卷积神经网络
深度神经网络已经在语音识别、图像识别等领域取得前所未有的成功。这一篇,讲一讲经典的卷积神经网络。我不打算详细描述卷积神经网络的生物学运行机理,因为网络上有太多的教程可以参考。这里,主要描述其数学上的计算过程,也就是如何自己编程去实现的问题。
一、概述
回想一下BP神经网络。BP网络每一层节点是一个线性的一维排列状态,层与层的网络节点之间是全连接的。这样设想一下,如果BP网络中层与层之间的节点连接不再是全连接的,而是局部连接的。这样,就是一种最简单的一维卷积网络。如果我们把上述这个思想扩展到二维,这就是我们在大多数参考资料上看到的卷积神经网络。具体参看下图:
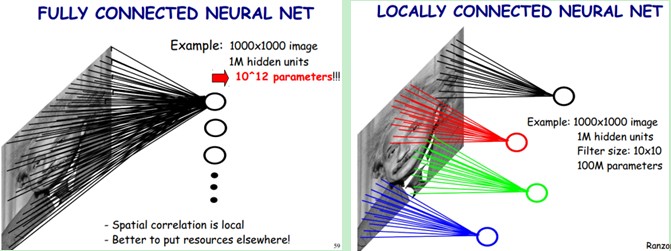
上图左:全连接网络。如果我们有1000*1000像素的图像,有1百万个隐层神经元,每个隐层神经元都连接图像的每一个像素点,就有1000*1000*1000000=10^12个连接,也就是10^12个权值参数。
上图右:局部连接网络。每一个节点与上层节点同位置附近10*10的窗口相连接,则1百万个隐层神经元就只有100w乘以100,即10^8个参数。其权值连接个数比原来减少了四个数量级。
根据BP网络信号前向传递过程,我们可以很容易计算网络节点的输出。例如,对于上图中被标注为红色节点的净输入,就等于所有与红线相连接的上一层神经元节点值与红色线表示的权值之积的累加。这样的的计算过程,很多书上称其为卷积。
事实上,对于数字滤波而言,其滤波器的系数通常是对称的。否则,卷积的计算需要先反向对折,然后进行乘累加的计算。上述神经网络权值满足对称码?我想答案是否定的。所以上述称其为卷积运算,显然是有失偏颇的。但这并不重要,仅仅是一个名词称谓而已。只是,搞信号处理的人,在初次接触卷积神经网络的时候,带来了一些理解上的误区。
卷积神经网络另外一个特性是权值共享。例如,就上面右边那幅图来说,权值共享,不是说,所有的红色线标注的连接权值相同。这一点初学者容易产生误解。
上面描述的只是单层网络结构,前A&T Shannon Lab的Yann LeCun等人据此提出了基于卷积神经网络的一个文字识别系统LeNet-5。该系统90年代就被用于银行手写数字的识别。
二、文字识别系统LeNet-5
在经典的模式识别中,一般是事先提取特征。提取诸多特征后,要对这些特征进行相关性分析,找到最能代表字符的特征,去掉对分类无关和自相关的特征。然而,这些特征的提取太过于依赖人的经验和主观意识,提取到的特征的不同对分类性能影响很大,甚至提取的特征的顺序也会影响最后的分类性能。同时,图像预处理的好坏也会影响到提取的特征。那么,如何把特征提取这一过程作为一个自适应、自学习的过程,通过机器学习找到分类性能最优的特征呢?
卷积神经元每一个隐层的单元提取图像局部特征,将其映射为一个平面,特征映射函数采用sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。每个神经元与前一层的局部感受野相连。注意前面我们说了,不是局部连接的神经元权值相同,而是同一平面层的神经元权值相同,有相同程度的位移、旋转不变性。每个特征提取后都紧跟着一个用来求局部平均与二次提取的亚取样层。这种特有的两次特征提取结构使得网络对输入样本有较高的畸变容忍能力。也就是说,卷积神经网络通过局部感受野、共享权值和亚取样来保证图像对位移、缩放、扭曲的鲁棒性。
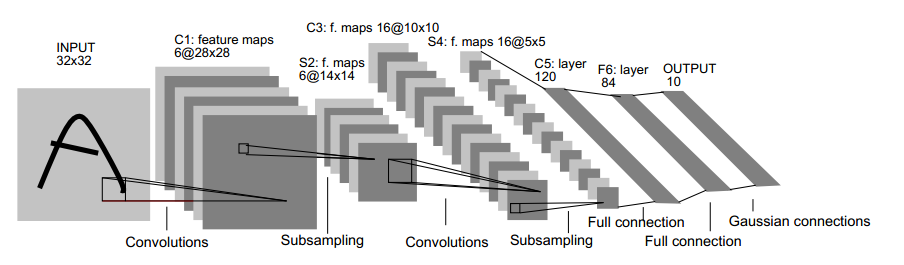
下面,有必要来解释下上面这个用于文字识别的LeNet-5深层卷积网络。
- 输入图像是32*32的大小,局部滑动窗的大小是5*5的,由于不考虑对图像的边界进行拓展,则滑动窗口将有28*28个不同的位置,也就是C1层的大小是28*28。这里设定有6个不同的C1层,每一个C1层内的权值是相同的。
- S2层是一个下采样层。简单地说,由4个点下采样为1个点,也就是4个数的加权平均。但在LeNet-5系统,下采样层比较复杂,因为这4个加权系数也需要学习得到,这显然增加了模型的复杂度。在斯坦福关于深度学习的教程中,这个过程叫做pool。
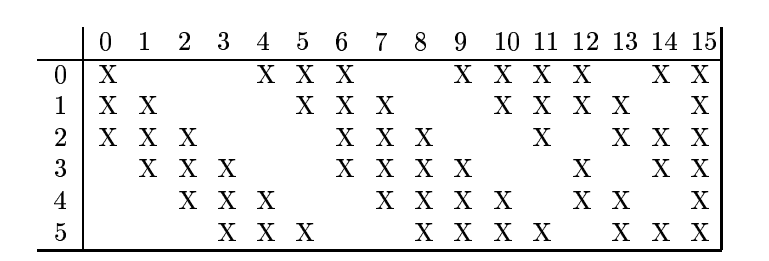
- 根据对前面C1层同样的理解,我们很容易得到C3层的大小为10*10。只不过C3层变成了16个10*10的网络。试想一下,如果S2层只有1个平面,那么由S2层得到C3层就和由输入层得到C1层是完全一样的。但是,S2层有多层,那么,我们只需按照一定的顺序组合这些层就可以了。具体的组合规则,在LeNet-5系统中给出了下面的表格,简单来说,例如对于C3层第0张特征图,其每一个节点与S2层的第0张特征图、第1张特征图、第2张特征图,总共3个5*5个节点相连接。后面依此类推,C3层每一张特征映射图的权值是相同的:
- S4层是在C3层基础上下采样,前面已述。在后面的层由于每一层节点个数比较少,都是全连接层,这个比较简单,不再赘述。
三、简化的LeNet-5系统
简化的LeNet-5系统把下采样层和卷积层结合起来,避免了下采样层过多的参数学习过程,同样保留了对图像位移、扭曲的鲁棒性。其网络结构图如下所示:
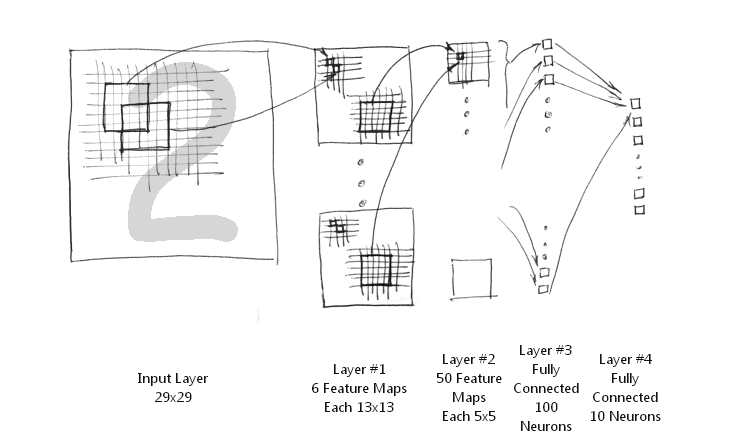
简化的LeNet-5系统包括输入层的话,只有5层结构,而原始LeNet-5结构不包含输入层就已经是7层网络结构了。它实现下采样非常简单,直接取其第一个位置节点上的值就可以了。
- 输入层。MNIST手写数字图像的大小是28*28的,这里通过补零扩展为29*29的大小。这样输入层神经节点个数为29*29等于841个。
- 第一层。由6张不同的特征映射图组成。每一张特征图的大小是13*13。注意,由于卷积窗大小为5*5,加上下采样过程,易得其大小为13*13。所以,第二层共有6*13*13等于1014个神经元节点。每一张特征图加上偏置共有5*5+1等于26个权值需要训练,总共有6*26等于156个不同的权值。即总共有1014*156等于26346条连接线。
- 第二层。由50张不同的特征映射图组成。每一张特征图的大小是5*5。注意,由于卷积窗大小为5*5,加上下采样过程,易得其大小为5*5。由于上一层是由多个特征映射图组成,那么,如何组合这些特征形成下一层特征映射图的节点呢?简化的LeNet-5系统采用全部所有上层特征图的组合。也就是原始LeNet-5特征映射组合图的最后一列的组合方式。因此,总共有5*5*50等于1250个神经元节点,有(5*5+1)*6*50等于7800个权值,总共有1250*26等于32500条连接线。
- 第三层。这一层是一个一维线性排布的网络节点,与前一层是全连接的网络,其节点个数设为100,故而总共有100*(1250+1)等于125100个不同的权值,同时,也有相同数目的连接数。
- 第四层。这一层是网络的输出层。如果要识别0~9数字的话,就是10个节点。该层与前一层是全连接的,故而,总共有10*(100+1)等于1010个权值,有相同数目的连接线。
四、卷积神经网络的实现问题
网上可以下载到很多关于卷积神经网络的源码,其中有matlab的,也有C++的。如果自己编程,需要注意些什么问题呢?
由于卷积神经网络采用BP网络相同的算法。所以,采用现有BP网络就可以实现。开源的神经网络代码FAAN可以利用。这个开源的实现采用了一些代码优化技术,有双精度,单精度,定点运算三个不同的版本。
由于经典的BP网络是一个一维节点分布排列,而卷积神经网络是二维网络结构。所以,要把卷积神经网络的每一层,按照一定的顺序和规则映射为一维节点分布,然后,按照这个分布创建一个多层反向传播算法的网络结构,就可以按照一般的BP训练算法去学习网络参数。对于实际环境中新样本的预测,也采用BP算法中相同信号前向传递算法进行。具体细节也可以参考网上的一个开源代码,链接如下:
http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi
注:这个代码在创建CNN的时候有个明显的BUG,如果你看明白了我上面对简化的LeNet-5的结构描述,一眼就会找出问题所在。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)