

该系列将描述一些自然语言处理方面的技术,完整目录请点击这里。
这个专题,我们主要学习如何从一个句子中来构建一个语言模型。语言模型最早是应用在语音识别的问题上,当然它们仍然在现代语音识别系统中发挥着核心的作用。之后,语言模型也被广泛的应用到其他的NLP任务之中。最原始的语言模型是采用参数评估技术来实现的,这个技术在很多的NLP任务中都被使用,比如后续我们会将到的标记问题和解析问题。
假设我们有一个语料库,里面有很多的句子。比如,这是一个人民日报多年积累下来的文章。那么,我们可以根据这个语料库来设计我们的语言模型。
那么什么是语言模型呢?首先,我们需要定义一个词集 V,比如,我们对英语构建一个语言模型,那么:
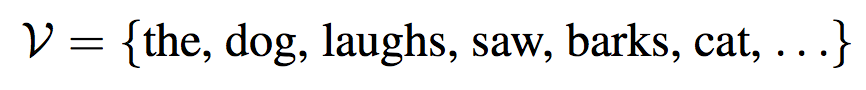
在真实的环境中,V 是一个非常大的集合,它可能包含成千上万的词。我们假设 V 是一个有限集合。一个句子可以用如下参数来表示:
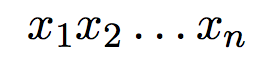
其中,n>=1,并且
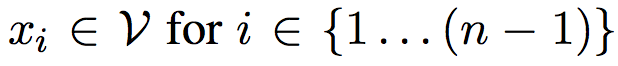
我们假设 xn 是一个特殊符号 STOP,并且该符号不在集合 V 里面。那么,我们为什么需要在句子的最后加上 STOP ,因为这样有助于去确定一个句子是否结尾,比较方便。举个例子,比如:
the dog barks STOP
the cat laughs STOP
the cat saw the dog STOP the STOP
cat the dog the STOP
cat cat cat STOP
STOP
...接下来,我们需要定义一个句子集合 V',这个集合中的句子是由集合 V 中的词所决定的,但这个集合是一个无限集合,因为句子的长度你无法确定。
接下来,我们正式定义语言模型。
Definition 1:语言模型有一个有限集合 V 和一个概率方程 p(x1, x2, ..., xn) 组成,使得:
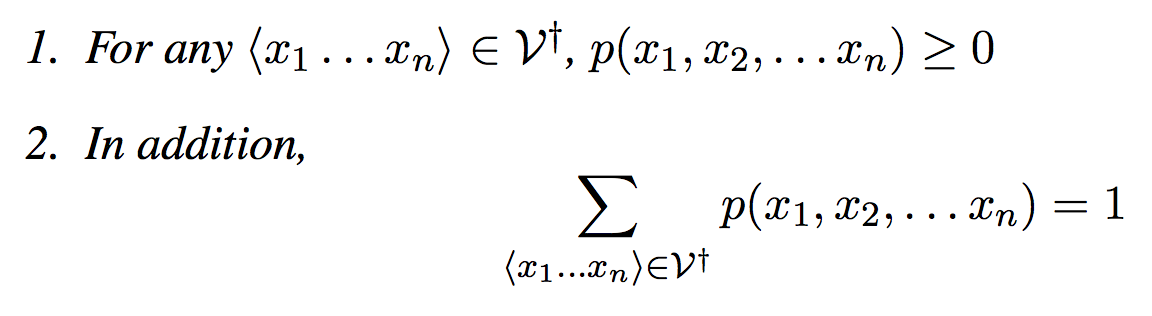
因此,p(x1, x2, .., xn) 是句子的一个概率分布。
那么,根据词库,我们如何来训练我们的语言模型呢?我们首先来介绍一个非常直观的方法,但是这个方法是很笨的。我们定义 c(x1, x2, x3, ..., xn) 是句子 x1x2x3....xn 在语料库中出现的书,N 是语料库能组成的句子的总和。那么我们可以定义如下:
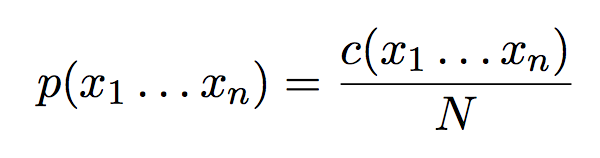
但正如我们刚刚说的,这是一个非常差的模型。那么为什么差呢?因为如果一个句子你没有在语料库中出现,那么你得到的概率就是 0。也就是说,如果在训练集中没有出现这个句子,那么测试集中我们一直会得到概率 0。但是我们不可能训练到每一个句子,所以这是一个非常差的模型。那么,这一章,我们的任务就是学习,如何去产生一个没有在训练集中出现的句子。
那么,我们为什么要学习语言模型呢?这个看起来很奇怪的东西,在以后的具体任务中会有什么用处呢?主要有以下两个理由:
-
语言模型在很多的应用中都有使用,特别语音识别和机器翻译。而且,在很多的场景中,语言模型被用作一个先验概率,判断那些词可能或者不可能出现在爱句子中。比如,在语音识别中,语言模型与声学模型相结合,用以模拟不同单词的发音。具体的实现步骤,一种
想法是,声学模型产生很多的候选句子,然后利用语言模型对所有的候选句子进行一个排序,从而确定一个概率最大的句子。 -
我们描述并且定义函数 p 的技术,也就是从训练样本中得到模型的参数估计,这种方法有助于应用到其他语境中。比如,隐马尔科夫模型,自然语言解析模型。







 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)