不尽相同,因此时间规整是必不可少的。DTW是一种将时间规整与距离测度有机结合的非线性规整技术,在语音识别时,需要把测试模板与参考模板进行实际比对和非线性伸缩,并依照某种距离测度选取距离最小的模板作为识别结果输出。动态时间规整技术的引入,将测试语音映射到标准语音时间轴上,使长短不等的两个信号最后通过时间轴弯折达到一样的时间长度,进而使得匹配差别最小,结合距离测度,得到测试语音与标准语音之间的距离。
- 支持向量机(SVM)
支持向量机是建立在VC维理论和结构风险最小理论基础上的分类方法,它是根据有限样本信息在模型复杂度与学习能力之间寻求最佳折中。从理论上说,SVM就是一个简单的寻优过程,它解决了神经网络算法中局部极值的问题,得到的是全局最优解。SVM已经成功地应用到语音识别中,并表现出良好的识别性能。
- 矢量量化(VQ)
矢量量化是一种广泛应用于语音和图像压缩编码等领域的重要信号压缩技术,思想来自香农的率-失真理论。其基本原理是把每帧特征矢量参数在多维空间中进行整体量化,在信息量损失较小的情况下对数据进行压缩。因此,它不仅可以减小数据存储,而且还能提高系统运行速度,保证语音编码质量和压缩效率,一般应用于小词汇量的孤立词语音识别系统。
- 隐马尔科夫模型(HMM)
隐马尔科夫模型是一种统计模型,目前多应用于语音信号处理领域。在该模型中,马尔科夫(Markov)链中的一个状态是否转移到另一个状态取决于状态转移概率,而某一状态产生的观察值取决于状态生成概率。在进行语音识别时,HMM首先为每个识别单元建立发声模型,通过长时间训练得到状态转移概率矩阵和输出概率矩阵,在识别时根据状态转移过程中的最大概率进行判决。
- 高斯混合模型(GMM)
高斯混合模型是单一高斯概率密度函数的延伸,GMM能够平滑地近似任意形状的密度分布。高斯混合模型种类有单高斯模型(Single Gaussian Model, SGM)和高斯混合模型(Gaussian Mixture Model, GMM)两类。类似于聚类,根据高斯概率密度函数(Probability Density Function, PDF)参数不同,每一个高斯模型可以看作一种类别,输入一个样本x,即可通过PDF计算其值,然后通过一个阈值来判断该样本是否属于高斯模型。很明显,SGM适合于仅有两类别问题的划分,而GMM由于具有多个模型,划分更为精细,适用于多类别的划分,可以应用于复杂对象建模。目前在语音识别领域,GMM需要和HMM一起构建完整的语音识别系统。
- 人工神经网络(ANN/BP)
人工神经网络由20世纪80年代末提出,其本质是一个基于生物神经系统的自适应非线性动力学系统,它旨在充分模拟神经系统执行任务的方式。如同人的大脑一样,神经网络是由相互联系、相互影响各自行为的神经元构成,这些神经元也称为节点或处理单元。神经网络通过大量节点来模仿人类神经元活动,并将所有节点连接成信息处理系统,以此来反映人脑功能的基本特性。尽管ANN模拟和抽象人脑功能很精准,但它毕竟是人工神经网络,只是一种模拟生物感知特性的分布式并行处理模型。ANN的独特优点及其强大的分类能力和输入输出映射能力促成在许多领域被广泛应用,特别在语音识别、图像处理、指纹识别、计算机智能控制及专家系统等领域。但从当前语音识别系统来看,由于ANN对语音信号的时间动态特性描述不够充分,大部分采用ANN与传统识别算法相结合的系统。
- 深度神经网络/深信度网络-隐马尔科夫(DNN/DBN-HMM)
当前诸如ANN,BP等多数分类的学习方法都是浅层结构算法,与深层算法相比存在局限。尤其当样本数据有限时,它们表征复杂函数的能力明显不足。深度学习可通过学习深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式,并展现从少数样本集中学习本质特征的强大能力。在深度结构非凸目标代价函数中普遍存在的局部最小问题是训练效果不理想的主要根源。为了解决以上问题,提出基于深度神经网络(DNN) 的非监督贪心逐层训练算法,它利用空间相对关系减少参数数目以提高神经网络的训练性能。相比传统的基于GMM-HMM的语音识别系统,其最大的改变是采用深度神经网络替换GMM模型对语音的观察概率进行建模。最初主流的深度神经网络是最简单的前馈型深度神经网络(Feedforward Deep Neural Network,FDNN)。DNN相比GMM的优势在于:1. 使用DNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;2. DNN的输入特征可以是多种特的融合,包括离散或者连续的;3. DNN可以利用相邻的语音帧所包含的结构信息。
- 循环神经网络(RNN)
语音识别需要对波形进行加窗、分帧、提取特征等预处理。训练GMM时候,输入特征一般只能是单帧的信号,而对于DNN可以采用拼接帧作为输入,这些是DNN相比GMM可以获得很大性能提升的关键因素。然而,语音是一种各帧之间具有很强相关性的复杂时变信号,这种相关性主要体现在说话时的协同发音现象上,往往前后好几个字对我们正要说的字都有影响,也就是语音的各帧之间具有长时相关性。采用拼接帧的方式可以学到一定程度的上下文信息。但是由于DNN输入的窗长是固定的,学习到的是固定输入到输入的映射关系,从而导致DNN对于时序信息的长时相关性的建模是较弱的。
- 长短时记忆模块(LSTM)
长短时记忆模块 (Long-Short Term Memory,LSTM) 的引入解决了传统简单RNN梯度消失等问题,使得RNN框架可以在语音识别领域实用化并获得了超越DNN的效果,目前已经使用在业界一些比较先进的语音系统中。除此之外,研究人员还在RNN的基础上做了进一步改进工作,当前语音识别中的主流RNN声学模型框架,主要包含两部分:深层双向RNN和序列短时分类(Connectionist Temporal Classification,CTC)输出层。其中双向RNN对当前语音帧进行判断时,不仅可以利用历史的语音信息,还可以利用未来的语音信息,从而进行更加准确的决策;CTC使得训练过程无需帧级别的标注,实现有效的“端对端”训练。
- 卷积神经网络(CNN)
CNN早在2012年就被用于语音识别系统,并且一直以来都有很多研究人员积极投身于基于CNN的语音识别系统的研究,但始终没有大的突破。最主要的原因是他们没有突破传统前馈神经网络采用固定长度的帧拼接作为输入的思维定式,从而无法看到足够长的语音上下文信息。另外一个缺陷是他们只是将CNN视作一种特征提取器,因此所用的卷积层数很少,一般只有一到二层,这样的卷积网络表达能力十分有限。针对这些问题,提出了一种名为深度全序列卷积神经网络(Deep Fully Convolutional Neural Network,DFCNN)的语音识别框架,使用大量的卷积层直接对整句语音信号进行建模,更好地表达了语音的长时相关性。
2.2文本转换为语音
 2.2.1 pyttsx的使用
2.2.1 pyttsx的使用
使用名为pyttsx的python包,你可以将文本转换为语音。直接使用pip就可以进行安装,命令如下所示:
|
pip install pyttsx3 |
【示例2-1】使用pyttsx实现文本转换语音
|
import pyttsx3 as pyttsx engine=pyttsx.init() engine.say('你好pyttsx') engine.runAndWait() |
2.2.2 SAPI的使用
在python中,你也可以使用SAPI来做文本到语音的转换。
【示例2-2】使用SAPI实现文本转换语音
|
from win32com.client import Dispatch msg="你好 SAPI" speaker = Dispatch('SAPI.SpVoice') speaker.Speak(msg) del speaker |
2.2.3 SpeechLib的使用
 使用SpeechLib,可以从文本文件中获取输入,再将其转换为语音。先使用pip安装,命令如下所示:
使用SpeechLib,可以从文本文件中获取输入,再将其转换为语音。先使用pip安装,命令如下所示:
|
pip install comtypes |
【示例2-3】使用SpeechLib实现文本转换语音
|
from comtypes.client import CreateObject engine=CreateObject("SAPI.SpVoice") stream=CreateObject('SAPI.SpFileStream') from comtypes.gen import SpeechLib infile='demo.txt' outfile='demo_audio.wav' stream.Open(outfile,SpeechLib.SSFMCreateForWrite) engine.AudioOutputStream=stream f=open(infile,'r',encoding='utf-8') theText=f.read() f.close() engine.speak(theText) stream.close() |
2.3语音转换为文本
2.3.1 PocketSphinx的使用
 PocketSphinx是一个用于语音转换文本的开源API。它是一个轻量级的语音识别引擎,尽管在桌面端也能很好地工作,它还专门为手机和移动设备做过调优。首先使用pip命令安装所需模块,命令如下所示:
PocketSphinx是一个用于语音转换文本的开源API。它是一个轻量级的语音识别引擎,尽管在桌面端也能很好地工作,它还专门为手机和移动设备做过调优。首先使用pip命令安装所需模块,命令如下所示:
|
pip install PocketSphinx pip install SpeechRecognition |
【示例2-4】使用PocketSphinx实现语音转换文本
|
import speech_recognition as sr audio_file='demo_audio.wav' r=sr.Recognizer() with sr.AudioFile(audio_file) as source: audio =r.record(source) try: # print('文本内容:',r.recognize_sphinx(audio,language="zh_CN")) print('文本内容:',r.recognize_sphinx(audio)) except Exception as e: print(e) |
|
注意:
|
习题
- 选择题
- 一些智能门能判断识别出主人的声音而决定是否开锁,你认为该门锁可能采用了()的智能技术。
- 智能代理
- 声音编辑
- 语音识别
- 专家系统
- 语音识别技术的英文缩写为()。
- SRT
- CTS
- SPE
- ASR
- 下列选项中是语音要素的有()。(多选)
- 音质
- 音调
- 音强
- 音长
- 语音信号处理也可以简称为语音处理,它是以()为基础而形成的一个综合性的学科。(多选)
- 数字信号处理
- 语音学
- 语音合成
- 语音识别
- 有限词汇的语音合成技术已经比较成熟了,一般我们是采用()作为合成基元。
- 词语
- 句子
- 音节
- 因素
二、解答题
- 语音识别概念
- 语音识别原理
- 语音识别所采用的主要技术及语言识别过程
- 语言识别的目的
三、编码题
- 编写程序,使用PocketSphinx实现语音转换文本。
- 编写程序,使用SpeechLib将文本内容转换为语音文件。
第三章 人脸识别
人脸识别指在图片中检测一张人脸然后使用算法来识别是谁的脸的过程。在现实生活中人脸检测可用于各行各业,而OpenCV提供了人脸检测算法。因此本章首先介绍OpenCV基本使用,接着介绍OpenCV的人脸检测函数,最后介绍Haar级联分类器,通过对比分析相邻图像区域来判断给定图像或子图像与已知对象是否匹配。
通过阅读本章,你可以:
- 了解什么是人脸检测和人脸识别
- 掌握如何使用OpenCV处理图像(灰度图片、修改尺寸、编辑图片)
- 掌握人脸检测和识别
3.1 OpenCV简介
OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。OpenCV是由英特尔公司发起并参与开发,以BSD许可证授权发行,可以在商业和研究领域中免费使用。OpenCV可用于开发实时的图像处理、计算机视觉以及模式识别程序。该程序库也可以使用英特尔公司的IPP进行加速处理。
OpenCV用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C语言接口。该库也有大量的Python、Java and MATLAB/OCTAVE(版本2.5)的接口。这些语言的API接口函数可以通过在线文档获得。如今也提供对于C#、Ch、Ruby、GO的支持。
3.2安装OpenCV模块
OpenCV已经支持python的模块了,直接使用pip就可以进行安装,命令如下:
|
pip install opencv-python |
3.3 OpenCV基本使用
3.3.1 读取图片
 显示图像是OpenCV最基本的操作之一,imshow()函数可以实现该操作。如果使用过其他GUI框架背景,就会很自然第调用imshow()来显示一幅图像。imshow()函数有两个参数:显示图像的帧名称以及要显示的图像本身。直接调用imshow()函数图像确实会显示,但随即会消失。要保证图片一直在窗口上显示,要通过waitKey()函数。waitKey()函数的参数为等待键盘触发的时间,单位为毫秒,其返回值是-1(表示没有键被按下)。
显示图像是OpenCV最基本的操作之一,imshow()函数可以实现该操作。如果使用过其他GUI框架背景,就会很自然第调用imshow()来显示一幅图像。imshow()函数有两个参数:显示图像的帧名称以及要显示的图像本身。直接调用imshow()函数图像确实会显示,但随即会消失。要保证图片一直在窗口上显示,要通过waitKey()函数。waitKey()函数的参数为等待键盘触发的时间,单位为毫秒,其返回值是-1(表示没有键被按下)。
|
image = cv2.imread(imagepath) |
【示例3-1】imread()函数读取图片
|
import cv2 as cv img=cv.imread('lena.jpg') #注意读取图片的路径不能有中文,不然数据读取不出来 cv.imshow('input image',img) cv.waitKey(0) #等待键盘的输入 单位是毫秒 传入0 无限等待 cv.destroyAllWindows() #C++语言 使用完内存必须释放 |
执行结果如图3-1所示:

图3-1 示例3-1运行效果图
 3.3.2图片灰度转换
3.3.2图片灰度转换
OpenCV中有数百种关于在不同色彩空间之间转换的方法。当前,在计算机视觉中有三种常用的色彩空间:灰度、BGR、以及HSV(Hue,Saturation,Value)。
- 灰度色彩空间是通过去除彩色信息来将其转换成灰阶,灰度色彩空间对中间处理特别有效,比如人脸识别。
- BGR及蓝、绿、红色彩空间,每一个像素点都由一个三元数组来表示,分别代表蓝、绿、红三种颜色。网页开发者可能熟悉另一个与之相似的颜色空间:RGB它们只是颜色顺序上不同。
- HSV,H(Hue)是色调,S(Saturation)是饱和度,V(Value)表示黑暗的程度(或光谱另一端的明亮程度)。
灰度转换的作用就是:转换成灰度的图片的计算强度得以降低。
【示例3-2】cvtColor()函数实现图片灰度转换
|
import cv2 as cv src=cv.imread('lena.jpg') cv.imshow('input image',src) #cv2读取图片的通道是BGR(蓝绿红) #PIL读取图片的通道是RGB gray_img=cv.cvtColor(src,code=cv.COLOR_BGR2GRAY) cv.imshow('gray_image',gray_img) cv.waitKey(0) cv.destroyAllWindows() #保存图片 cv.imwrite('gray_lena.jpg',gray_img) |
执行结果如图3-2所示:

图3-2 示例3-2运行效果图
 3.3.3修改图片尺寸
3.3.3修改图片尺寸
【示例3-3】resize()函数修改图片尺寸
|
import cv2 as cv img=cv.imread('lena.jpg') cv.imshow('input image',img) #修改图片的尺寸 # resize_img=cv.resize(img,dsize=(110,160)) resize_img=cv.resize(img,dsize=(400,360)) print(resize_img.shape) cv.imshow('resize_img',resize_img) #如果键盘输入的是q时候 退出 while True: if ord('q') == cv.waitKey(0): break cv.destroyAllWindows() |
执行结果如图3-3所示:
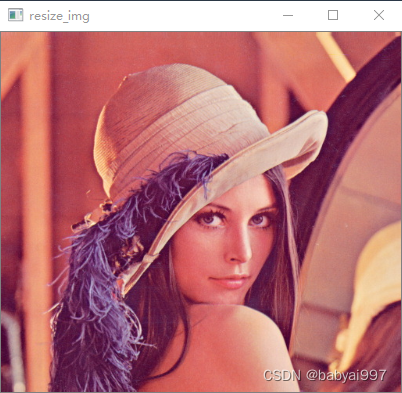
图3-3 示例3-3运行效果图
 3.3.4编辑图片
3.3.4编辑图片
OpenCV的强大之处的一个体现就是其可以对图片进行任意编辑处理。 下面的这个函数最后一个参数指定的就是画笔的大小。
【示例3-4】编辑图片
|
import cv2 as cv img=cv.imread('lena.jpg') #画矩形 x,y,w,h=50,50,80,80 cv.rectangle(img,(x,y,x+w,y+h),color=(0,255,0),thickness=2) #color=BGR cv.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,0,255),thickness=2) cv.imshow('result image',img) cv.waitKey(0) cv.destroyAllWindows() |
执行结果如图3-4所示:
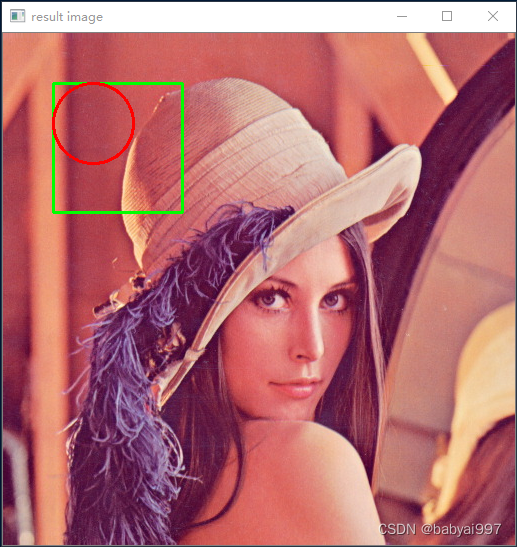
图3-4 示例3-4运行效果图
3.4人脸检测
 3.4.1 Haar级联的概念
3.4.1 Haar级联的概念
摄影作品可能包含很多令人愉悦的细节。但是,由于灯光、视角、视距、摄像头抖动以及数字噪声的变化,图像细节变得不稳定。人们在分类时不会受这些物理细节方面差异的影响。以前学过,在显微镜下没有两片看起来很像的雪花。幸运的是,作者生长在加拿大,已经学会如何不用显微镜来识别雪花。
因此,提取出图像的细节对产生稳定分类结果和跟踪结果很有用。这些提取的结果被称为特征,专业的表述为:从图像数据中提取特征。虽然任意像素都可以能影响多个特征,但特征应该比像素少得多。两个图像的相似程度可以通过它们对应特征的欧氏距离来度量。
Haar特征是一种用于实现实时人脸跟踪的特征。每一个Haar特征都描述了相邻图像区域的对比模式。例如,边、顶点和细线都能生成具有判别性的特征。
3.4.2获取Haar级联数据
首先要进入OpenCV官网:https://opencv.org 下载你需要的版本。点击RELEASES(发布)。如图3-5所示:

图3-5 OpenCV下载
由于OpenCV支持好多平台,比如Windows,Android, Maemo, FreeBSD,OpenBSD, iOS, Linux和Mac OS,一般初学者都是用windows,点击Windows。
图3-6 OpenCV下载
点击Windows 后跳出下面界面,等待5s自动下载。
图3-7 OpenCV下载
然后双击下载的文件,进行安装,实质就是解压一下,解压完出来一个文件夹,其他什么也没发生。安装完后的目录结构如图3-8所示。其中build是OpenCV使用时要用到的一些库文件,而sources中则是OpenCV官方为我们提供的一些demo示例源码。

图3-8 OpenCV目录结构
在sources的一个文件夹data/haarcascades。该文件夹包含了所有OpenCV的人脸检测的XML文件,这些可用于检测静止图像、视频和摄像头所得到图像中的人脸。
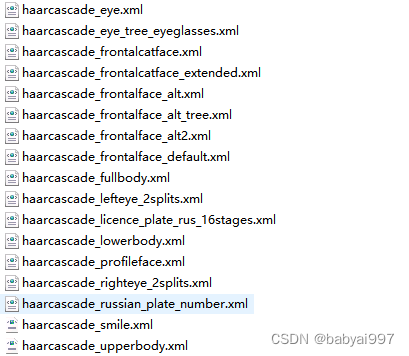
图3-9 OpenCV人脸检测的XML文件
从xml的文件夹名可知这些级联是用于人脸、眼睛、鼻子和嘴的跟踪如表3-1所示。这些文件需要正面、直立的人脸图像。在稍后创建人脸检测器时会使用这些文件。
表3-1 人脸检测的xml文件
|
xml文件名 |
检测器 |
|
haarcascade_frontalface_default.xml |
人脸检测器(默认) |
|
haarcascade_frontalface_alt2.xml |
人脸检测器(快速Harr) |
|
haarcascade_profileface.xml |
人脸检测器(侧视) |
|
haarcascade_lefteye_2splits.xml |
眼部检测器(左眼) |
|
haarcascade_righteye_2splits.xml |
眼部检测器(右眼) |
|
haarcascade_mcs_mouth.xml |
嘴部检测器 |
|
haarcascade_mcs_nose.xml |
鼻子检测器 |
|
haarcascade_fullbody.xml |
身体检测器 |
|
lbpcascade_frontalface.xml |
人脸检测器(快速LBP) |
3.5使用OpenCV进行人脸检测
3.5.1静态图像中人脸检测
人脸检测首先是加载图像并检测人脸,这也是最基本的一步。为了使所得到的结果有意义,可在原始图像的人脸周围绘制矩形框。
【示例3-5】识别图片中的人脸
|
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def face_detect_demo(): gray=cv.cvtColor(src,cv.COLOR_BGR2GRAY) face_detector=cv.CascadeClassifier('E:\\soft\\opencv\\opencv\\sources\\data\\haarcascades\\haarcascade_frontalface_alt_tree.xml') faces=face_detector.detectMultiScale(gray,1.02,5) for x,y,w,h in faces: cv.rectangle(src,(x,y),(x+w,y+h),color=(0,255,0),thickness=2) cv.imshow('result',src) src = cv.imread('lena.jpg') cv.imshow('result',src) face_detect_demo() cv.waitKey(0) cv.destroyAllWindows() |
执行结果如图3-10所示:

图3-10 示例3-5运行效果图
【示例3-6】识别图片中多张人脸
|
import cv2 as cv import numpy as np from matplotlib import pyplot as plt def face_detect_demo(): gray=cv.cvtColor(src,cv.COLOR_BGR2GRAY) face_detector=cv.CascadeClassifier('E:\\soft\\opencv\\opencv\\sources\\data\\haarcascades\\haarcascade_frontalface_alt_tree.xml') faces = face_detector.detectMultiScale(src) #修改检测参数scaleFactor minNeighbors faces=face_detector.detectMultiScale(src,scaleFactor=1.01,minNeighbors=3) for x,y,w,h in faces: cv.rectangle(src,(x,y),(x+w,y+h),color=(0,0,255),thickness=2) cv.circle(src,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=2) cv.imshow('result',src) src = cv.imread('face2.jpg') cv.imshow('result',src) face_detect_demo() cv.waitKey(0) cv.destroyAllWindows() |
执行结果如图3-11所示:

图3-11 示例3-6运行效果图
3.5.2视频中的人脸检测
 视频是一张一张图片组成的,在视频的帧上重复这个过程就能完成视频中的人脸检测。
视频是一张一张图片组成的,在视频的帧上重复这个过程就能完成视频中的人脸检测。
【示例3-7】识别视频中人脸
|
import cv2 as cv def face_detect_demo(img): #将图片灰度 gray=cv.cvtColor(img,cv.COLOR_BGR2GRAY) #加载特征数据 face_detector = cv.CascadeClassifier( 'E:/soft/opencv/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml') faces = face_detector.detectMultiScale(gray) for x,y,w,h in faces: cv.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2) cv.circle(img,center=(x+w//2,y+h//2),radius=(w//2),color=(0,255,0),thickness=2) cv.imshow('result',img) #读取视频 cap=cv.VideoCapture('video.mp4') while True: flag,frame=cap.read() print('flag:',flag,'frame.shape:',frame.shape) if not flag: break face_detect_demo(frame) if ord('q') == cv.waitKey(10): break cv.destroyAllWindows() cap.release() |
3.6人脸识别
人脸检测是OpenCV的一个很不错的功能,它是人脸识别的基础。什么是人脸识别呢?其实就是一个程序能识别给定图像或视频中的人脸。实现这一目标的方法之一是用一系列分好类的图像来“训练”程序,并基于这些图像来进行识别。
这就是OpenCV及其人脸识别模块进行人脸识别的过程。
人脸识别模块的另外一个重要特征是:每个识别都具有转置信(confidence)评分,因此可在实际应用中通过对其设置阈值来进行筛选。
人脸识别所需要的人脸可以通过两种方式来得到:自己获得图像或从人脸数据库免费获得可用的人脸图像。互联网上有许多人脸数据库:
https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html
为了对这些样本进行人脸识别,必须要在包含人脸的样本图像上进行人脸识别。这是一个学习的过程,但并不像自己提供的图像那样令人满意。
3.6.1训练数据
 有了数据,需要将这些样本图像加载到人脸识别算法中。所有的人脸识别算法在它们的train()函数中都有两个参数:图像数组和标签数组。这些标签表示进行识别时候某人人脸的ID,因此根据ID可以知道被识别的人是谁。要做到这一点,将在「trainer/」目录中保存为.yml 文件。
有了数据,需要将这些样本图像加载到人脸识别算法中。所有的人脸识别算法在它们的train()函数中都有两个参数:图像数组和标签数组。这些标签表示进行识别时候某人人脸的ID,因此根据ID可以知道被识别的人是谁。要做到这一点,将在「trainer/」目录中保存为.yml 文件。
在使用Python 3 &OpenCV 3.0.0 进行人脸识别训练时发现异常:
AttributeError: ‘module’ object has no attribute ‘LBPHFaceRecognizer_create’OpenCV需要安装opencv-contrib-python模块,直接使用pip就可以进行安装,命令如下:
|
pip install opencv-contrib-python |
【示例3-8】训练数据
|
import os import cv2 import numpy as np import sys from PIL import Image recognizer = cv2.face.LBPHFaceRecognizer_create() detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml") def getImagesAndLabels(path): imagePaths = [os.path.join(path,f) for f in os.listdir(path)] faceSamples=[] ids = [] for imagePath in imagePaths: PIL_img = Image.open(imagePath).convert('L') # convert it to grayscale img_numpy = np.array(PIL_img,'uint8') id = int(os.path.split(imagePath)[-1].split(".")[0]) faces = detector.detectMultiScale(img_numpy) for (x,y,w,h) in faces: faceSamples.append(img_numpy[y:y+h,x:x+w]) ids.append(id) return faceSamples,ids if __name__ == '__main__': path='./data/jm3/' faces, ids = getImagesAndLabels(path) recognizer.train(faces, np.array(ids)) # Save the model into trainer/trainer.yml recognizer.write('trainer/trainer.yml') |
3.6.2基于LBPH的人脸识别
 LBPH(Local Binary Pattern Histogram)将检测到的人脸分为小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。由于这种方法的灵活性,LBPH是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。
LBPH(Local Binary Pattern Histogram)将检测到的人脸分为小单元,并将其与模型中的对应单元进行比较,对每个区域的匹配值产生一个直方图。由于这种方法的灵活性,LBPH是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。
调整后的区域中调用predict()函数,该函数返回两个元素的数组:第一个元素是所识别个体的标签,第二个是置信度评分。所有的算法都有一个置信度评分阈值,置信度评分用来衡量所识别人脸与原模型的差距,0表示完全匹配。可能有时不想保留所有的识别结果,则需要进一步处理,因此可用自己的算法来估算识别的置信度评分。LBPH 一个好的识别参考值要低于 50 ,任何高于 80 的参考值都会被认为是低的置信度评分。
【示例3-9】基于LBPH的人脸识别
|
import cv2 import numpy as np import os recognizer = cv2.face.LBPHFaceRecognizer_create() recognizer.read('trainer/trainer.yml') faceCascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml") font = cv2.FONT_HERSHEY_SIMPLEX id = 0 img=cv2.imread('9.pgm') #识别的图片 gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale(gray,scaleFactor = 1.2,minNeighbors = 5) for(x,y,w,h) in faces: cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2) id, confidence = recognizer.predict(gray[y:y+h,x:x+w]) print(id,confidence) cv2.imshow('camera',img) cv2.waitKey(0) cv2.destroyAllWindows() |
习题
- 选择题
- 下列不属于眼部可观察特征的是()
- 眼脸
- 眼睛大小
- 眼形
- 眼黑眼白分布
- 衡量人中沟的长度,通常所用的参考系为()
- 鼻宽
- 口宽
- 唇中到眼角的距离
- 眼宽
- 以下说法正确的是()
- 人脸识别只需观察一点就可基本认定为同一人
- 人脸识别中整体观察重点查看的是脸型
- 人脸识别中整体观察的是三庭五眼
- 以上说法都不正确
- 人脸识别中整体观察指的是()
- 脸型和三庭五眼
- 脸型和额部
- 三庭和额部
- 三庭五眼
- 下列关于OpenCV基本使用叙述不正确的是()
- imread()读取图片路径中可以包含中文
- 灰度色彩空间是通过去除彩色信息来将其转换成灰阶,灰度色彩空间对中间处理特别有效。
- BGR及蓝、绿、红色彩空间,每一个像素点都由一个三元数组来表示。
- OpenCV的强大之处的一个体现就是其可以对图片进行任意编辑处理。
- 解答题
- OpenCV人脸识别的原理。
- “人脸识别”大致可分为哪两个阶段。
- 常用的特征提取方法。
- 彩色图像、灰度图像、二值图像和索引图像区别?
- 人脸检测技术有哪些?
三、编码题
- 编写程序,使用OpenCV中的函数,完成显示图像。
- 编写程序,使用OpenCV中的函数对图片进行编辑操作(修改尺寸、图片灰度等)。
- 编写程序,使用OpenCV检测静态图像。
- 编写程序,使用OpenCV检测视频中的图像。
- 编写程序,完成人脸识别。
第四章 基于TensorFlow人工智能实战
自从人类有文明以来,人类探索的脚步就从未停止过。目前,最为成功的深度学习方法与人工神经网络联系紧密,甚至可以毫不夸张地说,传统的人工神经网络就是深度学习框架的基础。因此,可以认为,目前人工智能以及机器学习的觉醒从本质上说,是以人工神经网络为代表的学习算法和框架的盛行以及广泛实践。人工神经网络已经从实验室里走了出来,得到更加广泛的实际商业应用。
通过阅读本章,你可以:
- 了解人工神经元模型与感知机
- 了解框架TensorFlow的基础概念
- 掌握如何使用TensorFlow实现线性回归
- 掌握如何使用TensorFlow实现手写数字识别
4.1神经网络
人工神经网络(Artificial Neural Networks)也简称为神经网络(NN)。是模拟人类大脑神经网络的结构和行为。
20世纪80年代以来,人工神经网络(Artificial Neural Network)研究所取得的突破性进展。神经网络辨识是采用神经网络进行逼近或建模,神经网络辨识为解决复杂的非线性、不确定、未知系统的控制问题开辟了新途径。
神经网络主要应用领域有:模式识别与图象处理(语音、指纹、故障检测和图象压缩等)、控制与优化、系统辨识、预测与管理(市场预测、风险分析)、通信等。
 4.1.1神经网络原理
4.1.1神经网络原理
经典的神经网络有以下三个层次组成:输入层(input layer), 隐藏层 (hidden layers), 输出层 (output layers)。
图4-1 神经网络三个层次
每个圆圈就是一个神经元。每层与每层之间是没有连接的,但是层与层之间都有连接。每个连接都是带有权重值的。隐藏层和输出层的神经元由输入的数据计算输出,但输入层神经元只有输入,一般指一个训练数据样本的数据。
神经系统的基本构造是神经元(神经细胞),它是处理人体内各部分之间相互信息传递的基本单元。每个神经元都由一个细胞体,一个连接其他神经元的轴突和一些向外伸出的其它较短分支—树突组成。轴突功能是将本神经元的输出信号(兴奋)传递给别的神经元,其末端的许多神经末梢使得兴奋可以同时传送给多个神经元。树突的功能是接受来自其它神经元的兴奋。神经元细胞体将接收到的所有信号进行简单地处理后,由轴突输出。神经元的轴突与另外神经元神经末梢相连的部分称为突触。
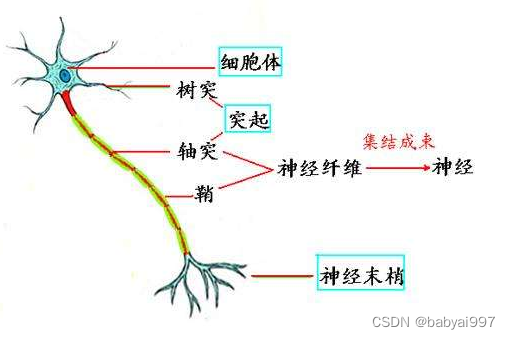
图4-2 神经元的解剖图
4.1.2感知机
感知机是一类人造神经元,模拟这样的大脑神经网络处理数据的过程。感知机模型如图4-3所示:
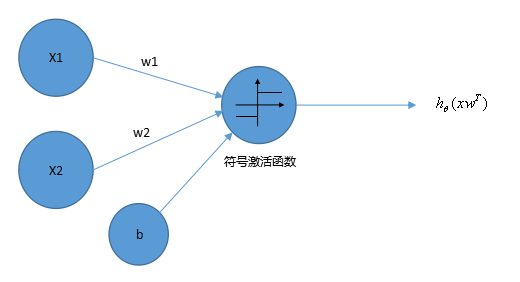
图4-3 感知机模型
其中x1,x2为输入,b为偏置,激活函数被称为符号函数(sign function)。
感知机是一种基本的分类模型,类似于逻辑回归。不同的是感知机的逻辑函数用的是sign,而逻辑回归用的是Sigmoid函数,感知机也具有连接权重和偏置。
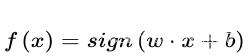
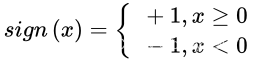
感知机可以用来处理线性可分类问题,线性可不可分简单来说,就是可不可以用一条直线把图上两类点划分开。如图4-5所示,无论怎么画直线都无法将两类点分区开。
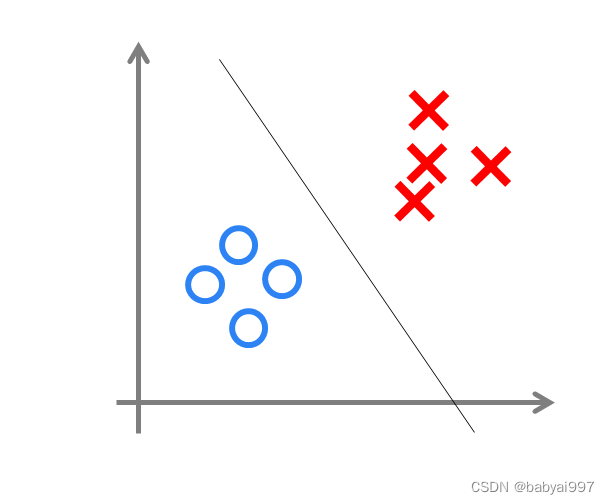
图4-4 线性可分
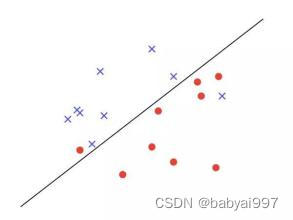
图4-5 线性不可分
对于线性不可分问题一般用多层神经网络,打开http://playground.tensorflow.org/。使用playground体会感知机的分类。
4.2激活函数
 4.2.1 Sigmoid函数
4.2.1 Sigmoid函数
sigmoid函数 由于其单增及反函数单增等性,sigmoid函数常被用做神经网络的激活函数,将变量映射到0,1之间。所以主要用来做二分类神经网络。
由于其平滑、易于求导的特性,处理特征相差不是很大或者复杂的数据效果比较好。
sigmoid函数的公式:
![]()
【示例4-1】使用matplotlib绘制Sigmoid函数
|
import matplotlib.pyplot as plt import numpy as np def sigmoid(x): return 1.0/(1+np.exp(-x)) nums = np.arange(-10, 10, step=1) #生成一个numpy数组 fig, ax = plt.subplots(figsize=(12,4)) #绘制子图 ax.plot(nums, sigmoid(nums), 'r') #绘制sigmoid的函数图像 plt.show() |
执行结果如图4-6所示:
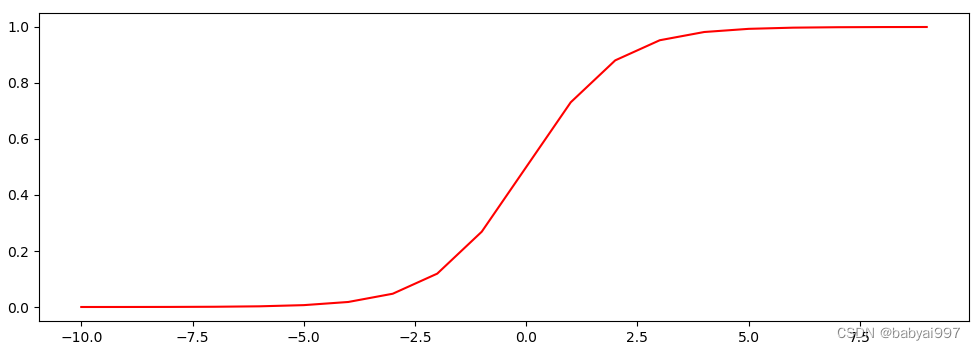
图4-6 示例4-6运行效果图
4.2.2双曲正切函数(tanh)
双曲正切函数(tanh)是双曲正弦函数(sinh)与双曲余弦函数(cosh)的比值,语法格式如下:
![]()
双曲正切函数(tanh)与tf.sigmoid非常接近,且与后者具有类似的优缺点。tf.sigmoid和tf.tanh的主要区别在于后者的值域为[-1.0,1.0]。
【示例4-2】使用matplotlib绘制tanh函数
|
import matplotlib.pyplot as plt import numpy as np #生成x数据 x = np.linspace(-10,10,100) y = np.tanh(x) plt.plot(x,y) plt.show() |
执行结果如图4-7所示:
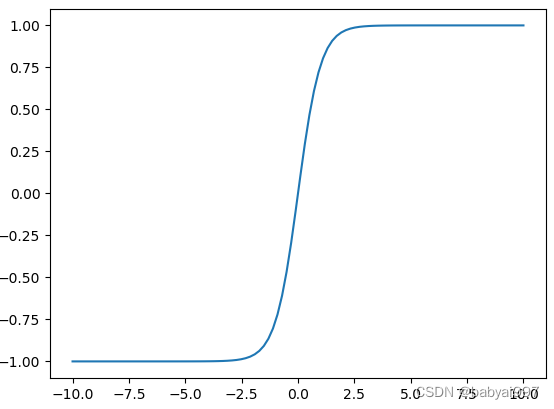
图4-7 示例4-2运行效果图
4.3 TensorFlow框架
 4.3.1 TensorFlow简介
4.3.1 TensorFlow简介
TensorFlow 是一个开源的、基于 Python 的机器学习框架,它由 Google 开发,并在图形分类、音频处理、推荐系统和自然语言处理等场景下有着丰富的应用,是目前最热门的机器学习框架。除了 Python,TensorFlow 也提供了 C/C++、Java、Go、R 等其它编程语言的接口。
- TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统。
- 2015年11月在GitHub上开源。
- 2016年4月分布式版本。
- 2017年发布了1.0版本,趋于稳定。
- Google希望让这个优秀的工具得到更多的应用,从整体上提高深度学习的效率。
TensorFlow相关链接:
- TensorFlow官网:www.tensorflow.org。
- GitHub网址:github.com/tensorflow/tensorflow。
- 模型仓库网址:github.com/tensorflow/models。
TensorFlow的安装:
TensorFlow提供CPU版本和GPU加速的版本。CPU是核芯的数量更少,但是每一个核芯的速度更快,性能更强,更适合于处理连续性任务。GPU是核芯数量更多,但是每一个核芯的处理速度较慢,更适合于并行任务。
|
pip install tensorflow==1.12.0 |
【示例4-3】使用TensorFlow实现加法运算
|
import tensorflow as tf def tensorflowDemo(): #回顾原生的python相加 a=10 b=20 c=a+b print('普通加法运算:',c) print('使用TensorFlow进行加法运算') a_t=tf.constant(10) b_t=tf.constant(20) c_t=a_t+b_t print('TensorFlow加法运算的结果:',c_t) #开启会话 with tf.Session() as sess: c_t_value= sess.run(c_t) print('c_t_value的值:',c_t_value) if __name__ == '__main__': tensorflowDemo() |
执行结果如图4-8所示:
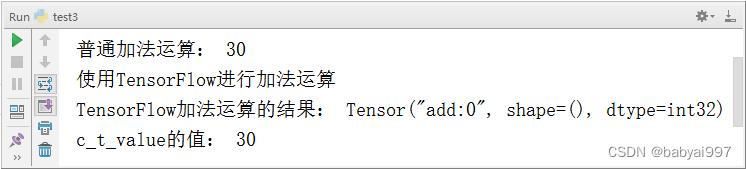
图4-8 示例4-3运行效果图
从上面的示例可以看到使用TensorFlow实现加法运算时候,直接输出c_t的结果,并没有获得加法运算的结果。如果要获取运算的结果要开启会话。TensorFlow程序通常被组织成一个构建图阶段和一个执行图阶段。构建阶段指数据与操作的执行步骤被描述成一个图。在执行阶段,使用会话执行构建好的图中的操作。
TensorFlow的结构有:
- 图:这是TensorFlow将计算表示为指令之间的依赖关系的一种表示法。
- 会话:TensorFlow跨一个或多个本地或远程设备运行数据流图的机制。
- 张量:TensorFlow中的基本数据对象。
- 节点:提供图当中执行的操作。
4.3.2 TensorFlow的数据流图
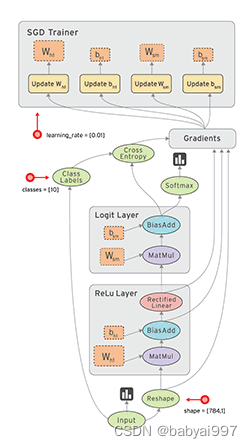
图4-9 数据流图
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源框架。节点(Operation)在图中表示数学操作,线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
4.3.3 图与TensorFlow
 图包含了一组tf.Operation代表的计算单元对象和tf.Tensor代表的计算单元之间流动的数据。
图包含了一组tf.Operation代表的计算单元对象和tf.Tensor代表的计算单元之间流动的数据。
- 默认图
通常TensorFlow会默认创建一张图,通过调用tf.get_default_graph()访问,要将操作添加到默认图中,直接创建OP即可。op、sess都含有graph属性。
【示例4-4】查看默认图的图属性
|
#查看默认图 #1.调用方法查看 default_g=tf.get_default_graph() print('默认图:',default_g) #2.查看属性 print('a_t的图属性:',a_t.graph) print('b_t的图属性:',b_t.graph) print('c_t的图属性:',c_t.graph) |
执行结果如图4-10所示:

图4-10 示例4-4运行效果图
- 自定义图
可以通过tf.Graph()自定义创建图。如果要在这张图中创建OP,使用tf.Graph.as_default()上下文管理器。
【示例4-5】自定义图
|
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' #不想让警告的信息输出可以添加 def graphDemo(): #创建图 new_g = tf.Graph() #在自己的图中定义数据和操作 with new_g.as_default(): a_new = tf.constant(20) b_new = tf.constant(30) c_new = a_new + b_new print('c_new:',c_new) #开启会话 需要传入图参数 with tf.Session(graph=new_g) as sess: c_new_value= sess.run(c_new) print('c_new_value的值:',c_new_value) if __name__ == '__main__': graphDemo() |
执行结果如图4-11所示:

图4-11 示例4-5运行效果图
 4.3.4 TensorBoard可视化
4.3.4 TensorBoard可视化
TensorFlow可用于训练大规模深度神经网络所需的计算,使用该工具涉及的计算往往复杂而深奥。为了更方便TensorFlow程序的理解、调试和优化,TensorFlow提供了TensorBoard可视化工具。
- 数据序列化成events文件
【示例4-6】将数据序列化成events文件
|
import tensorflow as tf def events_demo(): a = tf.constant(20) b = tf.constant(30) c = a+b print('c:',c) #开启会话 with tf.Session() as sess: c_value = sess.run(c) print('c_value:',c_value) #sess的图属性 print('sess的图图属性:',sess.graph) #将图写入本地生成的events文件 writer = tf.summary.FileWriter('e:/events/test',graph=tf.get_default_graph()) writer.close() |
- 启动TensorBoard
首先点开“开始”菜单,在最下边的“搜索程序和文件”搜索框中输入cmd,回车即可进入DOS窗口输入启动TensorBoard,命令如下:
|
tensorboard --logdir=’e:/events/test’ |
在浏览器中打开TensorBoard的图页面,输入http://localhost:6006,会看到如图4-12类似的图。
图4-12 TensorBoard可视化图
 4.3.5会话
4.3.5会话
一个会话里包括了TensorFlow运行时的控制和状态。通过调用tf.Session()就可以生成一个会话(Session)对象。会自动调用Session类的初始化__init__()方法,语法格式如下:
|
def __init__(target=’’,graph=None,config=None) |
其中参数target:如果设置为空(默认设置),会话将仅使用本地计算机中的设备,可以指定grpc://网址,以便指定TensorFlow服务器的地址,这使得会话可以访问该服务器控制的计算机上的所有设备。参数graph:默认情况下,新的tf.Session将绑定到当前的默认图。参数config:此参数允许您指定一个tf.ConfigProto以便控制会话的行为。例如,ConfigProto协议用于打印设备使用信息。
【示例4-7】config参数的使用
|
import tensorflow as tf def sess_demo(): a = tf.constant(10) b = tf.constant(20) c = a+b print('tensorflow的加法运算:',c) #开启会话 with tf.Session(config=tf.ConfigProto( allow_soft_placement=True, log_device_placement=True)) as sess: c_value = sess.run(c) print('c_value:',c_value) if __name__ == '__main__': sess_demo() |
执行结果如图4-13所示:

图4-13 示例4-7运行效果图
会话的run()
|
def run(self, fetches, feed_dict=None, options=None, run_metadata=None): |
其中参数fetches:单一的操作或者列表、元组(其它不属于TensorFlow类型的不行)。
【示例4-8】会话中获取结果
|
import tensorflow as tf def sess_demo(): a = tf.constant(10) b = tf.constant(20) c = a+b print('tensorflow的加法运算:',c) #开启会话 with tf.Session() as sess: value = sess.run([a,b,c]) print('value:',value) value2 = sess.run((a, b, c)) print('value:', value2) c_value = sess.run(c) print('c_value:',c_value) print('eval()方法获取') print('c.eval():',c.eval()) if __name__ == '__main__': sess_demo() |
执行结果如图4-14所示:
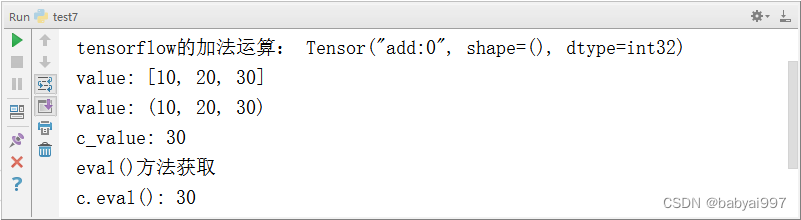
图4-14 示例4-8运行效果图
参数feed_dict:允许调用者覆盖图中张量的值,运行时赋值。使用占位符的方式,占位符是一个可以在之后赋给它数据的变量。它是用来接收外部输入的。占位符可以是一维或者多维,用来存储n维数组。feed_dict必须与tf.placeholder搭配使用,则会检测值的形状是否与占位符兼容。
【示例4-9】feed_dict参数的使用
|
import tensorflow as tf a = tf.placeholder(tf.float32) b = tf.placeholder('float32') c = a+b cc = tf.add(a,b) x = tf.placeholder(tf.float32,None) y = x*20 +100 with tf.Session() as sess: c_value = sess.run(c,feed_dict={a:10,b:20}) cc_value = sess.run(cc,feed_dict={a:10,b:20}) print('c_value:',c_value) print('cc_value:',cc_value) y_value =sess.run(y,feed_dict={x:[10,20,30,40]}) print('y_value:',y_value) |
执行结果如图4-15所示:
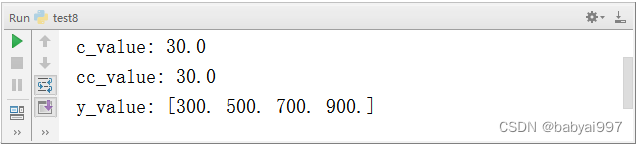
图4-15 示例4-9运行效果图
 4.3.6张量
4.3.6张量
张量是一个数学对象,它是对标量、向量和矩阵的泛化。张量可以表示为一个多维数组。零秩张量就是标量。向量或者数组是秩为1的张量,而矩阵是秩为2的张量。简而言之,张量可以被认为是一个n维数组。
TensorFlow用张量这种数据结构来表示所有的数据。可以把一个张量想象成一个n维的数组或列表。张量可以在图中的节点之间流通。其实张量代表的就是一种多维数组。在TensorFlow系统中,张量的维数来被描述为阶。
表4-1 张量
|
阶 |
数学实例 |
Python |
例子 |
|
0 |
标量 |
(只有大小) |
s = 483 |
|
1 |
向量 |
(大小和方向) |
v = [1.1, 2.2, 3.3] |
|
2 |
矩阵 |
(数据表) |
m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
|
阶 |
数学实例 |
Python |
例子 |
|
3 |
3阶张量 |
(数据立体) |
t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
|
n |
n阶 |
表4-2 张量的类型
|
数据类型 |
Python 类型 |
描述 |
|
DT_FLOAT |
tf.float32 |
32 位浮点数. |
|
DT_DOUBLE |
tf.float64 |
64 位浮点数. |
|
DT_INT64 |
tf.int64 |
64 位有符号整型. |
|
DT_INT32 |
tf.int32 |
32 位有符号整型. |
|
DT_INT16 |
tf.int16 |
16 位有符号整型. |
|
DT_INT8 |
tf.int8 |
8 位有符号整型. |
|
DT_UINT8 |
tf.uint8 |
8 位无符号整型. |
|
DT_STRING |
tf.string |
可变长度的字节数组.每一个张量元素都是一个字节数组. |
|
DT_BOOL |
tf.bool |
布尔型. |
|
DT_COMPLEX64 |
tf.complex64 |
由两个32位浮点数组成的复数:实数和虚数. |
|
DT_QINT32 |
tf.qint32 |
用于量化Ops的32位有符号整型. |
|
DT_QINT8 |
tf.qint8 |
用于量化Ops的8位有符号整型. |
|
DT_QUINT8 |
tf.quint8 |
用于量化Ops的8位无符号整型. |
【示例4-10】固定张量的创建
|
import tensorflow as tf tensor1 = tf.constant(5.0) tensor2 = tf.constant([1,2,3,4,5,6]) tensor3 = tf.constant([[1,2,3],[4,5,6]]) print('tensor1:',tensor1) print('tensor2:',tensor2) print('tensor3:',tensor3) |
执行结果如图4-16所示:

图4-16 示例4-10运行效果图
【示例4-11】随机张量的创建
|
import tensorflow as tf print('随机张量的创建') r = tf.ones(shape=[1,2,3]) print(r) z = tf.zeros(shape=[3,4]) print(z) print('创建均匀分布随机值') r1 = tf.random_uniform([2,3],minval=0,maxval=4) sess = tf.Session() print(sess.run(r1)) print('创建均值和标准差的正太分布随机值') r2 = tf.random_normal([2,3],mean=5,stddev=4) print(sess.run(r2)) sess.close() |
执行结果如图4-17所示:
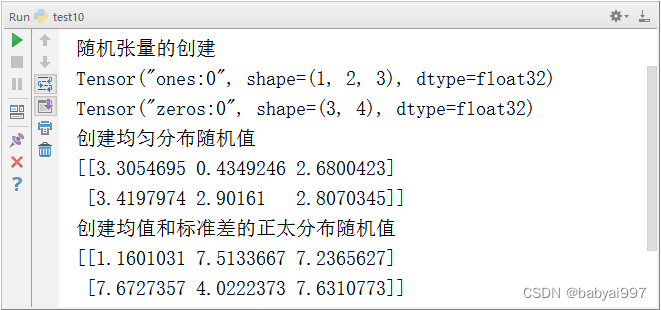
图4-17 示例4-11运行效果图
张量的形状变换
TensorFlow的张量具有两种形状变换,动态形状和静态形状。
静态形状转换调用set_shape(),转换的时候必须和初始创建张量时形状相同,对于已经固定好静态形状的张量,不能再次设置静态形状。
【示例4-12】更改静态形状
|
a_p = tf.placeholder(dtype=tf.float32,shape=[None,None]) b_p = tf.placeholder(dtype=tf.float32,shape=[None,5]) print('静态形状修改') print('修改前形状:') print('a_p:',a_p) print('b_p:',b_p) print('修改后形状') a_p.set_shape([2,5]) print('a_p:',a_p) b_p.set_shape([5,5]) print('b_p:',b_p) |
执行结果如图4-18所示:

图4-18 示例4-12运行效果图
动态形状转换调用tf.reshape(tensor,shape),动态转换形状张量的元素个数必须和修改前要相同。
【示例4-13】更改动态形状
|
c_p = tf.placeholder(dtype=tf.float32,shape=[3,4]) print('动态修改前:') print('c_p:',c_p) print('动态修改后') c_p = tf.reshape(c_p,shape=[2,6]) print('c_p:',c_p) c_p = tf.reshape(c_p,shape=[6,2]) print('c_p:', c_p) c_p = tf.reshape(c_p,shape=[4,3]) print('c_p:', c_p) |
执行结果如图4-19所示:

图4-19 示例4-13运行效果图
【示例4-14】矩阵运算
|
import tensorflow as tf import numpy as np sess = tf.Session() A = tf.random_uniform([3,2]) B = tf.fill([2,4],3.5) C = tf.random_normal([3,4]) print('sess.run(tf.matmul(A,B))\n',sess.run(tf.matmul(A,B))) print('加法运算:') print(sess.run(tf.matmul(A,B)+C)) |
执行结果如图4-20所示:
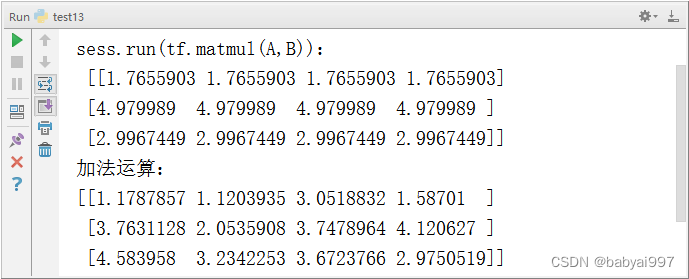
图4-20 示例4-14运行效果图
 4.3.7变量
4.3.7变量
为了训练模型,需要能够修改图以调节一些对象,比如权重值、偏置量。简单来说,变量让你能够给图添加可训练的参数,它们在创建时候就带有类型属性和初始值。
变量的创建语法格式如下:
|
tf.Variable(initial_value=None, trainable=True, collections=None, validate_shape=True, caching_device=None, name=None,) |
其中参数inital_value是初始化的值,trainable是否被训练。
【示例4-15】变量的使用
|
import tensorflow as tf x = tf.constant([10,20,30,40]) y = tf.Variable(x*2+10) #初始化变量 model = tf.global_variables_initializer() with tf.Session() as sess: #运行初始化 sess.run(model) print('y:',sess.run(y)) |
执行结果如图4-21所示:

图4-21 示例4-15运行效果图
4.4实现线性回归
根据数据建立回归模型,y=w1x1+w2x2+....+b,通过真实值与预测值之间建立误差,使用梯度下降优化得到损失最小对应的权重和偏置。最终确定模型的权重和偏置参数,最后可以用这些参数进行预测。
 4.4.1线性回归案例实现
4.4.1线性回归案例实现
假定随机指定100个点,只有一个特征。x和y之间的关系满足y=kx+b。
实现步骤:
- 准备数据
数据分布为y=0.8*x+0.7。这里将数据分布的规律确定,是为了使用我们训练处的参数和真实的参数(即0.8和0.7)比较是否训练准确。
|
X = tf.random_normal(shape=[100,1]) y_true = tf.matmul(X,[[0.8]])+0.7 |
- 构建模型
模型要满足y=weight*x+bias,数据x的形状为(100,1),与权重相乘后的形状为(100,1),即模型参数权重weight的形状为(1,1)。偏置bias的形状可以和权重形状相同也可以是一个标量。
|
weight = tf.Variable(initial_value=tf.random_normal(shape=[1,1])) bias = tf.Variable(initial_value=tf.random_normal(shape=[1,1])) y_predict = tf.matmul(X,weight)+bias |
- 构建损失函数
线性回归损失函数使用均方误差。
|
error = tf.reduce_mean(tf.square(y_predict-y_true)) |
- 优化损失
使用梯度下降优化,语法格式如下:
|
tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) |
其中learning_rate是学习率,一般为0-1之间比较小的值。因为要让损失最小,所以调用梯度下降优化器的minimize()方法。
【示例4-16】线性回归案例实现
|
import tensorflow as tf def linear_regression(): #准备数据 X = tf.random_normal(shape=[100,1]) y_true = tf.matmul(X,[[0.8]])+0.7 #构造模型 #构造模型参数权重weight和偏移bias weight = tf.Variable(initial_value=tf.random_normal(shape=[1,1])) bias = tf.Variable(initial_value=tf.random_normal(shape=[1,1])) y_predict = tf.matmul(X,weight)+bias #构造损失函数 error = tf.reduce_mean(tf.square(y_predict-y_true)) #优化损失 optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) #显示初始化变量 init = tf.global_variables_initializer() #开始会话 with tf.Session() as sess: #运行初始化变量 sess.run(init) print('查看训练前模型参数:权重:%f,偏量:%f,损失:%f'%(weight.eval(),bias.eval(),error.eval())) #开始训练 for i in range(1000): sess.run(optimizer) print('训练第%d次后模型参数:权重:%f,偏量:%f,损失:%f' % ((i+1),weight.eval(), bias.eval(), error.eval())) if __name__ == '__main__': linear_regression() |
4.4.2添加变量显示
 在TensorBoard中观察损失模型的参数,损失值等变量的变化。
在TensorBoard中观察损失模型的参数,损失值等变量的变化。
- 创建事件文件
|
file_writer = tf.summary.FileWriter('e:/events/test',graph=sess.graph) |
- 收集变量
收集对于损失函数和准确率等单值变量使用tf.summary.scalar(name=’’,tensor),收集高维度变量参数使用tf.summary.histogram(name=’’,tensor),收集输入的图片张量能显示图片使用tf.summary.image(name=’’,tensor),其中name为变量的名字,tensor为值。使用示例如下:
|
tf.summary.scalar(‘error’,error) tf.summary.histogram('weights',weight) tf.summary.histogram('bias',bias) |
- 合并变量
|
merged = tf.summary.merge_all() |
- 运行合并变量
|
summary = sess.run(merged) |
- 将summary写入事件文件
|
file_writer.add_summary(summary,i) |
 4.4.3增加命名空间
4.4.3增加命名空间
为了使代码结构更加清晰,TensorBoard图结构清楚,可以增加命名空间。
【示例4-17】增加命名空间
|
import tensorflow as tf def linear_regression(): with tf.variable_scope('prepare_data'): #准备数据 X = tf.random_normal(shape=[100,1],name='feature') y_true = tf.matmul(X,[[0.8]])+0.7 with tf.variable_scope('create_mode'): #构造模型 #构造模型参数权重weight和偏移bias weight = tf.Variable(initial_value=tf.random_normal(shape=[1,1]),name='Weights') bias = tf.Variable(initial_value=tf.random_normal(shape=[1,1]),name='bias') y_predict = tf.matmul(X,weight)+bias with tf.variable_scope('loss_function'): #构造损失函数 error = tf.reduce_mean(tf.square(y_predict-y_true)) with tf.variable_scope('optimizer'): #优化损失 optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) #2.收集变量 tf.summary.scalar('error',error) tf.summary.histogram('weights',weight) tf.summary.histogram('bias',bias) #3.合并变量 merged = tf.summary.merge_all() #显示初始化变量 init = tf.global_variables_initializer() #开始会话 with tf.Session() as sess: #运行初始化变量 sess.run(init) #1.创建事件文件 file_writer = tf.summary.FileWriter('e:/events/test',graph=sess.graph) print('查看训练前模型参数:权重:%f,偏量:%f,损失:%f'%(weight.eval(),bias.eval(),error.eval())) #开始训练 for i in range(1000): sess.run(optimizer) print('训练第%d次后模型参数:权重:%f,偏量:%f,损失:%f' % ((i+1),weight.eval(), bias.eval(), error.eval())) #4.运行合并变量 summary = sess.run(merged) #5.将每次迭代后的变量写入事件文件 file_writer.add_summary(summary,i) if __name__ == '__main__': linear_regression() |
 4.4.4保存读取模型
4.4.4保存读取模型
- 保存模型
|
#创建saver对象 saver = tf.train.Saver() saver.save(sess,'./ckpt/linear_regression.ckpt') |
- 读取模型
|
#判断模型是否存在 ckpt = tf.train.get_checkpoint_state('./ckpt/') if ckpt and ckpt.model_checkpoint_path: saver.restore(sess,'./ckpt/linear_regression.ckpt') print('训练后模型参数:权重:%f,偏量:%f,损失:%f' % (weight.eval(), bias.eval(), error.eval())) |
4.5 MNIST数据集
 4.5.1 MNIST数据集简介
4.5.1 MNIST数据集简介
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片,如图4-22所示:

图4-22 手写数字图片
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:训练集、训练集标签、测试集、测试集标签。
表4-3 MNIST数据集
|
文件名称 |
大小 |
内容 |
|
train-images-idx3-ubyte.gz |
9,681 kb |
55000张训练集,5000张验证集 |
|
train-labels-idx1-ubyte.gz |
29 kb |
训练集图片对应的标签 |
|
t10k-images-idx3-ubyte.gz |
1,611 kb |
10000张测试集 |
|
t10k-labels-idx1-ubyte.gz |
5 kb |
测试集图片对应的标签 |
MNIST中的每个图像都具有相应的标签,0到9之间的数字表示图像中绘制的数字,用的是one-hot编码nn[0,0,0,0,0,0,1,0,0,0],mnist.train.labels[55000,10]。
4.5.2加载MNIST数据集
直接下载下来的数据是无法通过解压或者应用程序打开的,因为这些文件不是任何标准的图像格式而是以字节的形式进行存储的,所以必须编写程序来打开它。
【示例4-18】使用TensorFlow来读取数据及标签
|
from tensorflow.examples.tutorials.mnist import input_data import matplotlib.pyplot as plt mnist = input_data.read_data_sets('E:\\soft\\MNIST_DATA',one_hot=True) # 第一个参数指的是存放数据的文件夹路径,one_hot=True 为采用one_hot的编码方式编码标签 #load data train_X = mnist.train.images #训练集样本 validation_X = mnist.validation.images #验证集样本 test_X = mnist.test.images #测试集样本 #labels train_Y = mnist.train.labels #训练集标签 validation_Y = mnist.validation.labels #验证集标签 test_Y = mnist.test.labels #测试集标签 print(train_X.shape,train_Y.shape) #输出训练集样本和标签的大小 #查看数据,例如训练集中第一个样本的内容和标签 print(train_X[0]) #是一个包含784个元素且值在[0,1]之间的向量 print(train_Y[0]) #获取数据集中100行 image,label = mnist.train.next_batch(100) print('image.shape:',image.shape,'label.shape:',label.shape) #可视化样本,下面是输出了训练集中前20个样本 fig, ax = plt.subplots(nrows=4,ncols=5,sharex='all',sharey='all') ax = ax.flatten() for i in range(20): img = train_X[i].reshape(28, 28) ax[i].imshow(img,cmap='Greys') ax[0].set_xticks([]) ax[0].set_yticks([]) # 自动调整子图参数,使之填充整个图像区域 plt.tight_layout() plt.show() |
训练集中前20个样本如图4-23所示:

图4-23 示例4-18运行效果图
 4.5.3手写数字识别
4.5.3手写数字识别
【示例4-19】手写数字识别
|
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' #不想让警告的信息输出可以添加 from tensorflow.examples.tutorials.mnist import input_data def mnist_demo(): #1.准备数据 mnist = input_data.read_data_sets('E:\\soft\\MNIST_DATA',one_hot=True) x = tf.placeholder(dtype = tf.float32,shape=[None,784]) y_true = tf.placeholder(dtype= tf.float32,shape=[None,10]) #2.构建模型 weight = tf.Variable(initial_value=tf.random_normal(shape=[784,10])) bias = tf.Variable(initial_value=tf.random_normal(shape=[10])) y_predict = tf.matmul(x,weight)+bias #3.构造损失函数 error = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict)) #优化损失 optimizer =tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(error) #初始化变量 init = tf.global_variables_initializer() #开始会话 with tf.Session() as sess: sess.run(init) image,label = mnist.train.next_batch(100) print('训练前损失:%f'%(sess.run(error,feed_dict={x:image,y_true:label}))) #开始训练 for i in range(1000): op,loss=sess.run([optimizer,error],feed_dict={x:image,y_true:label}) print('第%d次训练的损失loss为%f'%((i+1),loss)) if __name__ == '__main__': mnist_demo() |
习题
- 选择题
- 神经元是由()部分构成(多选)
- 细胞体
- 树突
- 轴突
- 突触
- 以下关于TensorFlow库的应用领域的描述,正确的选项是()
- 机器学习
- 数据可视化
- Web开发
- 文本分析
- 以下选项中,用于机器学习方向的第三方库是()
- Jieba
- SnowNLP
- Loso
- TensorFlow
- 有关 TensorFlow API,以下说法中正确的是:()
- tf.Variable和一般编程语言中“变量(Variable)”的含义完全相同。
- tf.placeholder定义的对象,对应于深度神经网络中的“超参数(Hyperparameter)”。
- 通过tf.constant定义的对象,因为是常量,所以,在session.run()运行前就可以用eval()方法获得对象的值。
- session.run()运行一个训练过程时,TensorFlow会使用符号执行(SymbolicExecution)对计算图进行优化。
- 人工智能研究领域不包括()
- 自然语言理解
- 自动程序设计
- 程序设计方法
- 自动定理证明
- 解答题
- 简述神经网络原理。
- 分布式TensorFlow中,变量何时被初始化,又在何时被销毁?
- 可以在同一个会话中运行两个图吗?
- 相比直接执行计算,创建计算图的最大优缺点。
- 逻辑回归的优缺点。
三、编码题
- 编写程序,使用matplotlib绘制Sigmoid函数。
- 编写程序,使用TensorFlow框架,完成线性回归案例实现。
- 编写程序,使用TensorFlow框架,完成手写数字识别。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)