【张同学】使用百度翻译api实现剪映双语字幕自动化
文介绍了使用百度翻译API实现剪映双语字幕自动化的步骤。通过随机选择一个视频流、导入到剪映、使用剪映的语音识别功能生成中文字幕、导出字幕文件、利用Python和百度翻译API进行翻译、替换原来的字幕文件以及将新的双语字幕导入到原视频中,我们可以实现双语字幕的自动化处理。这个方法可以大大提高字幕翻译的效率,为视频制作过程带来便利。
本文将介绍如何利用百度翻译API实现剪映双语字幕自动化的过程。我们将通过随机选择一个视频流,将其导入到剪映,并使用剪映的语音识别功能生成中文字幕。然后,我们将导出这些字幕文件(srt格式),并利用Python和百度翻译API进行翻译。最后,我们将替换原来的字幕文件,并将新的双语字幕导入到原视频中。
一、随机选择一个视频
在这一步,我们选择一个视频流作为示例。
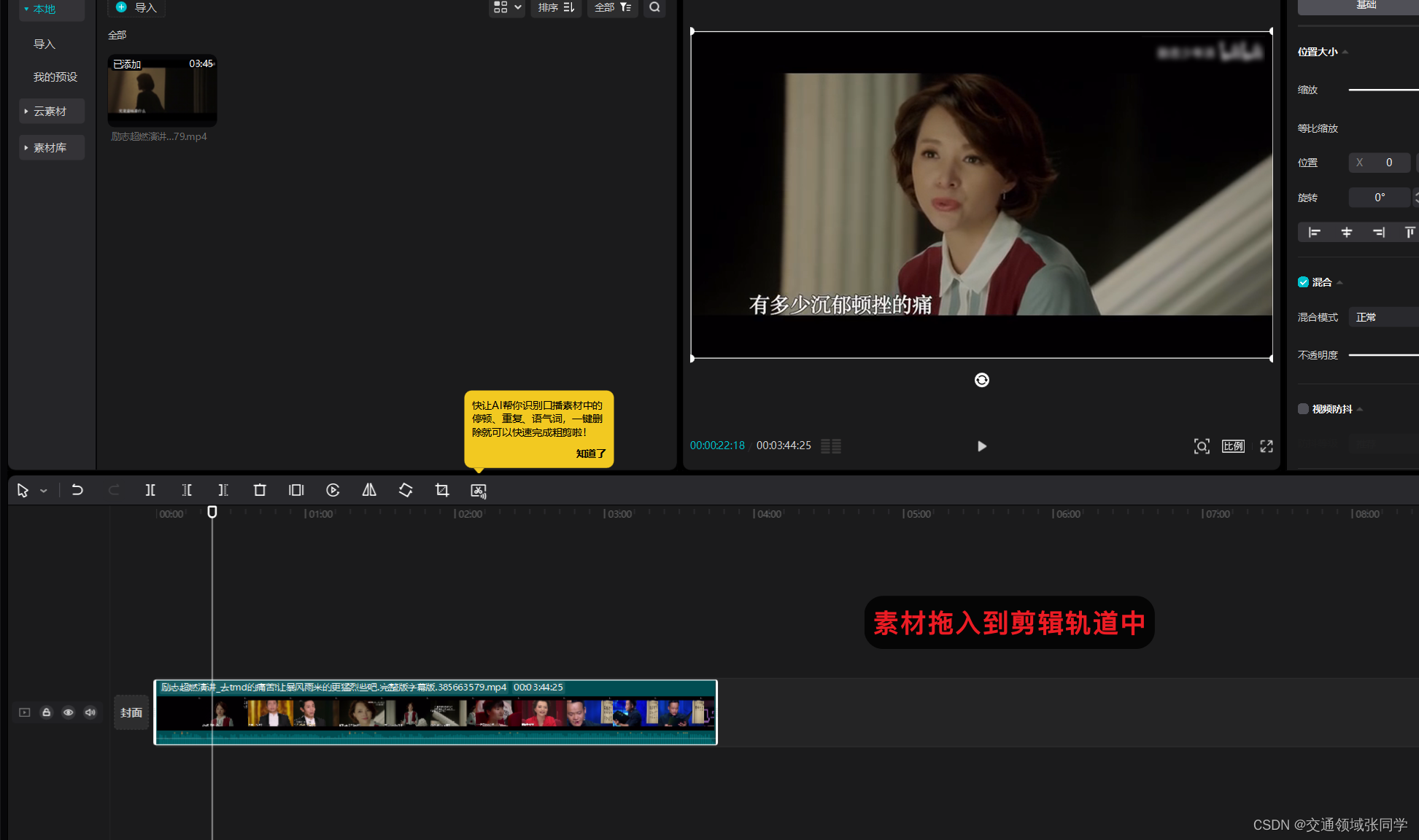
二、导入视频到剪映
将选定的视频导入到剪映软件中,以便后续操作。
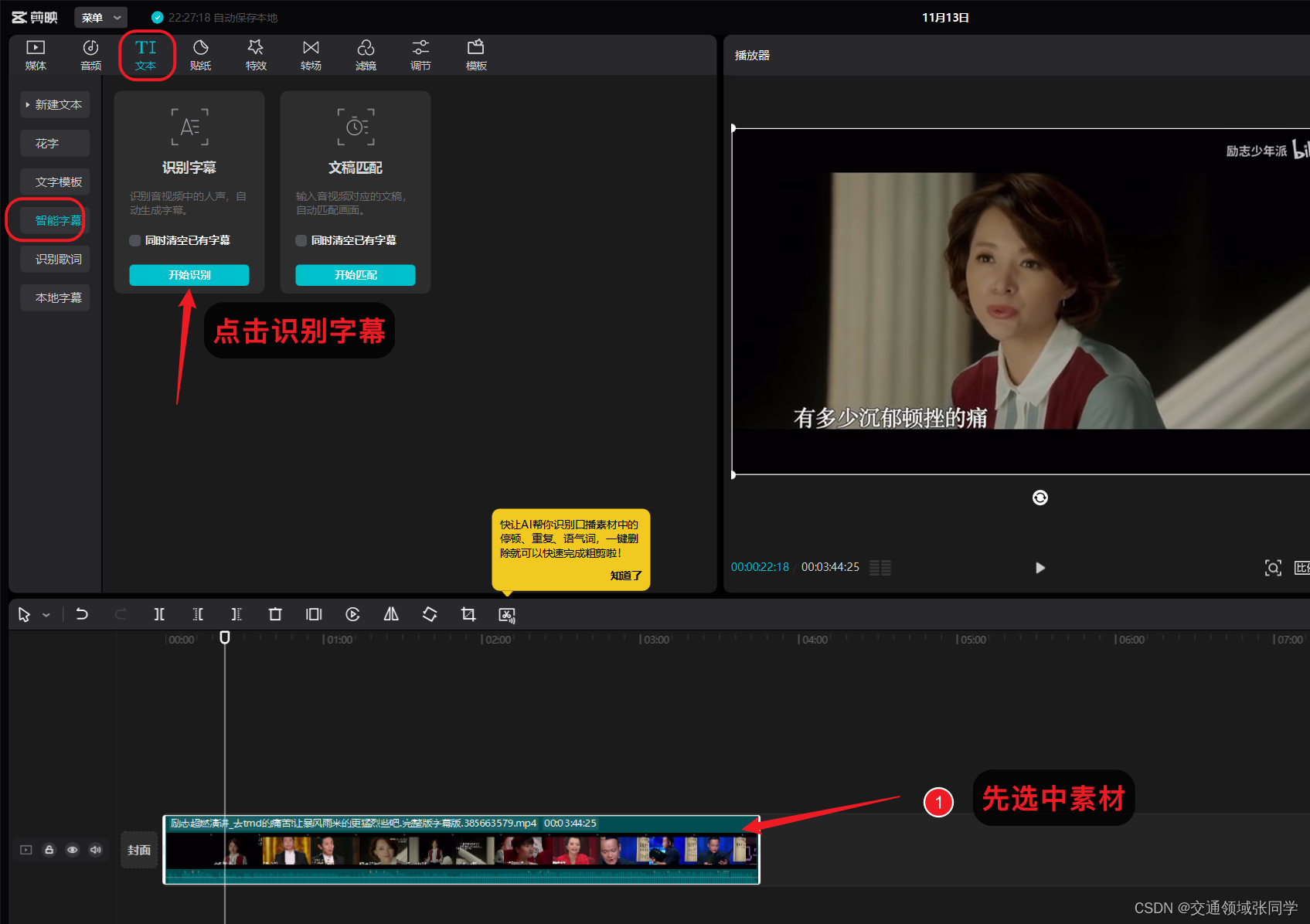
三、使用剪映的语音识别功能生成中文字幕
剪映提供了语音识别功能,可以将视频中的语音内容转换为文字。在这一步,我们需要使用该功能,将视频中的语音转换成中文文字,并生成对应的字幕文件(srt格式)。
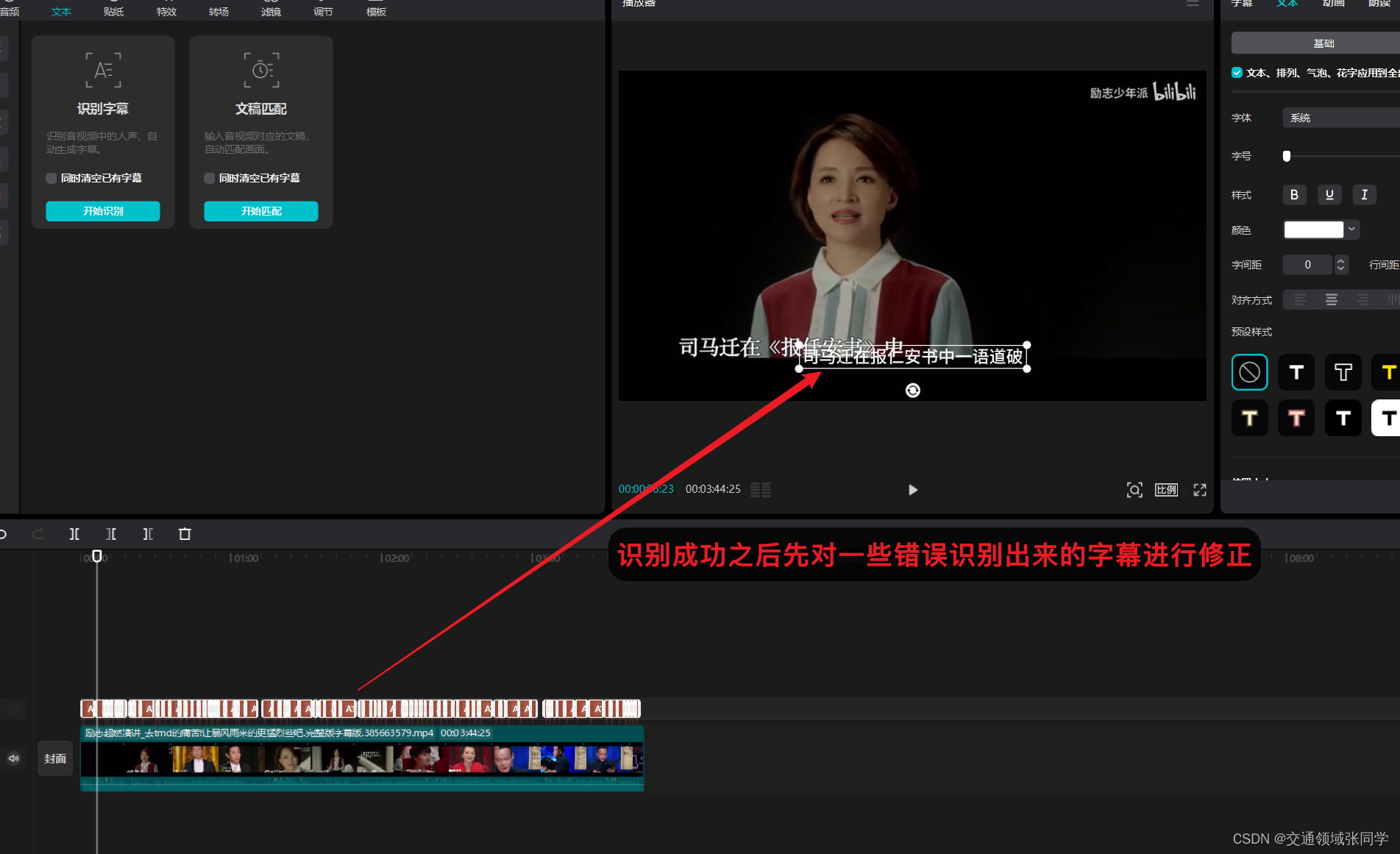
四、导出字幕文件(srt格式)
在剪映中,我们可以选择导出已生成的字幕文件(srt格式),以便后续处理。
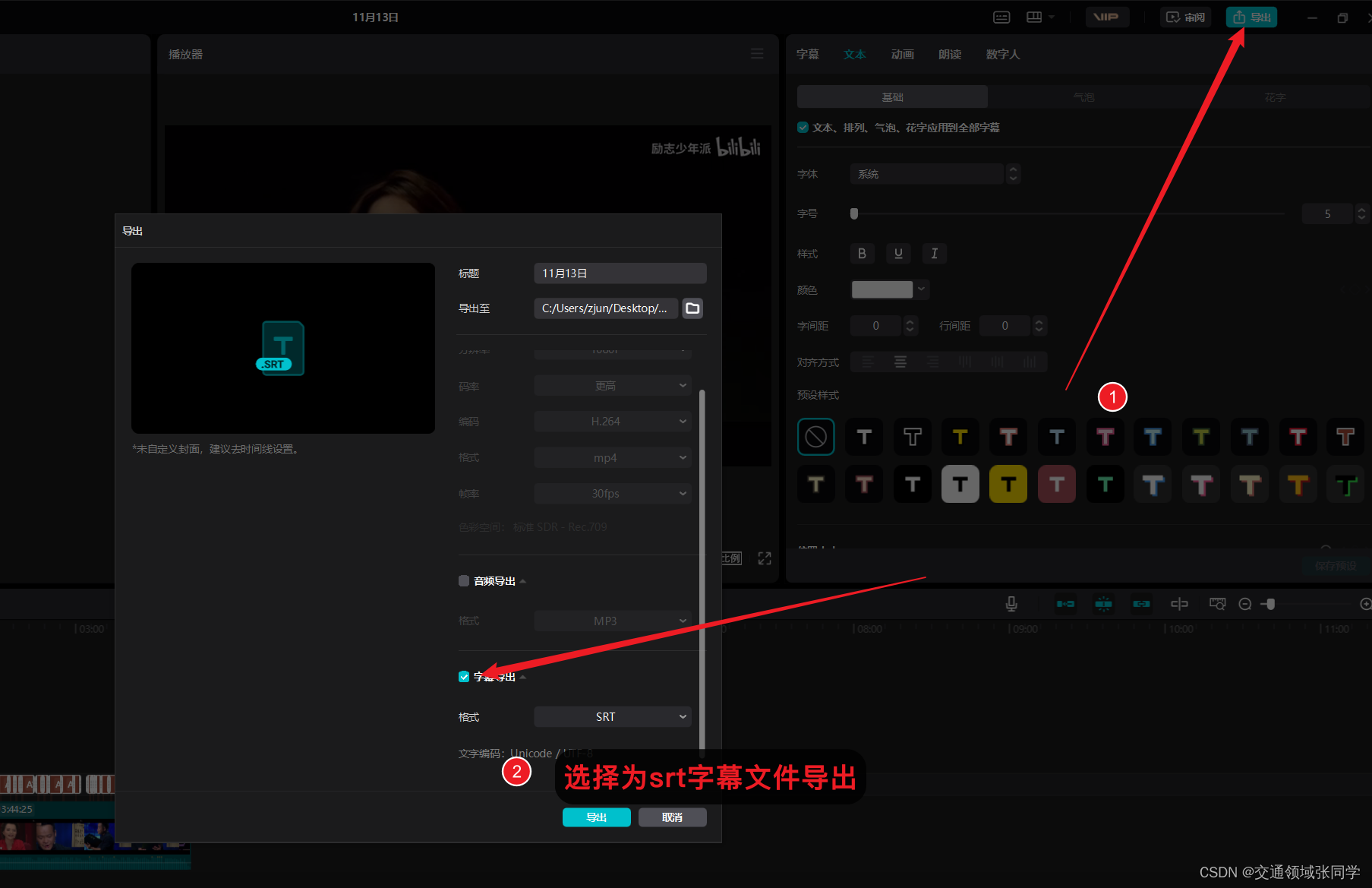
五、使用Python和百度翻译API进行翻译
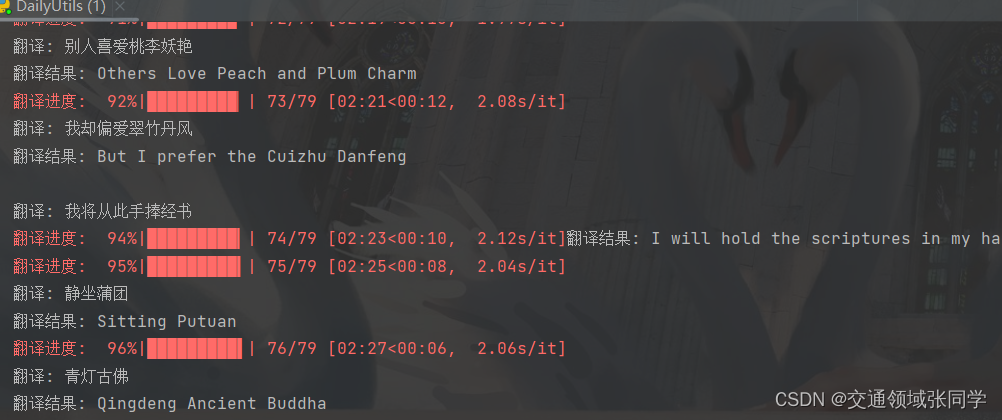
利用Python编程语言和百度翻译API,我们可以将中文字幕翻译成其他语言。首先,我们需要将导出的srt字幕文件读取到Python中,然后调用百度翻译API进行翻译。通过逐行翻译并替换原来的中文字幕,我们可以得到翻译后的字幕文件。
百度翻译api现在提供每个用户每月5万字符的免费额度,只需要去申请就可以了,如果你是自己拍摄vlog的话,够用了,再不行再调用gpt接口来进行翻译,也是免费的,且不限量。
然后我们使用python调用百度翻译api对字幕中的文件进行翻译,代码如下:
def baidu_translate_text(text, from_lang, to_lang):
# 调用翻译接口
import hashlib
import random
import requests
'''
:param text: 待翻译的文本
:param from_lang: 原文本的语言类型
:param to_lang: 目标翻译的语言类型
:return:
'''
# 百度翻译appid和appkey
appid = '这里替换为你的'
appkey = '这里替换为你的'
# 生成随机的salt
salt = random.randint(32768, 65536)
print("\n翻译:",text)
# 计算签名
sign = appid + text + str(salt) + appkey
sign = hashlib.md5(sign.encode()).hexdigest()
# 构建请求URL
url = 'https://fanyi-api.baidu.com/api/trans/vip/translate'
url += '?appid=' + appid
url += '&q=' + requests.utils.quote(text)
url += '&from=' + from_lang
url += '&to=' + to_lang
url += '&salt=' + str(salt)
url += '&sign=' + sign
# 发送请求并获取响应
response = requests.get(url)
result = response.json()
# 提取翻译结果
translation = result['trans_result'][0]['dst']
print("翻译结果:",translation)
return translation然后我们调用一下这个函数对srt进行操作:
# 翻译剪映srt文件
def translate_video_srt(path):
import pysrt
from tqdm import tqdm
import random
import time
'''
:param path: 导出的剪映的srt文件路径
:return: 没有返回值
'''
# 读取 SRT 文件
subs = pysrt.open(path)
# 使用 tqdm 显示进度条
translated_text = [] #存储最终的字幕结果。
with tqdm(total=len(subs), desc="翻译进度") as pbar:
# 遍历每个字幕条目并翻译
for sub in subs:
# 获取原始字幕文本
original_text = sub.text
# 使用 Translate 进行翻译
translation = baidu_translate_text(original_text, from_lang='zh', to_lang='en')
# 拼接翻译后的文本与原文本
translated_text.append(f"{original_text}\n{translation}")
# 生成随机的等待时间(0.5秒至1秒之间)
wait_time = random.uniform(1, 2)
time.sleep(wait_time)
pbar.update(1) # 更新进度条
# 遍历每个字幕条目,用列表中的内容进行替换
for i, sub in enumerate(subs):
if i < len(translated_text):
# 使用列表中的文本替换字幕文本
sub.text = translated_text[i]
else:
# 如果列表中的文本用完了,可以选择删除多余的字幕条目
subs.delete(i)
# 保存并拼接翻译后的字幕到新的 SRT 文件
print(subs.text)
subs.save('translated_subtitle.srt')
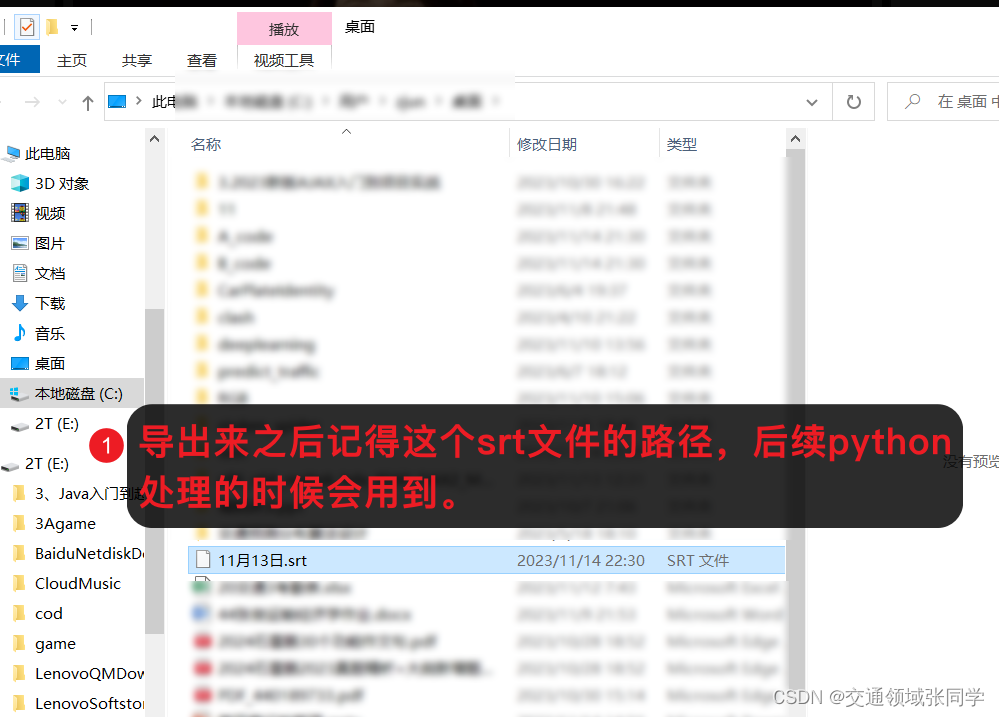
translate_video_srt(r"C:\Users\zjun\Desktop\11月13日.srt")至此,原来的srt文件已经被我们修改成新的双语字幕了。
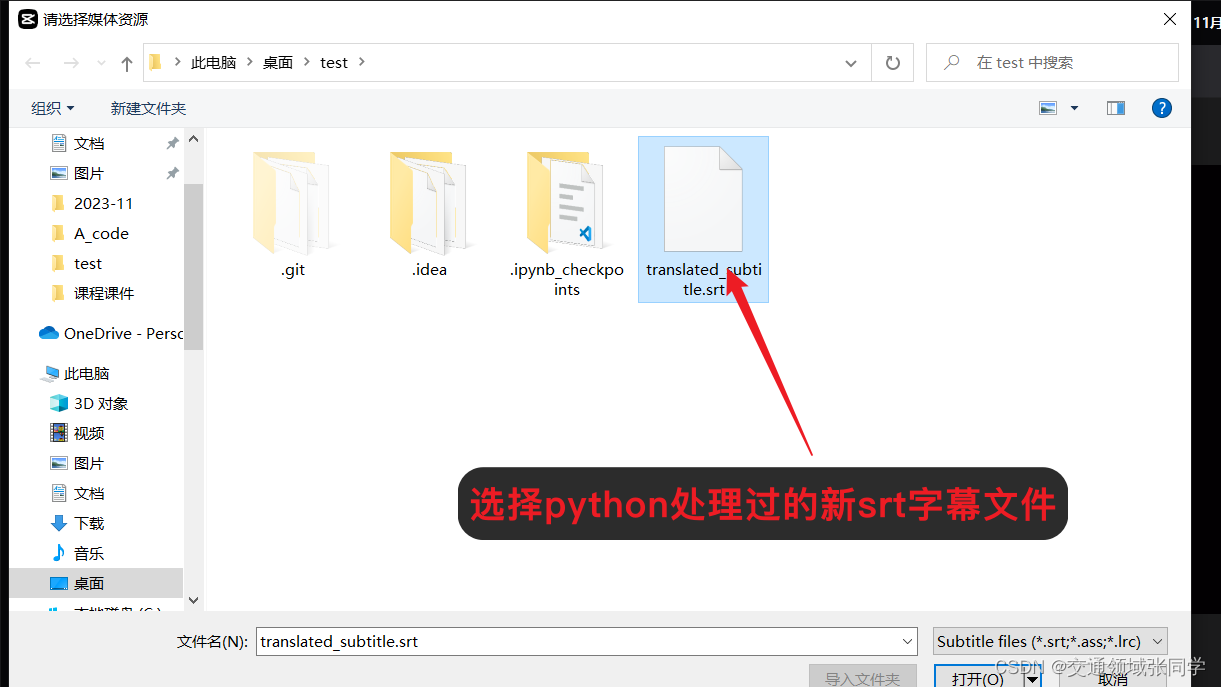
六、替换原来的字幕文件
在这一步,我们将翻译后的字幕文件替换原来的中文字幕文件。通过将翻译后的字幕文件保存为与原文件同名的文件,我们可以实现替换操作。
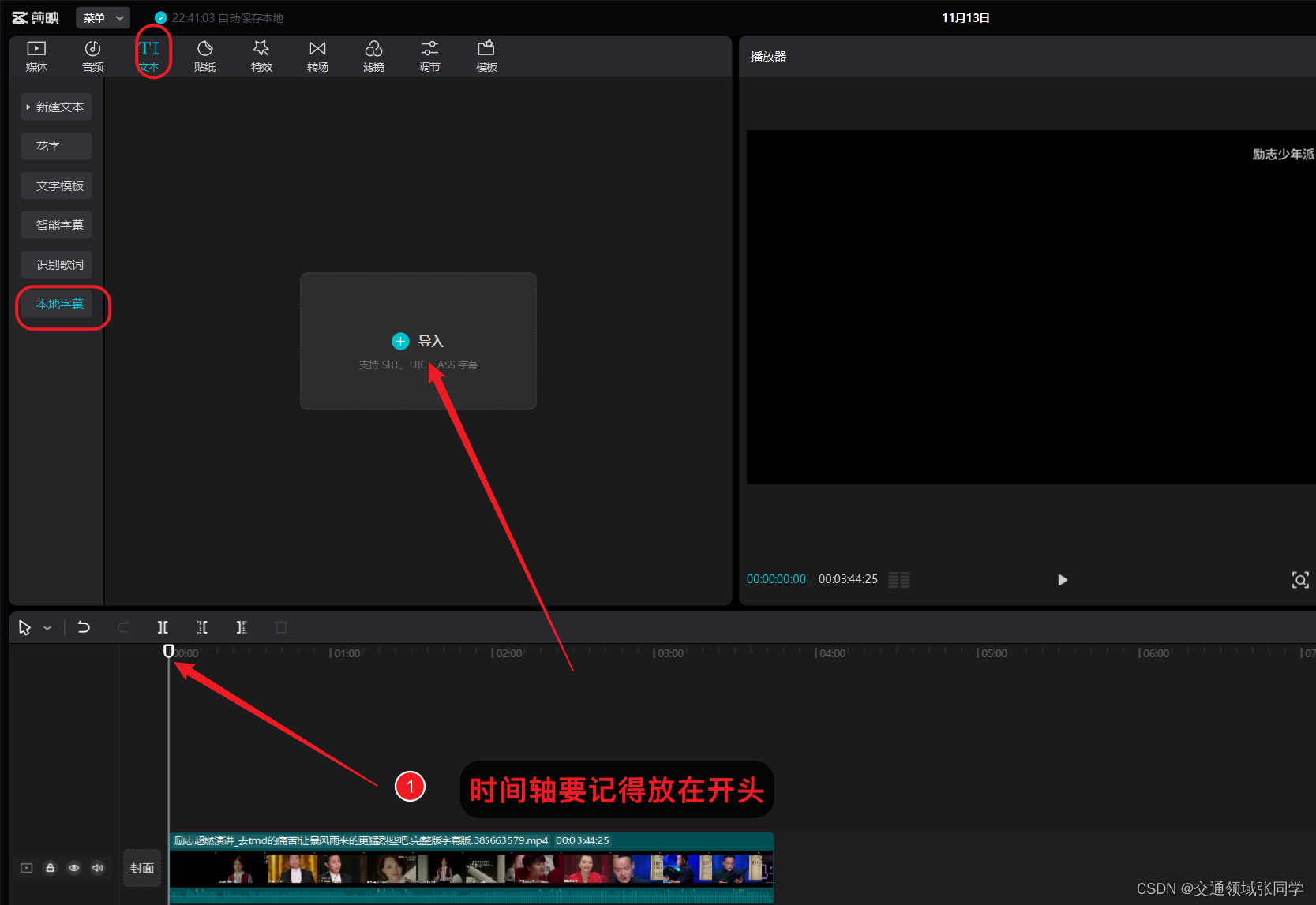
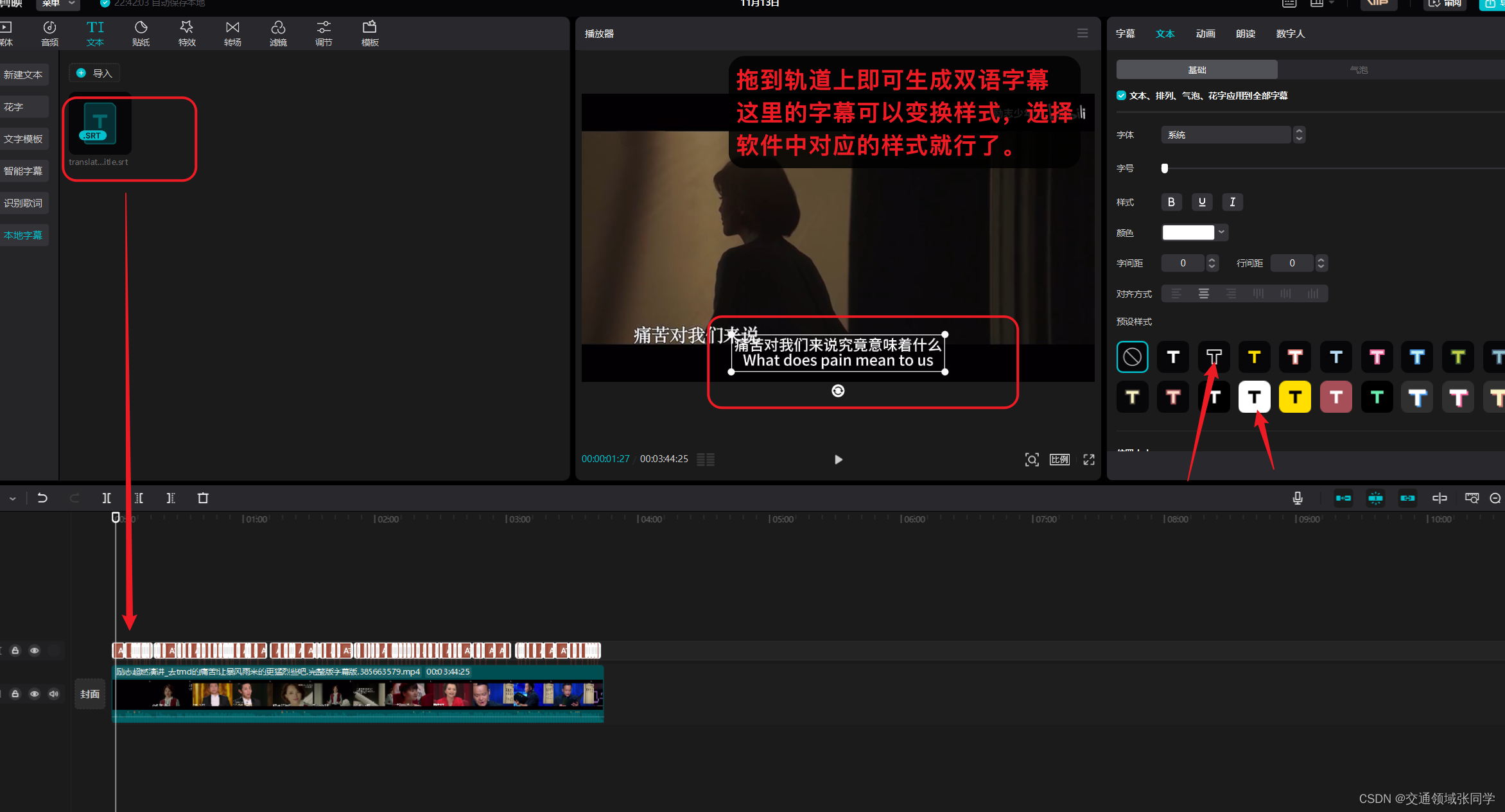
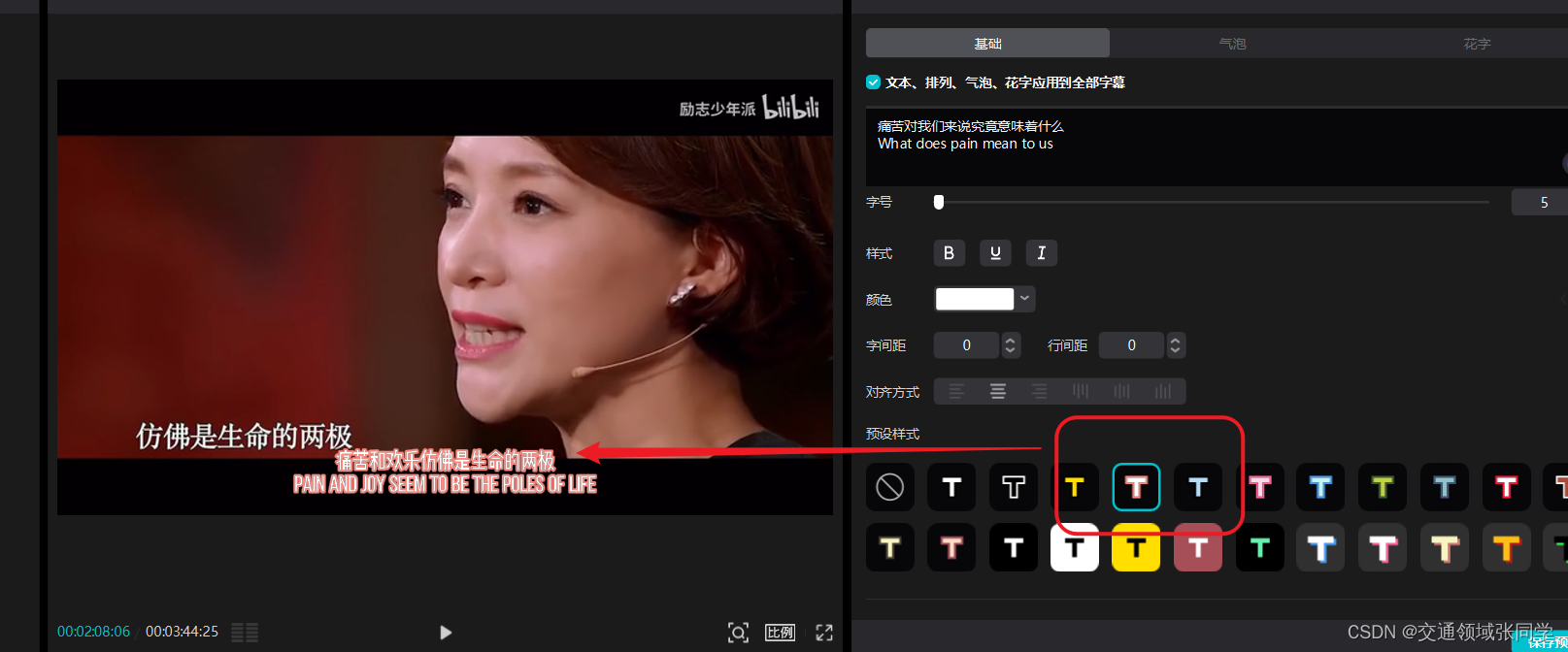
七、将新的双语字幕导入到原视频中
最后一步是将翻译后的字幕文件导入到原视频中。我们可以使用剪映软件,将新的字幕文件与原视频进行合并,以实现双语字幕的效果。
总结
本文介绍了使用百度翻译API实现剪映双语字幕自动化的步骤。通过随机选择一个视频流、导入到剪映、使用剪映的语音识别功能生成中文字幕、导出字幕文件、利用Python和百度翻译API进行翻译、替换原来的字幕文件以及将新的双语字幕导入到原视频中,我们可以实现双语字幕的自动化处理。这个方法可以大大提高字幕翻译的效率,为视频制作过程带来便利。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)