【语音识别】矢量量化(VQ)说话人识别【含Matlab源码 575期】
矢量量化(VQ)说话人识别完整的代码,方可运行;可提供运行操作视频!适合小白!
⛄一、获取代码方式
获取代码方式1:
完整代码已上传我的资源:【语音识别】基于matlab矢量量化(VQ)说话人识别【含Matlab源码 575期】
点击上面蓝色字体,直接付费下载,即可。
获取代码方式2:
付费专栏Matlab语音处理(初级版)
备注:
点击上面蓝色字体付费专栏Matlab语音处理(初级版),扫描上面二维码,付费29.9元订阅海神之光博客付费专栏Matlab语音处理(初级版),凭支付凭证,私信博主,可免费获得1份本博客上传CSDN资源代码(有效期为订阅日起,三天内有效);
点击CSDN资源下载链接:1份本博客上传CSDN资源代码
⛄二、矢量量化(VQ)说话人识别简介
目前自动说话人识别的方法主要是基于参数模型的HMM的方法和基于非参数模型的VQ的方法。1992年, 日本人Matsui和Fur ui主要从对语声波动的鲁棒性方面对基于VQ的方法和各态历经的离散和连续的HMM方法进行了比较。他们发现连续的各态历经HMM方法比离散的各态历经HMM方法优越, 当可用于训练的数据量较小时, 基于VQ的方法比连续的HMM方法有更大的鲁棒性。同时, 基于VQ的方法比较简单, 实时性也较好。因此,直到目前为止,基于VQ的说话人识别方法,仍然是最常用的识别方法之一。
应用VQ的说话人识别系统如图8-3所示。完成这个系统有两个步骤:一是利用每个说话人的训练语音,建立参考模型码本;二是对待识别话者的语音的每一帧和码本码字之间进行匹配。由于VQ码本保存了说话人个人特性,这样我们就可以利用VQ法来进行说话人识别。在VQ法中模型匹配不依赖于参数的时间顺序, 因而匹配过程中无需采用DTW技术;
而且这种方法比应用DTW方法的参考模型存储量小, 即码本码字小。
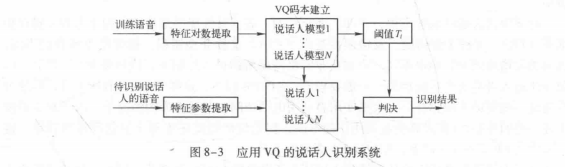
我们可以将每个待识别的说话人看作是一个信源,用一个码本来表征,码本是从该说话
人的训练序列中提取的特征矢量聚类而生成的,只要训练的数据量足够,就可以认为这个码本有效地包含了说话人的个人特征,而与说话的内容无关。识别时,首先对待识别的语音段提取特征矢量序列,然后用系统已有的每个码本依次进行矢量量化,计算各自的平均量化失真。选择平均量化失真最小的那个码本所对应的说话人作为系统识别的结果。
应用VQ的说话人识别过程的步骤如下。
(1)训练过程
1)从训练语音提取特征矢量,得到特征矢量集。
2) 通过LBG算法生成码本。
3)重复训练修正优化码本。
4)存储码本。
(2)识别过程
1)从测试语音提取特征矢量序列X,X,,…,Xu。
2)由每个模板依次对特征矢量序列进行矢量量化,计算各自的平均量化误差

3)选择平均量化误差最小的码本所对应的说话人作为系统的识别结果。
由于人所发的语音是随着生理、心理和健康的状况变化的,不同时间下的语音会有所不
同。因此,如果说话人识别系统的训练时间与使用时间相差过长,会使系统的性能明显下
降。为了维护系统的性能,一种可取的办法是,当某次识别正确时,利用此次测试数据修正原来的模板,让系统自动跟踪说话人语音的变化。
在应用VQ法进行说话人识别时,失真测度的选择将直接影响到聚类结果,进而影响说话人识别系统的性能。失真测度的选择要根据所使用的参数类型来定,在说话人识别采用的矢量量化中,较常用的失真测度是在8.3.2节介绍的欧氏距离测度和加权欧氏距离测度。在基于矢量量化的说话人识别方法中,为了提高识别系统的性能,还必须考虑VQ码本的优化问题和快速搜索算法的应用,以此来提高系统的识别精度和识别速度。
⛄三、部分源代码
function mfc=my_mfcc(x,fs)
%MY_MFCC:获取Speaker recognition的参数
%x:输入语音信号 fs:采样率
%mfc:十二个mfcc系数和一个能量 以及一阶和二阶差分 共36个参数 每一行为一帧数据
%clc,clear
%[x,fs]=audioread(‘wo6.wav’);
N=256;p=24;
bank=mel_banks(p,N,fs,0,fs/2);
% 归一化mel滤波器组系数
bank=full(bank);
bank=bank/max(bank(😃);
% 归一化倒谱提升窗口
w = 1 + 6 * sin(pi * [1:12] ./ 12);
w = w/max(w);
% 预加重滤波器
x=double(x);
x=filter([1 -0.9375],1,x);
% 语音信号分帧
sf=check_ter(x,N,128,10);
x=div_frame(x,N,128);
%sf=sp_ter(x,4,16);
%m=zeros(size(x,1),13);
m=zeros(1,13);
% 计算每帧的MFCC参数
for i=1:size(x,1)
if sf(i)==1
% j=j+1;
y = x(i,:);
y = y’ .* hamming(N);
energy=log(sum(y.^2)+eps);%能量
y = abs(fft(y));
y = y.^2+eps;
c1=dct(log(bank * y));
c2 = c1(2:13).*w’;%取2~13个系数
%m(i,:)=[c2;energy]‘;
m1=[c2;energy]’;
%m1=c2’;
m=[m;m1];
end
end
%差分系数
dm = zeros(size(m));
dmm= zeros(size(m));
for i=2:size(m,1)-1
dm(i,:) = (m(i,:) - m(i-1,:));
end
for i=3:size(m,1)-2
dmm(i,:) = (dm(i,:) - dm(i-1,:));
end
%dm = dm / 3;
function v=lbg(x,k)
%lbg:完成lbg均值聚类算法
% lbg(x,k) 对输入样本x,分成k类。其中,x为row*col矩阵,每一列为一个样本,
% 每个样本有row个元素。
% [v1 v2 v3 …vk]=lbg(…)返回k个分类,其中vi为结构体,vi.num为该类
% 中含有元素个数,vi.ele(i)为第i个元素值,vi.mea为相应类别的均值
[row,col]=size(x);
%u=zeros(row,k);%每一列为一个中心值
epision=0.03;%选择epision参数
delta=0.01;
%u2=zeros(row,k);
%LBG算法产生k个中心
u=mean(x,2);%第一个聚类中心,总体均值
for i3=1:log2(k)
u=[u*(1-epision),u*(1+epision)];%双倍
%time=0;
D=0;
DD=1;
while abs(D-DD)/DD>delta %sum(abs(u2(😃.2-u(😃.2))>0.5&&(time<=80) %u2~=u
DD=D;
for i=1:2^i3 %初始化
v(i).num=0;
v(i).ele=zeros(row,1);
end
for i=1:col %第i个样本
distance=dis(u,x(:,i));%第i个样本到各个中心的距离
[val,pos]=min(distance);
v(pos).num=v(pos).num+1;%元素的数量加1
if v(pos).num==1 %ele为空
v(pos).ele=x(:,i);
else
v(pos).ele=[v(pos).ele,x(:,i)];
end
end
for i=1:2^i3
u(:,i)=mean(v(i).ele,2);%新的均值中心
for m=1:size(v(i).ele,2)
D=D+sum((v(i).ele(m)-u(:,i)).^2);
end
end
end
end
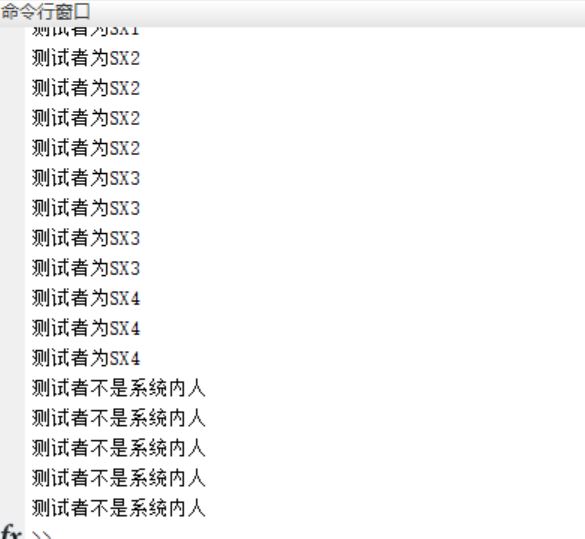
⛄四、运行结果

⛄五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 17
17 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)