语音识别实践7.1——训练加速
GPU流水线反向传播异步随机梯度下降增广拉格朗日算法及乘子方向交替算法减小模型规模改善训练速度可以通过更好的训练算法或者使用更小的模型。DNN中的权值矩阵大体上是低秩的,且DNN最后一层占用了系统50%的模型参数以及训练计算量。且DNN任意层只有最大的30%~40%的权重是重要的,每个权值矩阵可以近似地进行低秩分解且没有识别精度的损失。使用SVD,每个权值矩阵可以分解为两个更小的矩阵,...
·
- GPU流水线反向传播
- 异步随机梯度下降
- 增广拉格朗日算法及乘子方向交替算法
- 减小模型规模
改善训练速度可以通过更好的训练算法或者使用更小的模型。DNN中的权值矩阵大体上是低秩的,且DNN最后一层占用了系统50%的模型参数以及训练计算量。且DNN任意层只有最大的30%~40%的权重是重要的,每个权值矩阵可以近似地进行低秩分解且没有识别精度的损失。
使用SVD,每个权值矩阵可以分解为两个更小的矩阵,从而大大减少了DNN参数数量。
用W表示一个m n的低秩矩阵。如果W的秩为r,存在一个分解W=W2W1,W2是一个秩为r,大小为m r的矩阵,W1是一个秩为r、大小为r n的矩阵。我们用W2和W1相乘代替矩阵W,如果满足mr+rn<mn,则有可能减小模型规模并加速训练。如果想要减少模型p倍,则需要满足r<p∗m∗nm+nr < \frac{{p*m*n}}{{m + n}}r<m+np∗m∗n。当用W1和W2替换W时,等价于引入了一个线性层W1,后面接一个非线性层W2.如下图所示: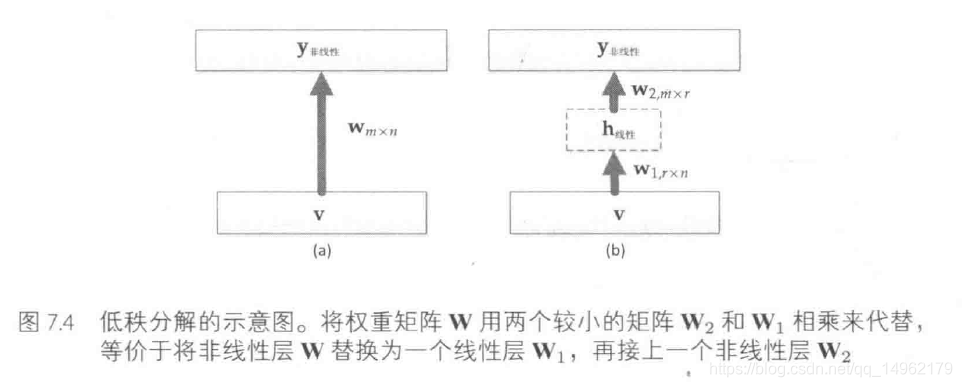
这是因为:
y=f(Wv)=f(W1W2v)=f(W2h)y=f(Wv)=f(W1W2v)=f(W2h)y=f(Wv)=f(W1W2v)=f(W2h)
其中,h=W1v是个先行转换,对不同的任务,如果只把softmax层分解为秩在128到512之间的矩阵,模型性能不会降低。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)