adaboost 弱分类 matlab,一种AdaBoost算法中弱分类器的同步选取、加权、排序方法与流程...
本发明涉及模式识别方法,特别是涉及一种AdaBoost算法中弱分类器的同步选取、加权、排序方法。背景技术:分类算法就是基于分类器模型为待检测样本从可选的分类中选取最佳的类别假设,它属于人工智能中机器学习范畴,已经吸引了该领域相关研究者的极大关注。人们投入了大量的时间和精力研究诸如C4.5、支持向量机、贝叶斯算法、AdaBoost算法和K-最近邻分类算法等分类算法,并将它们应用于面部识别、笔迹验证、
本发明涉及模式识别方法,特别是涉及一种AdaBoost算法中弱分类器的同步选取、加权、排序方法。
背景技术:
分类算法就是基于分类器模型为待检测样本从可选的分类中选取最佳的类别假设,它属于人工智能中机器学习范畴,已经吸引了该领域相关研究者的极大关注。人们投入了大量的时间和精力研究诸如C4.5、支持向量机、贝叶斯算法、AdaBoost算法和K-最近邻分类算法等分类算法,并将它们应用于面部识别、笔迹验证、数据分析和医学应用等不同领域。
AdaBoost一词是来源于Adaptive Boosting(自适应增强)的缩写,是由Yoav Freund和Robert Schapire提出的机器学习元算法。其设计的指导原则为确保当前训练样本有最高分类精度。通过将不同的弱分类器(这里所谓的弱分类器是指分类精度稍稍好于随机猜测)合理的组合起来,形成强分类器,尽管每个弱分类器的分类精度不高,但最终的强分类器在分类性能上得到巨大提升。AdaBoost算法在某种意义上讲是自适应的,通过调整之前被弱分类器错分的样本权值,提高后续弱分类器对错分样本的重视程度,实现最终分类器模型的设计。正是基于此,一组弱分类器的合理设计可以结合成强分类器,获得一个整体上令人满意的分类精度。
很明显,不同的弱分类器选择、加权和不同的弱分类器排序都将导致完全不同的分类效果。寻找最合适的弱分类器组合、加权方法并为这些分类器选择最佳的排列顺序相当重要,决定了分类器是否能拥有更高分类性能。但是,绝大多数AdaBoost算法应用中,研究者通常都直接指定用哪些分类器,这些分类器的排序也直接根据经验确定。显然,这并不合理。利用GA优化算法的并行搜索优势,本专利中以提高分类精度为目标,同步给出基于AdaBoost分类算法的最佳分类器组合选取、分类器加权和分类器排序方案。
技术实现要素:
针对传统的AdaBoost算法的分类器组合、加权与排序方法的不足,提出一种AdaBoost算法中弱分类器的同步选取、加权、排序方法。算法不同于以往基于人为经验的弱分类器组合选取和加权方法,同时增加了对分类器排序方案考虑,采用GA(Genetic Algorithm,简称GA)优化算法搜索弱分类器选择、加权与排序的最佳方案,使得最终基于AdaBoost算法训练得到的分类器分类效果更佳、分类精度更高。
同时,借助于GA算法并行搜索上的优势,通过智能的方式、基于对分类精度的追求,不但给出了最优的弱分类器组合、加权方案,而且同步的给出了弱分类器排序的最佳方案。通过上述策略,本文最终实现了基于GA算法的最优的AdaBoost分类器模型设计,确保了分类器模型基于分类精度指标上的最优设计。
一种AdaBoost算法中弱分类器的同步选取、加权、排序方法,包括如下步骤:
(1)初始化GA(Genetic Algorithm,简称GA)算法参数设置
设置基因算子GA(F,S,G,M,N),F表示适应度函数,S表示候选方案,G表示代沟因子,M和N分别表示变异率和最大迭代次数;
(2)初始弱分类器集合、权值与对应排列顺序设置
选取初始基因个体,由弱分类器组合、对应权值和排列顺序三部分组成,初始个体随机产生,称为第零代;
(3)GA个体更新
用新产生的GA个体更新之前的基因算子;
(4)适应度计算
基于GA优化中每一步基因个体对应的分类器组合、加权和排序方案,给出对应的分类器模型,进而得到分类器精度作为适应度;
(5)GA算法实现
通过交叉、变异产生新一代基因个体。
(6)迭代结束条件是否满足判断
判断迭代条件是否满足,如满足,在所有候选解中选出对应最高分类精度的分类器模型所代表的分类器组合、权值和排序方案;如不满足,回到步骤(4)。
作为优选,步骤(5)中的通过交叉、变异产生新一代基因个体包括:
采用概率方法从S中选取S(1-G)个成员,加入S1;
根据配对概率p和G,利用交叉算子产生候选基因个体S2;
根据变异概率M,选取候选方案S1中的个体进行变异;
S1与S2组合成新的候选基因个体S3。
与现有技术相比,本发明具有以下明显的优势和有益效果:
(1)本发明提出一种AdaBoost算法中弱分类器的同步选取、加权、排序方法,算法不同于以往基于人为经验的弱分类器组合选取和加权方法,同时增加了对分类器排序方案的考虑。
(2)本发明采用GA优化算法搜索弱分类器选择、加权与排序的最佳方案,使得最终基于AdaBoost算法训练得到的分类器分类效果更佳、分类精度更高。为验证本分类算法,运用本发明方法到笔迹验证试验中,对笔迹书写人身份进行判断,本文算法分类精度可达到96.22%。
附图说明
图1为本发明所提出的一种AdaBoost算法中弱分类器的同步选取、加权、排序方法功能框图;
图2为本发明所涉及方法的流程图;
图3为基因个体示意图,其中,第一部w1w2···wn对应一个弱分类器组合,第二部分α1α2···αn对应弱分类器的权值,d表示一个弱分类器的排列。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的描述。
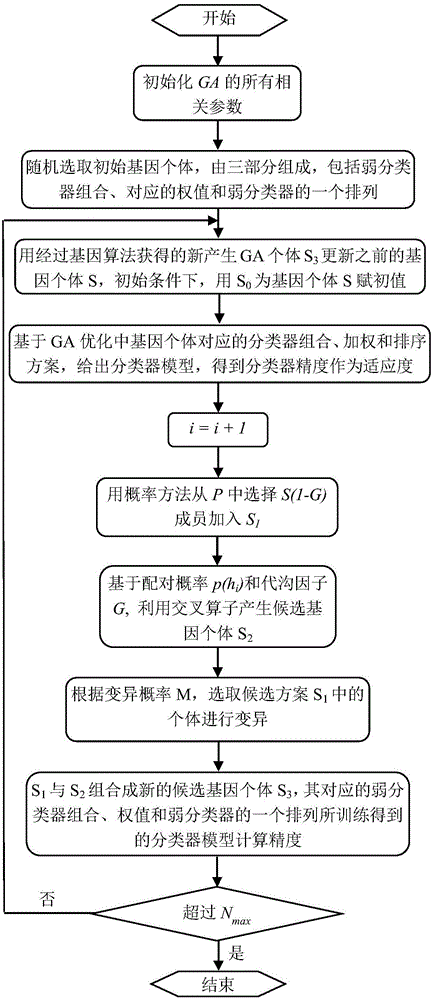
如图1、2所示,本发明实施例提供一种AdaBoost算法中弱分类器的同步选取、加权、排序方法,包括以下步骤:
(1)初始化GA(Genetic Algorithm,简称GA)算法参数设置
设置基因算子GA(F,S,G,M,N),F表示适应度函数,S表示候选方案,G表示代沟因子,M和N分别表示变异率和最大迭代次数;
(2)初始弱分类器集合、权值与对应排列顺序设置
随机选取初始阶段基因个体,该个体由三部分组成,如图3所示,包括弱分类器组合、对应的权值和弱分类器的一个排列,这里产生的初始基因个体被称为第零代;
(3)GA个体更新
用经过基因算法获得的新产生GA个体S3更新之前的基因个体S,初始条件下,用S0为基因个体S赋初值;
(4)适应度计算
基于GA优化中产生的基因个体S3,提取其所代表的分类器组合、权值和排序方案,给出基于该方案和AdaBoost算法训练所得的分类器模型,并基于该模型计算分类精度作为适应度;
(5)GA算法实现
通过交叉、变异产生新一代基因个体:
用概率方法从S中选取S(1-G)个成员,加入S1;
根据配对概率p和G,利用交叉算子产生候选基因个体S2;
根据变异概率M,选取候选方案S1中的个体进行变异;
S1与S2组合成新的候选基因个体S3。
(6)迭代结束条件是否满足判断
判断算法的迭代条件是否满足(迭代次数大于N),如满足,在所有候选解中选出对应最高分类精度的分类器模型,并根据该模型给出其所代表的分类器组合、权值和排序方案;如不满足,回到步骤(4)。
运用本发明方法到笔迹验证试验中。本实验中,设置GA初始化参数为S=36,G=0.5,M=0.05,N=200。同时,根据实验需求从HIT-MW样本库随机的选取笔迹样本作为训练样本,使用正交验证理论对算法进行验证。重复上述实验,给出该算法构建分类器模型的平均分类精度。通过对笔迹书写人身份进行判断,当分类器组合、权值和排序方案最优时,其分类精度可达到96.22%。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)