《模式识别与智能计算》的数据集
关于这本书的数据集问题这本书我老师说很好,让我买来看看,结果一学期过去了,emmmm,不是我的问题,是这本书没有数据,没有源代码(强行甩锅),咳咳,跑远了,这本书的数据集我我到网上看到了,它的数据集格式是这样的allsamples有两个字段,一个为num,一个feature,然后feature是一个25*5维的数据,25表示特征个数,5表示该类字体的个数。由于考虑到可能大多数买了书没有数据集...
·
关于这本书的数据集问题
这本书我老师说很好,让我买来看看,结果一学期过去了,emmmm,不是我的问题,是这本书没有数据,没有源代码(强行甩锅),咳咳,跑远了,这本书的数据集我我到网上看到了,它的数据集格式是这样的

allsamples有两个字段,一个为num,一个feature,然后feature是一个25*5维的数据,25表示特征个数,5表示该类字体的个数。由于考虑到可能大多数买了书没有数据集的问题,我后面写的代码都会用sklearn.dataset下的digits手写数据集,它是8x8维的矩阵表示一个数字,有1797个样本数据,比自己写好多了。下面是digits的形式
| 属性 | 意义 |
|---|---|
| data | 数据集 |
| target | 数据类型 |
| target_name | 数据类型名称 |
好了,后面写到的代码都会用到这个代码,其他的数据类型,有需要的自行查看,这里就不解释了。
from sklearn import datasets
import numpy as np
#导入数据
digits = datasets.load_digits()
#查看第一数据的样子
new_im = np.reshape(digits.data[0],(8,8))
print("第一个数字是",digits.target[0])
print(new_im)
运行结果如下: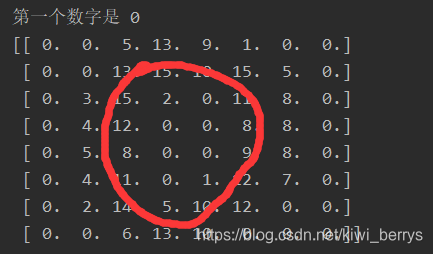
后面的内容都会用以上数据集,如果有错误请指出,互相学习*(▽)*

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)