【Java SE】IO流
模块化开发:Manager SellerEntity APIUtil Quarts Swaggerbuild.gradle每个Model生成时,会自动在各Model下生成一个 build.gradle,定义单个Model下的配置;而根目录下的 build.gradle可以统一管理各个Model;可以把各Model下的gradle文件清空;添加一个Model,比如util...
笔记
————————
JDK 8 新特性
bufferedReader.lines() 表示的数据是:Stream<String>
怎么把它改成List<String>?bufferedReader.lines().collect(Collectors.toList());
————————
————————
————————
————————
————————
————————
——————————————————————————————————
File
File是个抽象含义,File实例化了不代表文件就存在;
File是JVM通过操作系统和硬盘建立联系的,并不会直接联系;
————————
方法总结:
-
writer.createNewFile()
创建新文件; -
read()
读每个字 -
readLine()
读每一行;(易错!特别是“复制”功能时:读一行之后就分行写,如果选成了read(),那么每个字都会分行;) -
``
-
``
-
``
-
``
————————
Buffered部分:
Writer.write()
写数据,把流全部重新输入;Writer.append()
写数据,但是保留原有数据,在后面追加;writer.newLine()
换新行;writer.flush()(注意!是write要强制输出,不是read!)
强制刷新IO缓冲(强制把缓冲里的数据写入流);因为缓冲区中的数据要等到缓冲区满后才写出,我们可以显示调用flush将缓冲区中的数据强制写出或使用;writer.close()
关闭流;会自动调用.flush()功能(强制刷新IO缓冲);关闭流之前,缓冲输出流将缓冲区数据一次性写出;
———————————————————- 提问:怎么在IDEA中用File读取相对路径?

public class Test {
public static void main(String[] args){
File src = new File(Test.class.getClass().getResource("/Hello.txt").getPath());
———————————————————
- 提问:如何拼接绝对路径?
1.直接写;(最常用)
2.用File.separatoeChar常量拼接;(也会见到)
String path1 = "/Users/XXXX/Desktop/hello.txt";
System.out.println(path1);
String path2 = File.separatorChar + "Users" + File.separatorChar + "XXXX" + File.separatorChar + "Desktop" +File.separatorChar + "hello.txt";
System.out.println(path2);
———————————————————
输出:
/Users/XXXX/Desktop/hello.txt
/Users/XXXX/Desktop/hello.txt
———————————————————
构建File对象
File src = new File(path);
———————————————————src.exists()判断文件是否存在;src.isFile()判断资源是文件还是文件夹;
File src = new File("haha");
if (src == null || !src.exists()){
System.out.println("文件不存在");
}
if (src.isFile()){
System.out.println("这是文件");
}else{
System.out.println("这是文件夹");
}
———————————————————
输出:
文件不存在
这是文件夹
———————————————————src.length() 资源的字节长度
(区分格式:String的str.length();数组的arr.length)
———————————————————src.createNewFile() 新建文件src.delete() 删除已存在的文件
一定要指定文件后缀,否则不会成功;
抛出IOException;
public void test1() throws IOException {
File src = new File("/Users/XXXX/Desktop/new.txt");
src.createNewFile();
src.delete();
}
———————————————————
创建文件夹 Make Directory
创建文件夹的逻辑在于:指定的父路径存不存在,所以有两种方法:
mkdir() 父路径必须存在,否则本次创建失败;mkdirs()父路径无所谓存不存在,不存在即顺便创建父路径;
返回一个boolean值;
比如:我想创建Test文件夹,但是他的父路径Folder文件夹不存在,用mkdir()
File src = new File("/Users/XXXX/Desktop/Folder/Test");
boolean flag = src.mkdir();
System.out.println(flag);
———————————————————
输出:
false
改成mkdirs()试试:
File src = new File("/Users/XXXX/Desktop/Folder/Test");
boolean flag = src.mkdirs();
System.out.println(flag);
———————————————————
输出:
true
———————————————————.list 返回下级的所有 文件名(String),用String集合接收;.listFile 返回下级所有 文件路径(File),用File集合接收;
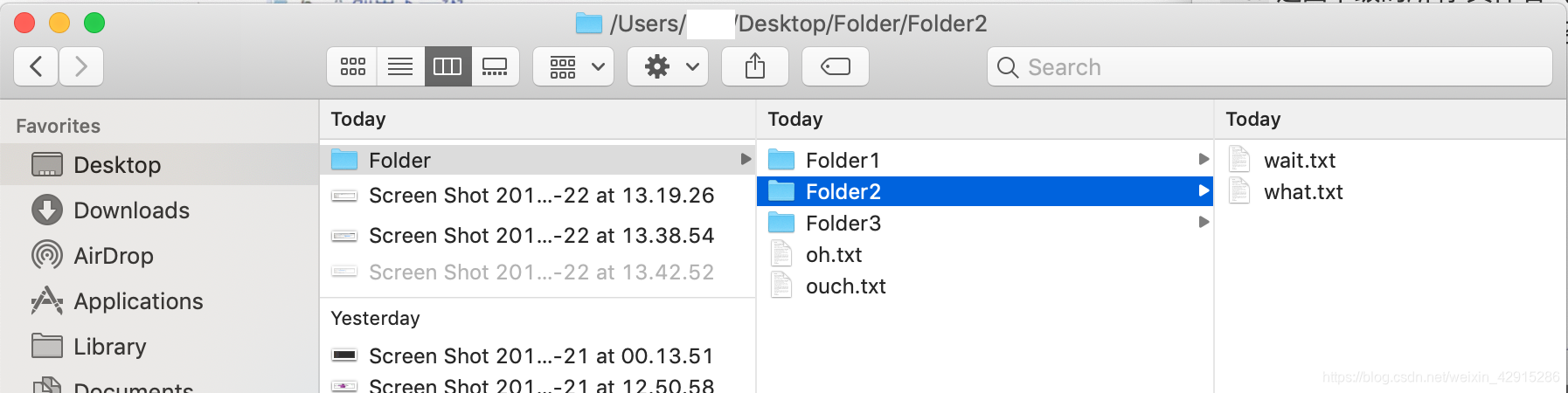
File dir = new File("/Users/XXXX/Desktop/Folder");
String[] subNames = dir.list();
for (String sub:subNames){
System.out.println(sub);
}
———————————————————
输出:
Folder1
Folder2
Folder3
oh.txt
ouch.txt
File dir = new File("/Users/XXXX/Desktop/Folder");
File[] subFiles = dir.listFiles();
for (File sub2:subFiles){
System.out.println(sub2);
}
———————————————————
输出:
/Users/XXXX/Desktop/Folder/Folder1
/Users/XXXX/Desktop/Folder/Folder2
/Users/XXXX/Desktop/Folder/Folder3
/Users/XXXX/Desktop/Folder/oh.txt
/Users/XXXX/Desktop/Folder/ouch.txt
那么怎么列出路径下所有子路径里的文件?
递归;
public class Test {
public static void main(String[] args) {
File dir = new File("/Users/chiu/Desktop/Folder");
printName(dir);
}
public static void printName(File src){
// for (int i=0 ; i<layer ; i++){
// System.out.println("-");
// }
System.out.println(src.getName());
if (src == null || !src.exists()){
return;
}else if (src.isDirectory()){
for (File s:src.listFiles()){
printName(s);
}
}
}
}
———————————————————
输出:
Folder
Folder2
what.txt
wait.txt
Folder3
oh.txt
ouch.txt
Folder1
如何有层次感?https://www.bilibili.com/video/av31433959/?p=5
———————————————————
File 编码字符
| 字符集 | 说明 |
|---|---|
| US-ASCII | 英文的ASCII |
| ISO-8859-1 | Latin-1 拉丁字符,包括中文、日文 |
| UTF-8 | 变长UNICODE字符(1-3字符),国际通用 |
| UTF-16BE | |
| UTF-16LE | |
| UTF-16 |
——————————————————————————————
四大抽象类
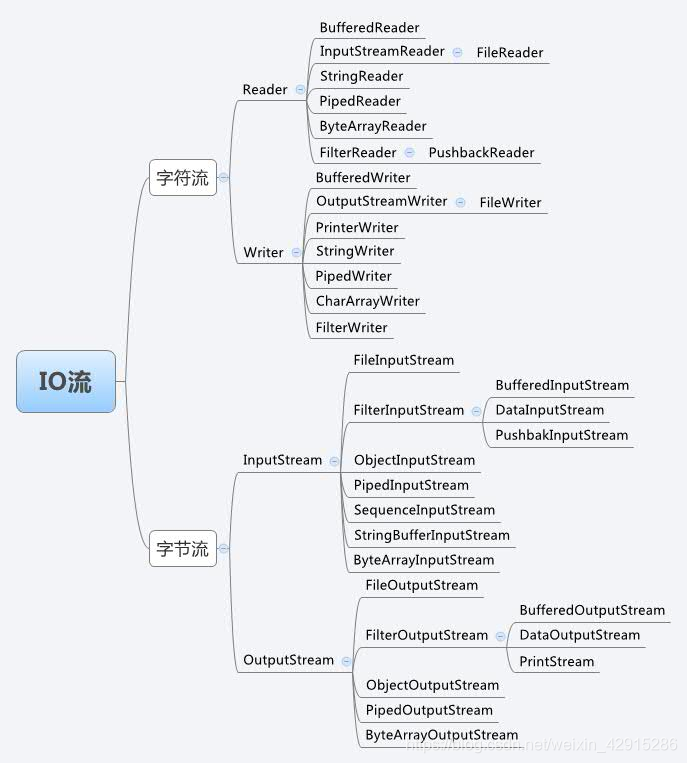
字符流都可以用字节流处理;
但字节流不一定能用字符流处理;
四个抽象类:
| 抽象类 | 常用方法 | |
|---|---|---|
| InputStream | int read() void close() | |
| OutputStream | void write(int) void flush() void close() | |
| Reader | int read() void close() | |
| Writer | void write(String) void flush() void close() |
———————————————————
标准写法(InputStream)
使用步骤:
1.创建流
2.选择源
3.操作
4.释放资源
.read()读到不存在的字符时(空格算字符),输出-1;
所以可以用-1作为判断文件内容有没有读取万的标志;
标准写法:
Resources下有个文件:Hello.txt
内容为:hello sxt hahaha
读取该文件的所有信息:
File src = new File("/Users/XXXX/Documents/IdeaProjects/springbootdemo/sb_test/src/main/resources/Hello.txt");
InputStream is = null; // 为什么InputStream实例化要分开写,因为finally中要关闭InputStream,写在try无法操作
try {
is = new FileInputStream(src);
int temp;
while((temp=is.read()) != -1){
System.out.println((char)temp); // 必须强转,因为用的是字节流,否则会输出数字
}
} catch (FileNotFoundException e) {
e.printStackTrace(); // new FileInoutStream()抛出
} catch (IOException e) {
e.printStackTrace(); // .read()抛出
} finally{
if (is != null){ //避免没读取到文件,空指针异常
try {
is.close();
} catch (IOException e) {
e.printStackTrace(); // .close()抛出
}
}
}
输出:
h
e
l
l
o
s
x
t
h
a
h
a
h
a
———————————————————
InputStream
实际情况中,分段读取更为合理;
文件内容改为:
hello,it's been long time,how's everything?
要求:每5个字符读取一次
(只改动了try块中的内容)
一次读取5个,到最后只剩下3个字符:ng?
File src = new File("/Users/chiu/Documents/IdeaProjects/springbootdemo/sb_test/src/main/resources/Hello.txt");
InputStream is = null;
try {
is = new FileInputStream(src);
byte[] car = new byte[5]; // 缓冲容器
int len = -1;
while((len=is.read(car)) != -1){
String str = new String(car,0,len);
System.out.println(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally{
if (is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
———————————————————
OutputStream
要求:生成一个原本不存在的文件,写一句话进去;
// 指向一个不存在的文件,要程序帮我创建
File src = new File("/Users/chiu/Documents/IdeaProjects/springbootdemo/sb_test/src/main/resources/Oh?.txt");
OutputStream os = null;
try {
os = new FileOutputStream(src);
String msg = "New Output here";
byte[] datas = msg.getBytes();
os.write(datas,0,datas.length);
os.flush(); // 刷新流,强制任何缓冲的输出字节被写出
} catch (IOException e) {
e.printStackTrace();
} finally{
if (os != null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
怎么区分append追加和覆盖?
os = new FileOutputStream(src,true); // append内容
os = new FileOutputStream(src,false); // 覆盖内容
怎么实现追加内容的换行?
String msg = "新内容 \r\n";
———————————————————
文件拷贝 InputStream + OutputStream
文件拷贝逻辑:
把Hello的内容复制到Oh?里去(覆盖);
(注意主要写了数据,就要带上flush(),这是好习惯)
(注意两个流都要关闭:先实例化的后关闭)
File src = new File("/Users/。。。/Hello.txt");
File dest = new File("/Users/。。。/Oh?.txt");
InputStream is = null;
OutputStream os = null;
try {
is = new FileInputStream(src);
os = new FileOutputStream(dest);
byte[] flush = new byte[1024*1]; //每次读取1K
int len = -1;
while((len=is.read(flush)) != -1){
os.write(flush,0,len);
}
os.flush();
} catch (IOException e) {
e.printStackTrace();
} finally{
if (os != null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
那么复制图片呢?
字节流一样能做到;
要求:复制图片;而且把流的逻辑变成一个方法,在另一个方法中引用该方法,写两个路径即可;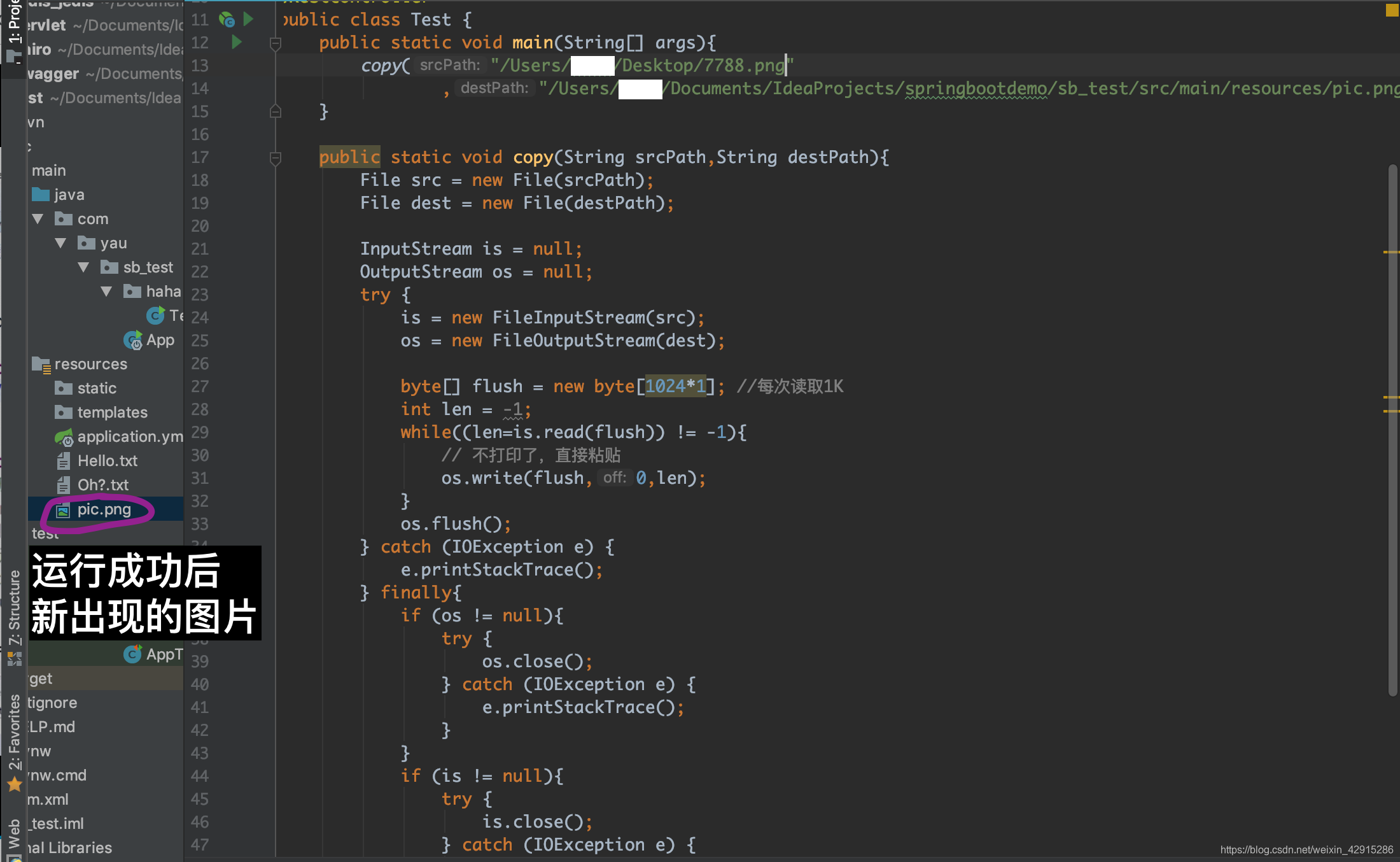
———————————————————
Reader
Reader和Writer仅适合处理文字,不要处理其他文件,比如视频、图片…
对于文字的传输,官方更推荐用Reader和Writer;
他们也不会出现中文乱码问题;
用字符流读取指定文件数据;
File src = new File("/Users/.../Hello.txt");
Reader reader = null;
try {
reader = new FileReader(src);
char[] flush = new char[1024];
int len = -1;
while((len = reader.read(flush)) != -1){
String str = new String(flush,0,len);
System.out.println(str);
}
} catch (IOException e) {
e.printStackTrace();
} finally{
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
———————————————————
输出:
hello,it's been long time,how's everything?
———————————————————
Writer
Reader和Writer仅适合处理文字,不要处理其他文件,比如视频、图片…
append一行中文数据:
File src = new File("/Users/.../Hello.txt");
Writer writer = null;
try {
writer = new FileWriter(src,true);
String msg = "新增中文数据\r\n";
writer.write(msg);
writer.write(...);
writer.flush();
。。。
writer.close();
}
或更灵活地append
File src = new File("/Users/.../Hello.txt");
Writer writer = null;
try {
writer = new FileWriter(src);
String msg = "新增中文数据\r\n";
writer.append(msg).append(...);
writer.flush();
。。。
writer.close();
}
——————————————————————————————
字节缓冲流
IO是影响程序性能的一个瓶颈,读取数据量大的文件时,读取的速度会很慢,很影响我们程序的效率;
Java中提高了一套缓冲流,它的存在,可提高IO流的读写速度;
如何释放流?
按道理,应该从里到外释放流,释放FileInputStream(自动释放内部的节点流),再释放BufferedInputStream;但是在这里,直接释放BufferedInputStream就够了;
重点有三:
1.缓冲流提升了性能;
2.流无论怎么嵌套,最底层一定是一个节点流;
3.释放时,只需要释放一个最外层即可(若想手动一个个释放,需要按照从里到外顺序释放);
———————————————————
BufferedInputStream
File src = new File("/Users/.../Hello.txt");
InputStream is = null;
try {
is = new BufferedInputStream(new FileInputStream(src));
byte[] flush = new byte[1024];
int len = -1;
while((len=is.read(flush)) != -1){
String str = new String(flush,0,len);
System.out.println(str);
}
} catch (IOException e) {
e.printStackTrace();
}finally{
if (is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
———————————————————
BufferedOutputStream
File src = new File("/Users/.../Hello.txt");
OutputStream os = null;
try {
os = new BufferedOutputStream(new FileOutputStream(src,true));
String msg = "lalala\r\n";
byte[] datas = msg.getBytes();
os.write(datas,0,datas.length);
os.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (os != null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
——————————————————————————————
字符缓冲流
读取数据量大的文件时,读取的速度会很慢,很影响我们程序的效率;
Java中提高了一套缓冲流,它的存在,可提高IO流的读写速度;
———————————————————
—————————
创建文件,并且用BufferedWriter在文件中写数据;
具体:
创建两个文件,在第一个文件中写几行文字;
File file1 = new File("/Users/xxxx/Desktop/haha1");
File file2 = new File("/Users/xxxx/Desktop/haha2");
try {
file1.createNewFile();
file2.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
Path path1 = Paths.get(file1.getPath());
try {
BufferedWriter writer1 = Files.newBufferedWriter(path1);
writer1.write("天天想你,天天守住一颗心");
writer1.newLine();
writer1.write("把我最好的爱留给你");
writer1.newLine();
writer1.write("当我伫立在窗前");
writer1.newLine();
writer1.write("当我徘徊在深夜");
writer1.newLine();
writer1.write("隐隐约约,闪动的双眼");
writer1.flush();
writer1.close();
} catch (IOException e) {
e.printStackTrace();
}
文件1:
天天想你,天天守住一颗心
把我最好的爱留给你
当我伫立在窗前
当我徘徊在深夜
隐隐约约,闪动的双眼
—————————
用BufferedReader和BufferedWriter在两个文件间复制粘贴文字;
前提:文件1有内容,文件2无内容;
复制文件1全部内容到文件2;
版本1和版本2的区别是:
前者用String记录路径,Paths.get(str);
后者用File记录路径,Paths.get(file.getPath());
个人认为版本1更简化;
版本1:
String str1 = "/Users/xxxx/Desktop/haha1";
String str2 = "/Users/xxxx/Desktop/haha2";
Path path1 = Paths.get(str1);
Path path2 = Paths.get(str2);
try {
BufferedReader reader = Files.newBufferedReader(path1);
BufferedWriter writer = Files.newBufferedWriter(path2);
//line = reader.readLine(); 判断条件不能写在这里,否则成了定值!!!
String line = null;
while((line = reader.readLine()) != null){
writer.append(line); // 易错处(另外,若要JSON序列化,就写在这里)
writer.newLine();
}
writer.flush();
writer.close();
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
有几个重大易错点!!!
-
1.我们要遍历文件1的每一行,所以用while判断
newLine()是不是空,下一行为空时表示复制结束;
判断条件(line = reader.readLine()) != null一定要写在while判断中,不能写在外部(比如10行)!! 写在外部表示是一个定值,程序会无穷无尽地复制文件1的第一句话到文件2,程序不会换行复制,造成灾难!!! -
2.Writer读取“行”要用
.readLine();不能用.read();后者表示逐字读取,加上读取后有空行操作,那么文件2得到的结果是一个字一行,造成灾难; -
3.区分
.write()和.append()!!!
版本2:
File file1 = new File("/Users/chiu/Desktop/haha1");
File file2 = new File("/Users/chiu/Desktop/haha2");
Path path1 = Paths.get(file1.getPath());
Path path2 = Paths.get(file2.getPath());
String line = null;
try {
BufferedReader reader = Files.newBufferedReader(path1);
BufferedWriter writer = Files.newBufferedWriter(path2);
//line = reader.readLine(); 判断条件不能写在这里,否则成了定值!!!
while((line = reader.readLine()) != null){
writer.append(line); // 易错处
writer.newLine();
}
writer.flush();
reader.close();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
—————————
———————————————————
BufferedReader
File src = new File("/Users/.../Hello.txt");
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(src));
String line = null;
while((line=reader.readLine()) != null){
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
} finally{
if (reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
———————————————————
BufferedWriter
老版本(不推荐)
File src = new File("/Users/.../Hello.txt");
BufferedWriter writer = null;
try {
writer = new BufferedWriter(new FileWriter(src,true));
writer.newLine();
writer.append("it's ok.");
writer.newLine();
writer.append("and it's fine.");
writer.flush();
} catch (IOException e) {
e.printStackTrace();
} finally{
if (writer != null){
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
新版本(推荐):
把一个集合比如List<AdPlanTable> tableList数据写进本地文件;(且JSON序列化)
Path path = Paths.get(“本地路径”);
BufferedWriter writer = Files.newBufferedWriter(path); //try块 抛出IOException
for(AdPlanTable t:tableList){
writer.write(JSON.toJSONString(t));
writer.newLine();
}
writer.close();
catch IOException
———————————————————
Copy
File src = new File("/Users/.../Hello.txt");
File dest = new File("/Users/.../Oh?.txt");
try {
BufferedReader br = new BufferedReader(new FileReader(src));
BufferedWriter bw = new BufferedWriter(new FileWriter(dest,true));
String line = null;
while((line = br.readLine()) != null){
bw.write(line);
bw.newLine();
}
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
——————————————————————————————
转换流
InputStreamReader / InputStreamWriter
作用:是字节流和字符流之间的桥梁;
把字节流转换成字符流,并且可以为字节流指定字符集,可处理一个个的字符;
- 提问:既然结果要的是字符流,为什么要“多此一举”,用字节流来处理?
之前说过,因为字节流能处理大多数数据,包括:文本、图片、视频、音频等等;
所以大多数系统、框架底层返回的数据都是字节流;
而拿到数据后怎么处理,是程序员自己的事;
所以,一旦我们知道系统传来的是纯文本,那么我们可得知:接收到的肯定是字节流,然后再手动转成字符流;
(特别是加了BufferedXXX后,逐行读取、逐行写出是很方便的)
(比如System.in:字节输入流;System.in:字节输出流)
从 字节 -> 字符:解码;
解码的过程中,若源头字符集和本地字符集不匹配,就会出现乱码;
所以我们最好指定解码后的字符集,InputStreamReader / InputStreamWriter 操作过程中就可以指定字符集;
使用转换流的要点:
1.我们知道系统传来的数据是纯文本;(非纯文本?转换流无法处理)
2.我们可以指定字符集;
—————————————————
InputStreamReader / InputStreamWriter
————————————
作用一:把纯文本的字节流 转换成 字符流
try{
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in,"utf-8"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));
//循环获取键盘的输入(exit退出),输出内容
String msg = "";
while( !msg.equals("exit")){
msg = reader.readLine();
writer.write(msg);
writer.newLine();
writer.flush();
}
}catch(Exception e){
System.out.println("操作异常");
}

注意事项:System.in以字节流读取 System.out以字节流输出;
这么做,一定要输出纯文本;


————————————
作用二:指定字符集
try(BufferedReader reader = new BufferedReader(new InputStreamReader(new URL("http://www.soso.com/").openStream(),"utf-8"));){
String msg = null;
if ((msg = reader.readLine()) != null){
System.out.println(msg);
}
}catch(Exception e){
System.out.println("操作异常");
}
————————————
—————————————————
数据流
https://www.bilibili.com/video/av31433959/?p=19
DataInputStream / DataOutputStream
————————————
————————————
—————————————————
对象流
为什么要了解他?我们每天用到的System.out.println()就是打印流;
—————————————————
打印流
——————————————————————————————
——————————————————————————————
——————————————————————————————
——————————————————————————————
提问:
————————————
- 提问:Java中有几种类型的流?
字节流:
InputStream
OutputStream
字符流:
Reader
Writer
————————————
- 提问:说说Java IO里面的常见类、接口、方法阻塞
常见类:
抽象类如上;
接口:
Closeable, Flushable, Appendable
方法阻塞:read() readLine()
————————————
- 提问:字符流和字节流有什么区别?
计算机中的一切最终都是二进制的字节形式存在。
对于中文字符,首先要得到其对应的字节,然后将字节写入到输出流。读取时,首先读到的是字节,可是我们要把它显示为字符,我们需要将字节转换成字符。由于这样的需求很广泛,人家专门提供了字符流的包装类。
底层设备永远只接受字节数据,有时候要写字符串到底层设备,需要将字符串转成字节再进行写入。字符流是字节流的包装,字符流则是直接接受字符串,它内部将串转成字节,再写入底层设备,这为我们向IO设别写入或读取字符串提供了一点点方便;
————————————
- 提问:讲讲NIO
————————————
- 提问:怎么递归读取文件夹的文件?
File[] files = new File(path).listFiles();
if (files == null) {
return;
}
for(File file : files) {
if (file.isFile()) {
System.out.println(file.getName());
} else if (file.isDirectory()) {
System.out.println("Directory:"+file.getName());
listFile(file.getPath());
} else {
System.out.println("Error");
}
}
————————————
- **提问:什么是节点流,什么是处理流,它们各有什么用处,处理流的创建有什么特征
**
节点流 直接与数据源相连,用于输入或者输出
处理流:在节点流的基础上对之进行加工,进行一些功能的扩展
处理流的构造器必须要 传入节点流的子类
————————————
- 提问:如果在对象序列化的时候不想给一个字段的数据保存在硬盘上面,采用那个关键字?
transient关键字
————————————
- 提问:InputStream里的
read()返回的是什么,read(byte[] data)是什么意思,返回的是什么值
返回的是所读取的字节的int型(范围0-255)
read(byte [ ] data)将读取的字节储存在这个数组
返回的就是传入数组参数个数;
Read 字节读取字节 字符读取字符;
————————————
- 提问:请问你在什么情况下会在你得java代码中使用可序列化? 如何实现java序列化?
把一个对象写入数据源或者从一个数据源读出来,使用可序列化,需要实现Serializable接口;
————————————
- 提问:在实现序列化接口是时候一般要生成一个serialVersionUID字段,它叫做什么,一般有什么用?
版本号,要保持版本号的一致,来进行序列化,为了防止序列化出错;
————————————
- 提问:字节流和字符流,你更喜欢使用拿一个?
个人来说,更喜欢使用字符流,因为他们更新一些。
许多在字符流中存在的特性,字节流中不存在。比如使用BufferedReader而不是BufferedInputStreams或DataInputStream,使用newLine()方法来读取下一行,但是在字节流中我们需要做额外的操作;
————————————
- 提问:
————————————
- 提问:
————————————
——————————————————————————————
——————————————————————————————
——————————————————————————————
——————————————————————————————
————————————
以下作废
IO(输入输出)
定义:输入和输出都被称作抽象的流;
可以被看作一组有序的字节集合,即数据在两个设备之间的传输;
本质:数据传输;
分类:
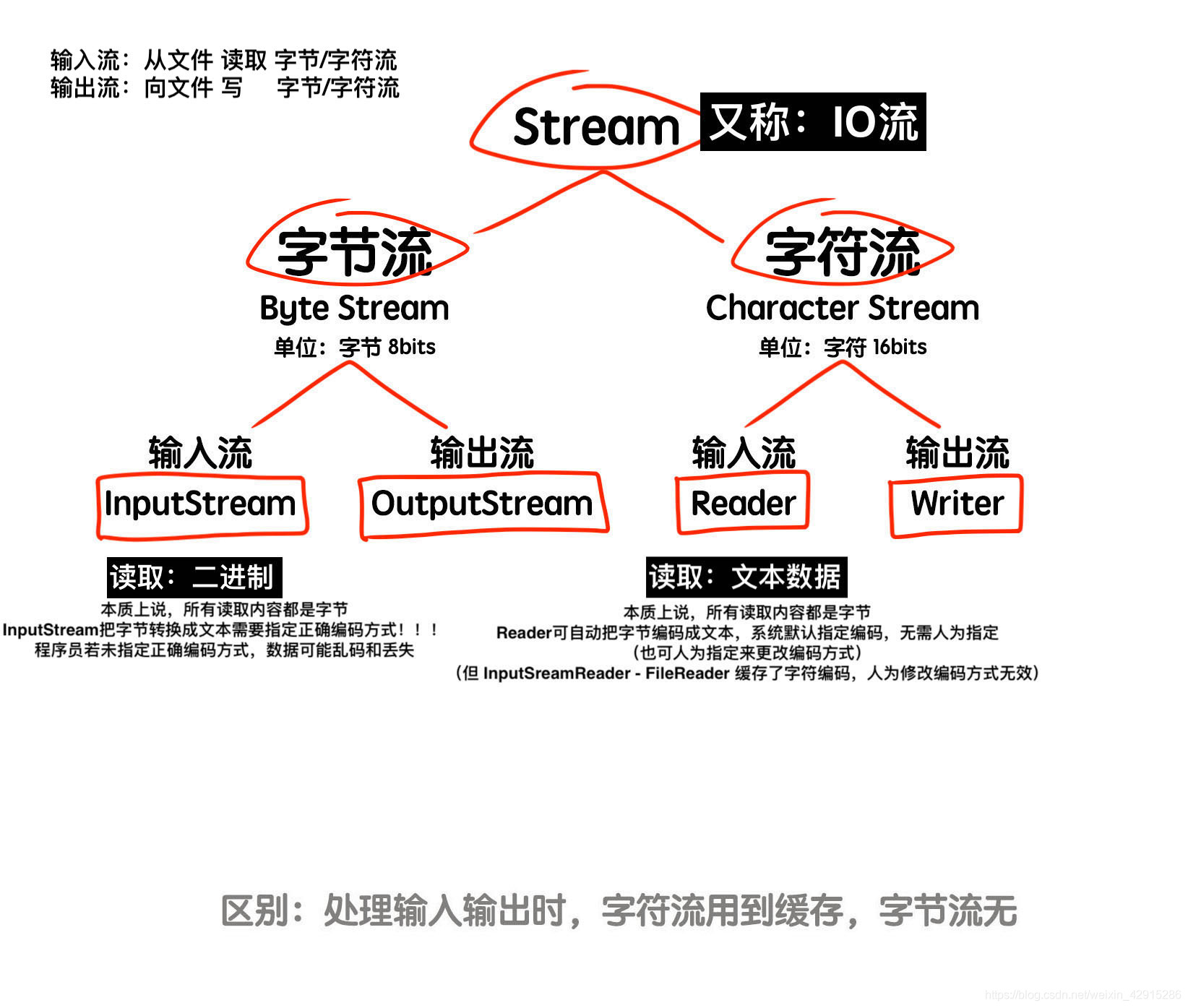
此图可应付大多数选择题:
举例,他们分别新建一个流对象的格式:InputStream: new ObjectInputStream(new FileInputStream("d.txt"));OutputStream: new GZIPOutputStream(new FileOutputStream("d.txt"));Reader: ``Writer: new BufferedWriter(new FileWriter("d.txt"));
————————————————
File类
java.io.File类:文件和目录名的抽象表示形式,和平台无关;
File能新建、删除、重命名「文件」和「目录」;
File对象可以作为参数传递给留的构造函数;
Java中,File类提供定位本地文件系统,对文件或目录及其属性进行基本操作;
File file1 = new File("Users/xxxx/Desktop/hello.txt"); //绝对路径
File file2 = new File("hello2.txt"); // 相对路径
System.out.println(file1.getName());
System.out.println(file2.getName());
————————————————
FileInputStream
提问:FileInputStream和FileReader有什么区别?
他们有着与上述内容相似的区别;FileReader从文件中读取字符数据,他继承自InputStreamReader,要么使用系统默认的编码方式,要么使用InputSreamReader使用的编码方式;
需要注意的是,InputSreamReader缓存了字符编码;所以在创建InputSreamReader对象之后,如果再对字符编码进行修改会没有任何作用。
————————————————
提问:从文件file.dat中读出第10个字节到变量c中,怎么写?FileInputStream in = new FileInputStream("file.dat");in.skip(9);int c = in.read();
in.skip()中不是填10!!
————————————————
Java中,若打开了外部资源(文件、DB连接等),我们必须在这些外部资源使用完毕后手动关掉他们;因为外部资源不属于JVM管,用不到垃圾回收机制;
若不关闭可能引起资源外泄 - 文件被异常占用 - DB连接过多 - 连接池溢出;
所以在finally中要关闭输入和输出流;
————————————————
一些基本概念:
1.区分同步或异步(synchronous/asynchronous)。
简单来说,同步是一种可靠的有序运行 机制,当我们进行同步操作时,后续的任务是等待当前调用返回,才会进行下一步;而异步 则相反,其他任务不需要等待当前调用返回,通常依靠事件、回调等机制来实现任务间次序关系。
(多线程环境中经常碰到数据共享问题:当多个线程需要访问同一个资源时,他们需要以某种顺序保证资源在某一时刻只能被一个线程使用,否则程序运行结果会不可预料,这时需要用同步:线程A需要使用某个资源时,若资源正在被线程B使用,同步机制会让A一直等下去,直到B结束使用后,A才能使用;由此可见,同步机制能保证资源的安全)
(想进行同步操作,必须获得每一个线程对象的锁,才能保证一次只有一个线程能进入临界区:即访问互斥资源的代码块,在这个锁被释放前,其他线程只能进入队列等待,队列中优先级别最高的线程才能获得该锁,进入共享代码区)
(同步可以用synchronized关键字实现,但同步也带来了系统极大的开销,有时甚至死锁,所以同步控制并非越多越好,要避免无谓的同步控制)
(异步:不必关心其他线程的状态和行为,也不必等到输入输出完毕才返回,提高了程序的效率)
另一种思路:
作者:严肃
链接:https://www.zhihu.com/question/19732473/answer/20851256
“阻塞”与"非阻塞"与"同步"与“异步"不能简单的从字面理解,提供一个从分布式系统角度的回答。
1.同步与异步 关注的是消息通信机制 (synchronous communication/ asynchronous communication)
同步异步,是对于线程而言的;
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。
而异步则是相反,调用在发出之后,这个调用就直接返回了,所以有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
2.阻塞与非阻塞 关注的是程序在等待调用结果(消息,返回值)时的状态。
阻塞非阻塞,是对于程序而言的;
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。还是上面的例子,你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
3. 如果是关心阻塞 IO/ 异步 IO, 参考 Unix Network Programming View Book
非阻塞可以配合同步进行,但发挥不到高效的作用
所以一般 “异步”是配合“非阻塞”使用 的,这样才能发挥异步的效用。
老张爱喝茶,废话不说,煮开水。
出场人物:老张,水壶两把(普通水壶,简称水壶;会响的水壶,简称响水壶)。
1 老张把水壶放到火上,立等水开。(同步阻塞)
老张觉得自己有点傻
2 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
老张还是觉得自己有点傻,于是变高端了,买了把会响笛的那种水壶。水开之后,能大声发出嘀~~~~的噪音。
3 老张把响水壶放到火上,立等水开。(异步阻塞)
老张觉得这样傻等意义不大
4 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
老张觉得自己聪明了。
所谓同步异步,只是对于水壶而言。
普通水壶,同步;响水壶,异步。
虽然都能干活,但响水壶可以在自己完工之后,提示老张水开了。
这是普通水壶所不能及的。同步只能让调用者去轮询自己(情况2中),造成老张效率的低下。
所谓阻塞非阻塞,仅仅对于老张而言。
立等的老张,阻塞;看电视的老张,非阻塞。
情况1和情况3中老张就是阻塞的,媳妇喊他都不知道。
虽然3中响水壶是异步的,可对于立等的老张没有太大的意义。
所以一般异步是配合非阻塞使用的,这样才能发挥异步的效用。
2.区分阻塞与非阻塞(blocking/non-blocking)。
在进行阻塞操作时,当前线程会处于阻塞 状态,无法从事其他任务,只有当条件就绪才能继续,比如 ServerSocket 新连接建立完毕,或数据读取、写入操作完成;
而非阻塞则是不管 IO 操作是否结束,直接返回,相应操作在后台继续处理。
不能一概而论认为同步或阻塞就是低效,具体还要看应用和系统特征。
IO 不仅仅是对文件的操作,网络编程中,比如 Socket 通信,都是典型的 IO 操作目标。
输入流、输出流(InputStream/OutputStream)是用于读取或写入字节的,例如操作图片 文件。
而 Reader/Writer 则是用于操作字符,增加了字符编解码等功能,适用于类似从文件中读取 或者写入文本信息。本质上计算机操作的都是字节,不管是网络通信还是文件读取,Reader/Writer 相当于构建了应用逻辑和原始数据之间的桥梁。
BufferedOutputStream 等带缓冲区的实现,可以避免频繁的磁盘读写,进而提高 IO 处理 效率。这种设计利用了缓冲区,将批量数据进行一次操作,但在使用中千万别忘了 flush。
参考下面这张类图,很多 IO 工具类都实现了 Closeable 接口,因为需要进行资源的释放。 比如,打开 FileInputStream,它就会获取相应的文件描述符(FileDescriptor),需要利用 try-with-resources、 try-finally 等机制保证 FileInputStream 被明确关闭,进而相应文件 描述符也会失效,否则将导致资源无法被释放。利用专栏前面的内容提到的 Cleaner 或 finalize 机制作为资源释放的最后把关,也是必要的。
提问:下列属于面向字符的输入流的是?
A.BufferedWriter
B.ObjectInputStream
C.FileInputStream
D.InputStreamReader
_____
答案D
提问:新建一个流对象,下面描述错误的是?
A.new BufferedWriter(new FileWriter("d.txt"));
B.new BufferedReader(new FileInputStream("d.dat"));
C.new ObjectInputStream(new FileInputStream("d.dat"));
D.new GZIPOutputStream(new FileOutputStream("d.zip"));
_____
答案B,因BufferedReader类只能包装Reader类和其子类
提问:构造BufferedInputStream的合适参数是?
A.BufferedInputStream
B.BufferedOutputStream
C.FileInputStream
D.FileOutputStream
E.File
_______
答案AC
————————
分析一段代码运行过程:
try{
PrintWriter out = new PrintWriter(new FileOutputStream("d:/a.txt"));
String name = "test";
out.print(name);
}catch(Exception e){
System.out.println("文件不存在");
}
若指定目录下文件不存在,在调用new PrintWriter(new FileOutputStream("d:/a.txt"))时,会抛出FileNotFoundException,这个异常是Exception的子类,能够匹配Exception从而执行catch代码块,输出文件不存在。
————————
详细分析InputStream和Reader的区别
InputStream用来读取二进制数(字节流);Reader用来读取文本数据(Unicode字符);
二进制数和文本数据有什么区别?从本质上来说,所有读取内容都是字节;
文本数据读取中:想要把字节转换成文本,需要指定一个编码方法;Reader中默认采用系统编码方式进行编码,亦可显示指定某编码方式,如UTF-8;
但程序员有个常见犯错,忘记指定正确编码方式,导致数据乱码和流失。
————————

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)