Python爬虫1:简单抓取网页
·
最近开始研究python,就想学习一下爬虫方面的技能,我使用的python3,找了资料,用pycharm运行成功后整理记录一下,
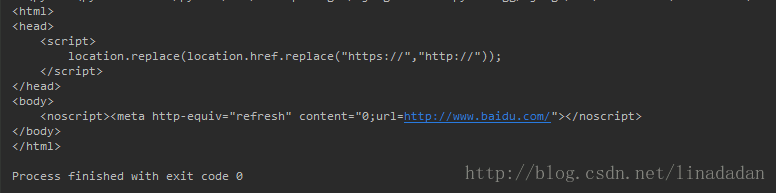
代码如下:
运行结果:#!/usr/bin/python # coding:utf-8 import urllib.request def getHtmlContent(url): request = urllib.request.Request(url) response = urllib.request.urlopen(request) data = response.read() data = data.decode('utf-8') return data def main(): url="https://www.baidu.com" print(getHtmlContent(url)) if __name__ == '__main__': main()

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)