决策树对鸢尾花数据两特征组合分类python代码的结果_基于决策树—鸢尾花分类...
决策树算法广泛应用于:语音识别、医疗诊断、客户关系管理、模式识别、专家系统等,在实际工作中,必须根据数据类型的特点及数据集的大小,选择合适的算法。本文选择经典案例——《鸢尾花分类》一、决策树定义决策树算法是一种基于实例的自上而下的算法,常用于分类与预测。利用树型结构二分类,问题主要集中在剪枝与训练样本。决策树思维是一种逻辑思考方式,逐层的设定条件对事物进行刷选判断,每一次刷选判断都是一次决策,最终

决策树算法广泛应用于:语音识别、医疗诊断、客户关系管理、模式识别、专家系统等,在实际工作中,必须根据数据类型的特点及数据集的大小,选择合适的算法。
本文选择经典案例——《鸢尾花分类》
一、决策树定义
决策树算法是一种基于实例的自上而下的算法,常用于分类与预测。利用树型结构二分类,问题主要集中在剪枝与训练样本。
决策树思维是一种逻辑思考方式,逐层的设定条件对事物进行刷选判断,每一次刷选判断都是一次决策,最终得到达到目的;整个思考过程,其逻辑结构类似分叉的树状,因此称为决策树思维;
决策树森林由几种决策树的预测组合成一个最终的预测,为应用集成思想提高决策树的准确率。
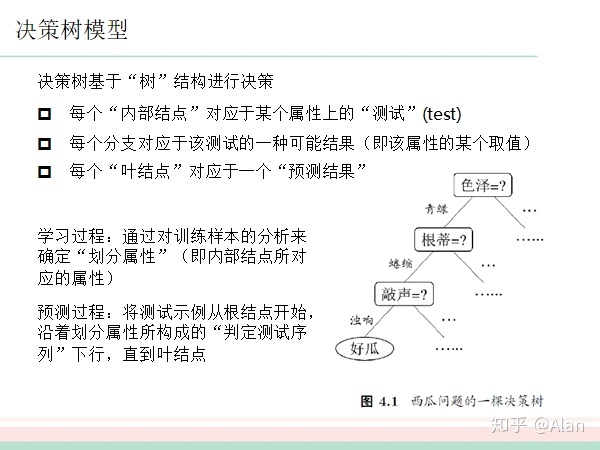
例:公式招聘时的决策树思维
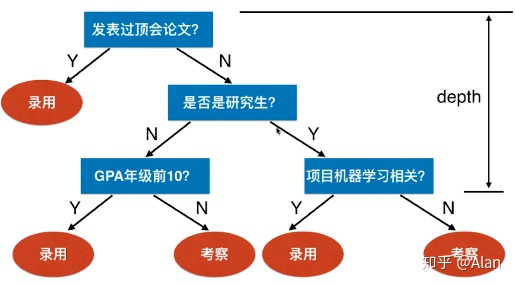
此过程形成了一个树的结构,树的叶子(录用 / 考察)节点位置是做出的决定,也可以理解为是对输出(也就是应聘者的信息)的分类:录用、考察——这样的逻辑思考的过程就叫决策树。
二、决策树分类的基本流程
2.1基本算法流程

2.2特征选择与算法选择
首先要考虑哪个变量是树根,哪个是树节点,为此,我们需要考虑变量的重要性。
怎么衡量?,或者说怎样选择?有三种算法:
- ID3算法 :使用信息增益(作为不纯度)——适合大规模数据处理
- C4.5算法 :使用信息增益率(作为不纯度)——适合大规模数据处理(相较于ID3算法更好,但是计算资源占用大)
- CART 算法:使用基尼系数(作为不纯度)——适合小样本数据处理
不同的方法形成不同的决策树,决策树方法会把每个特征都试一遍,最后选取能够使分类分的最好的特征(e.g. 将A属性作为父节点,产生的纯度增益(GainA)要大于B属性作为父节点,则A作为优先选取的属性)。




2.3划分选择与剪枝


三、案例分析
基于决策树对鸢尾花分类
#基于决策树的鸢尾花分类
'''
- 描述:“代码实操”以及内容延伸部分源代码
- 时间:2019-07-24
- 作者:欧XX(Alan Ou)
- 程序开发环境:win10 64位
- Python版本:64位 3.7
- 依赖库:numpy、pandas、sklearn、matplotlib
- 程序输入:iris.cvs
- 程序输出:iris_classification_result.xlsx
# -*- coding: utf-8 -*-
'''导入模块
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn import tree
读取数据
iris = load_iris()
iris_feature = iris.data #特征数据
iris_target = iris.target #分类数据
#鸢尾花数组长度为150,共3种类别。
#种类为:Iris Setosa(山鸢花)、Iris Versicolour(杂色鸢尾)Iris Virginica(维吉尼亚鸢尾),分别用0、1、2标签代表
print (iris.data) #输出数据集
print ('-----------------------------')
print (iris.target) #输出真实标签
print (len(iris.target) )
print ('-----------------------------')
print (iris.data.shape ) #150个样本 每个样本4个特征
print ('-----------------------------')打印返回值:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
[5.4 3.7 1.5 0.2]
[4.8 3.4 1.6 0.2]
[4.8 3. 1.4 0.1]
[4.3 3. 1.1 0.1]
[5.8 4. 1.2 0.2]
[5.7 4.4 1.5 0.4]
[5.4 3.9 1.3 0.4]
[5.1 3.5 1.4 0.3]
[5.7 3.8 1.7 0.3]
[5.1 3.8 1.5 0.3]
[5.4 3.4 1.7 0.2]
[5.1 3.7 1.5 0.4]
[4.6 3.6 1. 0.2]
[5.1 3.3 1.7 0.5]
[4.8 3.4 1.9 0.2]
[5. 3. 1.6 0.2]
[5. 3.4 1.6 0.4]
[5.2 3.5 1.5 0.2]
[5.2 3.4 1.4 0.2]
[4.7 3.2 1.6 0.2]
[4.8 3.1 1.6 0.2]
[5.4 3.4 1.5 0.4]
[5.2 4.1 1.5 0.1]
[5.5 4.2 1.4 0.2]
[4.9 3.1 1.5 0.2]
[5. 3.2 1.2 0.2]
[5.5 3.5 1.3 0.2]
[4.9 3.6 1.4 0.1]
[4.4 3. 1.3 0.2]
[5.1 3.4 1.5 0.2]
[5. 3.5 1.3 0.3]
[4.5 2.3 1.3 0.3]
[4.4 3.2 1.3 0.2]
[5. 3.5 1.6 0.6]
[5.1 3.8 1.9 0.4]
[4.8 3. 1.4 0.3]
[5.1 3.8 1.6 0.2]
[4.6 3.2 1.4 0.2]
[5.3 3.7 1.5 0.2]
[5. 3.3 1.4 0.2]
[7. 3.2 4.7 1.4]
[6.4 3.2 4.5 1.5]
[6.9 3.1 4.9 1.5]
[5.5 2.3 4. 1.3]
[6.5 2.8 4.6 1.5]
[5.7 2.8 4.5 1.3]
[6.3 3.3 4.7 1.6]
[4.9 2.4 3.3 1. ]
[6.6 2.9 4.6 1.3]
[5.2 2.7 3.9 1.4]
[5. 2. 3.5 1. ]
[5.9 3. 4.2 1.5]
[6. 2.2 4. 1. ]
[6.1 2.9 4.7 1.4]
[5.6 2.9 3.6 1.3]
[6.7 3.1 4.4 1.4]
[5.6 3. 4.5 1.5]
[5.8 2.7 4.1 1. ]
[6.2 2.2 4.5 1.5]
[5.6 2.5 3.9 1.1]
[5.9 3.2 4.8 1.8]
[6.1 2.8 4. 1.3]
[6.3 2.5 4.9 1.5]
[6.1 2.8 4.7 1.2]
[6.4 2.9 4.3 1.3]
[6.6 3. 4.4 1.4]
[6.8 2.8 4.8 1.4]
[6.7 3. 5. 1.7]
[6. 2.9 4.5 1.5]
[5.7 2.6 3.5 1. ]
[5.5 2.4 3.8 1.1]
[5.5 2.4 3.7 1. ]
[5.8 2.7 3.9 1.2]
[6. 2.7 5.1 1.6]
[5.4 3. 4.5 1.5]
[6. 3.4 4.5 1.6]
[6.7 3.1 4.7 1.5]
[6.3 2.3 4.4 1.3]
[5.6 3. 4.1 1.3]
[5.5 2.5 4. 1.3]
[5.5 2.6 4.4 1.2]
[6.1 3. 4.6 1.4]
[5.8 2.6 4. 1.2]
[5. 2.3 3.3 1. ]
[5.6 2.7 4.2 1.3]
[5.7 3. 4.2 1.2]
[5.7 2.9 4.2 1.3]
[6.2 2.9 4.3 1.3]
[5.1 2.5 3. 1.1]
[5.7 2.8 4.1 1.3]
[6.3 3.3 6. 2.5]
[5.8 2.7 5.1 1.9]
[7.1 3. 5.9 2.1]
[6.3 2.9 5.6 1.8]
[6.5 3. 5.8 2.2]
[7.6 3. 6.6 2.1]
[4.9 2.5 4.5 1.7]
[7.3 2.9 6.3 1.8]
[6.7 2.5 5.8 1.8]
[7.2 3.6 6.1 2.5]
[6.5 3.2 5.1 2. ]
[6.4 2.7 5.3 1.9]
[6.8 3. 5.5 2.1]
[5.7 2.5 5. 2. ]
[5.8 2.8 5.1 2.4]
[6.4 3.2 5.3 2.3]
[6.5 3. 5.5 1.8]
[7.7 3.8 6.7 2.2]
[7.7 2.6 6.9 2.3]
[6. 2.2 5. 1.5]
[6.9 3.2 5.7 2.3]
[5.6 2.8 4.9 2. ]
[7.7 2.8 6.7 2. ]
[6.3 2.7 4.9 1.8]
[6.7 3.3 5.7 2.1]
[7.2 3.2 6. 1.8]
[6.2 2.8 4.8 1.8]
[6.1 3. 4.9 1.8]
[6.4 2.8 5.6 2.1]
[7.2 3. 5.8 1.6]
[7.4 2.8 6.1 1.9]
[7.9 3.8 6.4 2. ]
[6.4 2.8 5.6 2.2]
[6.3 2.8 5.1 1.5]
[6.1 2.6 5.6 1.4]
[7.7 3. 6.1 2.3]
[6.3 3.4 5.6 2.4]
[6.4 3.1 5.5 1.8]
[6. 3. 4.8 1.8]
[6.9 3.1 5.4 2.1]
[6.7 3.1 5.6 2.4]
[6.9 3.1 5.1 2.3]
[5.8 2.7 5.1 1.9]
[6.8 3.2 5.9 2.3]
[6.7 3.3 5.7 2.5]
[6.7 3. 5.2 2.3]
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
-----------------------------
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
-----------------------------
(150, 4)
-----------------------------导入数据集
#导入数据集iris
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pd.read_csv(url, names=names) #读取csv数据
print(dataset.describe())
print ('-----------------------------')打印返回值:
sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
数据可视化
#4种特征维度分布情况
#直方图 histograms
dataset.hist()
plt.show()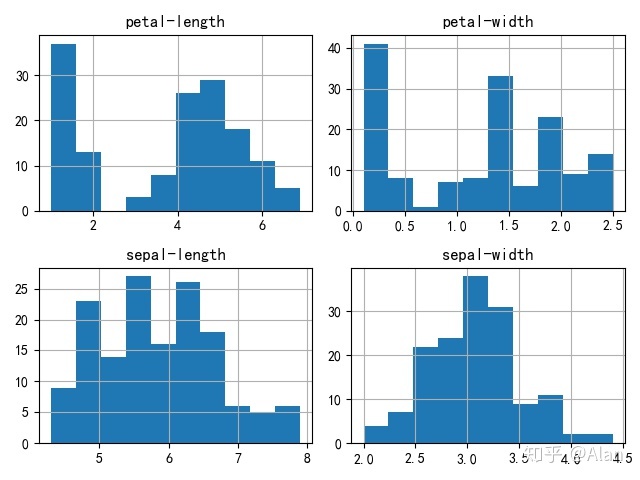
训练分类
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier() # 所以参数均置为默认状态
clf.fit(iris.data, iris.target) # 使用训练集训练模型
print(clf)
print ('-----------------------------')
predicted = clf.predict(iris.data)
print(predicted)
print ('-----------------------------')
打印返回值
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
-----------------------------
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]# 获取花卉两列数据集
X = iris.data
L1 = [x[0] for x in X]
print(L1)
print ('-----------------------------')
L2 = [x[1] for x in X]
print (L2)
print ('-----------------------------')
打印返回值:
[5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.8, 4.8, 4.3, 5.8, 5.7, 5.4,
5.1, 5.7, 5.1, 5.4, 5.1, 4.6, 5.1, 4.8, 5.0, 5.0, 5.2, 5.2, 4.7, 4.8, 5.4, 5.2, 5.5,
4.9, 5.0, 5.5, 4.9, 4.4, 5.1, 5.0, 4.5, 4.4, 5.0, 5.1, 4.8, 5.1, 4.6, 5.3, 5.0, 7.0,
6.4, 6.9, 5.5, 6.5, 5.7, 6.3, 4.9, 6.6, 5.2, 5.0, 5.9, 6.0, 6.1, 5.6, 6.7, 5.6, 5.8,
6.2, 5.6, 5.9, 6.1, 6.3, 6.1, 6.4, 6.6, 6.8, 6.7, 6.0, 5.7, 5.5, 5.5, 5.8, 6.0, 5.4,
6.0, 6.7, 6.3, 5.6, 5.5, 5.5, 6.1, 5.8, 5.0, 5.6, 5.7, 5.7, 6.2, 5.1, 5.7, 6.3, 5.8,
7.1, 6.3, 6.5, 7.6, 4.9, 7.3, 6.7, 7.2, 6.5, 6.4, 6.8, 5.7, 5.8, 6.4, 6.5, 7.7, 7.7,
6.0, 6.9, 5.6, 7.7, 6.3, 6.7, 7.2, 6.2, 6.1, 6.4, 7.2, 7.4, 7.9, 6.4, 6.3, 6.1, 7.7,
6.3, 6.4, 6.0, 6.9, 6.7, 6.9, 5.8, 6.8, 6.7, 6.7, 6.3, 6.5, 6.2, 5.9]
-----------------------------
[3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.4, 3.0, 3.0, 4.0, 4.4, 3.9,
3.5, 3.8, 3.8, 3.4, 3.7, 3.6, 3.3, 3.4, 3.0, 3.4, 3.5, 3.4, 3.2, 3.1, 3.4, 4.1, 4.2,
3.1, 3.2, 3.5, 3.6, 3.0, 3.4, 3.5, 2.3, 3.2, 3.5, 3.8, 3.0, 3.8, 3.2, 3.7, 3.3, 3.2,
3.2, 3.1, 2.3, 2.8, 2.8, 3.3, 2.4, 2.9, 2.7, 2.0, 3.0, 2.2, 2.9, 2.9, 3.1, 3.0, 2.7,
2.2, 2.5, 3.2, 2.8, 2.5, 2.8, 2.9, 3.0, 2.8, 3.0, 2.9, 2.6, 2.4, 2.4, 2.7, 2.7, 3.0,
3.4, 3.1, 2.3, 3.0, 2.5, 2.6, 3.0, 2.6, 2.3, 2.7, 3.0, 2.9, 2.9, 2.5, 2.8, 3.3, 2.7,
3.0, 2.9, 3.0, 3.0, 2.5, 2.9, 2.5, 3.6, 3.2, 2.7, 3.0, 2.5, 2.8, 3.2, 3.0, 3.8, 2.6,
2.2, 3.2, 2.8, 2.8, 2.7, 3.3, 3.2, 2.8, 3.0, 2.8, 3.0, 2.8, 3.8, 2.8, 2.8, 2.6, 3.0,
3.4, 3.1, 3.0, 3.1, 3.1, 3.1, 2.7, 3.2, 3.3, 3.0, 2.5, 3.0, 3.4, 3.0]
-----------------------------
绘图
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
plt.scatter(X[100:, 0], X[100:, 1], color='green', marker='s', label='Virginica')
#中文乱码解决
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.title("DTC基于决策数的鸢尾花分类")#标题
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xticks(())
plt.yticks(())
plt.legend(loc=2)
plt.show()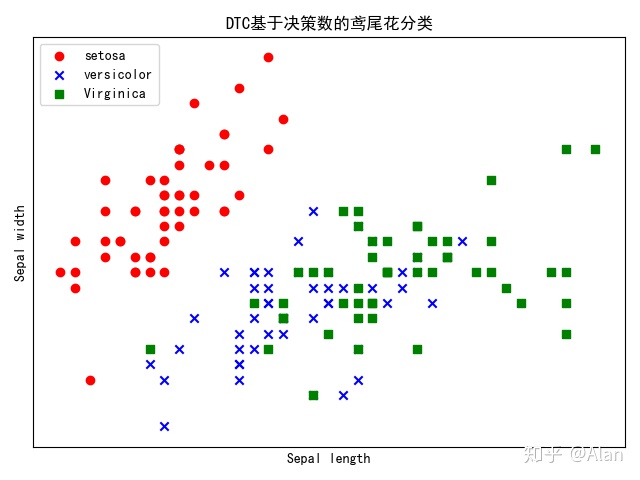
学习心得:
决策树优点:
- 简单直观,生成决策树很直观,基本不需要提前归一化、处理缺失值。
- 使用决策树预测的代价是O(
)。m为样本数。
- 既可以处理离散值也可以处理连续值,易解释。
- 可处理多维度输出的分类问题。
- 对于异常点的容错能力好,可交叉验证的剪枝(后剪枝)来选择模型,从而提高泛化能力。
决策树缺点:
- 决策树算法会过拟合,导致泛化能力不强,可以通过设置节点最少样本数量和限制决策树深度来改进。
- 决策树易受到样本变动,导致树结构改变。通过集成算法学习之类的方法优化。
- 有比较复杂的关系,决策树很难学习,比如异或。一般用神经网络分类方法来解决。
- 特征样本比例过大,生成决策树容易偏向这些特征。这个通过调节样本权重来改善。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)