【手搓深度学习算法】手打梯度下降算法
梯度下降算法是一种基于搜索的优化方法,用于寻找函数的最小值或最大值。其背后的原理是目标函数关于参数的梯度将是损失函数(loss function)上升最快的方向。而我们要最小化loss,只需要将参数沿着梯度相反的方向前进一个步长,就可以实现目标函数(loss function)的下降。这个步长η 又称为学习速率。在现代深度学习中,梯度下降算法被广泛使用。深度学习是机器学习的一个分支,它使用人工神经
背景
深度学习中,梯度下降是很重要的损失函数优化算法,所以想弄明白具体的工作原理,以及用代码简单呈现
术语介绍
梯度下降算法是一种基于搜索的优化方法,用于寻找函数的最小值或最大值。其背后的原理是目标函数关于参数的梯度将是损失函数(loss function)上升最快的方向。 而我们要最小化loss,只需要将参数沿着梯度相反的方向前进一个步长,就可以实现目标函数(loss function)的下降。 这个步长η 又称为学习速率。
在现代深度学习中,梯度下降算法被广泛使用。深度学习是机器学习的一个分支,它使用人工神经网络来模拟人脑的功能,以解决复杂的模式识别和预测问题。在深度学习中,我们常常需要最小化损失函数,以便让模型更好地拟合训练数据。梯度下降算法通过计算损失函数关于模型参数的梯度,然后沿着梯度的反方向更新参数值,不断迭代直至收敛。
在深度学习中,梯度下降算法有多种实现方式,包括原始梯度下降法、批量梯度下降法、随机梯度下降法和小批量梯度下降法等。其中,批量梯度下降法对所有的样本计算梯度后求平均,并更新参数,但速度较慢且无法处理超出内存容量限制的数据集。随机梯度下降法则在每次更新时只使用一个样本,使得计算速度加快,但可能会在局部最优解附近徘徊。小批量梯度下降法则介于两者之间,通过使用一定数量的样本计算梯度并更新参数,以平衡计算速度和收敛效果。
总之,梯度下降算法是现代深度学习中非常重要的优化方法之一,它通过计算损失函数的梯度并沿着梯度的反方向更新参数值,以实现损失函数的下降。不同的实现方式可以根据具体问题和数据集的特点进行选择。
可研究的参数
在这个代码中,可以虚构不同的损失函数模型,设置不同的学习率,观察数据收敛的速度和梯度变化的趋势
学习率的影响
相同的损失函数
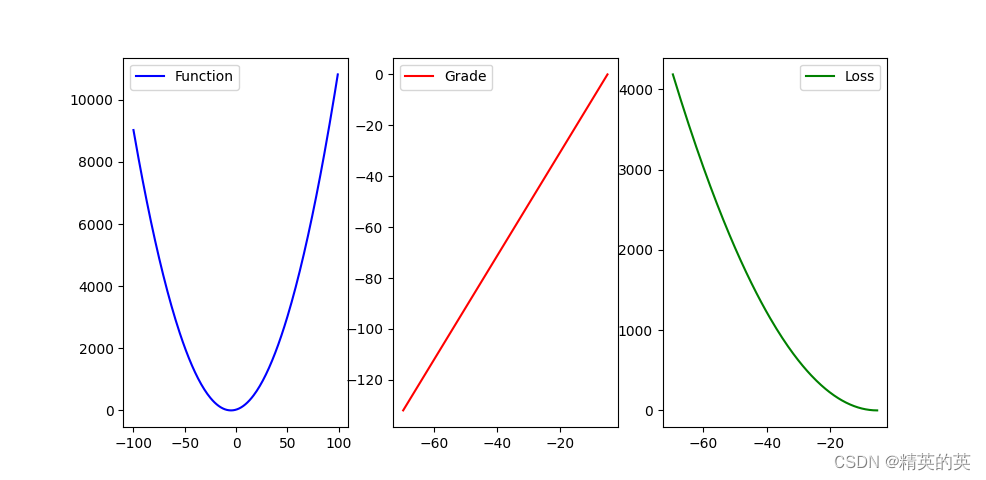
lr = 0.01
lr = 0.001
可见学习率显著影响模型收敛速度
那学习率是不是越大越好呢?
并不是
过高的学习率在变化复杂的函数中可能在谷底震荡,甚至直接跳到另一个山谷
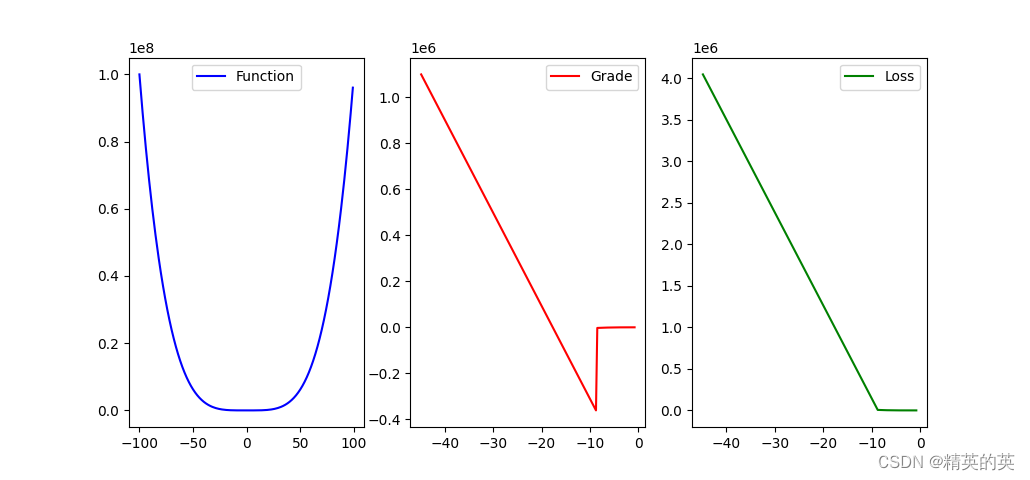
没有极值的函数无法使用梯度下降
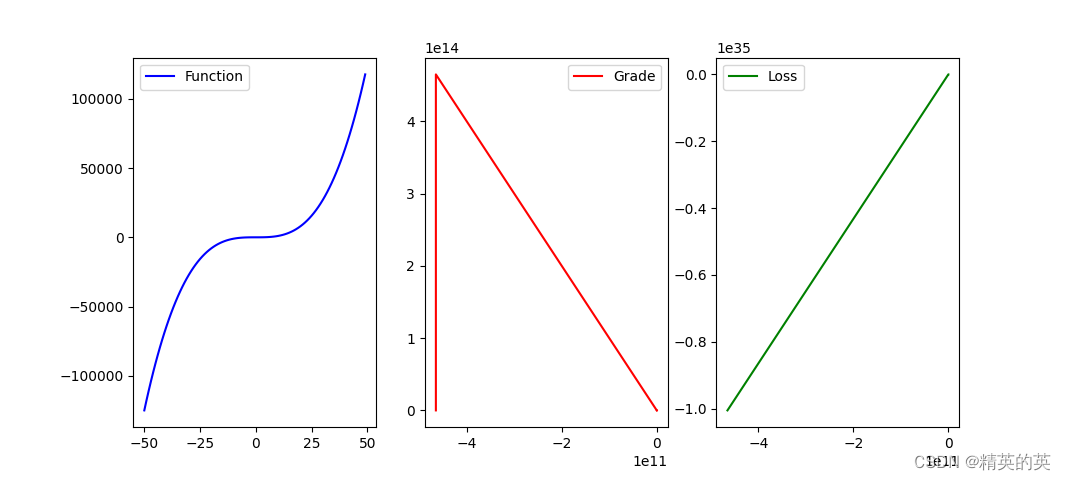
直接上代码
import random
import numpy as np
import matplotlib.pyplot as plt
def main():
def loss_fn(x):
return (x + 5)**2 + 1
def df_loss(x, h =0.00001):
return (loss_fn(x + h) - loss_fn(x)) / h
lr = 0.01
x_pos = random.randint(-100, 100)
print("X starts from {}".format(x_pos))
steps = 0
grade_trend = list()
loss_trend = list()
function_trend = list()
for x in range(-100, 100):
function_trend.append((x, loss_fn(x)))
while (True):
grade = df_loss(x_pos)
x_pos = x_pos - lr * grade
grade_trend.append((x_pos, grade))
loss = loss_fn(x_pos)
loss_trend.append((x_pos, loss))
steps += 1
if (steps % 10 == 0):
print("after {} steps, find when x = {:.3f} grade = {:.5f} loss = {:.5f}".format(steps, int(x_pos), grade, loss))
if ((abs(grade) < 0.1e-5)):
break;
fig, (ax1, ax2, ax3) = plt.subplots(1, 3)
x=[row[0] for row in function_trend]
y=[row[1] for row in function_trend]
ax1.plot(x,y, label="Function", color = 'blue')
ax1.legend()
x=[row[0] for row in grade_trend]
y=[row[1] for row in grade_trend]
ax2.plot(x,y, label="Grade", color = 'red')
ax2.legend()
x=[row[0] for row in loss_trend]
y=[row[1] for row in loss_trend]
ax3.plot(x,y, label="Loss", color = 'green')
ax3.legend()
(5,5,"When lr = {}\nAfter {} steps".format(lr, steps))
plt.show()
return
if (__name__ == "__main__"):
main()代码解析(from GPT)
这段代码实现了一个简单的梯度下降算法,用于寻找一个函数的最小值。以下是代码的详细解释:
-
导入必要的库:
random:用于生成随机数。numpy as np:用于数组和矩阵操作。matplotlib.pyplot as plt:用于绘图。
-
定义主函数
main():
a. 定义损失函数 loss_fn(x):
* 这个函数返回给定 x 的损失值。在这个例子中,损失函数是 \((x + 5)^2 + 1\)。 |
b. 定义损失函数的导数 df_loss(x, h =0.00001):
* 使用有限差分法计算损失函数的导数。导数近似为 \(\frac{f(x+h) - f(x)}{h}\)。 |
c. 设置学习率 lr 和初始位置 x_pos:
* `lr = 0.001`:学习率决定了每次更新的步长。 |
|
* `x_pos` 是随机初始化的,范围在 [-100, 100]。 |
d. 开始梯度下降过程:
* 使用一个 `while` 循环进行迭代。在每次迭代中,计算当前位置的梯度,然后按照梯度的反方向更新 `x_pos`。 |
|
* 记录每一步的梯度、损失和 `x_pos` 的值。 |
|
* 如果梯度的绝对值小于一个很小的阈值(`0.1e-5`),则停止迭代,因为这意味着已经接近最小值。 |
e. 使用 matplotlib 绘图:
* 在一个图上显示三个子图:原函数、梯度和损失随 x 的变化。 |
|
* 使用不同的颜色标记不同的曲线。 |
f. 显示图像并结束。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)