机器学习听课笔记( 第一章 序言-MOOC-浙江大学-机器学习)
目录机器学习 序言什么是机器学习?机器学习的分类监督学习强化学习(增强学习)机器学习的步骤没有免费午餐定理总结机器学习 序言什么是机器学习?定义一:其中,显著式编程:人为总结出定义,作用到计算机。非显著式编程:让计算机自己总结。就是我们规定行为和收益函数,让计算机自己去获得最大收益的行为。定义二:这个定义更加数学化,拿计算机识别菊花和玫瑰做例子:任务T:编写计算机程序识别菊花和玫瑰。经验E:一大堆
机器学习 序言
什么是机器学习?
定义一:
其中,
显著式编程:人为总结出定义,作用到计算机。
非显著式编程:让计算机自己总结。
就是我们规定行为和收益函数,让计算机自己去获得最大收益的行为。
定义二:
这个定义更加数学化,拿计算机识别菊花和玫瑰做例子:
任务T:编写计算机程序识别菊花和玫瑰。
经验E:一大堆菊花和玫瑰的图片。
性能指标P:不同机器学习算法会有不同。
机器学习的分类
按任务是否需要和环境交互获得经验将机器学习分为:
监督学习和强化学习。
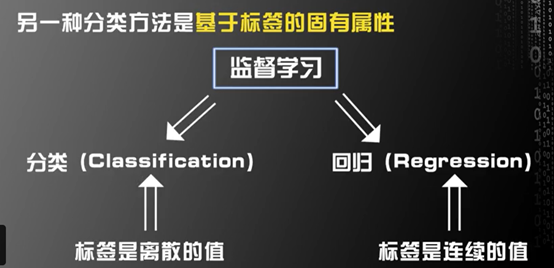
对监督学习还可以进行更细致的分类,
首先,按照训练数据是否存在标签,分为传统监督学习、半监督学习和非监督学习。
其次,按照标签是连续还是离散,将监督学习分为分类问题和回归问题。
监督学习
传统监督学习:从人工给定的训练集中学习出一个函数,当有新的数据时,可以通过这个函数得出结果。(每一个训练数据都有对应的标签)。其算法:1.支持向量机。2.人工神经网络。2.深度神经网络
非监督学习:训练集无人为标注结果。(所有训练数据都没有对应的标签)。其算法:聚类,EM算法。主程序分析
半监督学习:训练数据中一部分有标签一部分没标签
强化学习(增强学习):计算机通过与环境的互动,强化自己的行为模式。
强化学习(增强学习)
计算机通过与环境的互动,强化自己的行为模式。
机器学习的步骤
第一步:特征提取(好的特征很重要)
特征提取:通过训练样本获得的,对机器学习任务有帮助的多维度数据。
第二步:特征选择
特征选择:特征提取结果(选择差别大的特征来进行机器学习)
第三步:选择算法
支持向量机:线性内核,多项式核,高斯径向基数核
训练结果:特征空间 ,其关键词:维度,标准,
(可以高于二维)
要针对不同的应用场景选择合适的机器学习算法。
机器算法的流程: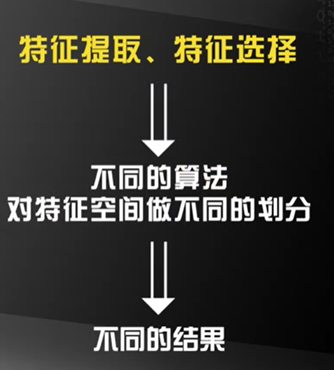
没有免费午餐定理
在任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对训练样本在特征空间的先分布有一定假设,那么表现好与表现不好的情况一样多。
所以,如果不对特征空间的先验分布有假设,那么所以算法的表现都一样。
总结


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)