分布式复习7~9章
参考:整体(“爹!”)https://zhuanlan.zhihu.com/p/341821846https://blog.csdn.net/u011544909/article/details/115004321本文是在“整体”上,结合自己的看法和老师给的考察框架总结的may the flame guide thee第七章 分布式文件系统0.文件系统提供文件的管理命名空间文件操作的APIcre
参考:
整体(“爹!”)https://zhuanlan.zhihu.com/p/341821846
https://blog.csdn.net/u011544909/article/details/115004321
本文是在“整体”上,结合自己的看法和老师给的考察框架总结的
may the flame guide thee
第七章 分布式文件系统
0.文件系统提供文件的管理
-
命名空间
-
文件操作的API
create, delete, open, close, read, write, append …
-
物理的存储管理和分配
块存储
-
安全保护
访问控制
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ejmEne33-1638724574927)(C:\Users\14182\AppData\Roaming\Typora\typora-user-images\image-20211205162341539.png)]
1.分布式文件系统的需求
能用(硬件和系统异构性)-》和本地一样(透明性),包括扩展,性能,位置和访问方式,移动方式。-》稳定(文件备份且一致 + 容错,一次一反应)-》安全(安全身份认证)-》效率高(支持并发)
- 透明性:分布式文件系统应该如同本地文件系统
- 访问透明性: 客户无需了解文件分布性,通过一组文件操作访问本地/远程文件
- 位置透明性: 客户使用单一的文件命名空间。路径不变,多个文件应该可重定位
- 移动透明性: 当文件移动时,客户的系统管理表不必修改
- 性能透明性: 负载在一个特定范围内变化时,性能可接受
- 伸缩透明性: 文件服务可扩充,以满足负载和网络规模增长的需要
- 并发文件更新
- 对共享资源并发控制
- 文件复制
- 一个文件可以表示为内容在不同位置的多个拷贝
- 更好的性能和系统容错
- 硬件和操作系统的异构型
- 接口定义明确,在不同操作系统和计算机上实现同样服务
- 容错
- 故障出现服务继续使用
- 为了处理瞬时通信故障,设计可以基于最多一次的调用语义
- 幂等操作,重复请求不会无效更新
- 无状态服务器,崩溃后无恢复重启
- 一致性
- 单个拷贝更新语义,并发访问只看到一个文件存在
- 安全性
- 请求认证,访问控制基于正确的用户身份
- 效率
- 至少和传统文件系统一致
2.文件服务体系结构(即三个组件)作用、接口、设计理念
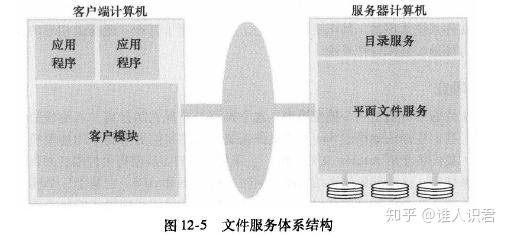
1)文件系统三个组件(文件、文件信息、传送)
2)平面文件服务接口

-
和 Unix 文件系统比较
-
- 没有 open 和 close 操作。引用合适的UFID可以立即访问文件
- read 和 write 操作需要一个开始位置
-
与 unix 文件系统相比在容错方面的影响

3)目录服务接口
- (增(addname)删(unname)改(无)查(Lookup,getNames))(只返回异常或名字(UFID))
3.NFS 体系结构、服务器操作、缓存机制(SUN网络文件系统)
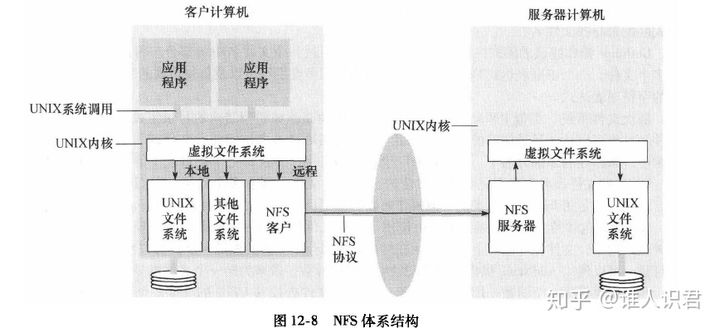
-
虚拟文件系统 VFS
- 在UNIX内核的一个转换层,使文件系统可以插入和共存
-
-
提供访问透明
-
- 将 vfs 加入 unix 内核,用于跟踪和区分本地或远程文件,区分 unix 文件系统或其它文件系统
-
-
v节点
- 本地文件:引用一个i节点
- 远程文件:引用一个文件句柄
-
文件句柄
- 文件系统标识符
- i节点数(标识和定位文件的数值)
- i节点产生数
- 客户与服务器之间传递文件句柄,但对客户不透明
-
服务器操作

-
路径名翻译
- UNIX文件系统每次使用open 、create或stat系统调用时,一步步地将多部分文件路径名转为i节点引用
- NFS服务器不进行路径名转换,需要由客户以交互方式完成路径名的翻译
-
NFS服务器缓存
-
-
使用服务器的缓存保持最近读取的磁盘块不会引起任何一致性问题
-
写操作,需要保证可以持久化数据,两种操作:
-
- 写透缓存,在给客户发送应答前先将应答写入磁盘
- 写透,但只在close():提交操作,写操作的数据存储在内存缓存中,当系统接收相关文件的 commit 操作时,写入磁盘
-
-
- 相比之下,unix采用预先读和延迟写
-
-
为了减少传输给服务器的请求数量,NFS 客户模块将操作的结果缓存起来
-
保持一致性
-
- 客户轮询服务器来检查他们所用的缓存数据是否是最新的
-
基于时间戳的验证
-
-
缓存中的每个数据块被标上两个时间戳
-
- Tc:缓存条目上一次被验证的时间
- Tm:服务器上一次修改文件块的时间
- T:当前时间
-
有效性条件:(T- Tc < t) 或者 (Tmclient = Tmserver)(服务器获得获得Tmserver值(对服务器应用getattr操作),并与本地Tmclient比较)
-
选择 t 时对一致性和效率进行折衷
-
-
4.AFS 设计理念、缓存机制
-
动机
-
Venus是运行在客户计算机上的用户进程,相当于抽象模型中的客户模块;
Vice是服务器软件的名字,是运行在每个服务器计算机上的用户级UNIX进程
-
应用场景
-
- 客户打开一个远程文件
- 在客户机上存储文件副本
- 客户在本地副本上进行读/写
- 客户关闭文件
- 如果文件被更新,将它刷新至服务器
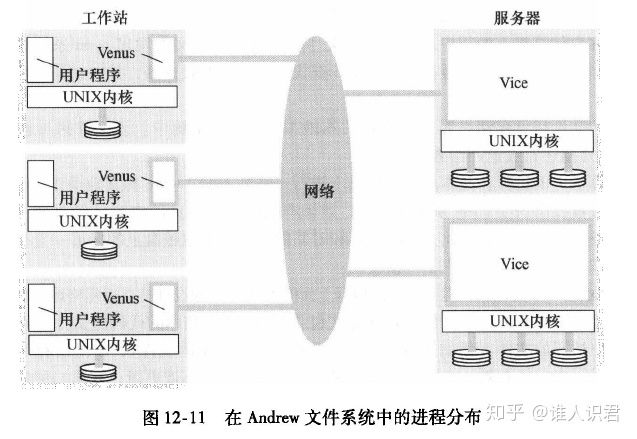
-
缓存一致性
-
-
回调承诺(维护缓存一致)(收到更新,高速所有人别用了)
-
- 由管理该文件的 Vice 服务器发送的一种标识
- 两种状态:有效或取消
- 当服务器执行一个更新文件请求时,它通知所有 Venus 进程将回调承诺标识设为取消状态
-
打开文件
-
- 先检查缓存,文件在缓存中,检查标识
- 如果没有文件或是文件的状态为取消,Venus 从服务器取得文件
-
关闭文件
-
- Venus 刷新文件当应用程序更新文件时
- Vice 顺序执行对文件的更新命令
- Vice 通知所有的文件缓存设为取消状态
-
当客户重启或者在时间 T 内没有收到回调信息 Venus 将认为该文件已经无效
-
可扩展性,由于大部分请求为读请求,与轮询相比,客户与服务器间的交互显著减少,提高了扩展性
-
第八章:谷歌文件系统 GFS
1.GFS 设计动机、设计思想、体系结构、读写添加操作流程
1)设计动机
Google 一直的目标就是构建高性能、高伸缩性的基础组织来支持它们的产品
Google 需要
- 跨数据中心的高可靠性
- 成千上万的网络节点的伸缩性
- 大读写带宽的需求
- 支持大块的数据,可能为上千兆字节
- 高效的跨节点操作分发来减少瓶颈
2)设计思想
-
文件以数据块的形式存储
- 数据块大小固定,每个数据块拥有句柄
-
利用副本技术保证可靠性
- 每个数据块至少在 3 个块服务器上存储副本
- 每个数据块作为本地文件存储在 Linux 文件系统中
-
主服务器维护所有文件系统的元数据
- 每个 GFS 簇只有一个主服务器
- 利用周期性的心跳信息更新服务器
-
缓存
- 无论是客户端还是 Chunk 服务器都不需要缓存文件数据。
- 客户端缓存数据几乎没有什么用处,因为大部分程序要么以流的方式读取一个巨大文件,要么工作集太大根本无法被缓存
- Chunk 以本地文件的方式保存,Linux 操作系统的文件系统缓存会把经常访问的数据缓存在内存中
- 无论是客户端还是 Chunk 服务器都不需要缓存文件数据。
3)基础组件
- Google的云计算应用均依赖于四个基础组件
- GFS,分布式文件存储
- BigTable,结构化数据表
- MapReduce,并行数据处理模型
- Chubby,分布式锁(GFS,BigTable, MapReduce都依赖)
4) 体系结构
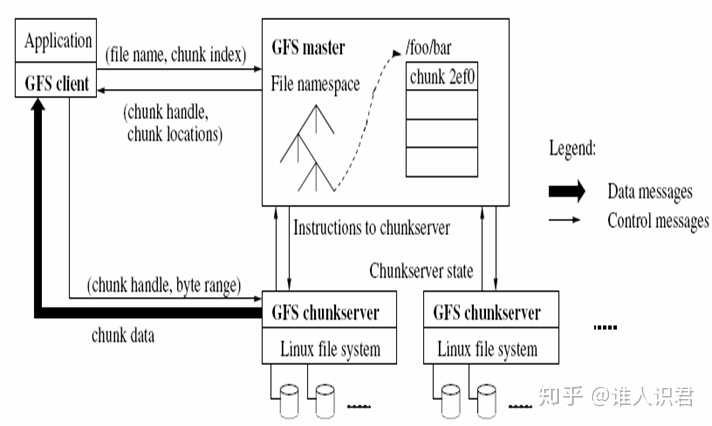
-
客户端
- 以 chunk 偏移量为索引发给主服务器获取 chunk handle 和 chunk 位置,并依次请求 chunkserver 请求文件
-
主服务器
- 存储元数据信息
- 文件命名空间、文件到数据块的映射、数据库的位置信息、访问控制信息
- 存储元数据信息
-
-
优点
- 减少 Master 存储数据规模
- 在客户端缓存 chunk 位置信息,减少网络负载
-
缺点
- 可能出现访问热点
-
-
心跳
- 主服务器通过心跳获取块位置信息
2.Master 不存在性能瓶颈原因
- 磁盘容量:只存储元数据,不存储文件数据
- 磁盘****IO:元数据会存储在磁盘和内存里
- 内存容量:元数据大小内存完全能装得下
- 带宽:所有数据流,数据缓存,都不通过Master
- CPU:元数据可以缓存在Client,每次从Client本地缓存访问元数据,只有元数据不准确的时候,才会访问Master
3.读、写、添加流程
- 读请求
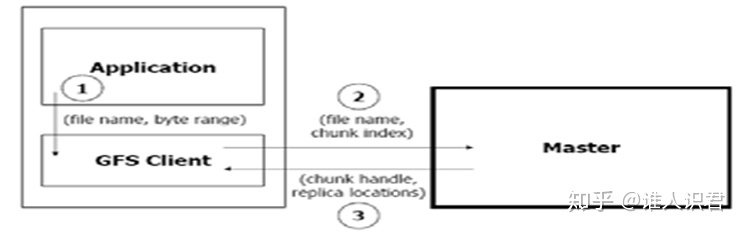
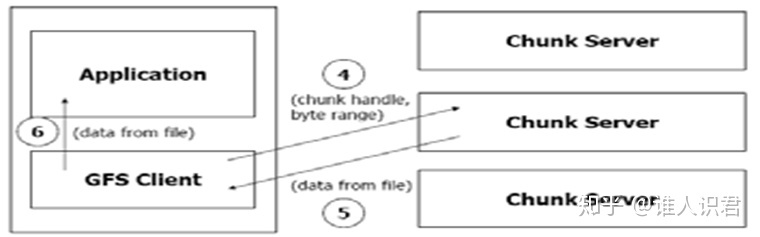
- 应用程序发出读请求
- 客户端将请求转换为(文件名、块位置),发给主服务器
- 主服务器返回数据块的指引信息和副本位置信息
- Client 选择其中一个位置信息,并给那个块服务器发送请求
- 块服务器返回请求的数据
- Client 将数据传送给应用程序
- 写请求
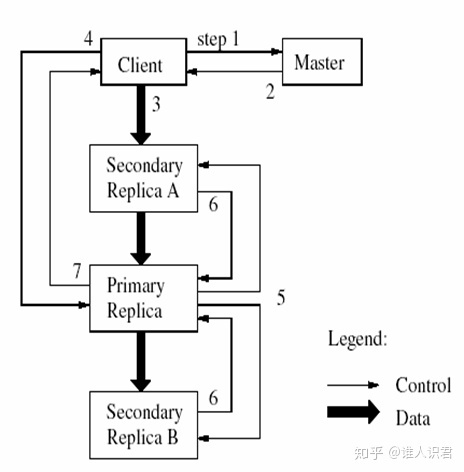
(和图序号不匹配)
1.Client发送请求到Master;
2.Master返回块的句柄和Replica位置信息;
3.Client将写数据推送给所有Replica(可以根据网络拓扑);
4.数据存储在Replica的缓存中;
5.Client发送写命令到Primary;
6.Primary给出写的次序(可能请求来自多个Client);
7.Primary将该次序发送给Secondaries;
8.Secondaries响应Primary;
9.Primary响应Client。
-
追加请求
目的:
- 把多个主机的结果合并到一个文件中。
- 将文件组织成生产者消费者队列。
1.Client将数据推送给所有Replica,然后向Primary发送请求
2.Primary检查Append是否会导致该块超过64MB
- 如果小于64MB,按正常情况处理。
- 如果超过64MB,将该块扩充到最大范围(写0),并要求所有Secondary做同样的操作,同时通知Client该操作需要在下一个块上重新尝试。
4.读写一致确定的含义
- 一致:所有的Client读取相同数据。
- 确定:所有的Client读取有效数据。
- Serial success:当多个Client 串行写时,写入并没有相互干扰,所有Client可以看到明确的写的过程,写的区域是 Defined,也是Consistent
- Concurrent success:Primary决定Client写的顺序。当多个Client并发写多个存在交叉的Chunk时,由于Primary之间并不通信,不同Primary可能选择不同的Client写顺序。如果执行成功,会导致所有Client看到相同的数据 (Consistent),但数据无效 (Undefined)
- Record append:Primary根据决定写入的offset,GFS不保证文件按位相同,只保证至少一次写 (at-least-once semantics),因此副本的同一个块可能包含重复的数据,Append成功的区域数据是Defined,但Append失败重试会导致Inconsistent(也是Undefined)
- 我的理解是遇到并发primary确定个顺序,但系统貌似是可以多个primary的,需要等更多的primary,暂时有个可以用的结果,但不确定最终是这个
第九章:P2P、DHT 及 Chrod
1.P2P基本结构类型
2.一致性hash算法
1)特点
-
平衡性
-
- 平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用
-
单调性(扩展性要好)
-
- 单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。
- 哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区
-
分散性
-
- 在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分
- 由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中
-
负载均衡(避免冲突)
-
- 负载问题实际上是从另一个角度看待分散性问题
- 一个特定的缓冲区,可能被不同的用户映射为不同的内容
2)例子
- 我们采用了一种新的方式来解决问题,处理服务器的选择不再仅仅依赖key的hash本身,而是将服务实例(节点)的配置也进行hash运算。
- 1)首先求出每个服务节点的hash,并将其配置到一个0~232的圆环(continuum)区间上。
- 2)其次使用同样的方法求出所需要存储的key的hash,也将其配置到这个圆环(continuum)上。
- 3)然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务节点上。如果超过232仍然找不到服务节点,就会保存到第一个服务节点上。
- (就是DHT,看看代码就懂了)(emmm下面好像就符合一致性hash描述的要求)
3.corda的原理、DHT分布规则和路由算法
1.基本原理
-
采用环形拓扑(Chord 环)
-
应用接口(增(节点or 内容键值对)删改查)
-
-
Insert(K, V)
-
- 将 <K, V> 对存放到节点ID为 Successor(K) 上
-
Lookup(K)
-
- 根据 K 查询相应的 V
-
Update(K, new_V)
-
- 根据 K 更新相应的 V
-
Join(NID)
-
- 节点加入
-
Leave()
-
- 节点主动退出
-
2.哈希表分布式规则
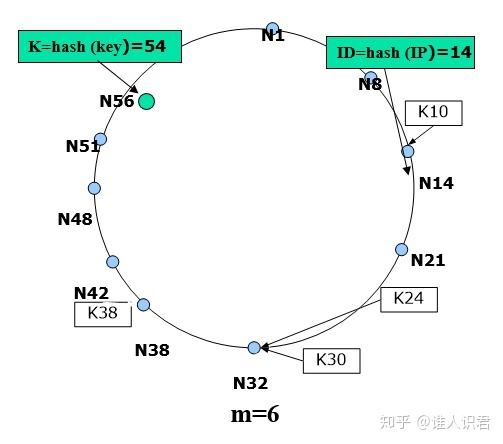
-
Hash 节点 IP 地址->m 位节点 ID(表示为 NID)
-
Hash 内容关键字->m 位K(表示为 KID)
-
节点按 ID 从小到大顺序排列在一个逻辑环上
-
<K, V> 存储在后继节点上
-
- Successor (K):从 K 开始顺时针方向距离 K 最近的节点
Chrod 路由
- 简单查询
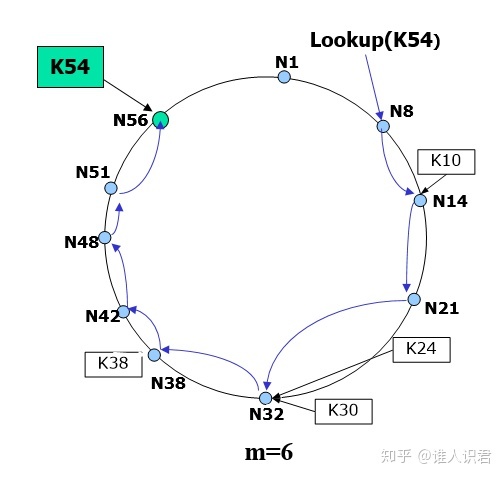
- 每个节点仅维护其后继节点 ID、IP 地址等信息
- 查询消息通过后继节点指针在圆环上传递
- 直到查询消息中包含的 K 落在某节点 ID 和它的后继节点 ID 之间
- 速度太慢 O(N),N 为网络中节点数
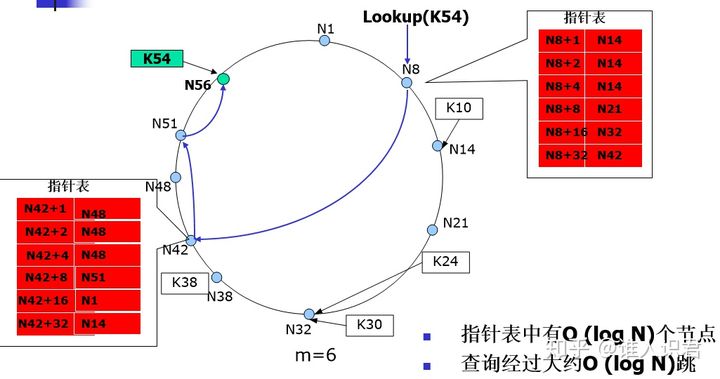
- 基于查找表的查找

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)