机器学习(一)
什么是机器学习首先我们来认识下什么是机器学习,机器学习就是为了完成某项工作或者说是任务,加入了一些评判项,包括一些数据和经验,来进行处理,从而完成我们的工作和任务,也就是说机器从数据和经验中学习到了东西.机器学习的主要工作就是从数据中学习有用的部分,辅助更好的完成工作.有人说机器学习就是通过统计学建立模型,进行分析和评判.机器学习的应用一、分类问题分类问题是机器学习中应用较...
春风如贵客,一到便繁华。各位看官点赞再看,养成好习惯(●´∀`●)
什么是机器学习
首先我们来认识下什么是机器学习,机器学习就是为了完成某项工作或者说是任务,加入了一些评判项,包括一些数据和经验,来进行处理,从而完成我们的工作和任务,也就是说机器从数据和经验中学习到了东西.
机器学习的主要工作就是从数据中学习有用的部分,辅助更好的完成工作.
有人说机器学习就是通过统计学建立模型,进行分析和评判.
机器学习的应用
一、分类问题
分类问题是机器学习中应用较多的一类问题,举个栗子,区分蛇和大象,我们需要设计一个程序,目的是让这个程序能够见到蛇和大象的时候能够区分他们是什么.
这类问题的判断结果都是类别,因此叫做分类问题.
二、回归问题
与分类问题对应,回归问题的判断结果是一个值.比如预测这只大象的体重或者身高等等.
但是经常情况下,分类和回归问题的算法是通用的,例如对于分类问题,我们可以使用回归问题给预测出的体重或身高等,判断样本的类型.
机器学习的过程
倘若计算机并没有见过蛇和大象,then计算机只能通过随机猜测,所以结果为五五开(致敬卢本伟),显而易见,这样的程序很low.
现在我们对程序进行优化,我们可以给程序10条蛇和10只大象,让他们学习下大象个蛇长什么样子.当然数据量越大,越准确.
其次,我们可以借助蛇和大象的身体特征来区分,我们很自然能想到蛇和大象很大的区别是有没有腿,可以根据这个特征准确的判断这个动物是大象还是蛇,这就是一个很好的参数.
大象和蛇都有两只眼睛,所以我们可以判定这个条件对判断这两个物种是没有作用的.
当然我们呢可能会遇到提取到某模型,但是我们并不知道这个特征对这个任务有没有用,我们可以把这个问题交给模型,让模型判断这些特征是否有用.因此我们可以通过模型进一步判断,比如体重>10kg的很有可能是大象,而不是蛇.
通过上述步骤,我们得到了一个模型,模型可以根据他学习到的特征进行简单判断,很显然这个模型比单纯随机猜测要好很多,这证明这个模型已经从样本中学习到了一些知识.
机器学习的几个概念
精度:对于分类问题来说,精度是指模型将分对数目/要区分的总数目.在学习之前精度为50%,但是在学习之后,精度大大提高.
样本:我们给出的10只大象和10条蛇样本,这个就叫做训练样本.
标签:我们告诉模型哪些是大象哪些是蛇,这就是精确标识,就是标签.
特征:我们从样本身上总结出来的腿或者体重就是样本特征.
特征提取:我们从样本身上提取到的腿或体重,就是特征提取.
特征选择:我们从严本身上获得的特征,包括体重和体重,或者眼镜,筛选出有用的,这就是特征选择,特征选择可以交给模型做,也可以交给人做.
模型训练:我们通过有用的特征来训练模型的过程。我们不只需要知道哪些特征有用,还需要知道怎么用这个特征。比如我们选择了10 kg作为体重这个特征的参数和分界点,来帮助我们进行判断。怎么使用特征的过程就是模型训练。程序可以通过某种方法找到10 kg这个分界点。
模型参数:在模型训练过程中,我们不能指望模型自己完成,而是需要给模型一些帮助。比如,如果模型学到的是体重低于10 kg的是猫,这是一个比较好的模型。但是,有时候模型会学到体重是5 kg或6 kg的是猫,那么这个学习结果其实不能推广,我们需要根据经验告诉模型,不需要学习这些细节,并给它加一些限制,从而人为地帮助模型进行学习。这就是模型参数问题。
训练集、验证集、测试集
训练集、验证集、测试集,这些都是为了训练模型分出的一些数据集。
训练集:那些有标签的样本,输入模型进行训练,比如给模型的那20个有明确标识的样本,即10只大象和10条蛇。
验证集:我们有20个样本,我们可能不会把它们都提供给模型进行训练,可能只拿出15个用来训练,另外5个用来验证。如果模型的学习效果比较好的话,它可以比较准确地分出这剩下的5个。如果效果不好,那么就需要重新进行训练。
测试集:模型并未见过的样本,用来进行模型评估。当模型训练好之后,可以使用测试集对模型效果进行评估。
有监督学习和无监督学习
顾名思义,有监督学习指的是有训练样本,并告诉模型哪些是蛇、哪些是大象,让模型进行学习。
无监督学习指的是给模型20个样本,即训练数据,但是并不告诉模型哪些是蛇、哪些是大象,而是让模型自己去学习。其中比较常见的是聚类问题,好的聚类方法可以把相同的动物分到一个类别,只是它不清楚这个类别具体是什么。
模型评价
训练出来的模型可能是一个好的模型,也可能是不好的模型,也可能在训练样本上可以做很好的判断,但是对于新样本就无法做很好的判断。因此,我们需要对模型进行评价。以下是各评价指标: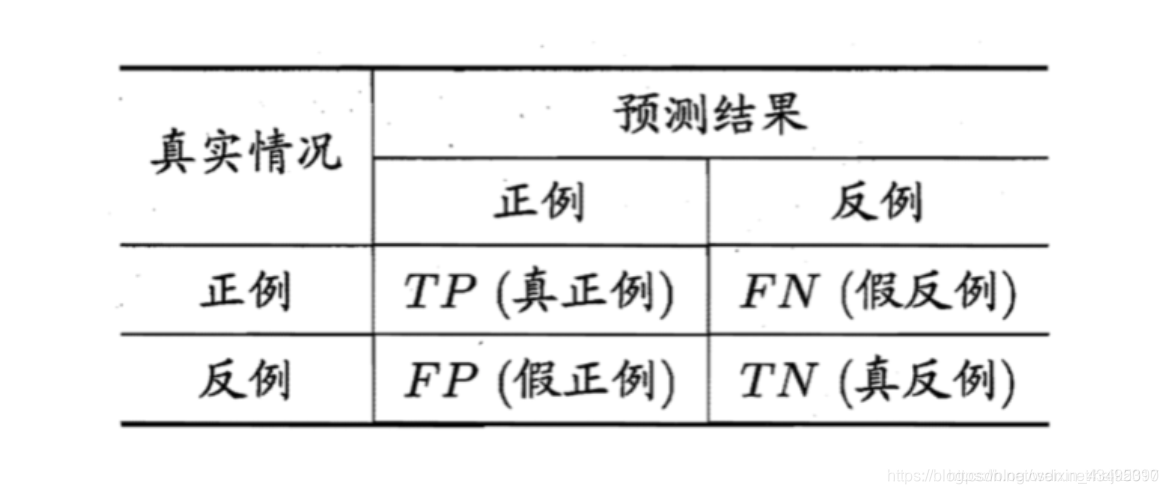
精度:分对的样本占总样本比例TP+TN / TP+TN+FP+FN
错误率:分错样本占总样本比例FP+FN / TP+TN+FP+FN
查准率:模型认为是正样本的样本中真正的正样本所占比例TP / TP+FP
查全率recall:模型找出的真正的正样本占正样本总数的比例TP / TP+FN
FPR:被模型判断为正样本的负样本占真正的负样本的比例 FP / FP+TN
TPR:被模型判断为正样本的正样本占真正的正样本的比例 TP / TP+FN
ROC:不同阈值下,TPR和FPR组成的曲线
AUC:ROC曲线下面积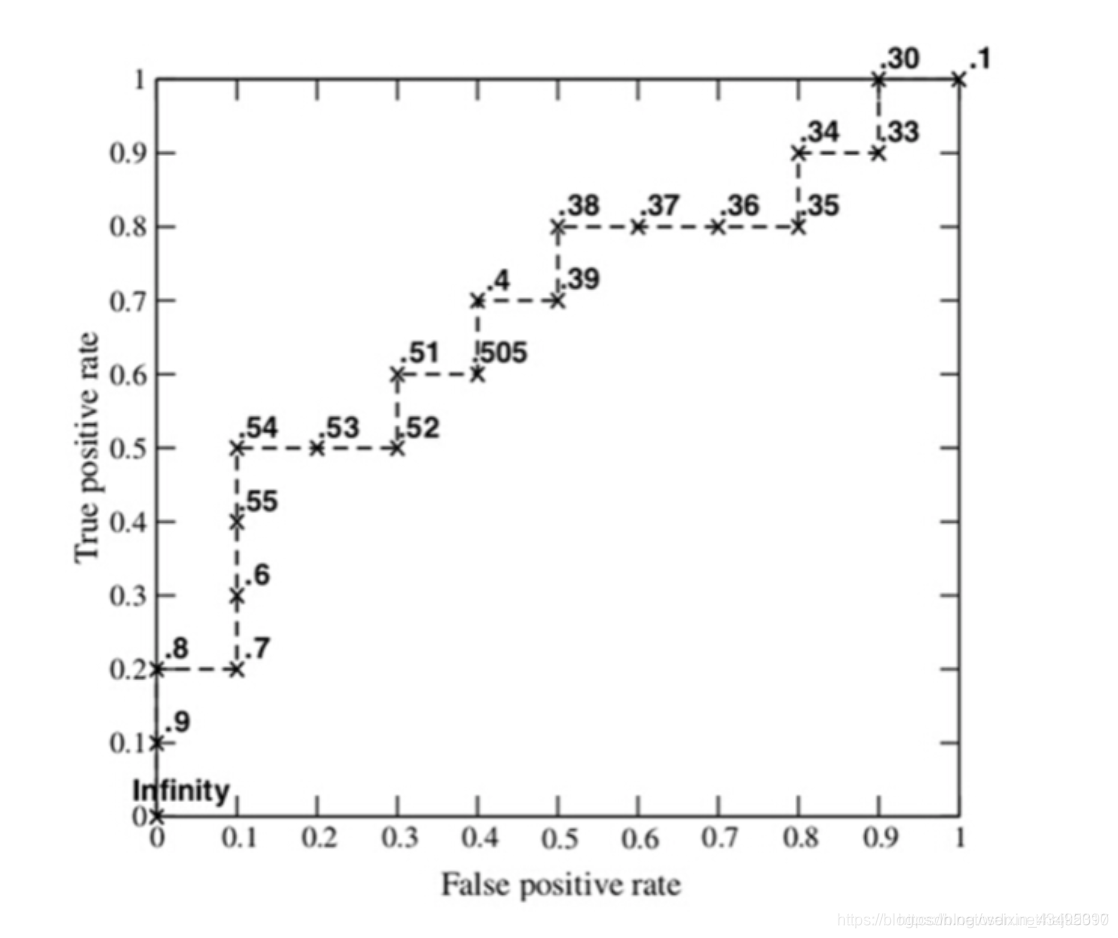
在ROC曲线上,(0,1)这个点代表模型误判为正样本的负样本数为0,同时模型找出了全部的正样本。这是最理想的模型。因此,曲线越接近这个点,模型的效果越好。
于是,我们利用ROC的曲线下面积(AUC)来总体评估模型在不同阈值下的表现。AUC越接近于1,证明模型的效果越好。
过拟合:简单来讲就是过于追求拟合时的契合度了,导致模型失去了一些通用性(泛化性),不能很好地适用于其他的场景。当机器学习的局部特征过多,就会造成过拟合。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)