0基础0元学习Python-第三天
李雷的学习来到了第三天。居然能坚持到第三天,不容易呀~复习第二天的内容学会了使用Python读取文件,获得文件里的数据。学会了通过Python使用正则表达式匹配字符串。正则表达式使得查询变得强大而且简单。使用的方式如下:#!/usr/bin/python# -*- coding: UTF-8 -*-import res = ''# 打开文件,把数据存入s变量,使用...
李雷的学习来到了第三天。居然能坚持到第三天,不容易呀~
复习第二天的内容
学会了使用Python读取文件,获得文件里的数据。
学会了通过Python使用正则表达式匹配字符串。正则表达式使得查询变得强大而且简单。使用的方式如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
s = ''
# 打开文件,把数据存入s变量,使用with打开,可以自动处理释放资源
with open('level3.txt') as file_:
s = ''.join(line.rstrip() for line in file_ )
# 通过正则表达式,获得匹配好的数据,re.M表示多行匹配,这里其实不是必须,因为上一步已经把字符串处理成了一行
searchAll = re.finditer( r'[a-z][A-Z]{3}([a-z])[A-Z]{3}[a-z]', s, re.M)
# 这个变量用来存放所有的匹配出来的小写字母
letter = ''
# 因为使用了re.finditer函数,需要利用循环来读取匹配到的结果,每一次循环获得匹配到的一个结果
for match in searchAll:
print(match.group())
print(match.group(1))
letter = letter + match.group(1) # 因为在模式字符串中写了(),所以使用group(1)能获得括号里的内容
print letter第4题
第二天李雷来到了第4题,是一个循环题目
页面里没有任何提示,但是图片可以点击,点击后的页面是:http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345
页面显示and the next nothing is 44827。然后访问http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=44827
页面显示and the next nothing is 45439,接着访问http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=45439
页面显示Your hands are getting tired and the next nothing is 94485,接着访问http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=94485
页面显示and the next nothing is 72198,接着访问http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=72198
页面显示and the next nothing is 80992,接着访问http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=80992
......
访问一个页面得到下一个页面的地址。这是一个编程能发挥作用的绝佳机会,就是重复,重复的访问并获得下一个链接。
程序能不知疲倦的重复执行一个操作,没有抱怨。李雷先学习了如何使用Python访问网页,然后思考如何写出让程序循环的访问这个页面,或者下次页面的参数再访问。根据一些经验,这里李雷觉得可以使用while循环,直到找到页面返回的内容不是and the next nothing is格式的,再停止。
为了识别这个格式,需要用到第二天学到的正则表达式。经过2个多小时的反复调试和实验,最后代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
import urllib
# 用next变量存开始页面的参数
next = '82972'
# 循环开始,只要返回的内容存在就一直执行
while (next):
# 使用页面参数拼接url打开一个网页
page = urllib.urlopen('http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=' + next)
# 读取数据
data = page.read()
# 判断数据是否符合特定格式
matchObj = re.match(r'and the next nothing is (\d+)', data)
# 如果满足特定格式,更新next变量为最新的参数
if matchObj:
next = matchObj.group(1)
else:
# 如果不满足格式,请求next,这个时候while循环会停止
next = ''
# 输出一下页面返回的结果
print('Data:', data.decode('utf-8'))代码运行截图:
程序输出的最后一行是peak.html。哈哈哈,来到了下一题。
这个代码有很多缺陷,其中最大的一个是没有考虑到打开网页的时候会超时。
第5题
打开http://www.pythonchallenge.com/pc/def/peak.html,李雷看到了一幅图

盯了半天,不知所云,还是看源代码吧。
<html>
<head>
<title>peak hell</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<center>
<img src="peakhell.jpg"/>
<br><font color="#c0c0ff">
pronounce it
<br>
<peakhell src="banner.p"/>
</body>
</html>
<!-- peak hell sounds familiar ? -->
不用多说,李雷赶紧在搜索引擎里搜索“Python .p文件”,看看能发现什么。
找到了相关的文章:
https://blog.csdn.net/cybeyond_xuan/article/details/82985066
发现.p文件是使用cPickle库序列化后的文件,可以使用cPickle库反序列化会序列化之后的文件, 李雷把.p文件下载回来,然后参考网上方法反序列化试一试。实际测试,发现本地没有cPickle库,但是有pickle库可以使用,是一样的。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import pickle
import re
dumps_content = ''
# 打开文件,把数据保存在dumps_content里
with open('banner.p') as file_:
# 读取整个文件,不需要处理结尾空白
dumps_content = file_.read()
# load一下整个文件,反序列化
loads_content = pickle.loads(dumps_content)
print(loads_content)输出了一个二位数组,如图:
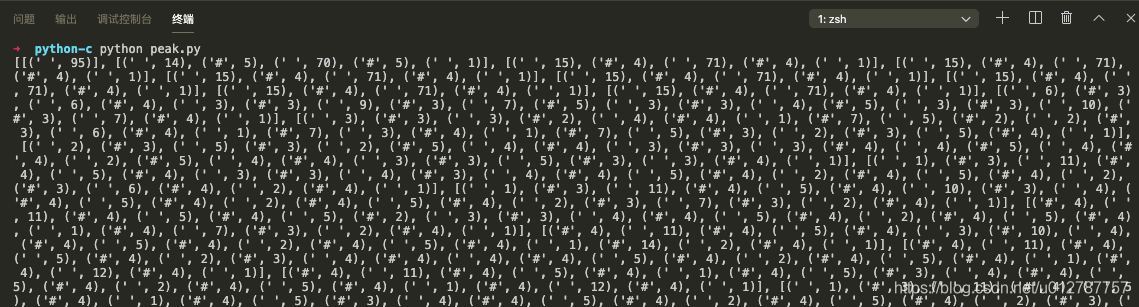
李雷仔细看了看里面的元素,仿佛发现了什么。第一个元素的数组里包含一个元组,元组第二个元素是95,第二个元素的数组里有5个元组,把这些元组的第二个元素加起来也是95。这貌似是表示一行有95个位置,每个元组表示这一行对应的列应该展示什么。如果有没有猜错的花,应该会输出一个图形来。李雷赶紧试一试通过两层循环,根据这个元组规则打印出来看看。
经过一个小时的尝试和练习,最后李雷写出来代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from __future__ import print_function
import pickle
import re
dumps_content = ''
# 打开文件,把数据保存在dumps_content里
with open('banner.p') as file_:
# 读取整个文件,不需要处理结尾空白
dumps_content = file_.read()
# load一下整个文件,反序列化
loads_content = pickle.loads(dumps_content)
# 循环每一行
for row in loads_content:
# 循环每一行的多元素
for item in row:
# 对每个元素,根据多个,循环打印出字符
for r in range(item[1]):
# 输出字符不换行
print(item[0], end='')
# 每一行循环完以后换行
print('')这个代码运行以后会输出:
cool。李雷顺(艰难)利(努力) 来到了第6题。http://www.pythonchallenge.com/pc/def/channel.html
第6题
http://www.pythonchallenge.com/pc/def/channel.html,有点色情,感觉是裤子拉链开了。

还有作者的捐助按钮,难道想表达的是捐钱可以继续往下拖?李雷看了一下源代码。
<html> <!-- <-- zip -->
<head>
<title>now there are pairs</title>
<link rel="stylesheet" type="text/css" href="../style.css">
</head>
<body>
<center>
<img src="channel.jpg">
<br/>
<!-- The following has nothing to do with the riddle itself. I just
thought it would be the right point to offer you to donate to the
Python Challenge project. Any amount will be greatly appreciated.
-thesamet
-->
<form action="https://www.paypal.com/cgi-bin/webscr" method="post">
<input type="hidden" name="cmd" value="_xclick">
<input type="hidden" name="business" value="thesamet@gmail.com">
<input type="hidden" name="item_name" value="Python Challenge donations">
<input type="hidden" name="no_note" value="1">
<input type="hidden" name="currency_code" value="USD">
<input type="hidden" name="tax" value="0">
<input type="hidden" name="bn" value="PP-DonationsBF">
<input type="image" src="https://www.paypal.com/en_US/i/btn/x-click-but04.gif" border="0" name="submit" alt="Make payments with PayPal - it's fast, free and secure!">
<img alt="" border="0" src="https://www.paypal.com/en_US/i/scr/pixel.gif" width="1" height="1">
</form>
</body>
</html>作者劝李雷充值,但是李雷并没有paypal,上个alipay,李雷或许考虑充1块钱感谢作者的题目。李雷看出来这是一个谜语题,只能靠传家宝了,猜猜猜。
根据第一行的提示,输入一个channle.zip试一试,没有。然后输入zip.html。页面提示:
yes, find the zip.
确认这个思路是正确的。
再试一次channel.zip。文件下载成功,第一次没有成功,应该是在源代码页面输入zip文件会触发下载,在源代码页面无效了。
这个压缩包里有很多文件。里面一个 readme.txt文件,里面是这样写着:
welcome to my zipped list.
hint1: start from 90052
hint2: answer is inside the zip
打开90052看看,里面写着:
Next nothing is 94191
看来和第5题一样的,只不过是把网页换成了文件。换汤不换药💊呀~
总结
李雷已经基本能读取文件,使用这则表达式。
并且实践了如何访问网页,反序列化字符串。
处理元组和数组。
第四天加油~

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)