A NIR-to-VIS face recognition via part adaptive and relation attention module阅读笔记
2021Computer Vision and Pattern RecognitionRushuang Xu, MyeongAh Cho, Sangyoun Lee一、简介许多研究集中在提取领域不变特征,如面部部分关系信息。然而,当姿态变化发生时,面部组件位置改变,并且提取不同的部分关系。我们提出了一个部件关系注意模块,该模块裁剪通过语义遮罩获得的面部部件,并使用这些代表性特征中的每一个来执行关系
2021
Computer Vision and Pattern Recognition
Rushuang Xu, MyeongAh Cho, Sangyoun Lee
一、简介
许多研究集中在提取领域不变特征,如面部部分关系信息。然而,当姿态变化发生时,面部组件位置改变。
面部组件之间的关系对于表示多域身份信息很重要。提出了一个组件关系注意模块(PRAM),该模块通过语义分割裁剪获得面部组件,并使用这些代表性的面部组件特征来进行关系建模,以学习对领域、姿势和情绪变化鲁棒的特征。
提出了一个基于语义分割的组件自适应三重损失函数(LCAT),使网络能够更有效地通过选择信息进行学习,解决姿态和表情变化带来的难题。
二、模型
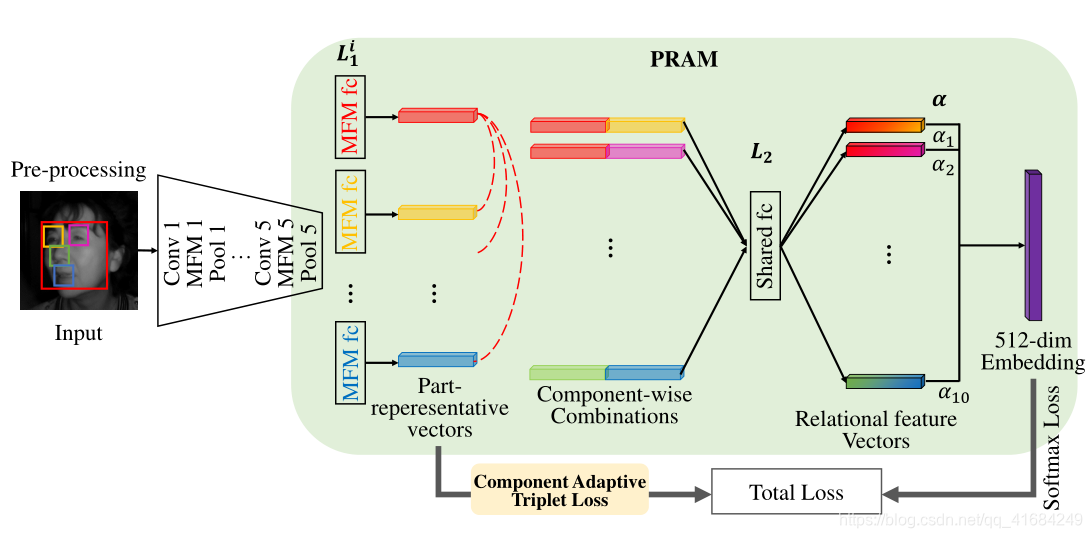
Part Relation Attention Module(PRAM):
第一步,使用分割网络将面部图像裁剪成四个部分:左眼、右眼、鼻子和嘴。将四个部分图像和整个面部图像(总共五个图像)分别输入主干LightCNN-9。
LightCNN-9只训练8和9层,以及其中的5个MFM FC层。MFM FC层是一种特殊的最大输出操作,它使用竞争关系来获得可推广性,这有利于跨域学习。
第二步,提取无顺序的成对组合,并以固定的顺序排列它们,以呈现两个组件之间的关系。
第三步,所有的组合被输入到一个参数共享的FC层(L2),以保证网络学习两个代表性特征之间相同的功能关系。通过这种计算,可以得到具有统一标准的某些区域之间的关系。
第四步,提出了一个可学习的权重α来获取每个关系的强度。一个512-dim的最终嵌入向量通过这些关系特征的α加权和来计算。
三、损失函数
Component Adaptive Triplet Loss Function:
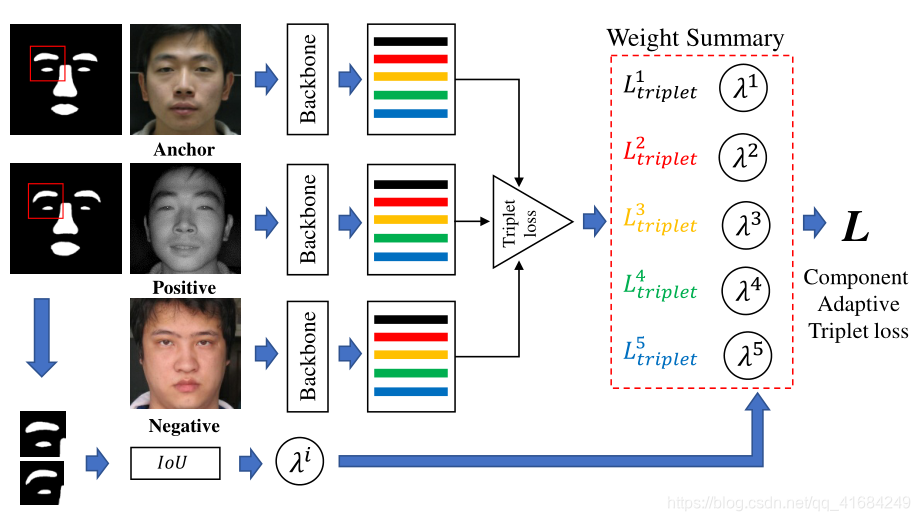
组件自适应三重损失函数。
对原始图像及其四个分量分别使用了五个损失项。
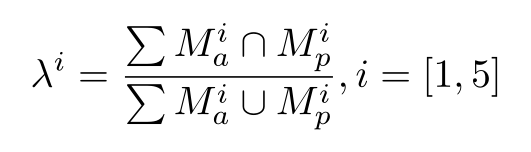
为了避免由于大的姿势或情绪变化而模糊不清的人脸在网络训练中导致偏差的负面影响,提出了一个函数,该函数基于两个例子的掩码之间的匹配区域自适应地为五个项分配权重。
a表示源域(VIS)人脸。
p表示与a同一身份的目标域(NIR)人脸。
M表示二进制图像,背景部分被设置为0,目标部分被设置为1。
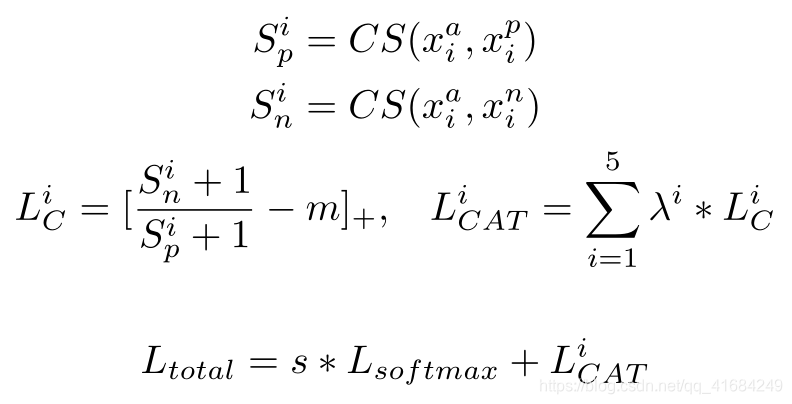
CS表示余弦相似度。
a表示源域(VIS)人脸。
p表示与a同一身份的目标域(NIR)人脸。
n表示与a不同身份的源域(VIS)人脸。
使用带有余量的三重损失,m取0.55。
1张人脸图像会被分割成5张图,一一求损失,然后在加权取平均。
比例因子s=24。
四、实验
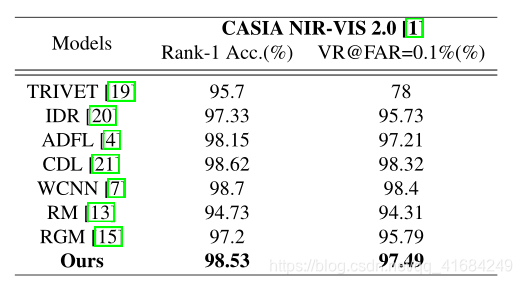
CASIA NIR-VIS 2.0:
BUAA-VisNir:


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)