语音识别综述
慢慢的降各种hi降各种网络架构用到语音识别当中去。会仔细斟酌,将其全部都搞定。
·

语音识别的基本单位
- Phoneme: 音位,音素
-
- a unit of sound 是声音的最基本单位**,每个词语token的声音由多个 phoneme 组成**
Grapheme(字位)
-
smallest unot of a writing system 每个单词书写最基本的单位,简单来说:
-
英文的grapheme可以认为是词缀, 由 [26个英文字母 + 空格 + 标点符号]组成
*** 中文的Grapheme是汉字**
Word词
英文可以用单词,作为语音识别的基本单位,但包括中文再内的很多语言无法使用word作为基本单位。(word数量太过于庞大,word之间难于分隔等)
Morpheme(词素)
- the smallest meaningful unit 类似英文单词中词缀
Bytes
用byte的序列来表示计算机中的每个字符(比如使用utf-8对字符编码),用用byte作为语音识别的基本单位可以让是识别系统将不同的语言统一处理,和语言本身无关,英文上叫 The system can be language independent
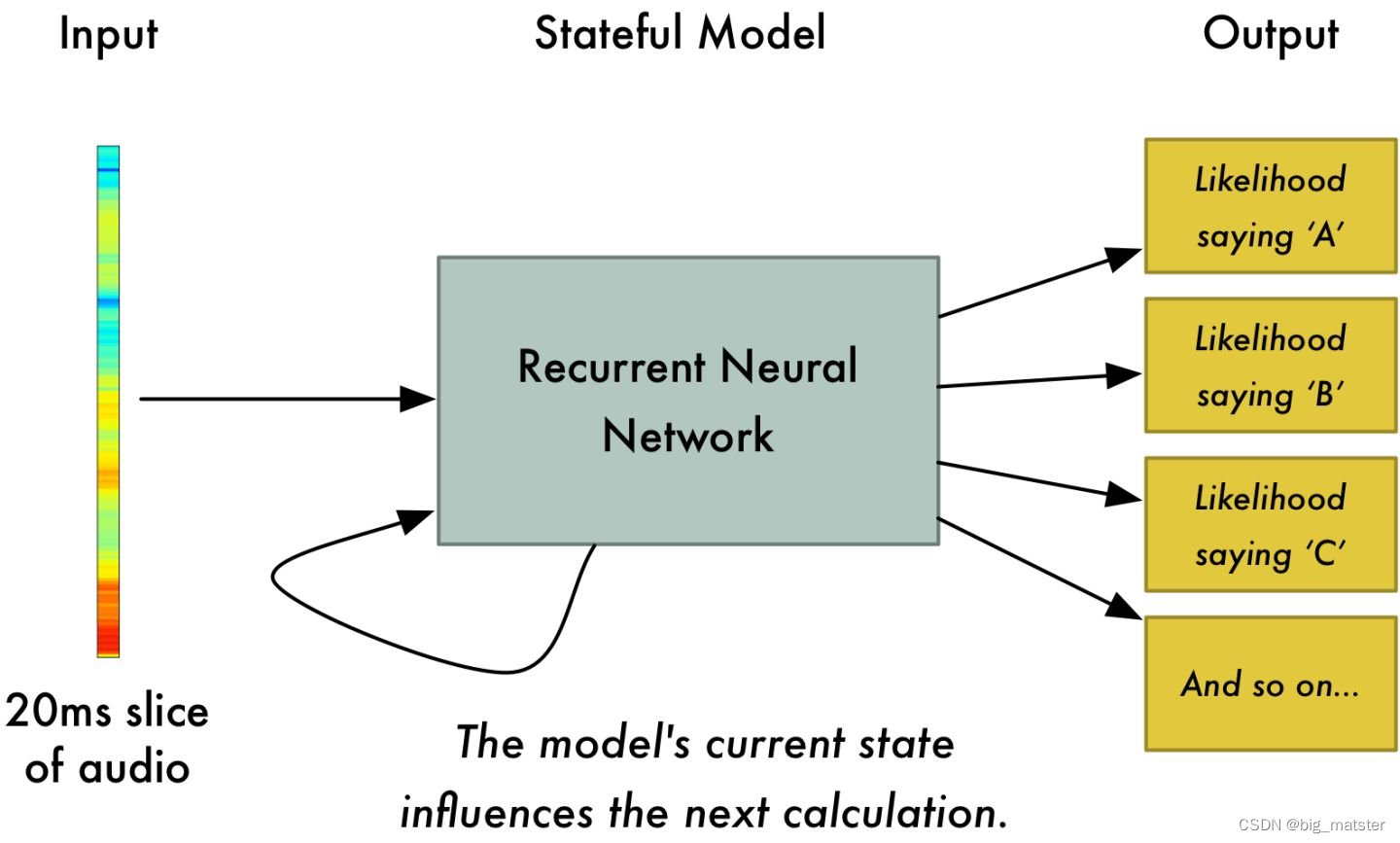
获取语音特征
- 获取语音特征的方法从难到易依次是:
-
- waveform -> spectrogram -> filter bank output -> MFCC

- waveform -> spectrogram -> filter bank output -> MFCC
语音识别的网络结构
语音识别的结构一般可以分为两种,一种是直接输出 word embedding(feature base);一种将语音识别模型和和其他模型相组合的end2end结构,如:speech recognition + 翻译模型、speech recognition + 分类模型、speech recognition + Slot filling模型,这里主要分析这一种类型
语音识别模型
主流的语音模型总体上可以分为seq2seq结构和HMM结构,而seq2seq结构有LAS、CTC、RNN-T、Neural Transducer、MoChA等
LAS

- encoder 中的 Self-Attention 用来对输入数据去噪同时提取有效数据
- Attend 中的 Attention 用来得到当前时刻encoder和decoder之间的语义向量(content vector)

down sampling 下采样
因为语音识别的数据量很大,因此在LAS的 encoder 内往往需要对数据进行下采样的操作,从而降低数据维度,在RNN中,一般使用如下两种方式进行下采样:
- 合并第**一个RNN的输出(两个和并为1个)然后传入第二个RNN
- 在第一个RNN的输出中选择部分输出传入第二个RNN**

Beam search


Location-aware attention


总结,
- 慢慢的将其全部都搞定都行啦的理由与打算。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)