1.10.Flink DataStreamAPI(API的抽象级别、Data Sources、connectors、Source容错性保证、Sink容错性保证、自定义sink、partition等)
1.10.Flink DataStreamAPI1.10.1.Flink API的抽象级别1.10.2.DatSource部分详解1.10.2.1.DataStream API之Data Sources1.10.2.2.DataSources API1.10.2.3.DataStream内置connectors1.10.2.4.Source容错性保证1.10.2.5.Sink容错性保证1.10.2
1.10.Flink DataStreamAPI
1.10.1.Flink API的抽象级别
1.10.2.DatSource部分详解
1.10.2.1.DataStream API之Data Sources
1.10.2.2.DataSources API
1.10.2.3.DataStream内置connectors
1.10.2.4.Source容错性保证
1.10.2.5.Sink容错性保证
1.10.2.6.自定义sink
1.10.2.7.Table & SQL Connectors
1.10.2.8.自定义source
1.10.2.9.DataStream API之Transformations部分详解
1.10.2.10.DataStream API之partition
1.10.2.11.DataStream API之Data Sink
1.10.Flink DataStreamAPI
1.10.1.Flink API的抽象级别
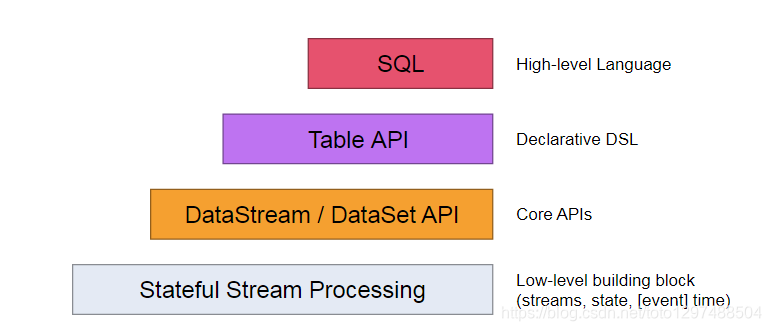
Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态。此外,用户可以在此层抽象中注册事件时间(event time)和处理时间(processing time)回调方法,从而允许程序可以实现复杂计算。
Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)和 DataSet API(应用于有界数据集场景)两部分。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
Process Function 这类底层抽象和 DataStream API 的相互集成使得用户可以选择使用更底层的抽象 API 来实现自己的需求。DataSet API 还额外提供了一些原语,比如循环/迭代(loop/iteration)操作。
Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。Table API 遵循(扩展)关系模型:即表拥有 schema(类似于关系型数据库中的 schema),并且 Table API 也提供了类似于关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以声明的方式定义应执行的逻辑操作,而不是确切地指定程序应该执行的代码。尽管 Table API 使用起来很简洁并且可以由各种类型的用户自定义函数扩展功能,但还是比 Core API 的表达能力差。此外,Table API 程序在执行之前还会使用优化器中的优化规则对用户编写的表达式进行优化。
表和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。
Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。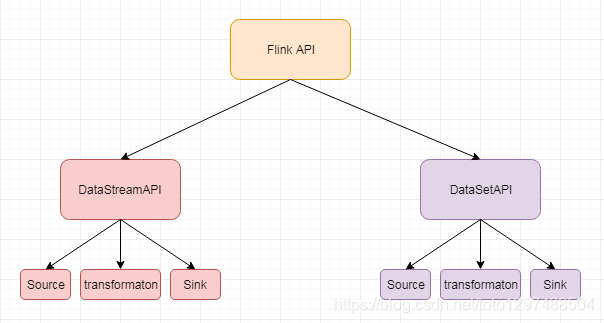
本技术文档上案例所需的pom.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>xxxxx.demo</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--maven properties -->
<maven.test.skip>false</maven.test.skip>
<maven.javadoc.skip>false</maven.javadoc.skip>
<!-- compiler settings properties -->
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<rocketmq.version>4.7.1</rocketmq.version>
<flink.version>1.11.1</flink.version>
<commons-lang.version>2.5</commons-lang.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<distributionManagement>
<repository>
<id>releases</id>
<layout>default</layout>
<url>http://ip/nexus/content/repositories/releases/</url>
</repository>
<snapshotRepository>
<id>snapshots</id>
<name>snapshots</name>
<url>http://ip/nexus/content/repositories/snapshots/</url>
</snapshotRepository>
</distributionManagement>
<repositories>
<repository>
<id>releases</id>
<layout>default</layout>
<url>http://ip/nexus/content/repositories/releases/</url>
</repository>
<repository>
<id>snapshots</id>
<name>snapshots</name>
<url>http://ip/nexus/content/repositories/snapshots/</url>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>warn</checksumPolicy>
</snapshots>
</repository>
<repository>
<id>tianque</id>
<name>tianque</name>
<url>http://ip/nexus/content/repositories/tianque/</url>
</repository>
<repository>
<id>public</id>
<name>public</name>
<url>http://ip/nexus/content/groups/public/</url>
</repository>
<!-- 新加 -->
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!--
1.compile : 默认的scope,运行期有效,需要打入包中。
2.provided : 编译器有效,运行期不需要提供,不会打入包中。
3.runtime : 编译不需要,在运行期有效,需要导入包中。(接口与实现分离)
4.test : 测试需要,不会打入包中
5.system : 非本地仓库引入、存在系统的某个路径下的jar。(一般不使用)
-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.tianque.doraemon</groupId>
<artifactId>issue-business-api</artifactId>
<version>1.0.6.RELEASE</version>
</dependency>
<!-- 使用scala编程的时候使用下面的依赖 start-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 使用scala编程的时候使用下面的依赖 end-->
<!-- kafka connector scala 2.12 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-queryable-state-runtime_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>${rocketmq.version}</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-acl</artifactId>
<version>${rocketmq.version}</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-common</artifactId>
<version>${rocketmq.version}</version>
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-tcnative</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>${commons-lang.version}</version>
</dependency>
<!--test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.powermock</groupId>
<artifactId>powermock-module-junit4</artifactId>
<version>1.5.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.powermock</groupId>
<artifactId>powermock-api-mockito</artifactId>
<version>1.5.5</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-namesrv</artifactId>
<version>${rocketmq.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-broker</artifactId>
<version>${rocketmq.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.tianque</groupId>
<artifactId>caterpillar-sdk</artifactId>
<version>0.1.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<encoding>UTF-8</encoding>
<compilerVersion>${maven.compiler.source}</compilerVersion>
<showDeprecation>true</showDeprecation>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12.4</version>
<configuration>
<skipTests>${maven.test.skip}</skipTests>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.rat</groupId>
<artifactId>apache-rat-plugin</artifactId>
<version>0.12</version>
<configuration>
<excludes>
<exclude>README.md</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>2.17</version>
<executions>
<execution>
<id>verify</id>
<phase>verify</phase>
<configuration>
<configLocation>style/rmq_checkstyle.xml</configLocation>
<encoding>UTF-8</encoding>
<consoleOutput>true</consoleOutput>
<failsOnError>true</failsOnError>
<includeTestSourceDirectory>false</includeTestSourceDirectory>
<includeTestResources>false</includeTestResources>
</configuration>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<version>2.10.4</version>
<configuration>
<aggregate>true</aggregate>
<reportOutputDirectory>javadocs</reportOutputDirectory>
<locale>en</locale>
</configuration>
</plugin>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<configuration>
<scalaCompatVersion>2.11</scalaCompatVersion>
<scalaVersion>2.11.12</scalaVersion>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 可以设置jar包的入口类(可选),此处根据自己项目的情况进行修改 -->
<mainClass>xxxxx.SocketWindowWordCountJava</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
1.10.2.DatSource部分详解
1.10.2.1.DataStream API之Data Sources
source是程序的数据源输入,你可以通过StreamExecutionEnvironment.addSource(sourceFunction)来为你的程序添加一个source。
Flink提供了大量的已经实现好的source方法,你也可以自定义source
- 通过实现sourceFunction接口来自定义无并行度的source
- 或者你也可以通过实现ParallelSourceFunction接口or继承RichParallelSourceFunction来自定义有并行度的source。
以下是自定义Source相关的内容
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* 自定义实现并行度为1的source
*
* 模拟产生从1开始的递增数字
*
*
* 注意:
* SourceFunction 和 SourceContext 都需要指定数据类型,如果不指定,代码运行的时候会报错
* Caused by: org.apache.flink.api.common.functions.InvalidTypesException:
* The types of the interface org.apache.flink.streaming.api.functions.source.SourceFunction could not be inferred.
* Support for synthetic interfaces, lambdas, and generic or raw types is limited at this point
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class MyNoParalleSource implements SourceFunction<Long>{
private long count = 1L;
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个source
* 大部分情况下,都需要在这个run方法中实现一个循环,这样就可以循环产生数据了
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Long> ctx) throws Exception {
while(isRunning){
ctx.collect(count);
count++;
//每秒产生一条数据
Thread.sleep(1000);
}
}
/**
* 取消一个cancel的时候会调用的方法
*
*/
@Override
public void cancel() {
isRunning = false;
}
}
scala代码:
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
* 创建自定义并行度为1的source
*
* 实现从1开始产生递增数字
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
class MyNoParallelSourceScala extends SourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel() = {
isRunning = false
}
}
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
/**
* 自定义实现一个支持并行度的source
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class MyParalleSource implements ParallelSourceFunction<Long> {
private long count = 1L;
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个source
* 大部分情况下,都需要在这个run方法中实现一个循环,这样就可以循环产生数据了
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Long> ctx) throws Exception {
while(isRunning){
ctx.collect(count);
count++;
//每秒产生一条数据
Thread.sleep(1000);
}
}
/**
* 取消一个cancel的时候会调用的方法
*
*/
@Override
public void cancel() {
isRunning = false;
}
}
```java
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
/**
* 自定义实现一个支持并行度的source
*
* RichParallelSourceFunction 会额外提供open和close方法
* 针对source中如果需要获取其他链接资源,那么可以在open方法中获取资源链接,在close中关闭资源链接
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class MyRichParalleSource extends RichParallelSourceFunction<Long> {
private long count = 1L;
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个source
* 大部分情况下,都需要在这个run方法中实现一个循环,这样就可以循环产生数据了
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Long> ctx) throws Exception {
while(isRunning){
ctx.collect(count);
count++;
//每秒产生一条数据
Thread.sleep(1000);
}
}
/**
* 取消一个cancel的时候会调用的方法
*
*/
@Override
public void cancel() {
isRunning = false;
}
/**
* 这个方法只会在最开始的时候被调用一次
* 实现获取链接的代码
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
System.out.println("open.............");
super.open(parameters);
}
/**
* 实现关闭链接的代码
* @throws Exception
*/
@Override
public void close() throws Exception {
super.close();
}
}
使用自己定义的source
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* 使用并行度为1的source
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoWithMyNoPralalleSource {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource<Long> text = env.addSource(new MyNoParalleSource()).setParallelism(1);//注意:针对此source,并行度只能设置为1
DataStream<Long> num = text.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("接收到数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream<Long> sum = num.timeWindowAll(Time.seconds(2)).sum(0);
//打印结果
sum.print().setParallelism(1);
String jobName = StreamingDemoWithMyNoPralalleSource.class.getSimpleName();
env.execute(jobName);
}
}
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* 使用多并行度的source
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoWithMyPralalleSource {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource<Long> text = env.addSource(new MyParalleSource()).setParallelism(2);
DataStream<Long> num = text.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("接收到数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream<Long> sum = num.timeWindowAll(Time.seconds(2)).sum(0);
//打印结果
sum.print().setParallelism(1);
String jobName = StreamingDemoWithMyPralalleSource.class.getSimpleName();
env.execute(jobName);
}
}
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
/**
* 使用多并行度的source
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoWithMyRichPralalleSource {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataStreamSource<Long> text = env.addSource(new MyRichParalleSource()).setParallelism(2);
DataStream<Long> num = text.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("接收到数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream<Long> sum = num.timeWindowAll(Time.seconds(2)).sum(0);
//打印结果
sum.print().setParallelism(1);
String jobName = StreamingDemoWithMyRichPralalleSource.class.getSimpleName();
env.execute(jobName);
}
}
以下是scala的实现
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
* 创建自定义并行度为1的source
*
* 实现从1开始产生递增数字
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
class MyNoParallelSourceScala extends SourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel() = {
isRunning = false
}
}
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
* 创建自定义并行度为1的source
*
* 实现从1开始产生递增数字
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
class MyParallelSourceScala extends ParallelSourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel() = {
isRunning = false
}
}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
/**
* 创建自定义并行度为1的source
*
* 实现从1开始产生递增数字
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
class MyRichParallelSourceScala extends RichParallelSourceFunction[Long]{
var count = 1L
var isRunning = true
override def run(ctx: SourceContext[Long]) = {
while(isRunning){
ctx.collect(count)
count+=1
Thread.sleep(1000)
}
}
override def cancel() = {
isRunning = false
}
override def open(parameters: Configuration): Unit = super.open(parameters)
override def close(): Unit = super.close()
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoWithMyNoParallelSourceScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyNoParallelSourceScala)
val mapData = text.map(line=>{
println("接收到的数据:"+line)
line
})
val sum = mapData.timeWindowAll(Time.seconds(2)).sum(0)
sum.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoWithMyParallelSourceScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyParallelSourceScala).setParallelism(2)
val mapData = text.map(line=>{
println("接收到的数据:"+line)
line
})
val sum = mapData.timeWindowAll(Time.seconds(2)).sum(0)
sum.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoWithMyRichParallelSourceScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyRichParallelSourceScala).setParallelism(2)
val mapData = text.map(line=>{
println("接收到的数据:"+line)
line
})
val sum = mapData.timeWindowAll(Time.seconds(2)).sum(0)
sum.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
1.10.2.2.DataSources API
基于文件
- readTextFile(path)
- 读取文本文件,文件遵循TextInputFormat读取规则,逐行读取并返回。
基于socket - 从socket中读取数据,元素可以通过一个分隔符切开。
基于集合 - fromCollection(Collection)
- 通过java 的collection集合创建一个数据流,集合中的所有元素必须是相同类型的。
自定义输入 - addSource 可以实现读取第三方数据源的数据
- 系统内置提供了一批connectors,连接器会提供对应的source支持【kafka】
基于集合的案例fromCollection(Collection):
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
/**
* @author tuzuoquan
* @version 1.0
* @ClassName StreamingFromCollection
* @description TODO
* @date 2020/9/16 13:49
**/
public class StreamingFromCollection {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ArrayList<Integer> data = new ArrayList<>();
data.add(10);
data.add(15);
data.add(20);
//指定数据源
DataStreamSource<Integer> collectionData = env.fromCollection(data);
//通map对数据进行处理
// DataStream<Integer> num = collectionData.map(new MapFunction<Integer, Integer>() {
// @Override
// public Integer map(Integer value) throws Exception {
// return value + 1;
// }
// });
//通map对数据进行处理
//DataStream<String>中的String为最终的系统中返回值
//new MapFunction<Integer, String>中的String和返回值的类型保值一致
//public String map(Integer value)中的String就是返回值中的类型
DataStream<String> num = collectionData.map(new MapFunction<Integer, String>() {
@Override
public String map(Integer value) throws Exception {
return value + 1 + "_suffix";
}
});
//直接打印
num.print().setParallelism(1);
env.execute("StreamingFromCollection");
}
}
1.10.2.3.DataStream内置connectors
一些比较基本的 Source 和 Sink 已经内置在 Flink 里。 预定义 data sources 支持从文件、目录、socket,以及 collections 和 iterators 中读取数据。 预定义 data sinks 支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和socket。
Apache Kafka (source/sink)
Apache Cassandra (sink)
Amazon Kinesis Streams (source/sink)
Elasticsearch (sink)
Hadoop FileSystem (sink)
RabbitMQ (source/sink)
Apache NiFi (source/sink)
Twitter Streaming API (source)
Google PubSub (source/sink)
JDBC (sink)
在使用一种连接器时,通常需要额外的第三方组件,比如:数据存储服务器或者消费队列。要注意这些列举的连接器是Flink工程的一部分,包含在发布的源码中,但是不包含在二进制发行版本中。
1.10.2.4.Source容错性保证
| Source | Guarantees | Notes |
|---|---|---|
| Apache Kafka | 精确一次 | 根据你的版本恰当的Kafka连接器 |
| AWS Kinesis Streams | 精确一次 | |
| RabbitMQ | 至多一次 (v 0.10) / 精确一次 (v 1.0) | |
| Twitter Streaming API | 至多一次 | |
| Google PubSub | 至少一次 | |
| Collections | 精确一次 | |
| Files | 精确一次 | |
| Sockets | 至多一次 |
为了保证端到端精确一次的数据交付(在精确一次的状态语义上更进一步),sink需要参与checkpointing。下表列举了Flink与其自带Sink的交付保证(假设精确一次状态更新)
1.10.2.5.Sink容错性保证
| Sink | Guarantees | Notes |
|---|---|---|
| HDFS BucketingSink | 精确一次 | 实现方法取决于 Hadoop 的版本 |
| Elasticsearch | 至少一次 | |
| Kafka producer | 至少一次/精确一次 | 当使用事务生产者时,保证精确一次 (v 0.11+) |
| Cassandra sink | 至少一次 / 精确一次 | |
| AWS Kinesis Streams | 至少一次 | |
| File sinks | 精确一次 | |
| Socket sinks | 至少一次 | |
| Standard output | 至少一次 | |
| Redis sink | 至少一次 |
1.10.2.6.自定义sink
实现自定义的sink
- 实现SinkFunction接口
- 或者继承RichSinkFunction
1.10.2.7.Table & SQL Connectors
- Formats
- Kafka
- JDBC
- Elasticsearch
- FileSystem
- HBASE
- DataGen
- BlackHole
1.10.2.8.自定义source
实现并行度为1的自定义source
- 实现SourceFunction
- 一般不需要实现容错性保证
- 处理好cancel方法(cancel应用的时候,这个方法会被调用)
实现并行化的自定义source - 实现ParallelSourceFunction
- 或者继承RichParallelSourceFunction
继承RichParallelSourceFunction的那些SourceFunction意味着它们都是并行执行的并且可能有一些资源需要open/close
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import xxx.xxx.streaming.custormSource.MyNoParalleSource;
/**
* broadcast分区规则
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoWithMyNoPralalleSourceBroadcast {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
//获取数据源
//注意:针对此source,并行度只能设置为1
DataStreamSource<Long> text = env.addSource(new MyNoParalleSource()).setParallelism(1);
DataStream<Long> num = text.broadcast().map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
long id = Thread.currentThread().getId();
System.out.println("线程id:"+id+",接收到数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream<Long> sum = num.timeWindowAll(Time.seconds(2)).sum(0);
//打印结果
sum.print().setParallelism(1);
String jobName = StreamingDemoWithMyNoPralalleSourceBroadcast.class.getSimpleName();
env.execute(jobName);
}
}
1.10.2.9.DataStream API之Transformations部分详解
- map:输入一个元素,然后返回一个元素,中间可以做一些清洗转换等操作
- flatmap:输入一个元素,可以返回零个,一个或者多个元素
- filter:过滤函数,对传入的数据进行判断,符合条件的数据会被留下
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import xxx.xxx.streaming.custormSource.MyNoParalleSource;
/**
* Filter演示
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoFilter {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
//注意:针对此source,并行度只能设置为1
DataStreamSource<Long> text = env.addSource(new MyNoParalleSource()).setParallelism(1);
DataStream<Long> num = text.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("原始接收到数据:" + value);
return value;
}
});
//执行filter过滤,满足条件的数据会被留下
DataStream<Long> filterData = num.filter(new FilterFunction<Long>() {
//把所有的奇数过滤掉
@Override
public boolean filter(Long value) throws Exception {
return value % 2 == 0;
}
});
DataStream<Long> resultData = filterData.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("过滤之后的数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream<Long> sum = resultData.timeWindowAll(Time.seconds(2)).sum(0);
//打印结果
sum.print().setParallelism(1);
String jobName = StreamingDemoFilter.class.getSimpleName();
env.execute(jobName);
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import xxx.xxx.streaming.custormSource.MyNoParallelSourceScala
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoFilterScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyNoParallelSourceScala)
val mapData = text.map(line=>{
println("原始接收到的数据:"+line)
line
}).filter(_ % 2 == 0)
val sum = mapData.map(line=>{
println("过滤之后的数据:"+line)
line
}).timeWindowAll(Time.seconds(2)).sum(0)
sum.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
- keyBy:根据指定的key进行分组,相同key的数据会进入同一个分区【典型用法见备注】
- reduce:对数据进行聚合操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值
- aggregations:sum(),min(),max()等
- window:在后面单独详解
- Union:合并多个流,新的流会包含所有流中的数据,但是union是一个限制,就是所有合并的流类型必须是一致的。
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import xxx.xxx.streaming.custormSource.MyNoParalleSource;
/**
* union
* 合并多个流,新的流会包含所有流中的数据,但是union是一个限制,就是所有合并的流类型必须是一致的
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoUnion {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
//注意:针对此source,并行度只能设置为1
DataStreamSource<Long> text1 = env.addSource(new MyNoParalleSource()).setParallelism(1);
DataStreamSource<Long> text2 = env.addSource(new MyNoParalleSource()).setParallelism(1);
//把text1和text2组装到一起
DataStream<Long> text = text1.union(text2);
DataStream<Long> num = text.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
System.out.println("原始接收到数据:" + value);
return value;
}
});
//每2秒钟处理一次数据
DataStream<Long> sum = num.timeWindowAll(Time.seconds(2)).sum(0);
//打印结果
sum.print().setParallelism(1);
String jobName = StreamingDemoUnion.class.getSimpleName();
env.execute(jobName);
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import xxx.xxx.streaming.custormSource.MyNoParallelSourceScala
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoUnionScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text1 = env.addSource(new MyNoParallelSourceScala)
val text2 = env.addSource(new MyNoParallelSourceScala)
val unionall = text1.union(text2)
val sum = unionall.map(line=>{
println("接收到的数据:"+line)
line
}).timeWindowAll(Time.seconds(2)).sum(0)
sum.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
- Connect:和union类似,但是只能连接两个流,两个流的数据类型可以不同,会对两个流中的数据应用不同的处理方法。
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import xxx.xxx.streaming.custormSource.MyNoParalleSource;
/**
* connect
* 和union类似,但是只能连接两个流,两个流的数据类型可以不同,会对两个流中的数据应用不同的处理方法
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoConnect {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
//注意:针对此source,并行度只能设置为1
DataStreamSource<Long> text1 = env.addSource(new MyNoParalleSource()).setParallelism(1);
DataStreamSource<Long> text2 = env.addSource(new MyNoParalleSource()).setParallelism(1);
SingleOutputStreamOperator<String> text2_str = text2.map(new MapFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
return "str_" + value;
}
});
ConnectedStreams<Long, String> connectStream = text1.connect(text2_str);
SingleOutputStreamOperator<Object> result = connectStream.map(new CoMapFunction<Long, String, Object>() {
@Override
public Object map1(Long value) throws Exception {
return value;
}
@Override
public Object map2(String value) throws Exception {
return value;
}
});
//打印结果
result.print().setParallelism(1);
String jobName = StreamingDemoConnect.class.getSimpleName();
env.execute(jobName);
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import xxx.xxx.streaming.custormSource.MyNoParallelSourceScala
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoConnectScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text1 = env.addSource(new MyNoParallelSourceScala)
val text2 = env.addSource(new MyNoParallelSourceScala)
val text2_str = text2.map("str" + _)
val connectedStreams = text1.connect(text2_str)
val result = connectedStreams.map(line1=>{line1},line2=>{line2})
result.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
- CoMap, CoFlatMap:在ConnectedStreams中需要使用这种函数,类似于map和flatmap
- Split:根据规则把一个数据流切分为多个流
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import xxx.xxx.streaming.custormSource.MyNoParalleSource;
import java.util.ArrayList;
/**
* split
*
* 根据规则把一个数据流切分为多个流
*
* 应用场景:
* 可能在实际工作中,源数据流中混合了多种类似的数据,多种类型的数据处理规则不一样,所以就可以在根据一定的规则,
* 把一个数据流切分成多个数据流,这样每个数据流就可以使用不用的处理逻辑了
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoSplit {
public static void main(String[] args) throws Exception {
//获取Flink的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//获取数据源
//注意:针对此source,并行度只能设置为1
DataStreamSource<Long> text = env.addSource(new MyNoParalleSource()).setParallelism(1);
//对流进行切分,按照数据的奇偶性进行区分
SplitStream<Long> splitStream = text.split(new OutputSelector<Long>() {
@Override
public Iterable<String> select(Long value) {
ArrayList<String> outPut = new ArrayList<>();
if (value % 2 == 0) {
outPut.add("even");//偶数
} else {
outPut.add("odd");//奇数
}
return outPut;
}
});
//选择一个或者多个切分后的流
DataStream<Long> evenStream = splitStream.select("even");
DataStream<Long> oddStream = splitStream.select("odd");
DataStream<Long> moreStream = splitStream.select("odd","even");
//打印结果
moreStream.print().setParallelism(1);
String jobName = StreamingDemoSplit.class.getSimpleName();
env.execute(jobName);
}
}
import java.util
import org.apache.flink.streaming.api.collector.selector.OutputSelector
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import xxx.xxx.streaming.custormSource.MyNoParallelSourceScala
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoSplitScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyNoParallelSourceScala)
val splitStream = text.split(new OutputSelector[Long] {
override def select(value: Long) = {
val list = new util.ArrayList[String]()
if(value%2 == 0){
list.add("even")// 偶数
}else{
list.add("odd")// 奇数
}
list
}
})
val evenStream = splitStream.select("even")
evenStream.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
- Select:和split配合使用,选择切分后的流
两种典型用法:
dataStream.keyBy(“someKey”) // 指定对象中的 "someKey"字段作为分组key
dataStream.keyBy(0) //指定Tuple中的第一个元素作为分组key
注意:以下类型是无法作为key的
- 1:一个实体类对象,没有重写hashCode方法,并且依赖object的hashCode方法
- 2:一个任意形式的数组类型
- 3:基本数据类型,int,long
1.10.2.10.DataStream API之partition
Random partitioning:随机分区
- dataStream.shuffle()
Rebalancing:对数据集进行再平衡,重分区,消除数据倾斜 - dataStream.rebalance()
Rescaling:解释见备注 - dataStream.rescale()
Custom partitioning:自定义分区 - 自定义分区需要实现Partitioner接口
- dataStream.partitionCustom(partitioner, “someKey”)
- 或者dataStream.partitionCustom(partitioner, 0);
Broadcasting:在后面单独详解
Rescaling解释:
举个例子:
如果上游操作有2个并发,而下游操作有4个并发,那么上游的一个并发结果分配给下游的两个并发操作,另外的一个并发结果分配给了下游的另外两个并发操作.另一方面,下游有两个并发操作而上游又4个并发操作,那么上游的其中两个操作的结果分配给下游的一个并发操作而另外两个并发操作的结果则分配给另外一个并发操作。
Rescaling与Rebalancing的区别:
Rebalancing会产生全量重分区,而Rescaling不会。
自定义分区案例:
import org.apache.flink.api.common.functions.Partitioner;
/**
* Created by xxxx on 2020/10/09
*/
public class MyPartition implements Partitioner<Long> {
@Override
public int partition(Long key, int numPartitions) {
System.out.println("分区总数:"+numPartitions);
if(key % 2 == 0){
return 0;
}else{
return 1;
}
}
}
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple1;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import xxx.xxx.streaming.custormSource.MyNoParalleSource;
/**
*
* 使用自定义分析
* 根据数字的奇偶性来分区
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class SteamingDemoWithMyParitition {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Long> text = env.addSource(new MyNoParalleSource());
//对数据进行转换,把long类型转成tuple1类型
DataStream<Tuple1<Long>> tupleData = text.map(new MapFunction<Long, Tuple1<Long>>() {
@Override
public Tuple1<Long> map(Long value) throws Exception {
return new Tuple1<>(value);
}
});
//分区之后的数据
DataStream<Tuple1<Long>> partitionData = tupleData.partitionCustom(new MyPartition(), 0);
DataStream<Long> result = partitionData.map(new MapFunction<Tuple1<Long>, Long>() {
@Override
public Long map(Tuple1<Long> value) throws Exception {
System.out.println("当前线程id:" + Thread.currentThread().getId() + ",value: " + value);
return value.getField(0);
}
});
result.print().setParallelism(1);
env.execute("SteamingDemoWithMyParitition");
}
}
scala案例:
import org.apache.flink.api.common.functions.Partitioner
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
class MyPartitionerScala extends Partitioner[Long]{
override def partition(key: Long, numPartitions: Int) = {
println("分区总数:"+numPartitions)
if(key % 2 ==0){
0
}else{
1
}
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import xxx.xxx.streaming.custormSource.MyNoParallelSourceScala
/**
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
object StreamingDemoMyPartitionerScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
//隐式转换
import org.apache.flink.api.scala._
val text = env.addSource(new MyNoParallelSourceScala)
//把long类型的数据转成tuple类型
val tupleData = text.map(line=>{
Tuple1(line)// 注意tuple1的实现方式
})
val partitionData = tupleData.partitionCustom(new MyPartitionerScala,0)
val result = partitionData.map(line=>{
println("当前线程id:"+Thread.currentThread().getId+",value: "+line)
line._1
})
result.print().setParallelism(1)
env.execute("StreamingDemoWithMyNoParallelSourceScala")
}
}
1.10.2.11.DataStream API之Data Sink
writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
print() / printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
自定义输出addSink【kafka、redis】
关于redis sink的案例:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
/**
* 接收socket数据,把数据保存到redis中
*
* list
*
* lpush list_key value
*
* Created by xxxx on 2020/10/09 on 2018/10/23.
*/
public class StreamingDemoToRedis {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> text = env.socketTextStream("hadoop100", 9000, "\n");
//lpsuh l_words word
//对数据进行组装,把string转化为tuple2<String,String>
DataStream<Tuple2<String, String>> l_wordsData = text.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
return new Tuple2<>("l_words", value);
}
});
//创建redis的配置
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop110").setPort(6379).build();
//创建redissink
RedisSink<Tuple2<String, String>> redisSink = new RedisSink<>(conf, new MyRedisMapper());
l_wordsData.addSink(redisSink);
env.execute("StreamingDemoToRedis");
}
public static class MyRedisMapper implements RedisMapper<Tuple2<String, String>>{
//表示从接收的数据中获取需要操作的redis key
@Override
public String getKeyFromData(Tuple2<String, String> data) {
return data.f0;
}
//表示从接收的数据中获取需要操作的redis value
@Override
public String getValueFromData(Tuple2<String, String> data) {
return data.f1;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.LPUSH);
}
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
/**
*
*
* Created by xxxx on 2020/10/09 .
*/
object StreamingDataToRedisScala {
def main(args: Array[String]): Unit = {
//获取socket端口号
val port = 9000
//获取运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//链接socket获取输入数据
val text = env.socketTextStream("hadoop100",port,'\n')
//注意:必须要添加这一行隐式转行,否则下面的flatmap方法执行会报错
import org.apache.flink.api.scala._
val l_wordsData = text.map(line=>("l_words_scala",line))
val conf = new FlinkJedisPoolConfig.Builder().setHost("hadoop110").setPort(6379).build()
val redisSink = new RedisSink[Tuple2[String,String]](conf,new MyRedisMapper)
l_wordsData.addSink(redisSink)
//执行任务
env.execute("Socket window count");
}
class MyRedisMapper extends RedisMapper[Tuple2[String,String]]{
override def getKeyFromData(data: (String, String)) = {
data._1
}
override def getValueFromData(data: (String, String)) = {
data._2
}
override def getCommandDescription = {
new RedisCommandDescription(RedisCommand.LPUSH)
}
}
}

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)