K近邻算法样例
K近邻算法介绍在模式识别领域,K近邻算法是一种用于分类和回归的非参数统计法。在这两种情况下,输入包含特征空间(Feature Space)中的k个最接近的训练样本。在k-NN分类中,输出是一个分类族群。一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小)中最常见的分类决定了赋予该对象的类别。若k = 1,则该对象的类别直接由最近的一个节点赋予。在k-NN回归中...
·
K近邻算法介绍
在模式识别领域,K近邻算法是一种用于分类和回归的非参数统计法。在这两种情况下,输入包含特征空间(Feature Space)中的k个最接近的训练样本。
- 在k-NN分类中,输出是一个分类族群。一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小)中最常见的分类决定了赋予该对象的类别。若k = 1,则该对象的类别直接由最近的一个节点赋予。
- 在k-NN回归中,输出是该对象的属性值。该值是其k个最近邻居的值的平均值。
距离指标
- 欧式距离:即两点之间的距离。比较直观,但是有部分值特别大时,结果较差。对稀疏矩阵的处理结果也不好。
- 曼哈顿距离:又叫出租车距离。d = |x2-x1|+|y2-y1|。解决了部分值特别大的问题。
- 夹角余弦距离。解决了以上两个问题,但是会丢失向量长度的一些信息。
加载数据集
import numpy as np
import csv
file="ionosphere.data"
# Size taken from the dataset and is known
X = np.zeros((351, 34), dtype='float')
y = np.zeros((351,), dtype='bool')
with open(file, 'r') as input_file:
reader = csv.reader(input_file)
#索引序列
for i,row in enumerate(reader):
# Get the data, converting each item to a float
data = [float(datum) for datum in row[:-1]]
# Set the appropriate row in our dataset
X[i] = data
# 1 if the class is 'g', 0 otherwise
y[i] = row[-1] == 'g'
print(y)
算法实现
划分数据集
from sklearn.cross_validation import train_test_split
# 划分 训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state = 14)
print("There are {0} samples in the training set.".format(X_train.shape[0]))
print("There are {0} samples in the test set.".format(X_test.shape[0]))
print("Each sample has {0} features.".format(X_test.shape[1]))
模型建立
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier()
estimator.fit(X_train,y_train)
y_predicted = estimator.predict(X_test)
accuracy = np.mean(y_test == y_predicted) * 100
print("The accuracy is {0:.1f}%.".format(accuracy))
交叉验证
from sklearn.cross_validation import cross_val_score
#交叉验证
scores = cross_val_score(estimator,X,y,scoring = 'accuracy')
average_accuracy = np.mean(scores)*100
print("The average accuracy is {0:.1f}%.".format(average_accuracy))
K参数选择
# set the parameters
avg_scores = []
all_scores = []
parameter_values = list(range(1,21))
for n_neighbors in parameter_values:
estimator = KNeighborsClassifier(n_neighbors=n_neighbors)
scores = cross_val_score(estimator,X,y,scoring="accuracy")
avg_scores.append(np.mean(scores))
all_scores.append(scores)
%matplotlib inline
from matplotlib import pyplot as plt
# plot the relationship between the n_neighbor and the accuracy
plt.figure(figsize=(32,20))
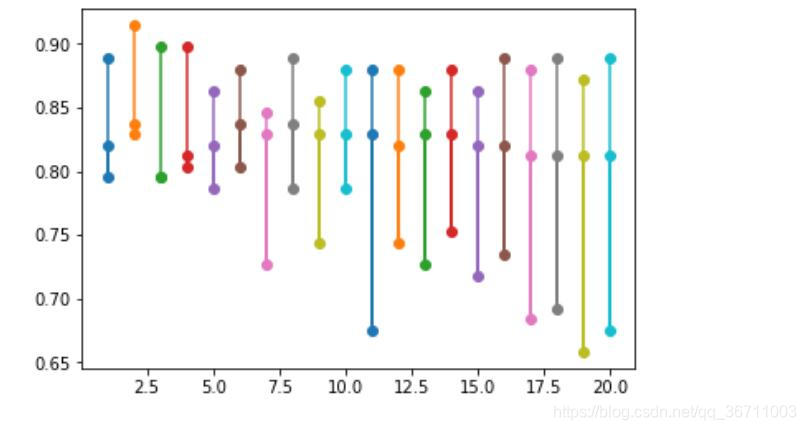
plt.plot(parameter_values,avg_scores,'-o',linewidth=5,markersize = 24)
for parameter,scores in zip(parameter_values,all_scores):
n_scores = len(scores)
plt.plot([parameter]*n_scores,scores,'-o')
标准化预处理
from sklearn.preprocessing import MinMaxScaler
# Normalizer,StandScaler,Binarizer
X_transformed = MinMaxScaler().fit_transform(X_broken)
estimator = KNeighborsClassifier()
transformed_scores = cross_val_score(estimator,X_transformed,y,scoring="accuracy")
print("The transformed average accuracy is {0:.1f}%.".format(np.mean(transformed_scores)*100))
# create your own pipeline
from sklearn.pipeline import Pipeline
scaling_pipeline = Pipeline([('scale',MinMaxScaler()),('predict',KNeighborsClassifier())])
scores = cross_val_score(scaling_pipeline,X_broken,y,scoring="accuracy")
print("The pipeline scored an average accuracy is {0:.1f}%.".format(np.mean(scores)*100))
结果展示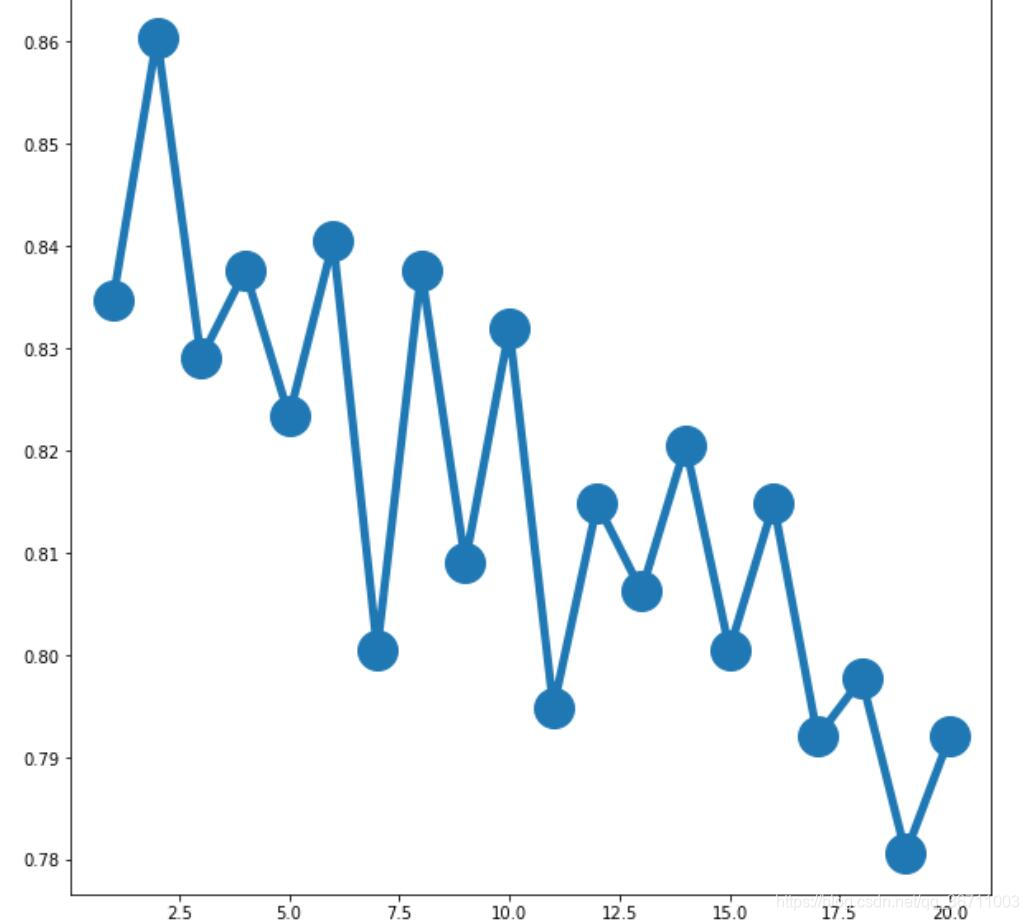

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)