视频监控技术综述
看看以前的综述,传统算法解决问题的方法找找灵感:分类识别(特征提取sift再聚类SVM分类)检测(基于目标HOG全局刚性模型性,基于部件变形DPM,深度学习R-CNN)再到今天的Yolo,真是发展太快了概述:所属计算机视觉、模式识别(通俗:目标是什么、做什么、在哪里、预测会发生什么智能监控让计算机像人脑分析视频序列,对被监控场景内容进行理解,实现对异常行为的自动预警和报警。应用:公共安全监控、工厂
看看以前的综述,传统算法解决问题的方法找找灵感:
- 分类识别(特征提取sift再聚类SVM分类)
- 检测(基于目标HOG全局刚性模型性,基于部件变形DPM,深度学习R-CNN)再到今天的Yolo,真是发展太快了。方向:特征描述、分类器、实时性
- 跟踪:历史轨迹和运动参数(位置、速度)(为行为分析打下基础)
- 识别
- 行为识别
五、行为分析:放在前面目标明确
分析目标干什么(指人):涉及到人视觉系统更深层次的理解、终极问题之一。理论研究价值、应用价值:人机交互、监控。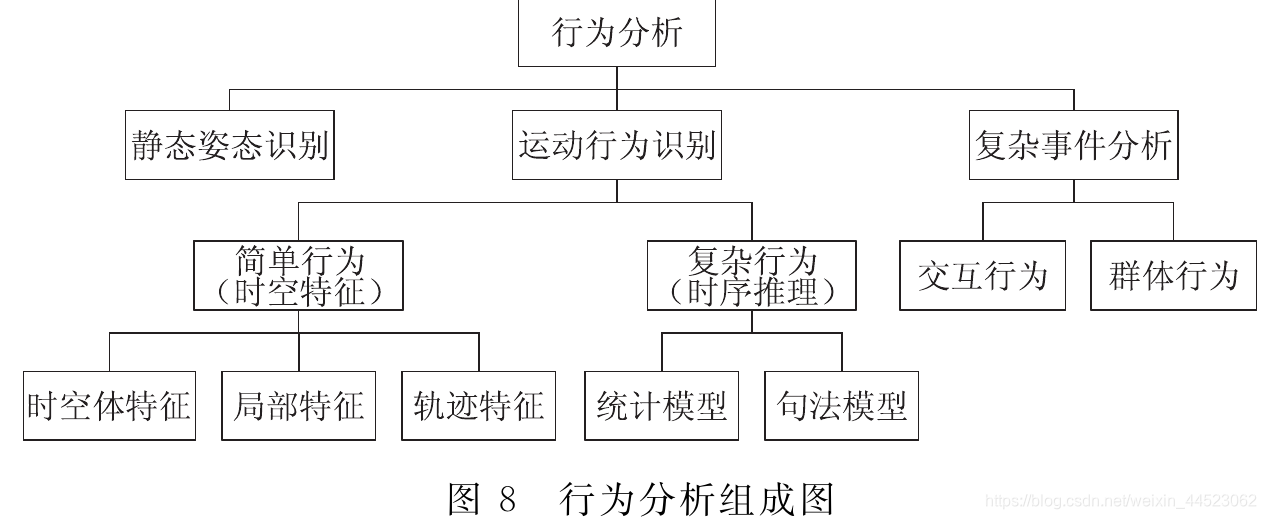
静态姿态识别:在检测和识别的基础上姿态分类
人体姿态模型的研究与计算机视觉的发展密切相关2010年MS的Kinect(随机森林)
Kinect利用RGBD检测跟踪人体骨架(随机森林算法)估计人的姿态,并成功运用到体感交互产品中。
视频姿态识别:主方向
一、概述:所属计算机视觉、模式识别
(通俗:目标是什么、做什么、在哪里、预测会发生什么
智能监控让计算机像人脑分析视频序列,对被监控场景内容进行理解,实现对异常行为的自动预警和报警。
应用:公共安全监控、工厂现场监控、居民小区、交通状态、犯罪预防、交通管制、意外防范、老弱病残监护。
发展
- 在底层上对动态场景中的感兴趣目标进行检测识别、分类、跟踪
- 在高层语义上:对目标行为识别、分析、理解
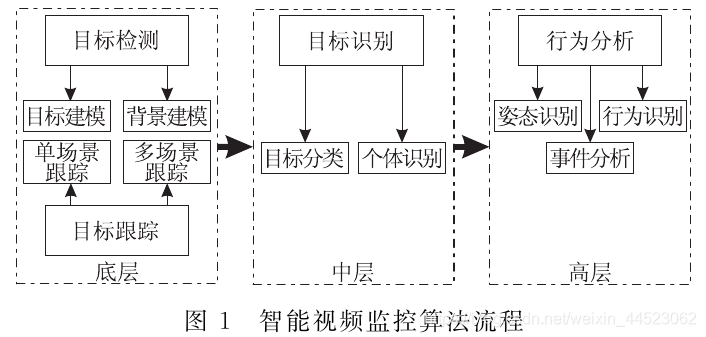
对原始视频图像经过背景建模、目标检测识别、跟踪等分析,得到行为事件:是谁、在哪、干什么
智能监控算法流程
- 检测 获得感兴趣对象
- 跟踪 获得目标活动时间、位置、运动速度、方向、大小。单场景目标跟踪和跨场景目标跟踪
- 识别 是为理解语义信息大桥梁(矩阵数字信号—语义信息)
- 行为分析:姿态识别、行为识别、事件分析(目标在做什么)
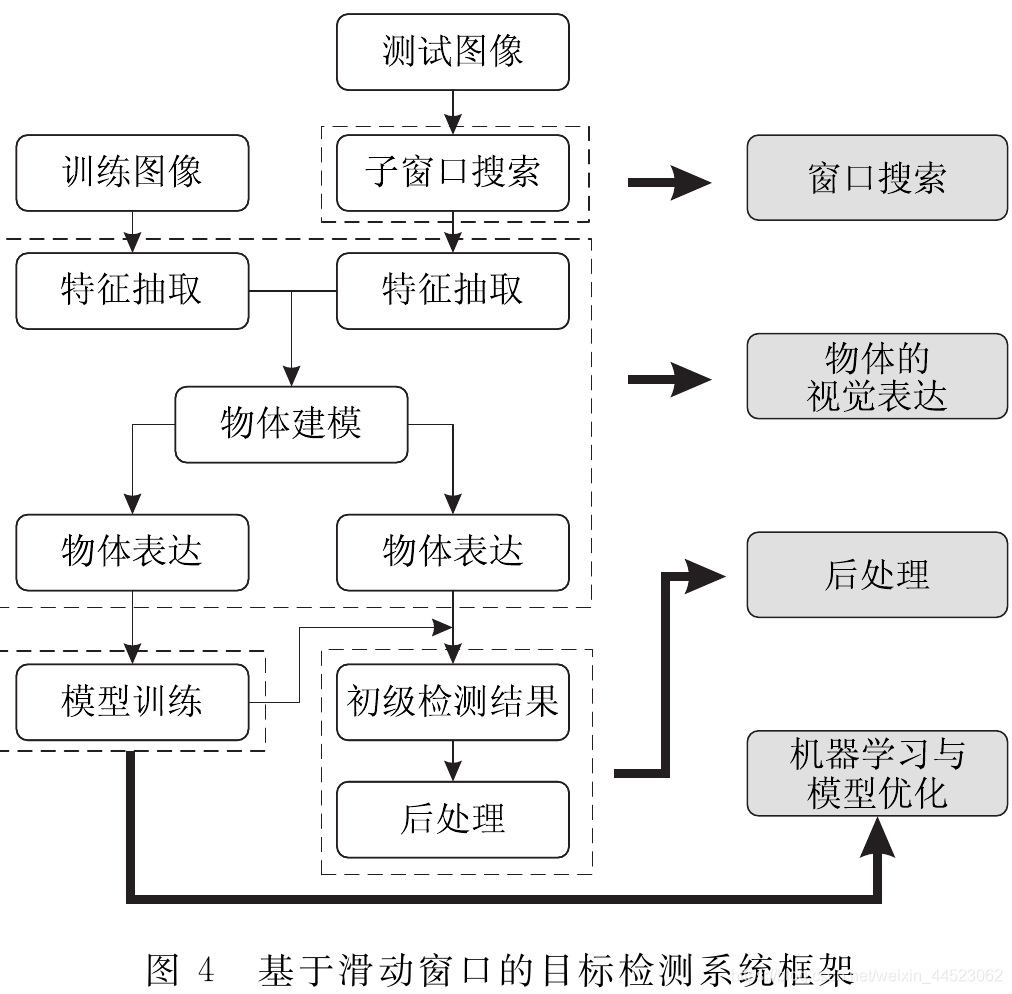
二、目标检测
目标建模:



1. 不受场景限制,利用大量目标进行训练学习,训练分类器,在图像多个尺度上滑动扫描,判定窗口是目标还是背景。
2. 全局模板检测、视觉词典检测、部件检测、深度学习模型检测
- 刚性全局模板检测模型:HOG
- Bag of Words(BOW)(对训练库中抽取局部特征:SIFT、SURF,学习一个视觉词典,然后聚类。预测:抽取局部特征SVM分类。利用局部特征的尺度不变性、仿射不变性、视角不变性可以解决 多视角、部分遮挡的问题
- 部件的检测:BOW丢失空间布局信息,基于部件:整体和多部分综合,有利于解决遮挡和多姿态。DPBM(deformable part based model)可变性部件模型:包含三部分:全局模型(刻画目标全局结构)、部件模型(描述各部件形变)、形变描述模型。
- 深度学习:数据特征表达能力,将检测识别推向新高度。问题:解释性差、模型复杂、优化困难、计算强度高
背景建模:适用于固定位置,背景不动、目标动。GMM(Gaussian Mixture Model)混合高斯模型进行检测可以得分割轮廓
难点:
基于目标建模的检测方法在应用中也有诸多挑战,如巨大的类内差、嘈杂的环境、各式的姿态、严重的遮挡、不同的光线条件、巨大的尺度差异、很小的类间差、严重的形变、低质量图片等等.而且在应用·中,该方法需要事先手工标定大量训练样本,并且在不同的应用场合有可能需要重新标定不同的样本,训练不同的分类器,带来大量的人力开销和费用支出·另外,由于采用滑动窗口策略,该方法时间消耗比较大,一般难以实时.
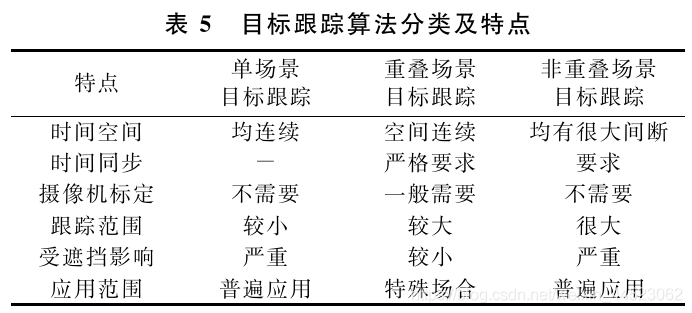
三、目标跟踪
单场景、多场景(重叠、非重叠)
单场景
前景表观建模:找到目标最佳位置 生成
判别前景和背景:判别式:检测和跟踪并行
多场景
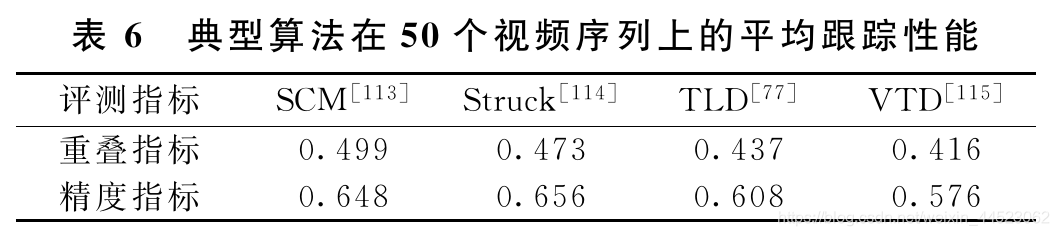
性能指标
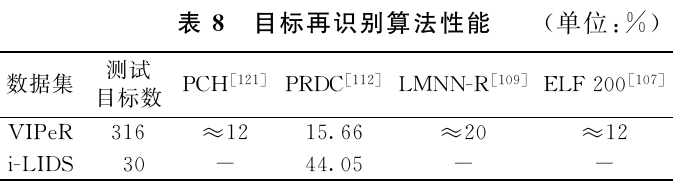
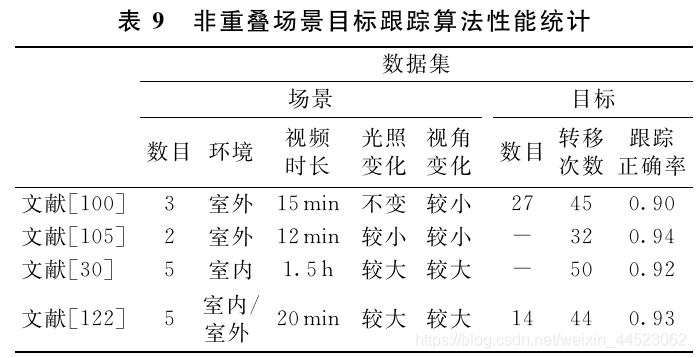
跟踪难题
虽然关于跟踪算法的研究已经持续了很多年,研究者们提出了各种各样的跟踪方法,但是还没有形成一个适用于所有应用场合的统一理论框架或体系,而且目标跟踪在实际应用中遇到的很多难点问题依然没有得到很好的解决,
例如光照突变、遮挡、姿态/视角变化、相似物体与杂乱背景干扰等等.另外,
算法的跟踪准确率与运行效率很难同时兼顾.目前绝大多数跟踪算法,或者实时性好,但准确率低;或者准确率高,但效率低而无法实用.这使得高层视觉技术的研究和应用受到了极大的约束.
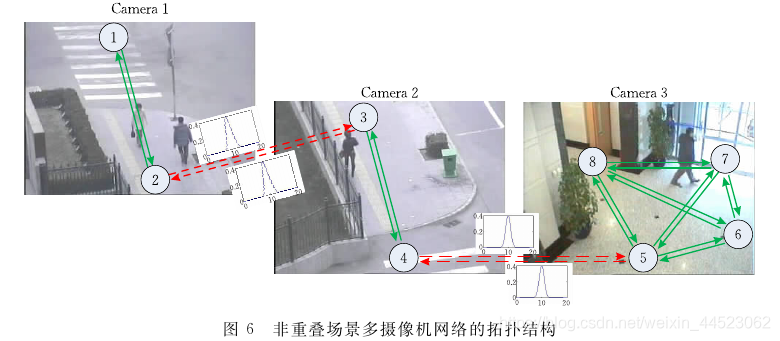
对于多场景的目标跟踪问题,虽然可以利用重叠场景的丰富的空间信息解决单场景下比较棘手的遮挡问题,但是由于经济条件和计算复杂度的限制,一般在实际应用中,更普遍的是非重叠场景的摄像机网络,因此,非重叠场景下的目标跟踪问题,除了面临单场景目标跟踪要面临的上述问题以外,还引人了新的挑战,
多场景目标跟踪挑战:不同摄像机安装的角度不同,所处的光照环境不同,甚至摄像机的参数不同等诸多因素都使得不同摄像机下观测到的同一个运动目标的表观有很大区别,
跨摄像机目标匹配和识别问题很难解决;
不同场景之间的监控盲区导致不同场景下的相同目标的不同观测在时间和空间上都不连续,这种时空信息的缺失给跨摄像机目标关联
四 分类和识别
词袋:BOW:特征提取、特征聚类、特征编码、特征汇聚、分类
特征编码:对底层特征进行编码、获得具有区分性、鲁棒性特征:稀疏、Fisher编码
特征汇聚:空间金字塔匹配
深度学习:CNN、自动编码器(Auto-encoder)、受限玻尔兹曼机(Restricted Boltzmann MachineRBM)、深度信念网络(Deep Belief Nets DBN)
卷积–池化–非线性变换函数(sigmoid、tanh、relu)–softmax分类–RBF分类器
词袋模型是特殊的CNN(一层提取特征、一层聚类)
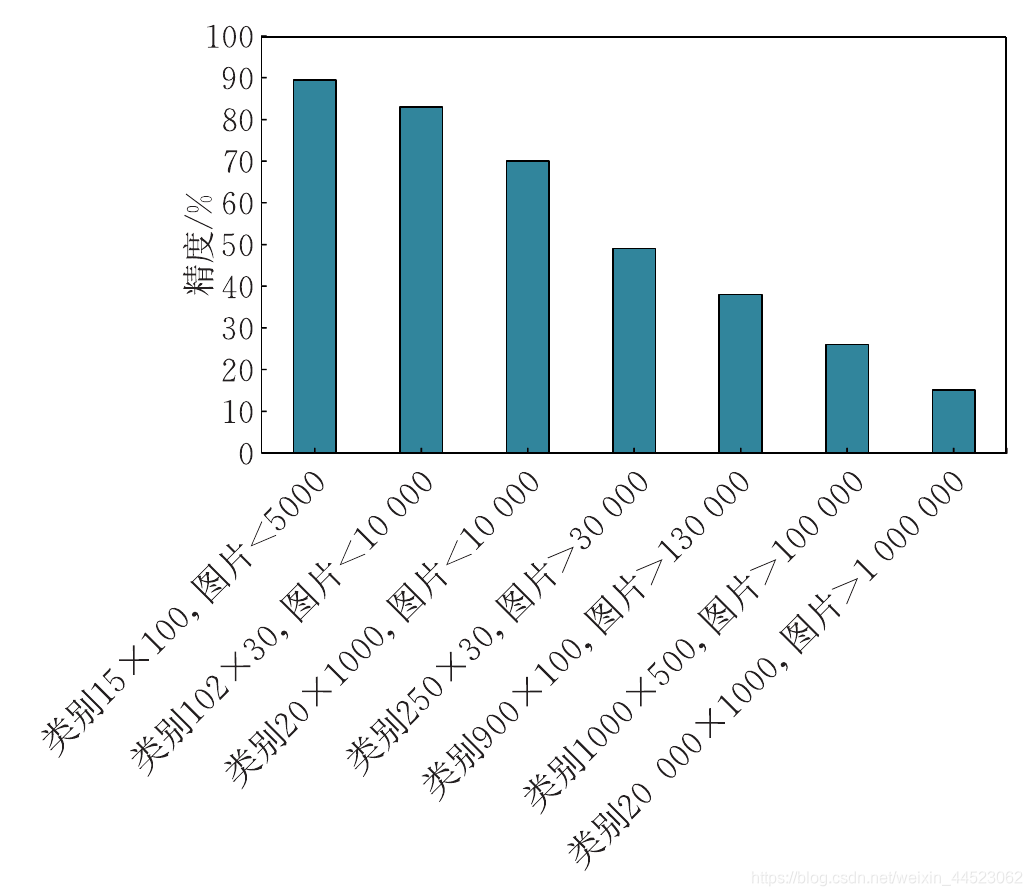
待解决问题
光照条件、视角、尺度、形变、遮挡,表观特征变化大。且背景千差万别,使提取局部特征或中层特征时引入很多噪声和干扰
速度快、精度高、泛化性鲁棒

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)