人工智能基础部分9-深度学习深入了解
大家好,我是微学AI,今天给大家介绍继续深入了解一下深度学习。
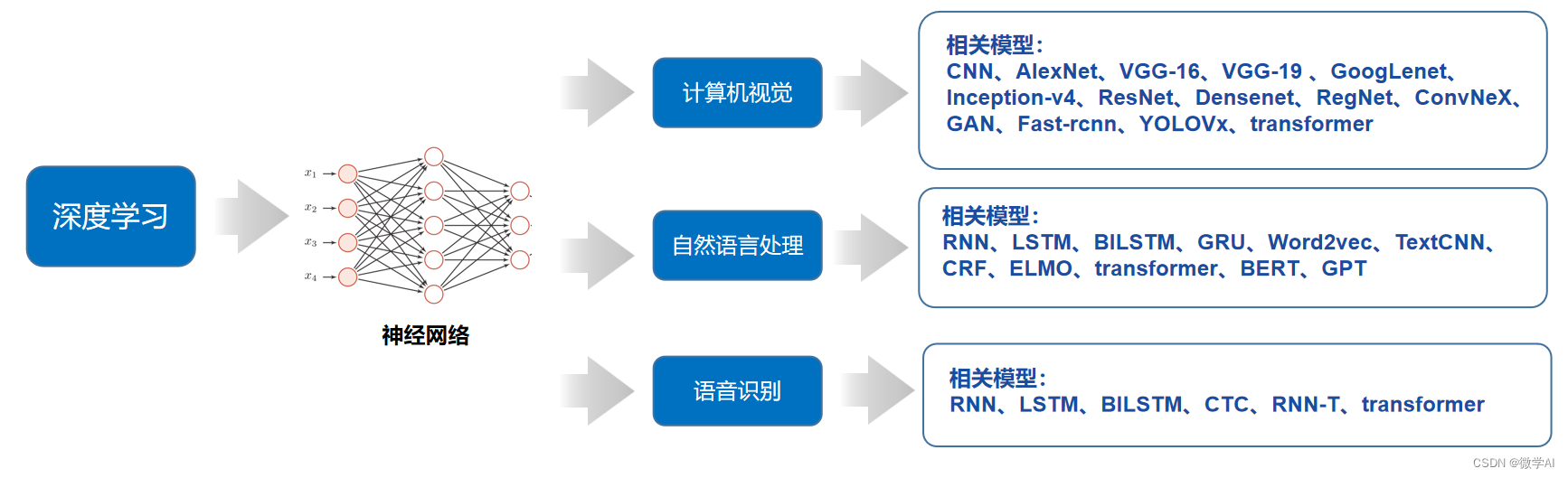
深度学习是一种机器学习技术,由一些多层次的非线性处理单元组成,每一层都可以学习数据中的复杂关系,并且可以组合到一起以构建更复杂的模型。它是由一系列的计算机模型组成的,这些模型是由非线性的多层神经网络构建的,其中每一层都可以学习数据中的复杂关系,并在更高的层次上抽象出更为宏观的模式。它主要应用于计算机视觉、自然语言处理、语音识别和推荐系统等领域。
一、深度学习的数学原理
深度学习的数学原理主要是针对神经网络的,包括线性代数、概率论、微积分、信息论等等。
(1)线性代数:深度学习的基础,学习深度学习之前要掌握矩阵乘法、特征值分解、矩阵求导等知识,这些知识可以帮助我们更好地理解神经网络中的参数、激活函数以及权重的变化。
线性代数是数学中处理向量和矩阵的分支,用于解决多元函数和线性方程组,在深度学习中用于分析神经网络的结构和模型。
(2)概率论:深度学习中的概率论主要涉及概率分布、条件概率等,可以用于训练神经网络,并用于预测模型的性能。
(3)微积分:深度学习的核心是梯度下降,梯度下降是一种基于求导的优化算法,它可以帮助我们找到损失函数的最优值,从而让我们的模型更加准确。
微积分是数学中处理函数的变化率和极限问题的分支,在深度学习中用于处理神经网络中的各种变量,比如梯度、导数和微分。
(4)信息论:信息论主要涉及信息熵、最大似然估计等,可以用于测量神经网络的准确度,从而对模型进行优化。
二、深度学习的应用领域
1. 图像识别:深度学习技术可以用于处理各种图像,从而实现图像分类、检测、识别等功能,如自动驾驶汽车、人脸识别、手写数字识别等。
2. 语音识别:语音识别是深度学习应用最受欢迎的领域之一,深度学习可以用于处理语音信号以及语音识别,从而构建语音对话系统、自动语音翻译系统等。
3. 自然语言处理:深度学习可以用于自然语言处理,如语义分析、机器翻译、命名实体识别、文本分类、关系抽取等,它可以帮助机器理解自然语言,从而实现自然语言交互。
4. 推荐系统:深度学习可以用于构建推荐系统,它可以根据用户的历史行为和兴趣,为用户推荐相关的商品或内容。
5. 智能客服:深度学习可以用于构建智能客服系统,它可以根据客户的输入自动识别意图,从而自动回答客户的问题。
 三、深度学习的框架
三、深度学习的框架
1、Tensorflow:Tensorflow是Google开源的机器学习框架,可以用来构建、训练和部署深度学习模型,也可以用来构建简单的模型来进行语音识别、图像分类等应用。
2、Keras:Keras是一个高级神经网络API,可以用来构建和训练深度学习模型,可以用来解决许多自然语言处理、语音识别、图像分类和计算机视觉等问题。
3、PyTorch:PyTorch是一个开源的深度学习库,可以用来构建和训练神经网络,可以用来解决许多机器学习任务,包括自然语言处理、语音识别、图像分类和计算机视觉等问题。
4、Scikit-Learn:Scikit-Learn是一个开源的Python机器学习库,可以用来构建和训练机器学习模型,可以用来解决许多机器学习任务,包括聚类、回归、分类等等。
5、Theano:Theano是一个开源的Python框架,可以用来构建、训练和部署深度学习模型,可以用来解决许多机器学习任务,包括自然语言处理、语音识别、图像分类和计算机视觉等问题。
6、PaddlePaddle:由百度研发,致力于成为业界最安全、最稳定、最易用的深度学习框架。PaddlePaddle结合了百度的大规模计算资源和深度学习经验,致力于为用户提供高性能、易用的深度学习服务。

三、深度学习的代码案例
1.keras 框架
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation
#创建一个模型
model = Sequential()
#添加一个全连接层
model.add(Dense(units=64, activation='relu', input_dim=100))
#添加一个第二个全连接层
model.add(Dense(units=10, activation='softmax'))
#优化器
opt = keras.optimizers.SGD(lr=0.01)
#编译模型
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# 生成虚拟数据
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
#将标签转换为分类的 one-hot 编码
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
#训练模型
model.fit(data, one_hot_labels, epochs=10, batch_size=32 )2.pytorch框架
import torch
from torch import nn
# 创建一个模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 添加一个全连接层
self.fc1 = nn.Linear(100, 64)
# 添加一个第二个全连接层
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
x = torch.softmax(x, dim=1)
return x
model = Net()
#准备数据
data = torch.rand((1000,100))
labels = torch.randint(10,(1000,1))
#将标签转换为分类的 one-hot 编码
one_hot_labels = torch.zeros(1000, 10).scatter_(1, labels.long(), 1)
# 训练模型
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#训练模型
for epoch in range(10):
#前向传播
y_pred = model(data)
#计算损失
loss = criterion(y_pred, one_hot_labels)
#将梯度归零
optimizer.zero_grad()
#反向传播
loss.backward()
#更新参数
optimizer.step()
print('Epoch: %d Loss: %.5f' % (epoch, loss.item()))有什么问题可以私信咨询,欢迎私信进行交流合作。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)