模式识别与机器学习:用决策树来实现鸢尾花的分类
【代码】模式识别与机器学习:用决策树来实现鸢尾花的分类。
·
运行代码如下:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
'''
1.使用load_iris函数加载鸢尾花数据集。
2.将数据集转换为pandas库中的DataFrame对象,方便数据处理和操作。
3.使用seaborn库绘制两两特征之间的关系图。
4.使用train_test_split函数将数据集划分为训练集和测试集。
5.创建DecisionTreeClassifier分类器对象。
6.在训练集上使用fit方法训练决策树模型。
7.在测试集上使用predict方法预测目标变量,并使用accuracy_score函数计算模型的准确度。
8.使用confusion_matrix函数计算混淆矩阵,并使用seaborn库绘制混淆矩阵图。
9.使用classification_report函数生成分类报告。
'''
# 加载鸢尾花数据集
iris = load_iris()
# 将数据集转换为DataFrame对象
iris_df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
# 将目标变量转换为分类变量的名称
iris_df['target'] = iris_df['target'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})
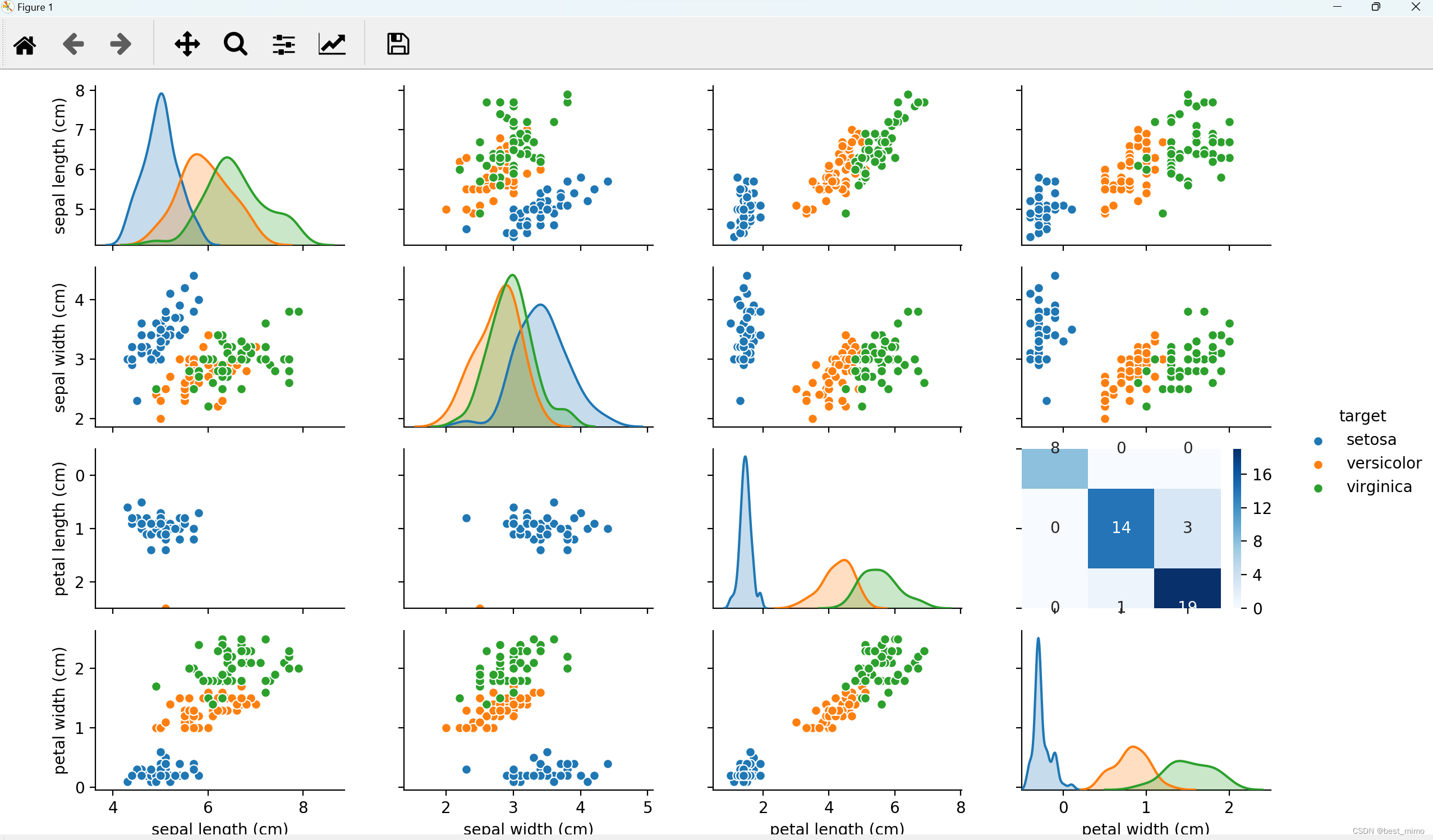
# 绘制两两特征之间的关系图
sns.pairplot(iris_df, hue='target')
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 在训练集上训练决策树模型
clf.fit(X_train, y_train)
# 在测试集上评估模型性能
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
# 打印分类报告
cr = classification_report(y_test, y_pred, target_names=iris.target_names)
print(cr)运行结果如下:

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)