Part5-1-2 Nodejs 核心模块
path用于处理 文件/目录 的路径path 模块常用API.basename() 获取路径中基础名称.dirname() 获取路径中目录名称.extname() 获取路径中扩展名称.isAbsolute() 获取路径是否为绝对路径.join() 拼接多个路径片段.resolve() 返回绝对路径.pasre() 解析路径.format() 序列化路径.normalize() 规范化路径const
path
用于处理 文件/目录 的路径
path 模块常用API
.basename() 获取路径中基础名称
.dirname() 获取路径中目录名称
.extname() 获取路径中扩展名称
.isAbsolute() 获取路径是否为绝对路径
.join() 拼接多个路径片段
.resolve() 返回绝对路径
.pasre() 解析路径
.format() 序列化路径
.normalize() 规范化路径
const path = require('path')
console.log(__filename) // 输出的完整路径
// D:\s\lagou\5\1\5-1-课程资料\Code\02Path\01-path.js
// 1 获取路径中的基础名称
/**
* 01 返回的就是接收路径当中的最后一部分
* 02 第二个参数表示扩展名,如果说没有设置则返回完整的文件名称带后缀
* 03 第二个参数做为后缀时,如果没有在当前路径中被匹配到,那么就会忽略
* 04 处理目录路径的时候如果说,结尾处有路径分割符,则也会被忽略掉
*/
console.log(path.basename(__filename))
// 01-path.js
console.log(path.basename(__filename, '.js'))
// 01-path
console.log(path.basename(__filename, '.css'))
// 01-path.js
console.log(path.basename('/a/b/c'))
// c
console.log(path.basename('/a/b/c/'))
// c
// 2 获取路径目录名 (路径)
/**
* 01 返回路径中最后一个部分的上一层目录所在路径
*/
console.log(path.dirname(__filename))
// D:\s\lagou\5\1\5-1-课程资料\Code\02Path
console.log(path.dirname('/a/b/c'))
// /a/b
console.log(path.dirname('/a/b/c/'))
// /a/b
// 3 获取路径的扩展名
/**
* 01 返回 path路径中相应文件的后缀名
* 02 如果 path 路径当中存在多个点,它匹配的是最后一个点,到结尾的内容
*/
console.log(path.extname(__filename))
// .js
console.log(path.extname('/a/b'))
// 输出空字符串
console.log(path.extname('/a/b/index.html.js.css'))
// .css
console.log(path.extname('/a/b/index.html.js.'))
// .
// 4 解析路径
/**
* 01 接收一个路径,返回一个对象,包含不同的信息
* 02 root dir base ext name
*/
const obj = path.parse('/a/b/c/index.html')
console.log(obj.name)
/*
{
root: '/',
dir: '/a/b/c',
base: 'index.html',
ext: '.html',
name: 'index'
}
*/
const obj1 = path.parse('/a/b/c/')
console.log(obj1.name)
/*
{
root: '/',
dir: '/a/b',
base: 'c',
ext: '',
name: 'c'
}
*/
const obj2 = path.parse('./a/b/c/')
console.log(obj2.name)
/*
{
root: '',
dir: './a/b',
base: 'c',
ext: '',
name: 'c'
}
*/
// 5 序列化路径
const obj = path.parse('./a/b/c/')
console.log(path.format(obj))
// ./a/b\c
// 6 判断当前路径是否为绝对路径
console.log(path.isAbsolute('foo')) // false
console.log(path.isAbsolute('/foo')) // true
console.log(path.isAbsolute('///foo')) // true
console.log(path.isAbsolute('')) // false
console.log(path.isAbsolute('.')) // false
console.log(path.isAbsolute('../bar')) // false
console.log(path.isAbsolute('/')) // true
console.log(path.isAbsolute('./')) // false
// 7 拼接路径
console.log(path.join('a/b', 'c', 'index.html'))
// a\b\c\index.html
console.log(path.join('/a/b', 'c', 'index.html'))
// \a\b\c\index.html
console.log(path.join('/a/b', 'c', '../', 'index.html'))
// \a\b\index.html
console.log(path.join('/a/b', 'c', './', 'index.html'))
// \a\b\c\index.html
console.log(path.join('/a/b', 'c', '', 'index.html'))
// \a\b\c\index.html
console.log(path.join(''))
// .
// 8 规范化路径
console.log(path.normalize('')) // .
console.log(path.normalize('a/b/c/d')) // a\b\c\d
console.log(path.normalize('a///b/c../d')) // a\b\c..\d
console.log(path.normalize('a//\\/b/c\\/d')) // a\b\c\d
console.log(path.normalize('a//\b/c\\/d')) // a\c\d
// 9 绝对路径
console.log(path.resolve())
// D:\s\lagou\5\1\5-1-课程资料\Code\02Path
console.log(path.resolve('a', 'b'))
// D:\s\lagou\5\1\5-1-课程资料\Code\02Path\a\b
console.log(path.resolve('a', '/b'))
// D:\b
console.log(path.resolve('/a', '/b'))
// D:\b
console.log(path.resolve('/a', 'b'))
// D:\a\b
console.log(path.resolve('/a', '../b'))
// D:\b
console.log(path.resolve('index.html'))
// D:\s\lagou\5\1\5-1-课程资料\Code\02Path\index.html
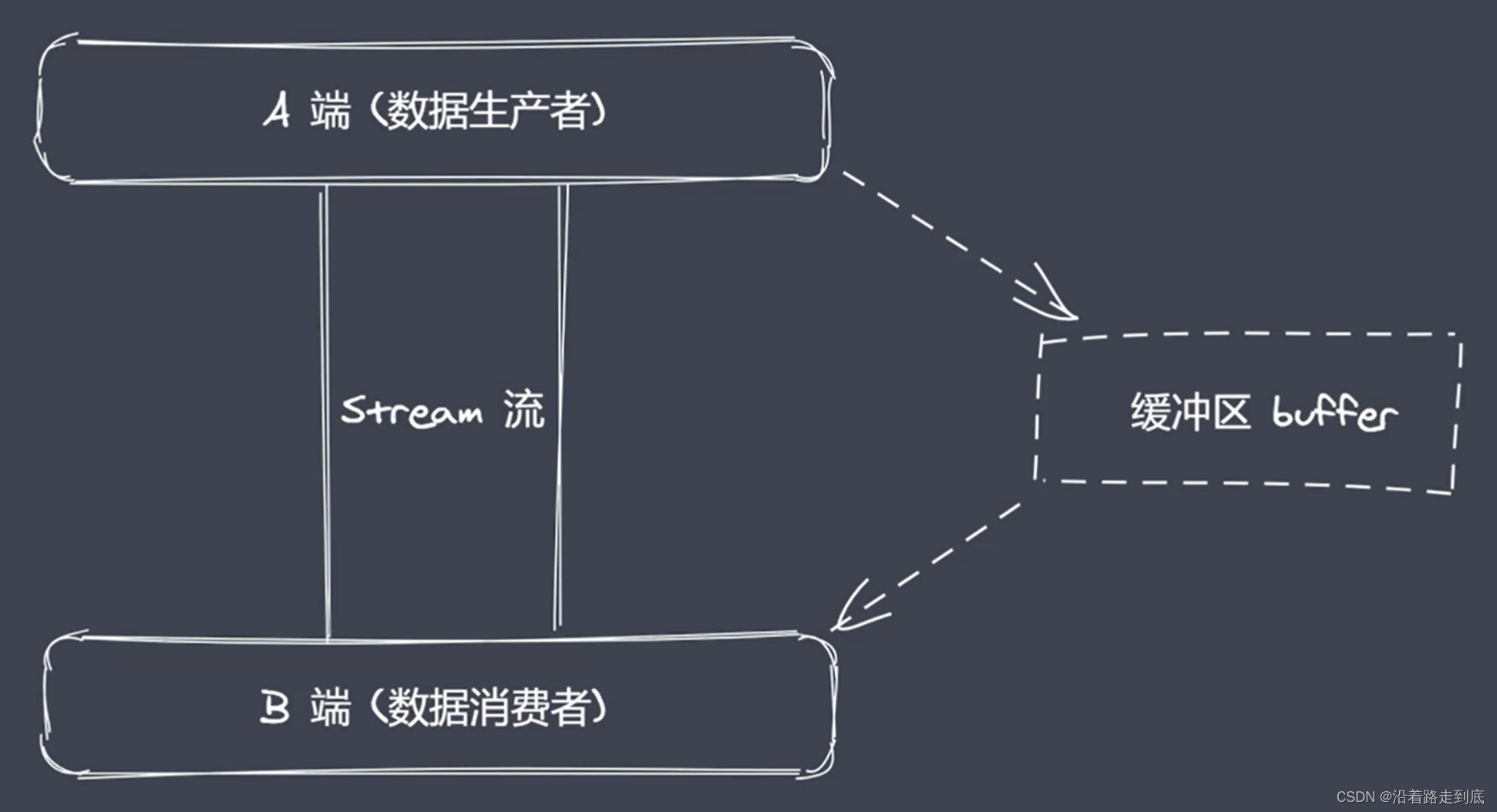
Buffer 缓冲区
Buffer 让 JavaScript 可以操作二进制
Buffer是什么?在哪?做什么?
二进制数据、流操作、Buffer
NodeJs 平台下 JavaScript 可实现 IO
IO 行为操作的就是二进制数据
Stream 流操作并非 NodeJs 独创
流操作配合管道实现数据分段传输
数据的端到端传输会有生产者和消费者
产生等待时数据存放在哪?Buffer
NodeJs 中 Buffer 是一片内存空间
Buffer总结:
无需require的一个全局变量
实现Nodejs 平台下的二进制数据操作
不占据V8堆内存大小的内存空间
内存的使用由Node来控制,由V8的GC回收
一般配合Stream流使用,充当数据缓冲区
创建Buffer
alloc:创建指定字节大小的 buffer
allocUnsafe:创建指定大小的 buffer (不安全)
from:接收数据,创建 buffer
const b1 = Buffer.alloc(10)
const b2 = Buffer.allocUnsafe(10)
const b3 = Buffer.from('中') // 会转成16进制
console.log(b1) // <Buffer 00 00 00 00 00 00 00 00 00 00>
console.log(b2) // <Buffer 25 10 7c b3 45 02 00 00 f0 62>
console.log(b3) // <Buffer e4 b8 ad></Buffer>
console.log(b3.toString()) // 中 默认utf-8编码
const b4 = Buffer.from([0xe4, 0xb8, 0xad])
const b5 = Buffer.from([0x60, 0b1001, 12])
console.log(b4) // <Buffer e4 b8 ad>
console.log(b5) // <Buffer 60 09 0c>
const b6 = Buffer.alloc(3)
const b7 = Buffer.from(b6) // b7 和 b6 是两个独立的内存空间,修改不会影响对方
console.log(b6) // <Buffer 00 00 00>
console.log(b7) // <Buffer 00 00 00>
b6[0] = 1
console.log(b6) // <Buffer 01 00 00>
console.log(b7) // <Buffer 00 00 00>Buffer 实例方法
fill:使用数据填充 buffer
write:向 buffer 中写入数据
toString:从 buffer 中提取数据
slice:截取 buffer
indexOf:在 buffer 中查找数据
copy:拷贝 buffer 中的数据
let buf = Buffer.alloc(6)
// fill
buf.fill('123')
console.log(buf) // <Buffer 31 32 33 31 32 33>
console.log(buf.toString()) // 123123
buf.fill('123456789') // 超过容器大小会截断
console.log(buf) // <Buffer 31 32 33 34 35 36>
console.log(buf.toString()) // 123456
buf.fill('123', 1, 3) // 第2,3个参数表示写入的初始位置和结束位置
console.log(buf) // <Buffer 00 31 32 00 00 00>
console.log(buf.toString()) // 12
buf.fill(123) // 转成对应的utf-8编码对应的字符
console.log(buf) // <Buffer 7b 7b 7b 7b 7b 7b>
console.log(buf.toString()) // {{{{{{
// write
buf.write('123')
console.log(buf) // <Buffer 31 32 33 00 00 00>
console.log(buf.toString()) // 123
buf.write('123', 1, 3) // 第2,3个参数表示写入的初始位置和结束位置
console.log(buf) // <Buffer 00 31 32 33 00 00>
console.log(buf.toString()) // 123
// toString
buf = Buffer.from('前端') // 一个中文占用3个字节
console.log(buf) // <Buffer e5 89 8d e7 ab af>
console.log(buf.toString()) // 前端
console.log(buf.toString('utf-8', 3, 9)) // 端 第一个参数指定编码,默认utf-8,第2,3个参数表示截取的初始位置和结束位置
// slice
buf = Buffer.from('前端工程')
let b1 = buf.slice() // 默认从头截到尾
console.log(b1) // <Buffer e5 89 8d e7 ab af e5 b7 a5 e7 a8 8b>
console.log(b1.toString()) // 前端工程
b1 = buf.slice(3, 9)
console.log(b1) // <Buffer e7 ab af e5 b7 a5>
console.log(b1.toString()) // 端工
b1 = buf.slice(-3) // 负数表示从后向前截取多少位
console.log(b1) // <Buffer e7 a8 8b>
console.log(b1.toString()) // 程
// indexOf
buf = Buffer.from('zce爱前端,爱大家,我爱所有')
console.log(buf) // <Buffer 7a 63 65 e7 88 b1 e5 89 8d e7 ab af ef bc 8c e7 88 b1 e5 a4 a7 e5 ae b6 ef bc 8c e6 88 91 e7 88 b1 e6 89 80 e6 9c 89>
console.log(buf.indexOf('爱')) // 3
console.log(buf.indexOf('爱q')) // -1
console.log(buf.indexOf('爱', 4)) // 15 中文占3个字节
// copy
let b1 = Buffer.alloc(6)
let b2 = Buffer.from('前端')
b2.copy(b1) // 将 b2 的数据拷贝进 b1
console.log(b1.toString()) // 前端
console.log(b2.toString()) // 前端
b2.copy(b1, 3, 3, 6) // 第二个参数表示截取多少字符,第3,4个参数表示截取的初始位置和结束位置
console.log(b1.toString()) // 前端
console.log(b2.toString()) // 前端
Buffer 静态方法
concat:将多个buffer拼接成一个新的buffer
isBuffer:判断当前数据是否位 buffer
let b1 = Buffer.from('前端')
let b2 = Buffer.from('工程')
let b = Buffer.concat([b1, b2])
console.log(b) // <Buffer e5 89 8d e7 ab af e5 b7 a5 e7 a8 8b>
console.log(b.toString()) // 前端工程
b = Buffer.concat([b1, b2], 9)
console.log(b) // <Buffer e5 89 8d e7 ab af e5 b7 a5>
console.log(b.toString()) // 前端工
// isBuffer
let b3= '123'
console.log(Buffer.isBuffer(b1)) // true
console.log(Buffer.isBuffer(b3)) // false自定义 Buffer 之 split
ArrayBuffer.prototype.split = function (sep) {
let len = Buffer.from(sep).length
let ret = []
let start = 0
let offset = 0
while( offset = this.indexOf(sep, start) !== -1) {
ret.push(this.slice(start, offset))
start = offset + len
}
ret.push(this.slice(start))
return ret
}
let buf = 'zce吃馒头,吃面条,我吃所有吃'
let bufArr = buf.split('吃')
console.log(bufArr) // [ 'zce', '馒头,', '面条,我', '所有', '' ]FS
提供文件系统操作的API

前置知识:权限位、标识符、文件描述符
权限位:用户对于文件所具备的操作权限(r,w,x)
r: 读权限
w: 写权限
x:执行权限

Nodejs中 flag 表示对文件操作方式
常见 flag 操作符
r: 表示可读
w: 表示可写
s: 表示同步
+: 表示执行相反操作,例如:r+ 表示可读又可写
x: 表示排他操作
a: 表示追加操作
标识符:fd就是操作系统分配给被打开文件的标识
文件操作API
readFile:从指定文件中读取数据
writeFile:向指定文件中写入数据
appendFile:追加的方式向指定文件中写入数据
copyFile:将某个文件中的数据拷贝至另一文件
watchFile:对 指定文件进行监控
const fs = require('fs')
const path = require('path')
// readFile
fs.readFile(path.resolve('data.txt'), 'utf-8', (err, data) => {
console.log(err)
if (!err) {
console.log(data)
}
})
// writeFile 如果文件不存在,会执行创建操作
fs.writeFile('data.txt', '123', {
mode: 438, // 操作权限
flag: 'w+',
encoding: 'utf-8'
}, (err) => {
if (!err) {
fs.readFile('data.txt', 'utf-8', (err, data) => {
console.log(data)
})
}
})
// appendFile
fs.appendFile('data.txt', 'hello node.js',{}, (err) => {
console.log('写入成功')
})
// copyFile
fs.copyFile('data.txt', 'test1.txt', () => {
console.log('拷贝成功')
})
// watchFile
fs.watchFile('data.txt', {interval: 20}, (curr, prev) => {
if (curr.mtime !== prev.mtime) {
console.log('文件被修改了')
fs.unwatchFile('data.txt') // 取消监控
}
})文件操作实现 md 转 html
const fs = require('fs')
const path = require('path')
const marked = require('marked')
const browserSync = require('browser-sync')
/**
* 01 读取 md 和 css 内容
* 02 将上述读取出来的内容替换占位符,生成一个最终需要展的 Html 字符串
* 03 将上述的 Html 字符写入到指定的 Html 文件中
* 04 监听 md 文档内容的变经,然后更新 html 内容
* 05 使用 browser-sync 来实时显示 Html 内容
*/
let mdPath = path.join(__dirname, process.argv[2])
let cssPath = path.resolve('github.css')
let htmlPath = mdPath.replace(path.extname(mdPath), '.html')
fs.watchFile(mdPath, (curr, prev) => {
if (curr.mtime !== prev.mtime) {
fs.readFile(mdPath, 'utf-8', (err, data) => {
// 将 md--》html
let htmlStr = marked(data)
fs.readFile(cssPath, 'utf-8', (err, data) => {
let retHtml = temp.replace('{{content}}', htmlStr).replace('{{style}}', data)
// 将上述的内容写入到指定的 html 文件中,用于在浏览器里进行展示
fs.writeFile(htmlPath, retHtml, (err) => {
console.log('html 生成成功了')
})
})
})
}
})
browserSync.init({
browser: '',
server: __dirname,
watch: true,
index: path.basename(htmlPath)
})
const temp = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
<style>
.markdown-body {
box-sizing: border-box;
min-width: 200px;
max-width: 1000px;
margin: 0 auto;
padding: 45px;
}
@media (max-width: 750px) {
.markdown-body {
padding: 15px;
}
}
{{style}}
</style>
</head>
<body>
<div class="markdown-body">
{{content}}
</div>
</body>
</html>
`文件打开与关闭
const fs = require('fs')
const path = require('path')
// open
fs.open(path.resolve('data.txt'), 'r', (err, fd) => {
console.log(fd)
})
// close
fs.open('data.txt', 'r', (err, fd) => {
console.log(fd)
fs.close(fd, err => {
console.log('关闭成功')
})
})大文件读写操作
const fs = require('fs')
// read : 所谓的读操作就是将数据从磁盘文件中写入到 buffer 中
let buf = Buffer.alloc(10)
/**
* fd 定位当前被打开的文件
* buf 用于表示当前缓冲区
* offset 表示当前从 buf 的哪个位置开始执行写入
* length 表示当前次写入的长度
* position 表示当前从文件的哪个位置开始读取
*/
fs.open('data.txt', 'r', (err, rfd) => {
console.log(rfd)
fs.read(rfd, buf, 1, 4, 3, (err, readBytes, data) => {
console.log(readBytes)
console.log(data)
console.log(data.toString())
})
})
// write 将缓冲区里的内容写入到磁盘文件中
buf = Buffer.from('1234567890')
fs.open('b.txt', 'w', (err, wfd) => {
fs.write(wfd, buf, 2, 4, 0, (err, written, buffer) => {
console.log(written, '----')
fs.close(wfd)
})
})文件拷贝自定义实现
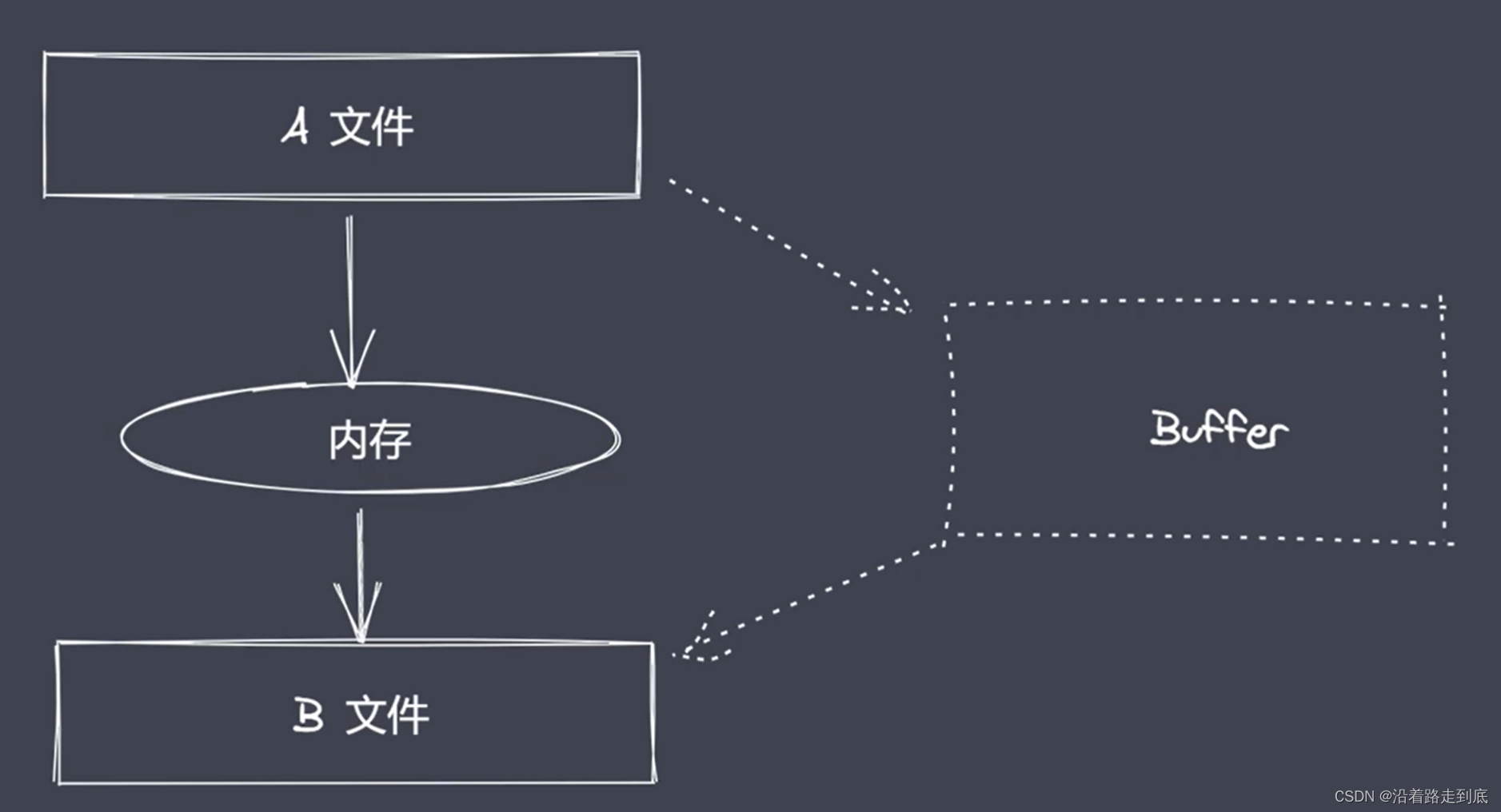
const fs = require('fs')
/**
* 01 打开 a 文件,利用 read 将数据保存到 buffer 暂存起来
* 02 打开 b 文件,利用 write 将 buffer 中数据写入到 b 文件中
*/
let buf = Buffer.alloc(10)
// 01 打开指定的文件
fs.open('a.txt', 'r', (err, rfd) => {
// 03 打开 b 文件,用于执行数据写入操作
fs.open('b.txt', 'w', (err, wfd) => {
// 02 从打开的文件中读取数据
fs.read(rfd, buf, 0, 10, 0, (err, readBytes) => {
// 04 将 buffer 中的数据写入到 b.txt 当中
fs.write(wfd, buf, 0, 10, 0, (err, written) => {
console.log('写入成功')
})
})
})
})
// 02 数据的完全拷贝
fs.open('a.txt', 'r', (err, rfd) => {
fs.open('b.txt', 'a+', (err, wfd) => {
fs.read(rfd, buf, 0, 10, 0, (err, readBytes) => {
fs.write(wfd, buf, 0, 10, 0, (err, written) => {
fs.read(rfd, buf, 0, 5, 10, (err, readBytes) => {
fs.write(wfd, buf, 0, 5, 10, (err, written) => {
console.log('写入成功')
})
})
})
})
})
})
const BUFFER_SIZE = buf.length
let readOffset = 0
fs.open('a.txt', 'r', (err, rfd) => {
fs.open('b.txt', 'w', (err, wfd) => {
function next () {
fs.read(rfd, buf, 0, BUFFER_SIZE, readOffset, (err, readBytes) => {
if (!readBytes) {
// 如果条件成立,说明内容已经读取完毕
fs.close(rfd, ()=> {})
fs.close(wfd, ()=> {})
console.log('拷贝完成')
return
}
readOffset += readBytes
fs.write(wfd, buf, 0, readBytes, (err, written) => {
next()
})
})
}
next()
})
})目录操作API
access:判断文件或目录是否具有操作权限
stat:获取目录及文件信息
mkdir:创建目录
rmdir:删除目录
readdir:读取目录中内容
unlink:删除指定文件
// 一、access
fs.access('a.txt', (err) => {
if (err) {
console.log(err)
} else {
console.log('有操作权限')
}
})
// 二、stat
fs.stat('a.txt', (err, statObj) => {
console.log(statObj)
/*
{
dev: 2785216053,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: 4096,
ino: 2533274790614554,
size: 108,
blocks: 0,
atimeMs: 1648620695844.4788,
mtimeMs: 1605512042441.8066,
ctimeMs: 1646890564919.2437,
birthtimeMs: 1646890564919.2437,
atime: 2022-03-30T06:11:35.844Z,
mtime: 2020-11-16T07:34:02.442Z,
ctime: 2022-03-10T05:36:04.919Z,
birthtime: 2022-03-10T05:36:04.919Z
}
*/
console.log(statObj.size)
console.log(statObj.isFile())
console.log(statObj.isDirectory())
})
// 三、mkdir
// recursive: 父级目录如果不存在,会一起创建
fs.mkdir('a/b/c', {recursive: true}, (err) => {
if (!err) {
console.log('创建成功')
}else{
console.log(err)
}
})
// 四、rmdir
// recursive: 目录下的子目录和文件会一起删除
fs.rmdir('a', {recursive: true}, (err) => {
if (!err) {
console.log('删除成功')
} else {
console.log(err)
}
})
// 五、readdir
fs.readdir('a/b', (err, files) => {
console.log(files) // [ 'b.txt', 'c' ]
})
// 六、unlink
fs.unlink('a/a.txt', (err) => {
if (!err) {
console.log('删除成功')
}
})目录创建之同步实现
const fs = require('fs')
const path = require('path')
/**
* 01 将来调用时需要接收类似于 a/b/c ,这样的路径,它们之间是采用 / 去行连接
* 02 利用 / 分割符将路径进行拆分,将每一项放入一个数组中进行管理 ['a', 'b', 'c']
* 03 对上述的数组进行遍历,我们需要拿到每一项,然后与前一项进行拼接 /
* 04 判断一个当前对拼接之后的路径是否具有可操作的权限,如果有则证明存在,否则的话就需要执行创建
*/
function makeDirSync (dirPath) {
let items = dirPath.split(path.sep)
for(let i = 1; i <= items.length; i++) {
let dir = items.slice(0, i).join(path.sep)
try {
fs.accessSync(dir)
} catch (err) {
fs.mkdirSync(dir)
}
}
}
makeDirSync('a\\b\\c')目录创建之异步实现
const fs = require('fs')
const path = require('path')
const {promisify} = require('util')
function mkDir (dirPath, cb) {
let parts = dirPath.split('/')
let index = 1
function next () {
if (index > parts.length) return cb && cb()
let current = parts.slice(0, index++).join('/')
fs.access(current, (err) => {
if (err) {
fs.mkdir(current, next)
}else{
next()
}
})
}
next()
}
mkDir('a/b/c', () => {
console.log('创建成功')
})
// 将 access 与 mkdir 处理成 async... 风格
const access = promisify(fs.access)
const mkdir = promisify(fs.mkdir)
async function myMkdir (dirPath, cb) {
let parts = dirPath.split('/')
for(let index = 1; index <= parts.length; index++) {
let current = parts.slice(0, index).join('/')
try {
await access(current)
} catch (err) {
await mkdir(current)
}
}
cb && cb()
}
myMkdir('a/b/c', () => {
console.log('创建成功')
})目录删除之异步实现
const { dir } = require('console')
const fs = require('fs')
const path = require('path')
/**
* 需求:自定义一个函数,接收一个路径,然后执行删除
* 01 判断当前传入的路径是否为一个文件,直接删除当前文件即可
* 02 如果当前传入的是一个目录,我们需要继续读取目录中的内容,然后再执行删除操作
* 03 将删除行为定义成一个函数,然后通过递归的方式进行复用
* 04 将当前的名称拼接成在删除时可使用的路径
*/
function myRmdir (dirPath, cb) {
// 判断当前 dirPath 的类型
fs.stat(dirPath, (err, statObj) => {
if (statObj.isDirectory()) {
// 目录---> 继续读取
fs.readdir(dirPath, (err, files) => {
let dirs = files.map(item => {
return path.join(dirPath, item)
})
let index = 0
function next () {
if (index == dirs.length) return fs.rmdir(dirPath, cb)
let current = dirs[index++]
myRmdir(current, next)
}
next()
})
} else {
// 文件---> 直接删除
fs.unlink(dirPath, cb)
}
})
}
myRmdir('tmp', () => {
console.log('删除成功了')
})Nodejs 与 CommonJS
CommonJS 规范定义模块的加载是同步完成
任意一个文件就是一模块,具有独立作用域
使用 require 导入其他模块
将模块 ID 传入 require 实现模板模块定位
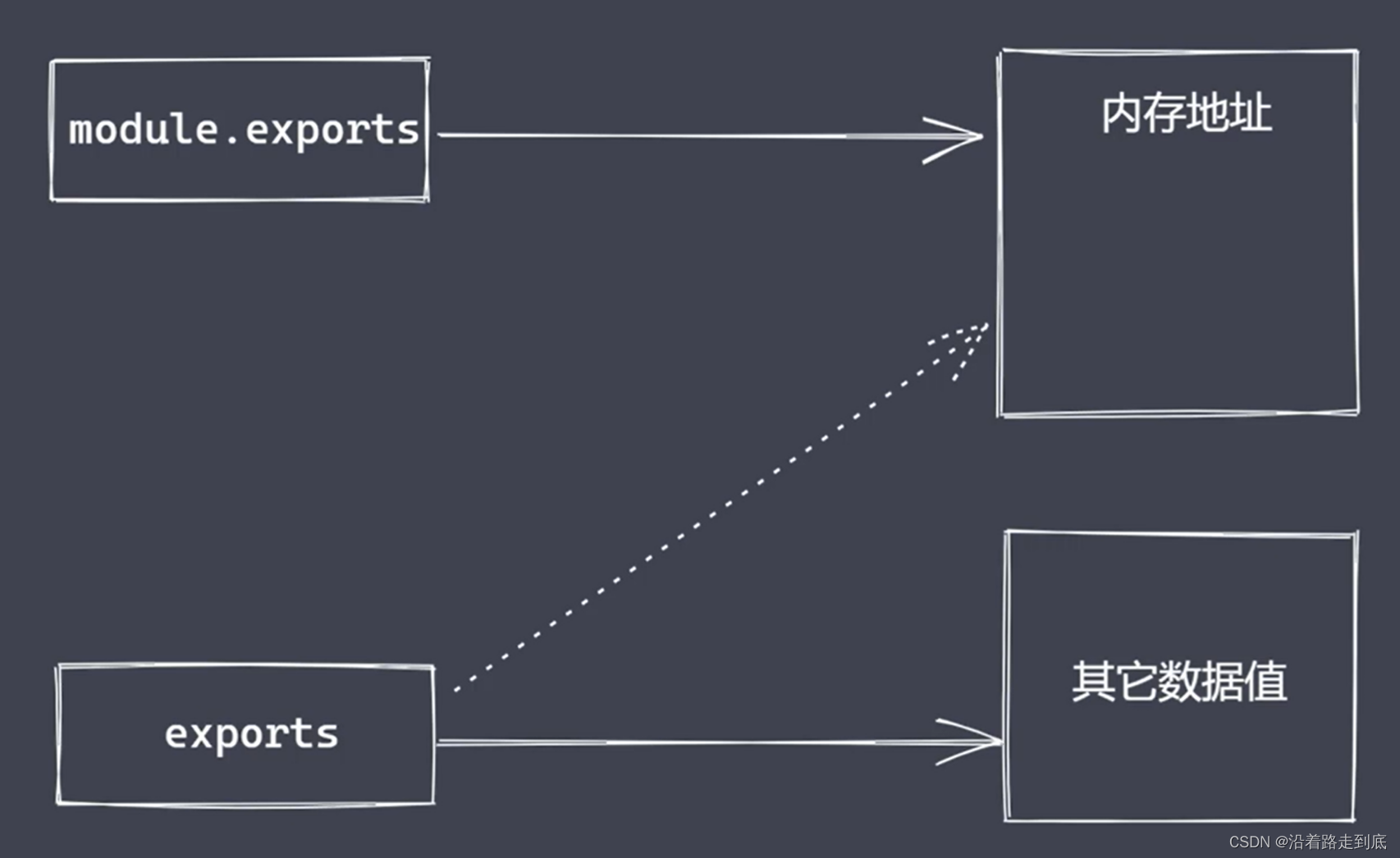
module 属性
任意 js 文件就是一个模块,可以直接使用 module 属性
id:返回模块标识符,一般是一个绝对路径
filename:返回文件模块的绝对路径
loaded:返回布尔值,表示模块是否完成加载
parent:返回对象存放调用当前模块的模块
children: 返回数组,存放当前模块调用的其他模块
exports:返回当前模块需要暴露的内容
paths:返回数组,存放不同目录下的 node_modules 位置
module.exports 与 exports 有何区别?
require 属性
基本功能是读入并且执行一个模块文件
resolve:返回模块文件绝对路径
extensions:依据不同后缀名执行解析操作
main:返回主模块对象
m.js
// 一、模块的导入与导出
const age = 18
const addFn = (x, y) => {
return x + y
}
module.exports = {
age: age,
addFn: addFn
}
// 二、module
module.exports = 1111
console.log(module)
/*
{
id: 'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module\\m.js',
path: 'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module',
exports: 1111,
parent: Module {
id: '.',
path: 'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module',
exports: {},
parent: null,
filename: 'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module\\01-nodejs-commonjs.js',
loaded: false,
children: [ [Circular *1] ],
paths: [
'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module\\node_modules',
'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\node_modules',
'D:\\s\\lagou\\5\\1\\5-1-课程资料\\node_modules',
'D:\\s\\lagou\\5\\1\\node_modules',
'D:\\s\\lagou\\5\\node_modules',
'D:\\s\\lagou\\node_modules',
'D:\\s\\node_modules',
'D:\\node_modules'
]
},
filename: 'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module\\m.js',
loaded: false,
children: [],
paths: [
'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\05Module\\node_modules',
'D:\\s\\lagou\\5\\1\\5-1-课程资料\\Code\\node_modules',
'D:\\s\\lagou\\5\\1\\5-1-课程资料\\node_modules',
'D:\\s\\lagou\\5\\1\\node_modules',
'D:\\s\\lagou\\5\\node_modules',
'D:\\s\\lagou\\node_modules',
'D:\\s\\node_modules',
'D:\\node_modules'
]
}
*/
// 三、exports
exports.name = 'zce'
// 不能直接给 exports 赋值, 否则不会导出内容, 失去了作为导出接口的功能
// exports = {
// name: 'syy',
// age: 18
// }
// 四、同步加载
let name = 'lg'
let iTime = new Date()
while(new Date() -iTime < 4000) {}
module.exports = name
console.log('m.js被加载导入了')
console.log(require.main == module) // false require.main 指向的是 parent, module 指向的是自己
module.exports = 'lg'
nodejs-commonjs.js
// 一、导入
let obj = require('./m')
console.log(obj)
// 二、module
let obj = require('./m')
// 三、exports
let obj = require('./m')
console.log(obj)
// 四、同步加载
let obj = require('./m')
console.log('01.js代码执行了')
let obj = require('./m')
console.log(require.main == module) // true
模块加载速度
核心模块:Node 源码编译时写入到二进制文件中
文件模块:代码运行时,动态加载
加载流程
路径分析:依据标识符确定模块位置
文件定位:确定目标模块中具体的文件及文件类型
编译执行:采用对应的方式完成文件的编译执行
文件定位
项目下存在 m1.js 模块,导入时使用 require('m1') 语法
查找顺序按照:m1.js --> m1.json --> m1.node
如果没有找到,会查找 package.json 文件,使用 JSON.parse() 解析,取出描述文件中的main属性值,
main.js --> main.json --> main.node
如果没有查到,会将 index 作为目标模块中的具体文件名称
如果没有找到,会向上一层层查找 node_modules 目录,
最终没有找到,会抛出查找失败的错误
编译执行
将某个具体类型的文件按照相应的方式进行编译和执行
创建新对象,按路径载入,完成编译执行
JS文件的编译执行
使用 fs 模块同步读入目标文件内容
对内容进行语法包装,生成可执行 JS 函数
调用函数时传入 exports、module、require 等属性值
JSON文件编译执行
将读取到的内容通过 JSON.parse() 进行解析
缓存优化原则
提高模块加载速度
当前模块不存在,则经历一次完整加载流程
模块加载完成后,使用路径作为索引进行缓存
加载流程小结
路径分析:确定目标模块位置
文件定位:确定目标模块中的具体文件
编译执行:对模块内容进行编译,返回可用 exports 对象
vm模块
const fs = require('fs')
const vm = require('vm')
let age = 33
let content = fs.readFileSync('test.txt', 'utf-8')
// eval
// eval(content)
// new Function
/* console.log(age)
let fn = new Function('age', "return age + 1")
console.log(fn(age)) */
vm.runInThisContext("age += 10")
console.log(age)模拟文件模块加载流程实现
核心逻辑:
路径分析
缓存优化
文件定位
编译执行
const { dir } = require('console')
const fs = require('fs')
const path = require('path')
const vm = require('vm')
function Module (id) {
this.id = id
this.exports = {}
console.log(1111)
}
Module._resolveFilename = function (filename) {
// 利用 Path 将 filename 转为绝对路径
let absPath = path.resolve(__dirname, filename)
// 判断当前路径对应的内容是否存在()
if (fs.existsSync(absPath)) {
// 如果条件成立则说明 absPath 对应的内容是存在的
return absPath
} else {
// 文件定位
let suffix = Object.keys(Module._extensions)
for(var i=0; i<suffix.length; i++) {
let newPath = absPath + suffix[i]
if (fs.existsSync(newPath)) {
return newPath
}
}
}
throw new Error(`${filename} is not exists`)
}
Module._extensions = {
'.js'(module) {
// 读取
let content = fs.readFileSync(module.id, 'utf-8')
// 包装
content = Module.wrapper[0] + content + Module.wrapper[1]
// VM
let compileFn = vm.runInThisContext(content)
// 准备参数的值
let exports = module.exports
let dirname = path.dirname(module.id)
let filename = module.id
// 调用
compileFn.call(exports, exports, myRequire, module, filename, dirname)
},
'.json'(module) {
let content = JSON.parse(fs.readFileSync(module.id, 'utf-8'))
module.exports = content
}
}
Module.wrapper = [
"(function (exports, require, module, __filename, __dirname) {",
"})"
]
Module._cache = {}
Module.prototype.load = function () {
let extname = path.extname(this.id)
Module._extensions[extname](this)
}
function myRequire (filename) {
// 1 绝对路径
let mPath = Module._resolveFilename(filename)
// 2 缓存优先
let cacheModule = Module._cache[mPath]
if (cacheModule) return cacheModule.exports
// 3 创建空对象加载目标模块
let module = new Module(mPath)
// 4 缓存已加载过的模块
Module._cache[mPath] = module
// 5 执行加载(编译执行)
module.load()
// 6 返回数据
return module.exports
}
let obj = myRequire('./v')
let obj2 = myRequire('./v')
console.log(obj.age)
事件模块 Events
通过 EventEmitter 类实现事件统一管理
events 与 EventEmitter
node.js 是基于事件驱动的异步操作架构,内置 events 模块
events 模块提供了 EventEmitter 类
node.js 中很多内置核心模块继承 EventEmitter
EventEmitter 常见API
on:添加当事件被触发时调用的回调函数
emit:触发事件,按照注册的顺序同步调用每个事件监听器
once:添加当事件在注册之后首次被触发时调用的回调函数
off:移除特定的监听器
const EventEmitter = require('events')
const ev = new EventEmitter()
// on
ev.on('事件1', () => {
console.log('事件1执行了---2')
})
ev.on('事件1', () => {
console.log('事件1执行了')
})
// emit
ev.emit('事件1')
ev.emit('事件1')
// once
ev.once('事件1', () => {
console.log('事件1执行了')
})
ev.once('事件1', () => {
console.log('事件1执行了--2')
})
ev.emit('事件1')
ev.emit('事件1')
// off
let cbFn = (...args) => {
console.log(args)
}
ev.on('事件1', cbFn)
ev.emit('事件1')
ev.off('事件1', cbFn)
ev.emit('事件1', 1, 2, 3)
ev.on('事件1', function () {
console.log(this)
})
ev.on('事件1', function () {
console.log(2222)
})
ev.on('事件2', function () {
console.log(333)
})
ev.emit('事件1')
const fs = require('fs')
const crt = fs.createReadStream()
crt.on('data')发布订阅模式
定义对象间一对多的依赖关系
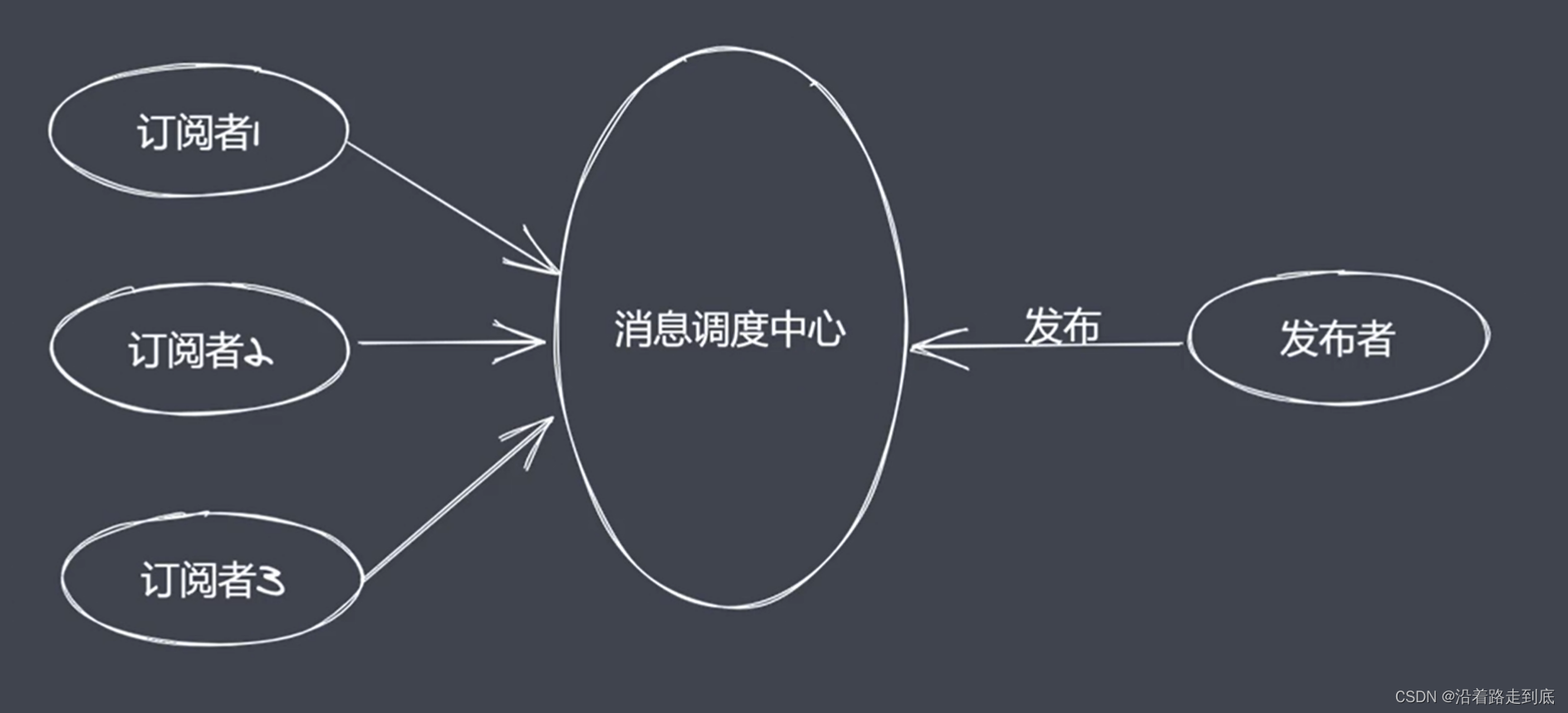
发布订阅要素
缓存队列,存放订阅者信息
具有增加、删除订阅的能力
状态改变时通知所有订阅者执行监听
class PubSub{
constructor() {
this._events = {}
}
// 注册
subscribe(event, callback) {
if (this._events[event]) {
// 如果当前 event 存在,所以我们只需要往后添加当前次监听操作
this._events[event].push(callback)
} else {
// 之前没有订阅过此事件
this._events[event] = [callback]
}
}
// 发布
publish(event, ...args) {
const items = this._events[event]
if (items && items.length) {
items.forEach(function (callback) {
callback.call(this, ...args)
})
}
}
}
let ps = new PubSub()
ps.subscribe('事件1', () => {
console.log('事件1执行了')
})
ps.subscribe('事件1', () => {
console.log('事件1执行了---2')
})
ps.publish('事件1')
ps.publish('事件1')EventEmitter模拟
function MyEvent () {
// 准备一个数据结构用于缓存订阅者信息
this._events = Object.create(null)
}
MyEvent.prototype.on = function (type, callback) {
// 判断当前次的事件是否已经存在,然后再决定如何做缓存
if (this._events[type]) {
this._events[type].push(callback)
} else {
this._events[type] = [callback]
}
}
MyEvent.prototype.emit = function (type, ...args) {
if (this._events && this._events[type].length) {
this._events[type].forEach((callback) => {
callback.call(this, ...args)
})
}
}
MyEvent.prototype.off = function (type, callback) {
// 判断当前 type 事件监听是否存在,如果存在则取消指定的监听
if (this._events && this._events[type]) {
this._events[type] = this._events[type].filter((item) => {
return item !== callback && item.link !== callback
})
}
}
MyEvent.prototype.once = function (type, callback) {
let foo = function (...args) {
callback.call(this, ...args)
this.off(type, foo)
}
foo.link = callback
this.on(type, foo)
}
let ev = new MyEvent()
let fn = function (...data) {
console.log('事件1执行了', data)
}
ev.on('事件1', fn)
ev.on('事件1', () => {
console.log('事件1----2')
})
ev.emit('事件1', 1, 2)
ev.emit('事件1', 1, 2)
ev.on('事件1', fn)
ev.emit('事件1', '前')
ev.off('事件1', fn)
ev.emit('事件1', '后')
ev.once('事件1', fn)
ev.off('事件1', fn)
ev.emit('事件1', '前')浏览器中的事件循环
1
setTimeout(() => {
console.log('s1')
Promise.resolve().then(() => {
console.log('p1')
})
Promise.resolve().then(() => {
console.log('p2')
})
})
setTimeout(() => {
console.log('s2')
Promise.resolve().then(() => {
console.log('p3')
})
Promise.resolve().then(() => {
console.log('p4')
})
})
// s1 p1 p2 s2 p3 p42
setTimeout(() => {
console.log('s1')
Promise.resolve().then(() => {
console.log('p2')
})
Promise.resolve().then(() => {
console.log('p3')
})
})
Promise.resolve().then(() => {
console.log('p1')
setTimeout(() => {
console.log('s2')
})
setTimeout(() => {
console.log('s3')
})
})
// p1 s1 p2 p3 s2 s3完整事件环执行顺序
从上至下执行所有的同步代码
执行过程中将遇到的宏任务与微任务添加至相应的队列
同步代码执行完毕后,执行满足条件的微任务回调
微任务队列执行完毕后执行所有满足需求的宏任务回调
循环事件环操作
注意:每执行一个宏任务之后就会立刻检查微任务队列
NodeJS中的事件循环
有6个任务队列
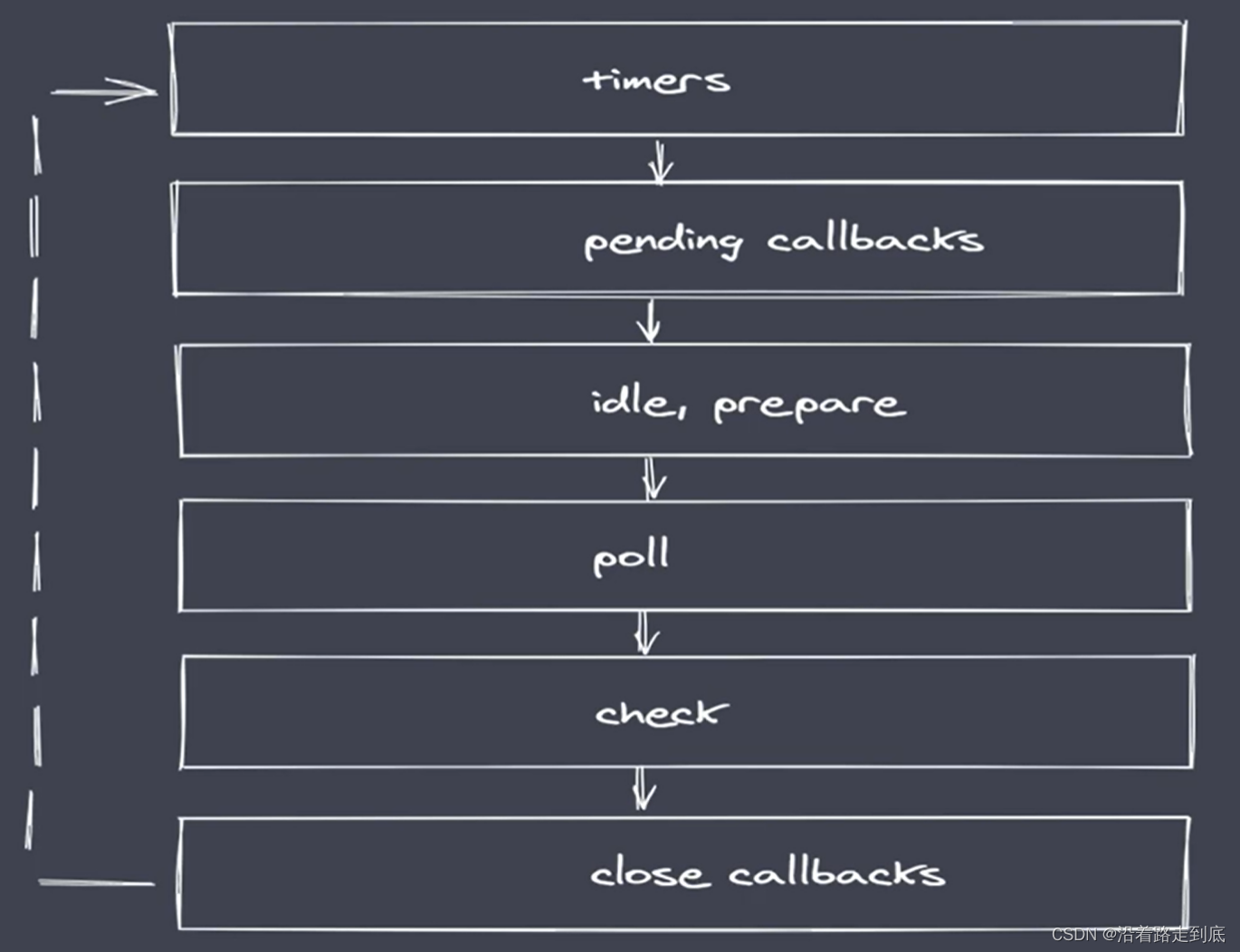
队列说明
timers:执行 setTimeout 与 setInterval 回调
pending callbacks:执行系统操作的回调,例如:tcp、udp
idle、prepare:只在系统内部进行使用
poll:执行与 I/O 相关的回调
check:执行 setImmediate 中的回调
close callbacks:执行 close 事件的回调
NodeJS完整事件环执行顺序
执行同步代码,将不同的任务添加至相应的队列
所有同步代码执行后会去执行满足条件微任务
注意:nextTick 的优先级要高于 promise
所有微任务代码执行后会执行 timer 队列中满足的宏任务
timer 中的所有宏任务执行完成后就会依次切换队列
注意:在完成队列切换之前会先清空微任务代码
setTimeout(() => {
console.log('s1')
})
Promise.resolve().then(() => {
console.log('p1')
})
console.log('start')
process.nextTick(() => {
console.log('tick')
})
setImmediate(() => {
console.log('setimmediate')
})
console.log('end')
// start, end, tick, p1, s1, setimmediate图解:
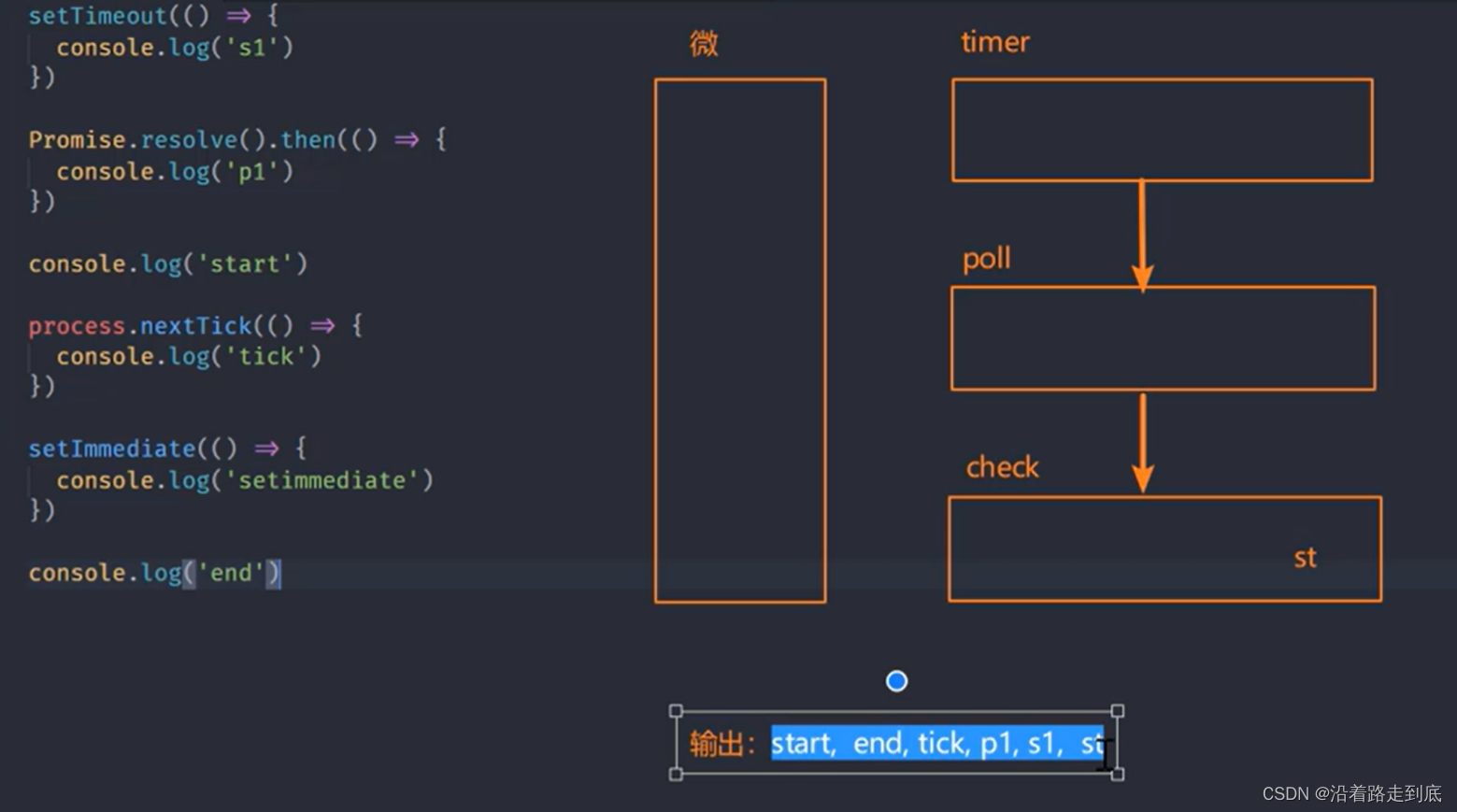
NodeJS事件环梳理
setTimeout(() => {
console.log('s1')
Promise.resolve().then(() => {
console.log('p1')
})
process.nextTick(() => {
console.log('t1')
})
})
Promise.resolve().then(() => {
console.log('p2')
})
console.log('start')
setTimeout(() => {
console.log('s2')
Promise.resolve().then(() => {
console.log('p3')
})
process.nextTick(() => {
console.log('t2')
})
})
console.log('end')
// 旧版nodejs:start, end,p2, s1, s2, t1, t2, p1, p3
// 新版nodejs:start, end, p2, s1, t1, p1, s2, t2, p3Nodejs 与 浏览器事件环区别
任务队列数不同
浏览器中只有二个任务队列
Nodejs 中有6个事件队列
Nodejs 微任务执行时机不同
二者都会在同步代码执行完毕后执行微任务
浏览器平台下每当一个宏任务执行完毕后就清空微任务
Nodejs 平台在事件队列切换时会去清空微任务
微任务优先级不同
浏览器事件环中,微任务存放于事件队列,先进先出
Nodejs 中 process.nextTick 先于 promise.then
Nodejs 事件环常见问题
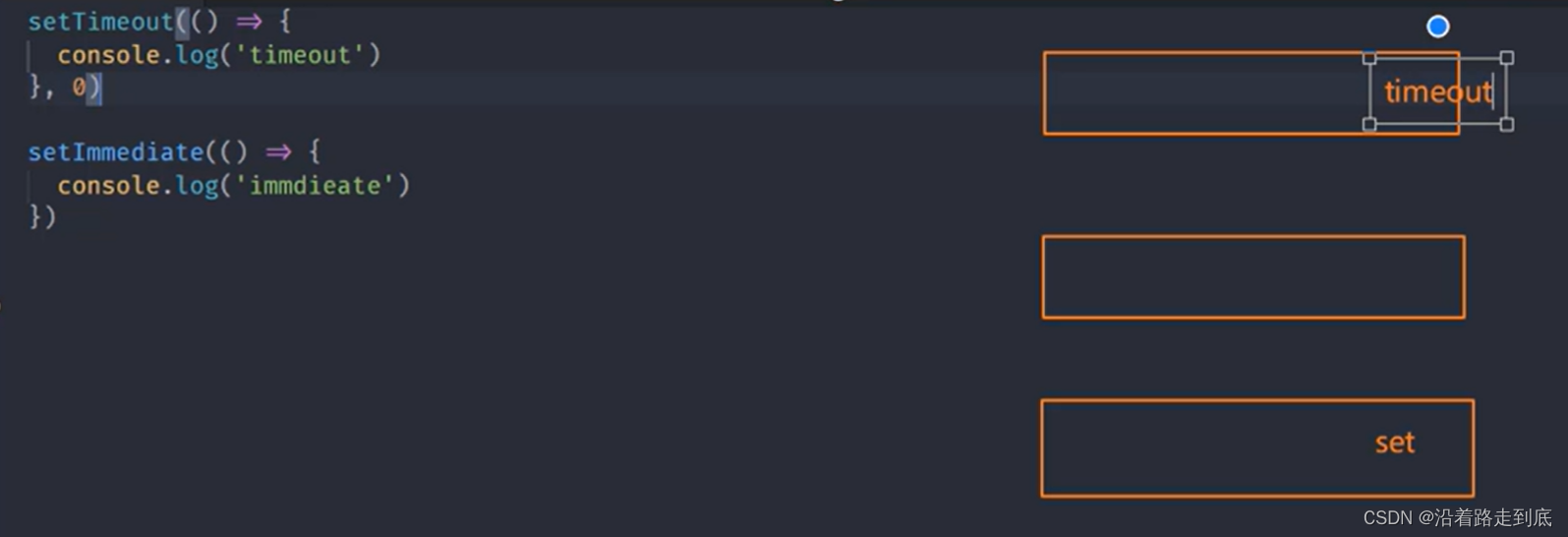
有些时候,setTimeout 会有延时,所以有时会先执行 setImmediate
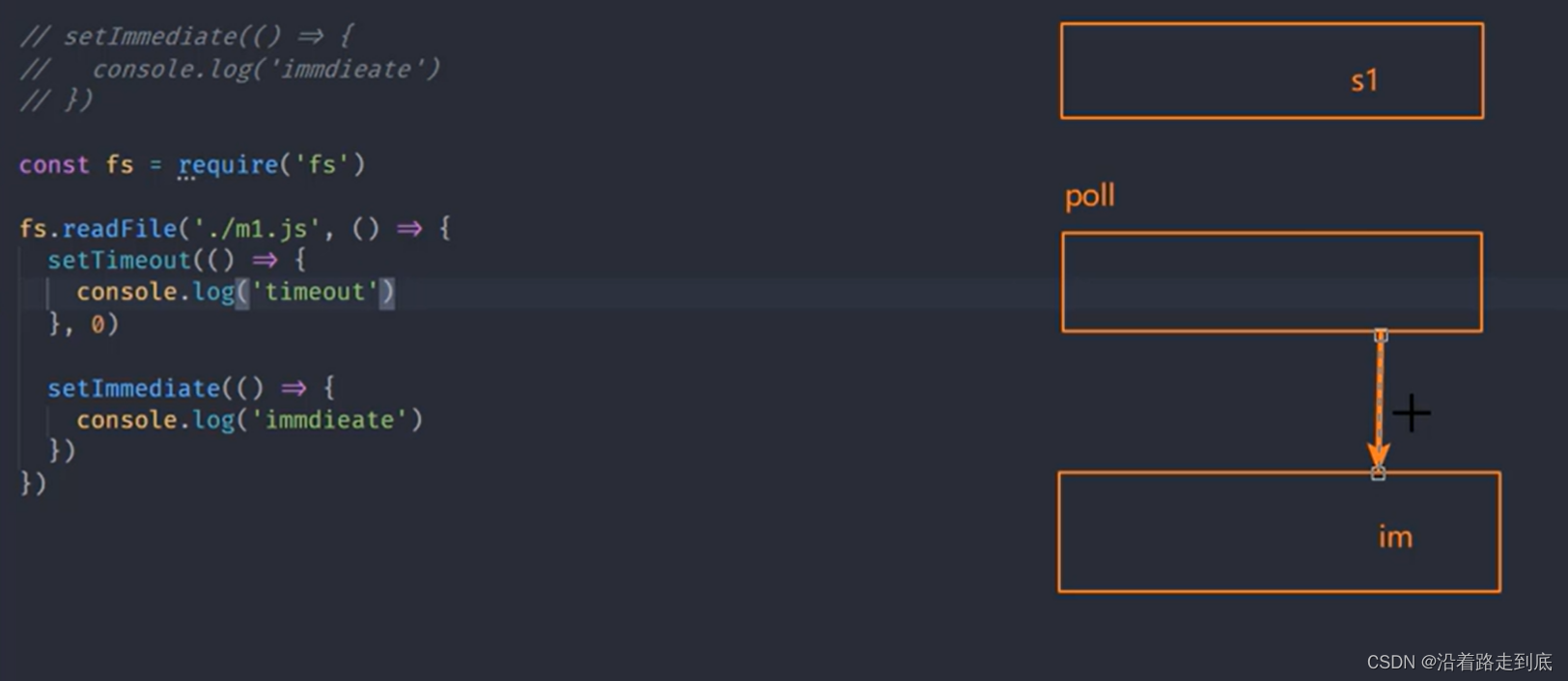
读取文件的回调函数是放在 poll 队列里的,poll队列里的执行完会切换到 check 队列,所以会先执行 setImmediate,再执行 setTimeout
stream
Nodejs 诞生之初就是为了提高 I/O 性能
文件操作系统和网络模块实现了流接口
Node.js中的流就是处理流式数据的抽象接口
应用程序中为什么使用流来处理数据?
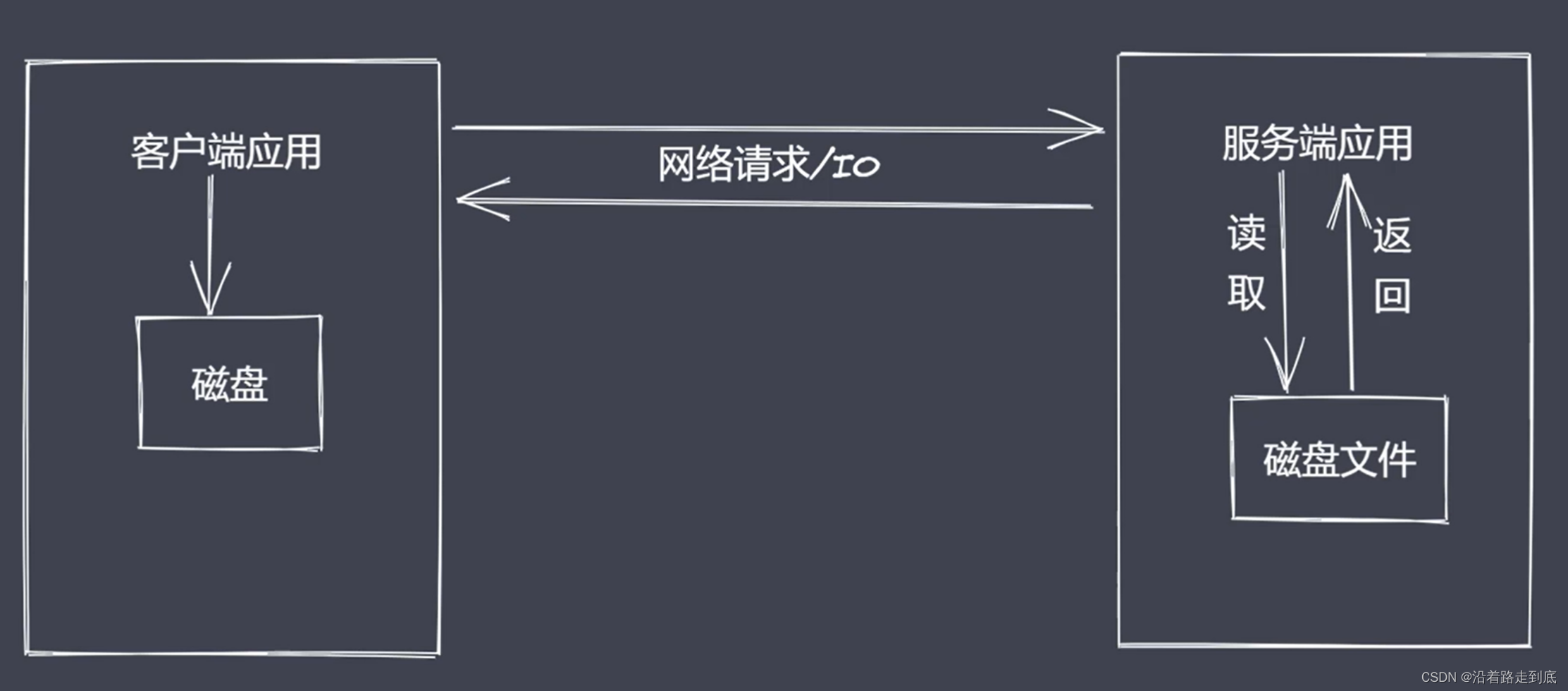
常见问题:
同步读取资源文件,用户需要等待数据读取完成
资源文件最终一次性加载至内存,开销较大
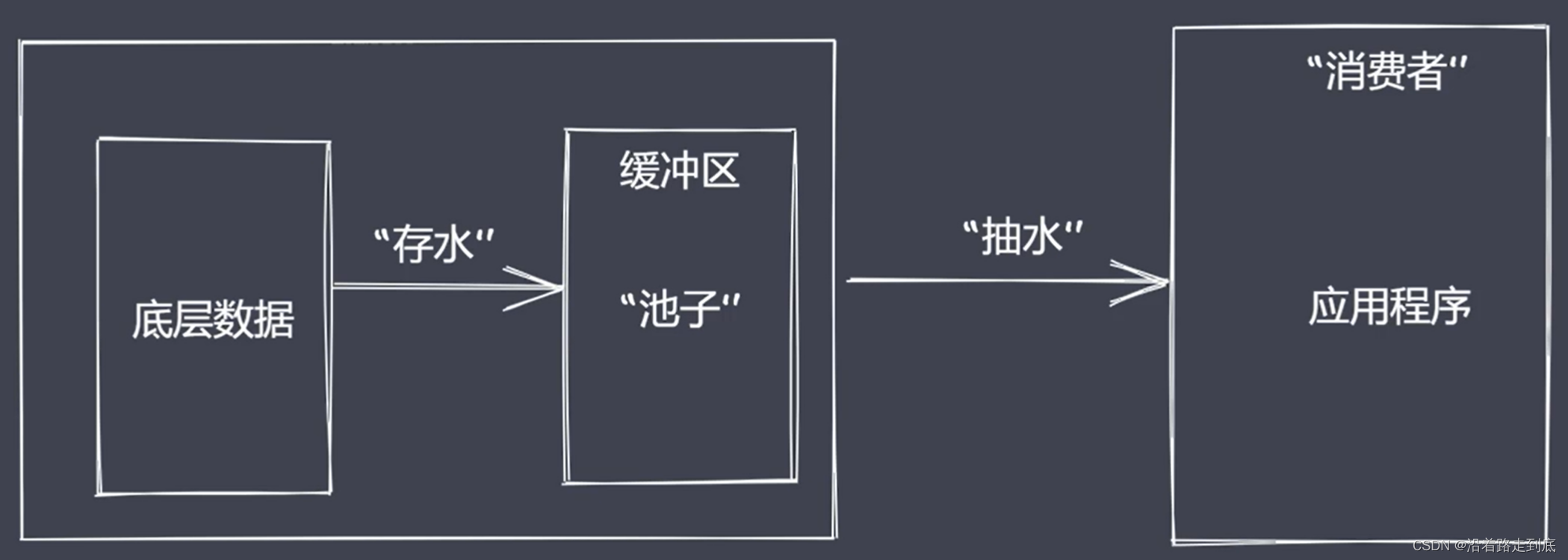
流处理数据的优势
时间效率:流的分段处理可以同时操作多个数据 chunk
空间效率:同一时间流无需占据大内存空间
使用方便:流配合管理,扩展程序变得简单
1

Nodejs 内置了 stream,它实现了流操作对象
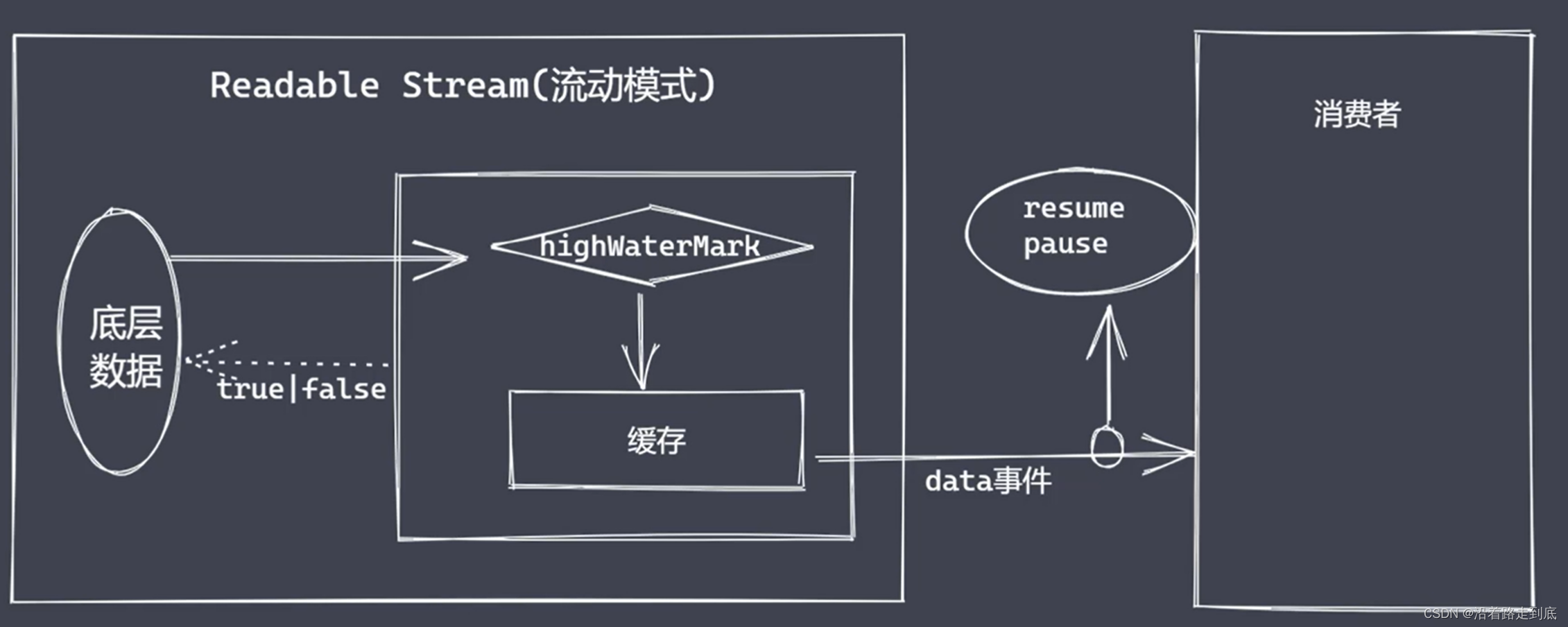
Nodejs中流的分类
Readable:可读流,能够实现数据的读取
Writeable:可写流,能够实现数据的写操作
Duplex:双工流,既可读又可写
Tranform:转换流,可读可写,还能实现数据转换
Nodejs 流特点
Stream 模块实现了四个具体的抽象
所有流都继承自 EventEmitter
const fs = require('fs')
let rs = fs.createReadStream('./test.txt')
let ws = fs.createWriteStream('./test1.txt')
// 通过流操作将 test.txt 里的内容经过管道 复制到 test1.txt 中
rs.pipe(ws)Stream 可读流
生产供程序消费数据的流
const fs = require('fs')
const fs = fs.createReadStream('test.txt')
rs.pipe(process.stdout)自定义可读流
继承 stream 里的 Readable
重写 _read 方法,调用 push 产出数据
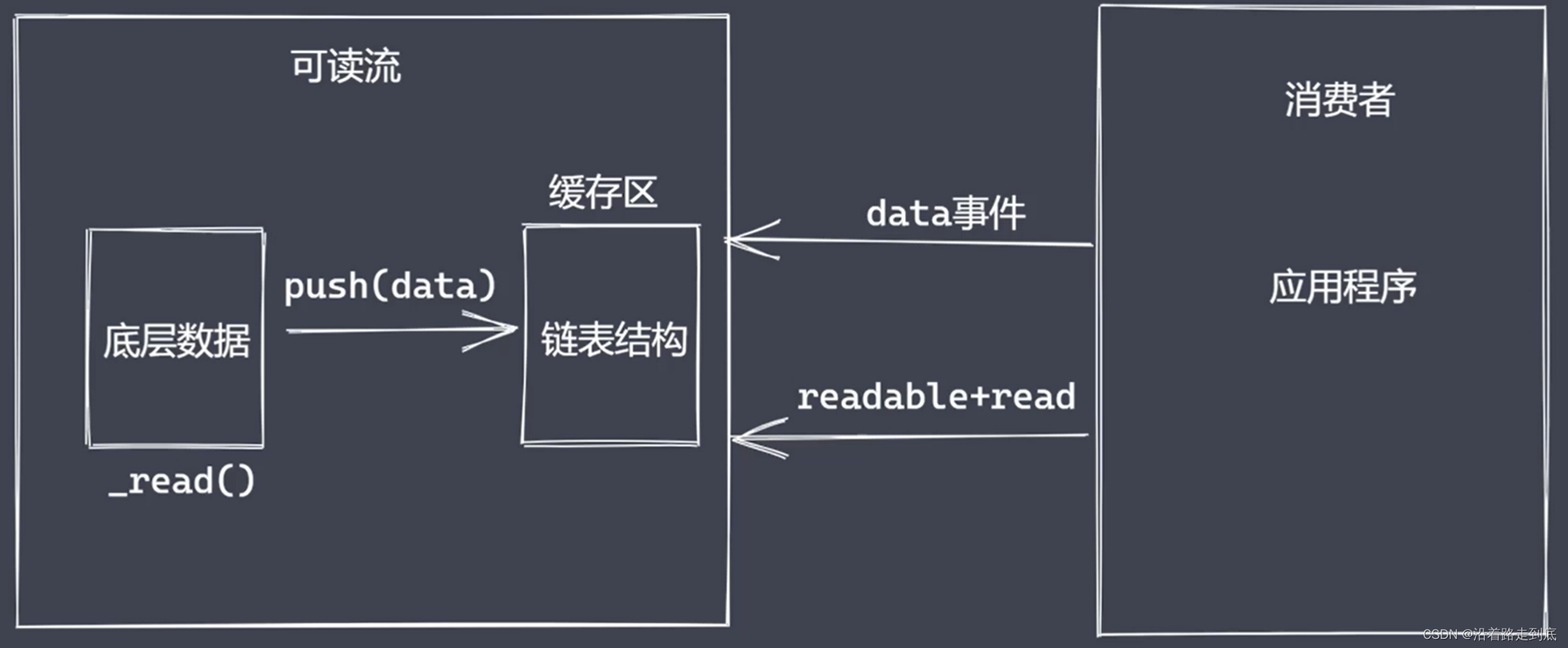
1
const {Readable} = require('stream')
// 模拟底层数据
let source = ['lg', 'zce', 'syy']
// 自定义类继承 Readable
class MyReadable extends Readable{
constructor(source) {
super()
this.source = source
}
_read() {
let data = this.source.shift() || null
this.push(data)
}
}
// 实例化
let myReadable = new MyReadable(source)
// readable事件:当流中存在可读取数据时触发
myReadable.on('readable', () => {
let data = null
while((data = myReadable.read(2)) != null) {
console.log(data.toString())
}
})
// data事件:当流中数据块传给消费者后触发
myReadable.on('data', (chunk) => {
console.log(chunk.toString())
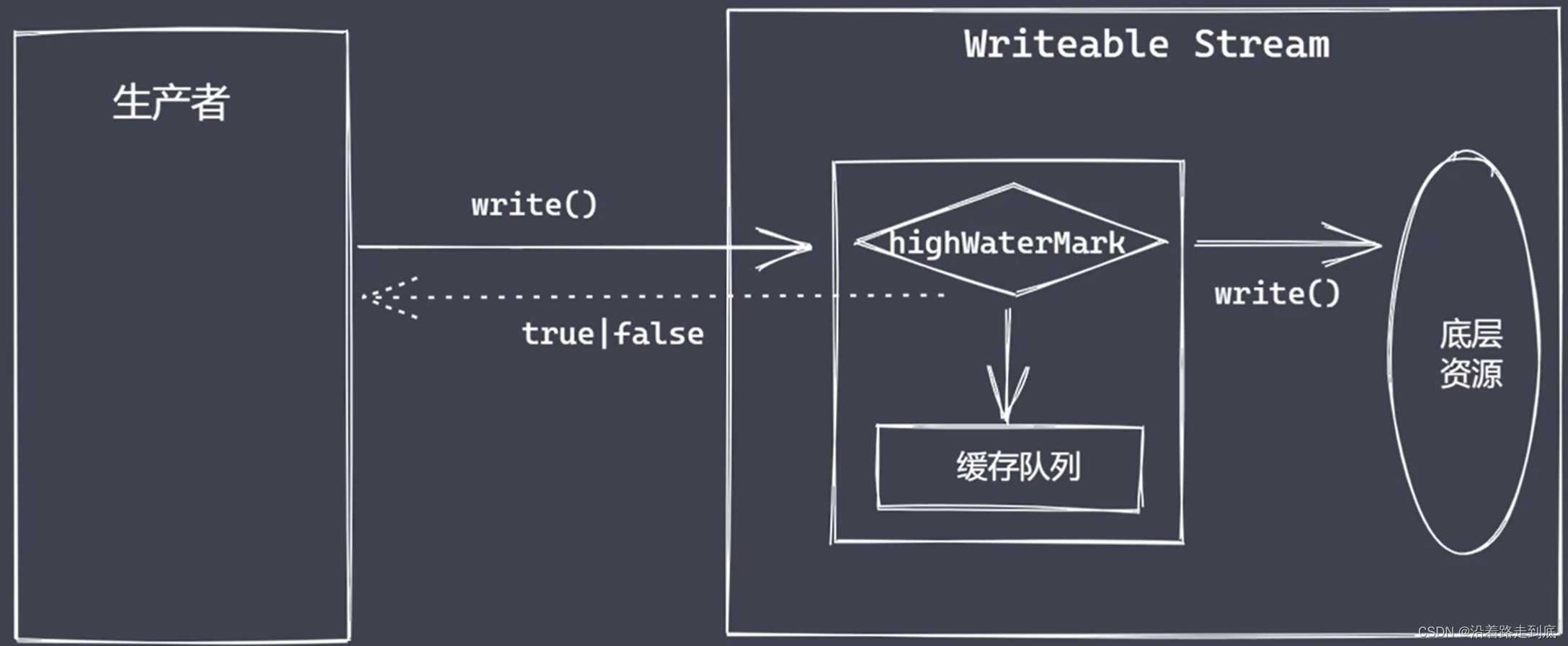
})Stream 可写流
用于消费数据的流
const fs = require('fs')
// 创建一个可读流,生产数据
let rs = fs.createReadStream('test.txt')
// 修改字符编码,便于后续使用
rs.setEncoding('utf-8')
// 创建一个可写流,消费数据
let ws = fs.createWriteStream('test1.txt')
// 监听事件调用方法,完成具体的消费
rs.on('data', (chunk) => {
// 执行数据写入
ws.write(chunk)
}) 自定义可写流
继承 stream 里的 Writeable
重写 _write 方法,调用 write 产出数据
可写流事件
pipe事件:可读流调用 pipe() 方法时触发
unpipe事件:数据切断,可读流调用 unpipe() 方法时触发
const {Writable} = require('stream')
class MyWriteable extends Writable{
constructor() {
super()
}
_write(chunk, en, done) {
process.stdout.write(chunk.toString() + '<----')
process.nextTick(done)
}
}
let myWriteable = new MyWriteable()
myWriteable.write('拉勾教育', 'utf-8', () => {
console.log('end')
})Duplex 双工流
既能生产又能消费
自定义双工流
继承 Duplex 类
重写 _read 方法,调用 push 生产数据
重写 _write 方法,调用 write 消费数据
let {Duplex} = require('stream')
class MyDuplex extends Duplex{
constructor(source) {
super()
this.source = source
}
_read() {
let data = this.source.shift() || null
this.push(data)
}
_write(chunk, en, next) {
process.stdout.write(chunk)
process.nextTick(next)
}
}
let source = ['a', 'b', 'c']
let myDuplex = new MyDuplex(source)
myDuplex.on('data', (chunk) => {
console.log(chunk.toString())
})
myDuplex.write('前端工程', () => {
console.log(1111)
})
Transform 转换流
Transform 也是一个双工流
自定义转换流
继承 Transform 类
重写 _transform 方法,调用 push 和 callback
重写 _flush 方法,处理剩余数据
let {Transform} = require('stream')
class MyTransform extends Transform{
constructor() {
super()
}
_transform(chunk, en, cb) {
this.push(chunk.toString().toUpperCase())
cb(null)
}
}
let t = new MyTransform()
t.write('a')
t.on('data', (chunk) => {
console.log(chunk.toString())
})文件可读流创建和消费、事件与应用
const fs = require('fs')
let rs = fs.createReadStream('test.txt', {
flags: 'r',
encoding: null,
fd: null,
mode: 438,
autoClose: true,
start: 0, // 开始读取的位置
// end: 3, // 结束读取的位置
highWaterMark: 4 // 每次读取多少字节
})
rs.on('data', (chunk) => {
console.log(chunk.toString())
rs.pause() // 暂停读取
setTimeout(() => {
rs.resume() // 继续读取
}, 1000)
})
rs.on('readable', () => {
let data
while((data = rs.read(1)) !== null) {
console.log(data.toString())
console.log('----------', rs._readableState.length)
}
})
rs.on('open', (fd) => {
console.log(fd, '文件打开了')
})
rs.on('close', () => {
console.log('文件关闭了')
})
let bufferArr = []
rs.on('data', (chunk) => {
bufferArr.push(chunk)
})
rs.on('end', () => {
console.log(Buffer.concat(bufferArr).toString())
console.log('当数据被清空之后')
})
rs.on('error', (err) => {
console.log('出错了')
})文件可写流
const fs = require('fs')
const ws = fs.createWriteStream('test.txt', {
flags: 'w',
mode: 438,
fd: null,
encoding: "utf-8",
start: 0,
highWaterMark: 3
})
let buf = Buffer.from('abc')
// 字符串 或者 buffer ===》 fs rs
ws.write(buf, () => {
console.log('ok2')
})
ws.write('拉勾教育', () => {
console.log('ok1')
})
ws.on('open', (fd) => {
console.log('open', fd)
})
ws.write("2")
// close 是在数据写入操作全部完成之后再执行
ws.on('close', () => {
console.log('文件关闭了')
})
// end 执行之后就意味着数据写入操作完成
ws.end('拉勾教育')
// error
ws.on('error', (err) => {
console.log('出错了')
})
write 执行流程
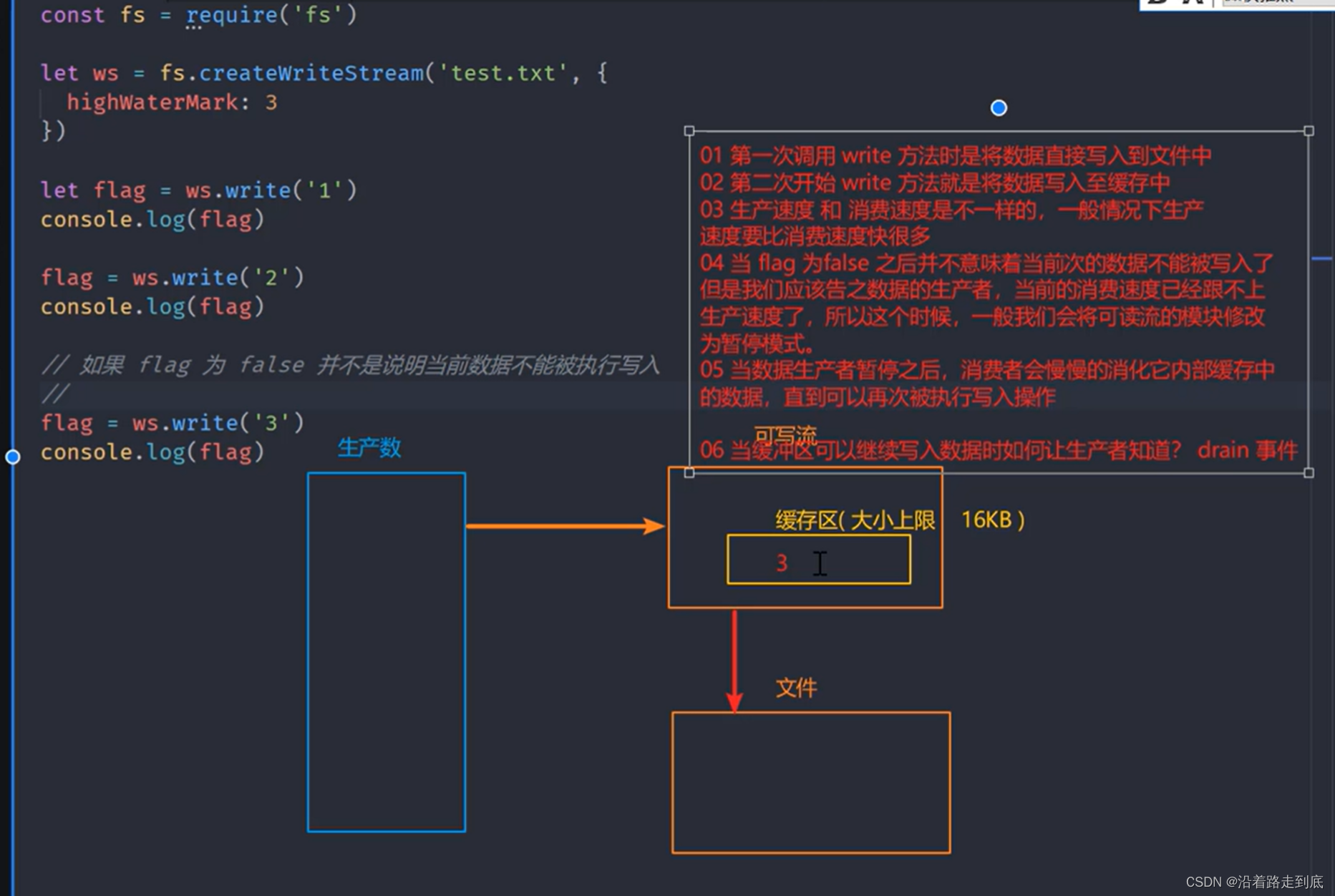
drain 事件控制写入速度
/**
* 需求:“前端工程” 写入指定的文件
* 01 一次性写入
* 02 分批写入
* 对比:
*/
let fs = require('fs')
let ws = fs.createWriteStream('test.txt', {
highWaterMark: 3
})
// ws.write('前端工程')
let source = "前端工程".split('')
let num = 0
let flag = true
function executeWrite () {
flag = true
while(num !== 4 && flag) {
flag = ws.write(source[num])
num++
}
}
executeWrite()
ws.on('drain', () => {
console.log('drain 执行了')
executeWrite()
})
// pipe
背压机制
Node.js 的 stream 已实现了背压机制
let fs = require('fs')
let rs = fs.createReadStream('test.txt')
let ws = fs.createWriteStream('test1.txt')
rs.on('data', (chunk) => {
ws.write(chunk)
})生产速度远远大于消费速度,因此会造成内存溢出、GC频繁调用、其他进程变慢。
基于这种场景,就需要一种可以让数据的生产者与消费者之间平滑流动的机制,这种机制就是背压机制。
1
2
模拟文件可读流
const fs = require('fs')
const EventEmitter = require('events')
class MyFileReadStream extends EventEmitter{
constructor(path, options = {}) {
super()
this.path = path
this.flags = options.flags || "r"
this.mode = options.mode || 438
this.autoClose = options.autoClose || true
this.start = options.start || 0
this.end = options.end
this.highWaterMark = options.highWaterMark || 64 * 1024
this.readOffset = 0
this.open()
this.on('newListener', (type) => {
if (type === 'data') {
this.read()
}
})
}
open() {
// 原生 open 方法来打开指定位置上的文件
fs.open(this.path, this.flags, this.mode, (err, fd) => {
if (err) {
this.emit('error', err)
}
this.fd = fd
this.emit('open', fd)
})
}
read() {
if (typeof this.fd !== 'number') {
return this.once('open', this.read)
}
let buf = Buffer.alloc(this.highWaterMark)
let howMuchToRead
/* if (this.end) {
howMuchToRead = Math.min(this.end - this.readOffset + 1, this.highWaterMark)
} else {
howMuchToRead = this.highWaterMark
} */
howMuchToRead = this.end ? Math.min(this.end - this.readOffset + 1, this.highWaterMark) : this.highWaterMark
fs.read(this.fd, buf, 0, howMuchToRead, this.readOffset, (err, readBytes) => {
if (readBytes) {
this.readOffset += readBytes
this.emit('data', buf.slice(0, readBytes))
this.read()
} else {
this.emit('end')
this.close()
}
})
}
close() {
fs.close(this.fd, () => {
this.emit('close')
})
}
}
let rs = new MyFileReadStream('test.txt', {
end: 7,
highWaterMark: 3
})
rs.on('data', (chunk) => {
console.log(chunk)
})
文件可写流实现
const fs = require('fs')
const EventsEmitter = require('events')
const Queue = require('./linkedlist')
class MyWriteStream extends EventsEmitter{
constructor(path, options={}) {
super()
this.path = path
this.flags = options.flags || 'w'
this.mode = options.mode || 438
this.autoClose = options.autoClose || true
this.start = options.start || 0
this.encoding = options.encoding || 'utf8'
this.highWaterMark = options.highWaterMark || 16*1024
this.open()
this.writeoffset = this.start
this.writing = false
this.writeLen = 0
this.needDrain = false
this.cache = new Queue()
}
open() {
// 原生 fs.open
fs.open(this.path, this.flags, (err, fd) => {
if (err) {
this.emit('error', err)
}
// 正常打开文件
this.fd = fd
this.emit('open', fd)
})
}
write(chunk, encoding, cb) {
chunk = Buffer.isBuffer(chunk) ? chunk : Buffer.from(chunk)
this.writeLen += chunk.length
let flag = this.writeLen < this.highWaterMark
this.needDrain = !flag
if (this.writing) {
// 当前正在执行写入,所以内容应该排队
this.cache.enQueue({chunk, encoding, cb})
} else {
this.writing = true
// 当前不是正在写入那么就执行写入
this._write(chunk, encoding, () => {
cb()
// 清空排队的内容
this._clearBuffer()
})
}
return flag
}
_write(chunk, encoding, cb) {
if (typeof this.fd !== 'number') {
return this.once('open', ()=>{return this._write(chunk, encoding, cb)})
}
fs.write(this.fd, chunk, this.start, chunk.length, this.writeoffset, (err, written) => {
this.writeoffset += written
this.writeLen -= written
cb && cb()
})
}
_clearBuffer() {
let data = this.cache.deQueue()
if (data) {
this._write(data.element.chunk, data.element.encoding, ()=>{
data.element.cb && data.element.cb()
this._clearBuffer()
})
} else {
if (this.needDrain) {
this.needDrain = false
this.emit('drain')
}
}
}
}
const ws = new MyWriteStream('./f9.txt', {})
ws.on('open', (fd) => {
console.log('open---->', fd)
})
let flag = ws.write('1', 'utf8', () => {
console.log('ok1')
})
flag = ws.write('10', 'utf8', () => {
console.log('ok1')
})
flag = ws.write('拉勾教育', 'utf8', () => {
console.log('ok3')
})
ws.on('drain', () => {
console.log('drain')
})pipe 方法实现
const fs = require('fs')
const rs = fs.createReadStream('./f9.txt', {
highWaterMark: 4
})
const ws = fs.createWriteStream('./f10.txt')
rs.pipe(ws)1

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)