Python爬虫攻略(3)>链家网爬虫 Selenium+Requests多线程
申明:本文对爬取的数据仅做学习使用,请勿使用爬取的数据做任何商业活动,侵删这篇文章是对这一篇文章中代码的优化: Python爬虫攻略(2)>Selenium+多线程爬取链家网二手房信息先上代码:更多的信息在代码注释中#!/usr/bin/env python#-*- coding: utf-8 -*-# author: hao 2019/11/9-17:40import j...
·
申明:本文对爬取的数据仅做学习使用,请勿使用爬取的数据做任何商业活动,侵删
本文是对上一篇文章中代码的优化: Python爬虫攻略(2)>Selenium+多线程爬取链家网二手房信息
先上代码:
更多的信息在代码注释中
#!/usr/bin/env python
#-*- coding: utf-8 -*-
# author: hao 2019/11/9-17:40
import json
import time
import requests
from threading import Thread
from datetime import date
from pymongo import MongoClient
from selenium import webdriver
from fake_useragent import UserAgent
from lxml import etree
ua = UserAgent() # 实例化ua, 为后续调用
class LianJia:
def __init__(self):
options = webdriver.ChromeOptions()
# 设置参数, 让driver以无图模式打开, 提升效率
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
# 声明Chrome浏览器对象
self.driver = webdriver.Chrome(r'E:\chromedriver.exe', options=options)
# 声明Mongodb数据库对象
self.coll = MongoClient(host="localhost", port=27017).Spider.LianJia
@staticmethod
def write_json(item):
"""写入json文件"""
json_data = json.dumps(item, ensure_ascii=False)
with open('data.json', 'a', encoding='utf-8') as f:
f.write(json_data + '\n')
print(f">>>[{item['title']}]写入成功")
@staticmethod
def handle_price(price):
"""返回获取价格的时间"""
dc = {
'crawledTime': date.today().strftime("%Y-%m-%d"),
'totalPrice': price
}
return dc
def write_mongo(self, item):
"""写入mongodb数据库"""
self.coll.insert_one(item)
print(f'>>>[{item["title"]}]写入成功')
def house_detail(self, item):
"""获取一间房子的详情信息"""
if self.coll.find_one({'houseURL': item['houseURL']}):
print('已爬取,跳过 ', item['houseURL'])
return
headers = {
'Referer': 'https://wh.lianjia.com/ershoufang/',
'User-Agent': ua.random,
}
try:
time.sleep(1)
resp = requests.get(item['houseURL'], headers=headers) # 访问一间房子的详情页
except Exception as e:
print('>>>>>线程请求详细页面出错 ', item['houseURL'])
print(e)
# 先保存url,之后再用脚本补全信息
self.write_mongo(item)
return
html = etree.HTML(resp.text) # 生成xpath页面对象
# 获取页面上的房子信息
try:
item['title'] = html.xpath('//h1/text()')[0] # 标题
price = html.xpath('//span[@class="total"]/text()')[0] # 价格
first_price = self.handle_price(price) # 第一次的价格
item['totalPrice'] = [first_price] # 房子的价格, 可增量爬取
house_info = html.xpath('//div[@class="mainInfo"]/text()')
item['room'] = house_info[0] # 户型
item['faceTo'] = house_info[1] # 朝向
item['area'] = house_info[2] # 面积
# 小区名
item['communityName'] = html.xpath('//div[@class="communityName"]/a[1]/text()')[0]
# 发布日期
item['releaseDate'] = html.xpath('//div[@class="transaction"]/div[2]/ul/li[1]/span[2]/text()')[0]
except Exception as e:
print(">>>>>字段检索异常", e)
self.write_mongo(item)
def house_list(self, item):
"""获取一个城区中所有房子的详情页链接"""
self.driver.get(item['partURL']) # 访问城区的页面
# 第一次访问时, 获取一下页数
page_number = int(self.driver.find_elements_by_xpath('//div[@class="page-box house-lst-page-box"]/a')[-2].text)
for page in range(1, page_number + 1):
# 获取指定页码页面数据, co32代排序方式为'最新发布'
self.driver.get(item['partURL'] + f'pg{page}co32/')
# 获取到所有的房子链接
house_ls = self.driver.find_elements_by_xpath('//ul[@class="sellListContent"]//div[@class="title"]/a')
# 生成url列表
house_url_ls = [house.get_attribute("href") for house in house_ls]
task_ls = [] # 定义一个任务容器
for url in house_url_ls:
item['houseURL'] = url
# 将获取详情页的任务交给子线程完成, dict(item)表示深拷贝对象
task = Thread(target=self.house_detail, args=(dict(item),))
task.start() # 开始线程中的任务
task_ls.append(task) # 添加到任务容器中
# 为什么不把join放在上面的循环里?
# join的作用是等待项目执行完成, 如果未完成则会一直阻塞, 正因为这样就会导致无法继续下一次循环, 也就无法实现并发的效果
# 所以要放在外面单独执行
for task in task_ls:
# 逐条等待完成
task.join()
print(f'>>[{item["partName"]}]第{page}页--[Done]')
def run(self):
"""获取所有城区的页面链接"""
with open('crawledPart.txt', 'w+') as f:
crawled_part = f.read() or []
print('已经抓取过的区:', crawled_part)
self.driver.get('https://wh.lianjia.com/ershoufang/') # 访问二手房网址
# 获取所有城区的元素对象
temp_ls = self.driver.find_elements_by_xpath('//div[@class="position"]/dl[2]/dd/div[1]/div/a')
part_name_ls = [ele.text for ele in temp_ls] # 城区名 集
part_url_ls = [ele.get_attribute("href") for ele in temp_ls] # 城区链接 集
item = {} # 初始化一个容器, 用来存放房子的信息
for i in range(len(temp_ls)):
if part_name_ls[i] in crawled_part:
print(part_name_ls[i], '-------跳过')
continue
item['partName'] = part_name_ls[i] # 城区名
item['partURL'] = part_url_ls[i] # 城区页面链接
self.house_list(dict(item)) # 传递深拷贝的item对象
crawled_part.append(item['partName'])
with open('crawledPart.txt', 'w') as f:
f.write(crawled_part)
def __del__(self):
# 到这里表示循环顺利执行完毕
self.driver.close() # 关闭浏览器
print('>>>>[Well Done]')
if __name__ == '__main__':
lj = LianJia()
lj.run()
运行结果示例: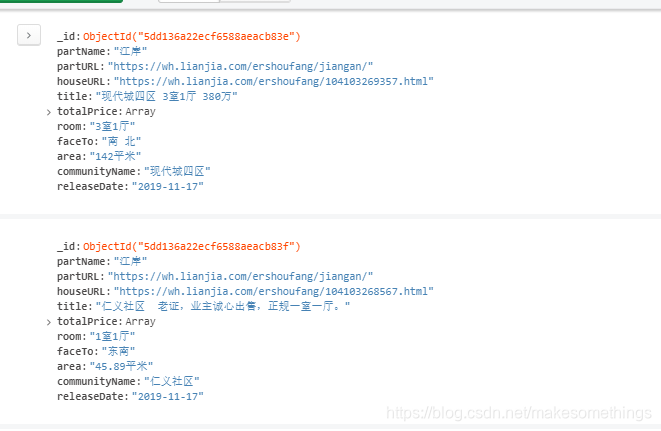
总结一下技术点
线程
基本的框体没有变化, 在处理多线程上面多下了些功夫
之前使用的是ThreadPoolExecutor, 后来发现非常蛋疼的一点是, 不会报错
想要看到错误还要设置参数什么的, 麻烦
果断改成threading, 享受优质的生活
之前的多线程实现的是:
- 同时操控多个浏览器,
运行时间 = 单线程运行时间 / 浏览器个数 平均获取一页(30个)数据的时间 = 3s * 30
经过Z老师的指点改成了:
- selenium负责获取房子的url
- requests负责多线程并发执行数据采集
得到的效果是两秒内就可以获取30个房子的信息, 可以说是质的飞跃

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)