TensorFlow视觉:使用TensorFlow构建卷积神经网络
卷积神经网络 Tensorflow(CNNs) 已成为深度学习领域中处理具有挑战性的图片分类和识别任务的有力工具。CNN已经改变了多个领域,包括计算机视觉模式识别,甚至自然语言处理,它们能够从原始像素数据中自动学习分层特征。CNN已经彻底改变了人类查看视觉数据和与视觉数据交互的方式,无论是用于照片中的物体识别、疾病诊断还是卫星图像分析。无论您是新手还是经验丰富的从业者,本博客都将逐步介绍使用 Te
概述
卷积神经网络 Tensorflow(CNNs) 已成为深度学习领域中处理具有挑战性的图片分类和识别任务的有力工具。CNN已经改变了多个领域,包括计算机视觉、模式识别,甚至自然语言处理,它们能够从原始像素数据中自动学习分层特征。CNN已经彻底改变了人类查看视觉数据和与视觉数据交互的方式,无论是用于照片中的物体识别、疾病诊断还是卫星图像分析。无论您是新手还是经验丰富的从业者,本博客都将逐步介绍使用 TensorFlow 构建 CNN 模型所涉及的关键思想和方法。
卷积神经网络 Tensorflow
创建了一种称为卷积神经网络 Tensorlfow (CNN) 的特殊人工神经网络来分析和处理视觉输入,例如图片和电影。它已经发展成为计算机视觉应用的当代深度学习的基础,允许在图片分类、对象识别和其他视觉识别任务方面取得进步。

有关卷积神经网络 Tensorflow 的简要概述,请参阅深度学习中心中关于卷积神经网络 Tensorflow的文章。
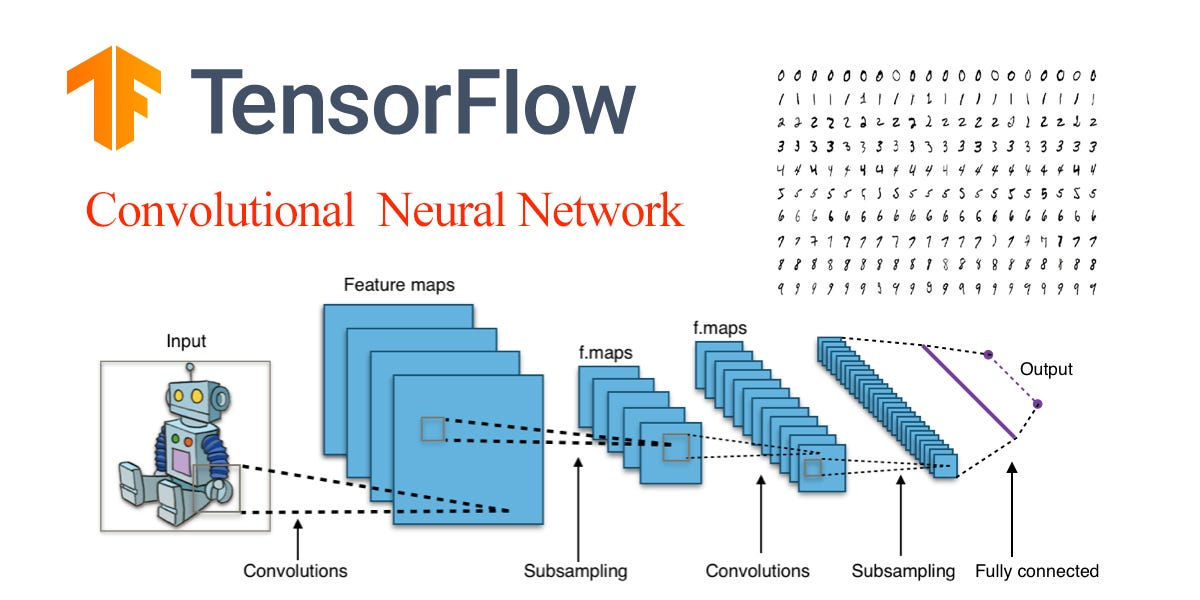
传统的神经网络将输入数据作为平面向量处理,而 CNN 则保持图片中看到的空间连接。他们擅长识别区域趋势,并通过分层学习获得更复杂的视觉信息表示。人类视觉皮层的结构和操作,其中神经元被训练来识别某些视觉刺激,是这方面的灵感来源。
CNN 的基本要素是:
-
卷积层:
这些层使用一组可示教滤波器(有时称为卷积核)转换输入图片。每个过滤器都执行一个卷积数学过程,该过程生成特征图并通过在图片上滑动来提取局部特征。这些特征图将注意力吸引到重要的图案上,如边缘、角落或纹理。
-
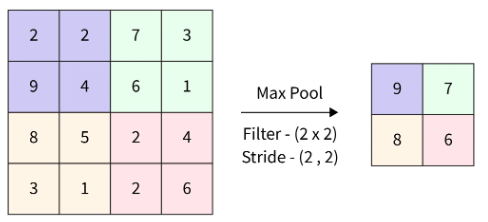
池化层:
这些通常用于对特征图进行下采样,并在卷积层之后降低其空间维数。在提取最重要的信息时,通过池化来改善网络的翻译不变性。最典型的池化过程称为最大池化,在特征图的给定区域内选择可能的最高值。
-
全连接层:
全连接层:全连接层负责在 CNN 架构中进行最终分类或预测。这些层通过将上一层中的每个神经元链接到下一层中的每个神经元来实现高级特征组合和决策。通常,softmax 函数用于从全连接层的输出中生成多个类的概率分布。
卷积神经网络 Tensorflow 在训练过程中使用反向传播技术,根据误差信号修改滤波器和全连接层的权重。
像 TensorFlow 这样的深度学习框架提供了有效构建、训练和部署卷积神经网络 Tensorflow 模型所需的资源,可用于开发 CNN。
使用 TensorFlow 实现 CNN
在进入 TensorFlow 卷积神经网络 Tensorflow (CNN) 的迷人领域之前,创建坚实的基础并掌握驱动这项强大技术的核心思想至关重要。CNN通过允许机器以类似人类的精度识别和解释图片,改变了计算机视觉。
在本文中,我们将介绍在开始使用 TensorFlow 创建 CNN 之前必须了解的核心思想。如果您了解这些想法,您将更好地理解 CNN 的内部工作原理并构建强大的计算机视觉应用程序。
步骤 1。神经网络基础
第2步。计算机视觉基础知识
第 3 步。CNN(卷积神经网络 Tensorflow)
第 4 步。CNN 的架构和变体
第 5 步。TensorFlow 基础知识
第 6 步。创建环境
第 7 步。计算机视觉所需的 Python 库
第 8 步。选择最佳数据集
导入 TensorFlow
使用以下代码导入 TensorFlow
import tensorflow as tf
导入 TensorFlow 后,您可以使用其功能和类来创建和训练神经网络,包括卷积神经网络 Tensorflow (CNN)。请务必记住,在您的环境中安装 TensorFlow 是导入它的先决条件。根据你喜欢的包管理器,你可以使用 pip 或 Conda 安装 TensorFlow。
例如,使用以下命令使用 pip 安装 TensorFlow:
pip install tensorflow
下载并准备CIFAR10数据集
第 1 步:首先导入必要的库。
import tensorflow as tf
from tensorflow.keras import datasets
第 2 步:在第二步中加载 CIFAR-10 数据集。
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
Step 3: Normalise the pixel values in step three.
train_images = train_images / 255.0
test_images = test_images / 255.0
第 4 步:将标签的格式更改为分类
train_labels = tf.keras.utils.to_categorical(train_labels, num_classes=10)
test_labels = tf.keras.utils.to_categorical(test_labels, num_classes=10)
这些操作将加载 CIFAR-10 数据集,对其进行规范化,然后将标签转换为分类格式。
验证数据
下面是如何验证数据的图示:
步骤1:
检查加载数据的表单。
要检查图片和标签数组的尺寸是否与所需形式匹配,将显示此内容。
print("Training images shape:", train_images.shape)
print("Training labels shape:", train_labels.shape)
print("Test images shape:", test_images.shape)
print("Test labels shape:", test_labels.shape)
步骤2:
在步骤 2 中可视化数据。
为了直观地分析数据,此代码段将提供示例照片和随附的标签网格。
import matplotlib.pyplot as plt
# Display a few sample images from the training set
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for i, ax in enumerate(axes.flat):
ax.imshow(train_images[i])
ax.axis('off')
ax.set_title("Label: {}".format(train_labels[i]))
plt.show()
步骤3:
在步骤 3 中验证标签编码。
为了验证它们是否被正确编码,这将打印训练集中包含的唯一标签。
import numpy as np
# Check unique labels in the training set
unique_labels = np.unique(train_labels)
print("Unique labels:", unique_labels)
通过执行这些测试,您可以确认 CIFAR-10 数据集已正确加载和格式化,并了解有关其结构的更多信息。
创建卷积库
您可以使用以下代码使用 TensorFlow 为卷积神经网络 Tensorflow(CNN) 生成卷积基础:
import tensorflow as tf
from tensorflow.Keras import layers
# Create the convolutional base
conv_base = tf.keras.Sequential()
# Add the first convolutional layer
conv_base.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
# Add more convolutional layers
conv_base.add(layers.Conv2D(64, (3, 3), activation='relu'))
conv_base.add(layers.MaxPooling2D((2, 2)))
conv_base.add(layers.Conv2D(128, (3, 3), activation='relu'))
conv_base.add(layers.MaxPooling2D((2, 2)))
conv_base.add(layers.Conv2D(128, (3, 3), activation='relu'))
conv_base.add(layers.MaxPooling2D((2, 2)))
# Flatten the output from convolutional layers
conv_base.add(layers.Flatten())
# Print the summary of the convolutional base
conv_base.summary()

使用 Conv2D 层,我们构建了许多卷积层,同时定义了滤波器的数量、滤波器大小、激活函数和输入形状。RGB 图片尺寸和颜色通道数 (32, 32, 3) 由输入形状表示,输入形状设置为 (32, 32, 3)。
conv_base.summary() 命令输出卷积基本摘要,包括层的类型、输出形状和可训练参数的数量。
TensorFlow 中 CNN 模型的卷积基础可以使用此代码构建。随后,可以将用于分类或回归任务的最终输出层和完全链接层添加到此基础中。
在顶部添加密集图层
您可以按如下方式更改 TensorFlow 中的代码,以在卷积基之上添加密集层:
import tensorflow as tf
from tensorflow.keras import layers
# Create the convolutional base
conv_base = tf.keras.Sequential()
# Add the convolutional layers...
# Flatten the output from convolutional layers
conv_base.add(layers.Flatten())
# Add dense layers
conv_base.add(layers.Dense(64, activation='relu'))
conv_base.add(layers.Dense(10, activation='softmax'))
# Print the summary of the model
conv_base.summary()
您可以在 Flatten 和 Convolutional 层之后使用“Dense”层添加一个或多个密集层。ReLU 激活函数用于第一密集层,该层由 64 个单元组成。

softmax 激活函数用于最后一个致密层,该层由 10 个单元组成。这适用于需要对多个类进行分类的工作,其中每个单元代表一个不同的类,结果是所有类的概率分布。
编译和训练模型
以以下代码为例,在 TensorFlow 中编译和训练基于卷积基础的模型:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# Load and prepare the CIFAR-10 dataset
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
# Create the convolutional base
conv_base = tf.keras.Sequential()
conv_base.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
conv_base.add(layers.MaxPooling2D((2, 2)))
conv_base.add(layers.Conv2D(64, (3, 3), activation='relu'))
conv_base.add(layers.MaxPooling2D((2, 2)))
conv_base.add(layers.Conv2D(64, (3, 3), activation='relu'))
# Add dense layers on top
conv_base.add(layers.Flatten())
conv_base.add(layers.Dense(64, activation='relu'))
conv_base.add(layers.Dense(10, activation='softmax'))
# Compile the model
conv_base.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# Train the model
history = conv_base.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
与之前一样,此代码片段首先加载并准备 CIFAR-10 数据集。然后,使用卷积层、池化层和密集层,通过适当的设计构建卷积基础。
模型架构
- 卷积层用于特征提取,激活函数用于非线性,池化层用于下采样,全连接层用于预测。
- 分类由输出层通过正确激活启用。体系结构的深度和广度对性能有影响,促使在复杂性和可用资源之间进行权衡。
- 迁移学习和预训练模型有助于提高效率。

在模型构建完成后,我们使用 compile 函数来构建模型。在此场景中,我们定义优化器(在本例中为“Adam”)、损失函数(用于多类分类的 SparseCategoricalCrossentropy)以及训练期间要评估的指标(准确性)。
模型训练
- 选择损失函数、优化器、学习率和批量大小,以及使用验证集和数据增强,都是该过程的一部分。
- 监控训练进度有助于识别问题并微调模型以获得最佳性能。
- 通过有效训练CNN,可以开发出具有出色准确性和泛化潜力的强大计算机视觉系统。
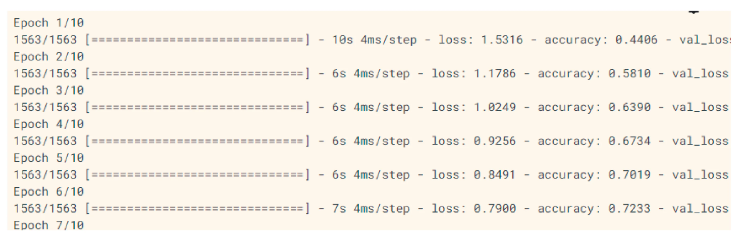
评估模型
您可以使用 TensorFlow 的“evaluate”方法来评估训练模型并衡量它在测试数据集上的表现。下面是如何评估模型的图示:
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# Load and prepare the CIFAR-10 dataset
(test_images, test_labels) = datasets.cifar10.load_data()
test_images = test_images / 255.0
# Create and compile the model
conv_base = tf.keras.Sequential()
# Build the model architecture...
# Compile the model...
# Load the trained weights (optional)
# conv_base.load_weights('path_to_weights.h5')
# Evaluate the model
loss, accuracy = conv_base.evaluate(test_images, test_labels)
print("Test Loss:", loss)
print("Test Accuracy:", accuracy)
我们假设模型已经构建、训练并存储在这一段代码中。我们对测试图片进行归一化并加载 CIFAR-10 测试数据集。
模型评估
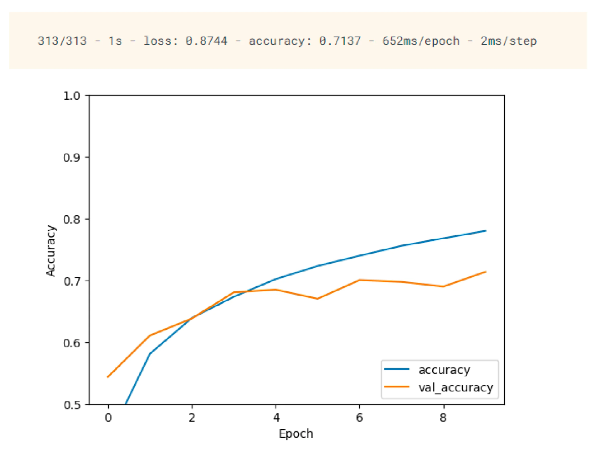
正如我们在训练期间所做的那样,我们现在使用所需的架构和编译参数生成和编译模型。
如果您已经使用 load_weights 方法存储了经过训练的权重,则可以选择加载它们。
使用 TensorFlow 在 CNN 中进行迁移学习和微调
卷积神经网络 Tensorflow (CNN) 采用强大的迁移学习和微调技术来利用先前训练的模型,并将其应用于新的、可比较的工作。这些方法使我们能够使用在大型数据集上训练的模型获得的信息来解决我们独特的问题,即使数据量很少。
-
迁移学习:
迁移学习需要从已经训练过的模型开始,然后对其进行更改或扩展以适应新任务。目标是将预训练模型的学习表示应用于我们的问题领域。通过这样做,我们可以利用预训练模型从一开始就泛化和减少对重要训练的需求的能力。
迁移学习程序:
a.a. 选择预训练模型:
选择一个已经在相当大的数据集(例如 ImageNet)上训练过的 CNN 模型。VGG、ResNet、Inception 或 MobileNet 是常见选项。
b. 冻结卷积碱基:
预训练层的权重应冻结在卷积基中,以防止它们在训练过程中发生变化。在此阶段之后,只有新添加的层才会被训练,以保护学习到的表示。
c. 添加自定义图层:
在已冻结的卷积基之上,添加其他层。这些层可以是脱落层、完全链接层或适合特定用途的任何其他设计。
d. 模型训练:
利用数据集来训练新模型。在冻结预训练层的同时,更新新层的权重。
-
微调:
微调过程更进一步,使一些先前训练的层能够解冻并与新插入的层一起训练。通过使用这种方法,可以根据手头的特定工作定制学习的表示。当新数据集和训练预训练模型的原始数据集具有可比性时,微调非常有帮助。
微调方法:
a.a. 选择预训练模型:
选择一个预先训练的 CNN 模型,该模型与您要执行的任务相似,并且与问题域匹配。
b. 解冻图层:
解冻一些已经过预训练的层,通常是网络开发后期的层。通过在训练期间更新这些层,可以将模型调整为当前作业。
c. 添加自定义图层:
将新图层与已经教授过的图层叠加在一起。与冷冻层一起,这些层将被教授。
d. 训练模型:
使用数据集训练完整的模型,包括先前训练的层和添加的其他层。
您可以利用预先训练的模型获得的信息和表示,并通过使用迁移学习和微调方法将它们应用于您的特定任务。当处理同一域中的相同问题或使用有限的数据时,此方法非常有用。为了使 CNN 中的迁移学习和微调更易于应用,TensorFlow 提供了工具和预训练模型。
使用 TensorFlow Hub 进行迁移学习
使用 TensorFlow Hub(一个可重用的机器学习模型库)中的预训练模型的一种有效方法是使用 TensorFlow Hub 进行迁移学习。为了更轻松地找到适用于特定应用的模型,TensorFlow Hub 提供了各种预训练模型,这些模型已在不同的数据集和不同的架构上进行了训练。
下面概述了如何在 TensorFlow Hub 中使用迁移学习:
-
添加所需的库:
import tensorflow as tf import tensorflow_hub as hub -
应从 TensorFlow Hub 加载预训练模型:
model_url = "https://tfhub.dev/google/imagenet/resnet_v2_50/feature_vector/4" # Example model URL model = tf.keras.Sequential([ hub.KerasLayer(model_url, trainable=False) # Set trainable=False to freeze the pre-trained model ]) -
制作模型并编译它:
model.add(tf.keras.layers.Dense(num_classes, activation='softmax')) # Add a new output layer model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) -
开发模型:
model.fit(train_images, train_labels, epochs=num_epochs, validation_data=(test_images, test_labels))
测试
为了评估经过训练的模型的性能并衡量其在未观察到的数据上的正确性,测试是一个关键步骤。TensorFlow 中的 evaluate() 和 predict() 函数可用于评估模型。下面是如何进行测试的图示:
-
调出测试数据集:
(test_images, test_labels) = datasets.cifar10.load_data() test_images = test_images / 255.0 -
测试应使用 evaluate() 运行:
loss, accuracy = model.evaluate(test_images, test_labels) print("Test Loss:", loss) print("Test Accuracy:", accuracy) -
测试应使用 predict() 运行:
predictions = model.predict(test_images)
结论
- 卷积神经网络 (CNN) 是识别和分类图像的有效工具。
- 创建 CNN 模型所需的工具和功能由 TensorFlow 提供,TensorFlow 是一个广受欢迎的深度学习框架。
- 为了学习高级表示并生成预测,在卷积基之上分层了密集层。
- 借助 TensorFlow Hub,可以使用迁移学习和微调预训练模型来提高性能和有效性。
- 研究人员和从业者可以通过使用 TensorFlow 创建 CNN 模型,自信地应对现实世界的图像分类挑战。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)