[NLP]搞懂词向量Word2vec(上)
关键词:神经网络、自然语言处理、word2vec- - - - - - - - - -笔记:桃子????日期:2021.6- - - - - - - - - -目录- - - - - - - - - -神经网络自然语言处理定义3种表示方法word2vec定义2个模型计算公式优缺点一、神经网络定...
·
关键词:神经网络、自然语言处理、word2vec
- - - - - - - - - -
一、神经网络
1. 1 概念
神经网络:一个函数。函数是将某些输入变换为某些输出
偏置:一个不受前一层的神经元影响的常数
MatMul 节点: 矩阵乘积称为 MatMul 节点( Matrix Multiply 的缩 写)
全连接 网络: 所有相邻 的神经元之间都存在由箭头表示的连接
Softmax 函数:(0-1)分子是得分 sk 的指数函数,分母是所有输入信号的指数函数的和
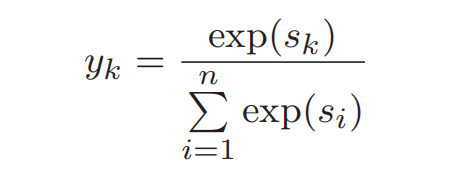
交叉熵误差:交叉熵误差由神经网络输出的各类别的概率和监督标签求得,tk 是对应于第 k 个类别的监督标签
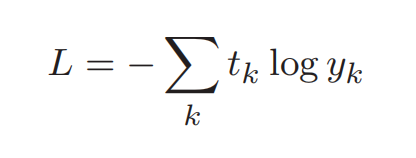
梯度:将关于向量(矩阵)各个元素的导数罗列到一起,就得到了梯度(gradient)
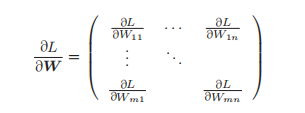
数学中的梯度仅限于关于向量的导数。
而在深度学习领域,一般也会定义关于矩阵和张量的导数,称为“梯度”
链式法则: 反向传播中流动 的导数的值是根据从上游(输出侧)传来的导数和各个运算节点的局部导数 之积求得的
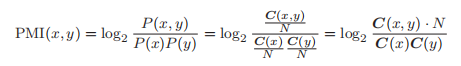
梯度下降法:通过将参数向该梯度的反方向更新,可以降低损失
随机梯度下降法:(Stochastic Gradient Descent,SGD)其中,“随机”是指使用随机选择的数据(mini-batch)的梯度
1.2 计算速度
使用 32 位浮点数也可以无损地(识别精度几乎不下降)进行神经网络的推理和学习。从内存的角度来看,因为 32 位只有 64 位的一半,所以通常首选 32 位
GPU:深度学习的计算由大量的乘法累加运算组成。这些乘法累加运算的绝大部分可以并行计算,这是 GPU 比 CPU 擅长的地方(库:CuPy)
二、自然语言处理
2.1 定义
自然语言处理NLP,就是处理自然语言的科学。
简单地说,它是一种能够让计算机理解人类语言的技术。
换言之,自然语言处理的目标就是让计算机理解人说的话,进而完成对我们有帮助的事情。
2.2 应用
Web 检索、机器翻译、语音助理
2.3 其他要点
深度学习自然语言处理包括:
word2vec、RNN、LSTM、GRU、seq2seq 和 Attention
在自然语言处理领域,单词的密集向量表示,称为:
词嵌入(word embedding)--基于神经网络
或单词的分布式表示(distributed representation)--基于计数
加快大规模数据的训练速度的 :Negative Sampling
处理时序数据的 :RNN、LSTM 和 GRU
处理时序数据的误差反向传播法(Backpropagation Through Time)
三、单词表示的3种方法
3.1 基于同义词词典的方法
IS 具有相同含义的单词(同义词)或含义类似的单词(近义词)通过人工标记被归 类到同一个组中
代表: WordNet
缺点:新词不断涌现、人力成本高
3.2 基于计数的方法(也称为“基于统计的方法“)
IS 使用语料库corpus, 从富有实践知识的语料库中,自动且高效地提取本质
IS 基于词的分布式假设,从语料库中‘计算’出词的向量表示
代表: 语料库( Wikipedia、Google News )
一个概念:词分布假设
定义:某个单词的含义由它周围的单词形成
所表达的理念:单词本身没有含义,单词含义由它 所在的上下文(语境)形成。
如何基于分布式假设计算出单词的表示( 向量) ?
最直截了当 的实现方法是对周围单词的数量进行计数,得到 共现矩阵
如何测量向量间的相似度?
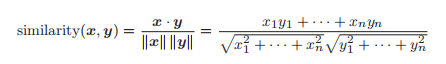
余弦相似度直观地表示了“两个向量在多大程度上指向同一方向”
两个向量完全指向相同的方向时,余弦相似度为 1;
完全指向相反的方向时,余弦相似度为 −1。
当某个单词被查询时,如何输出?
当某个单词被作为查询词时,将与这个查询词相似的单词按降序显示出 来。
缺点
①只统计词频,这种 “原始”的次数并不具备好的性质; 比如the car 共现高,driver和car也共现高,实际意义上的相关性没有表述出来
②数据量大,计算开销大 [S VD 的复杂度是 O(n3)]
改进
a).点互信息( PMI)
C(x, y): 单词 x 和 y 的共现次数
C(x): 单词 x 和 y 出现次数
C(y): 单词 x 和 y 出现次数
N: 语料库的单词数量
PMI 的值越高,表明相关性越强
解决: 当两个单词的共现次数为 0 时,log20 = −∞的问题
b).降维 SVD
总结
首先创建单词的共现矩阵,将其转化为 PPMI 矩阵,再基于 SVD 降 维以提高稳健性,最后获得每个单词的分布式表示。另外,我们已经确认 过,这样的分布式表示具有在含义或语法上相似的单词在向量空间上位置相 近的性质
3.3 基于推理的方法(word2vec)
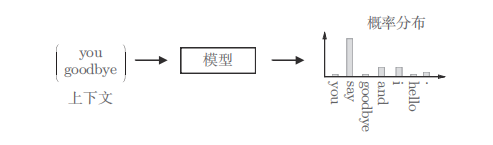
IS 基于词的分布式假设,构造合适的语言任务,从语料库中用神经网络学习出词的向量表示
基于推理的方法的主要任务:
解开图中的推理问题并学习规律, 通过反复求解这些推理问题,可以学习到单词的出现模式。
如何基于分布式假设使 用神经网络学习出 单词的 表示( 向量) ?
( 基于推理的方法的全貌)
模型:神经网络模型
输入: 上下文信息
输出:(可能出现的)各个单 词的出现概率
学习路径:使用语料库来学习模型,使之能做出正确 的预测
模型产物:作为模型学习的产物,我们得到了 单词的分布式表示
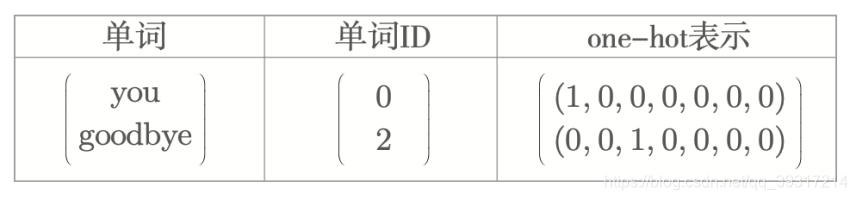
神经网络如何接收单词输入?(单词的处理方法)
将单词转换为 one-hot 表示: 只有一个元素是1,其余是0
(热编码提供了一种十分简单的手段,但是缺陷也很多,比如过于稀疏,没有用到词之间的上下文信息等基于one-hot编码,我们引入word embedding技术)
只要将单词表示为向量,这些向量就可以 由构成神经网络的各种“层”来处理

3.4 对比基于计数和基于推理
基于计数的方法使用 整个语料库的统计数据 (共现矩阵和 PPMI 等), 通过一次处理( SVD 等)获得单词的分布式表示。
而基于推理的方法使用 神经网络 ,通常在 mini-batch 数据 上进行学习。这意味着神经网络一次只 需要看一部分学习数据( mini-batch ),并反复更新权重。
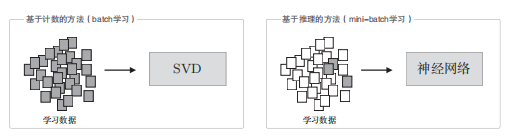
①在向词汇表添加新词并更新单词的分布式表示的场 景, 基于计数的方法需要从头开始计算,基于推理的方法(word2vec)允许参数的增量学习。可 将之前学习到的权重作为下一次学习的初始值,不损失之前学习到的经 验。
② 基于计数的方法主要是编码单词的相似性,而 word2vec (特别是 skip-gram 模型)除了单词的相似性以外,还 能理解更复杂的单词之间的模式( 能解开“king − man + woman = queen”这类推问题 )
③基于推理的方法和基于计数的方法存在关联 性。具体地说,使用了 skip-gram 和 Negative Sampling 的模 型被证明与对整个语料库的共现矩阵进 行特殊矩阵分解的方法具有相同的作用
④有研究人员提出了 GloVe 方法。GloVe 方法融合了基于推理的方法和基于计数的方法。 将整个语料库的统计数据的信息纳入损失函数,进行 mini-batch 学习
三、word2vec
3.1 定义
word2vec 一词最初用来指程序或者工具,但是随着该词的流行,在某些语境下,也指神经网络的模型
发明者:马斯·米科洛夫(Tomas Mikolov)
包括:(2个神经网络模型)

3.2 skip-gram 跳字模型
IS 根据目标词预测上下文
给定中心词,通过最大似然估计,找到临近词
3.3 CBOW 连续词袋模型( continuous bag-of-words )
IS 根据上下文预测目标词
给定临近词,通过最大似然估计,找到中心词
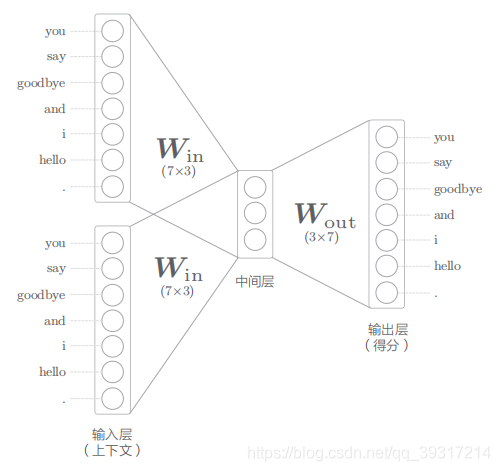

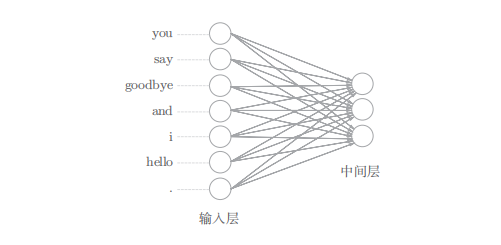
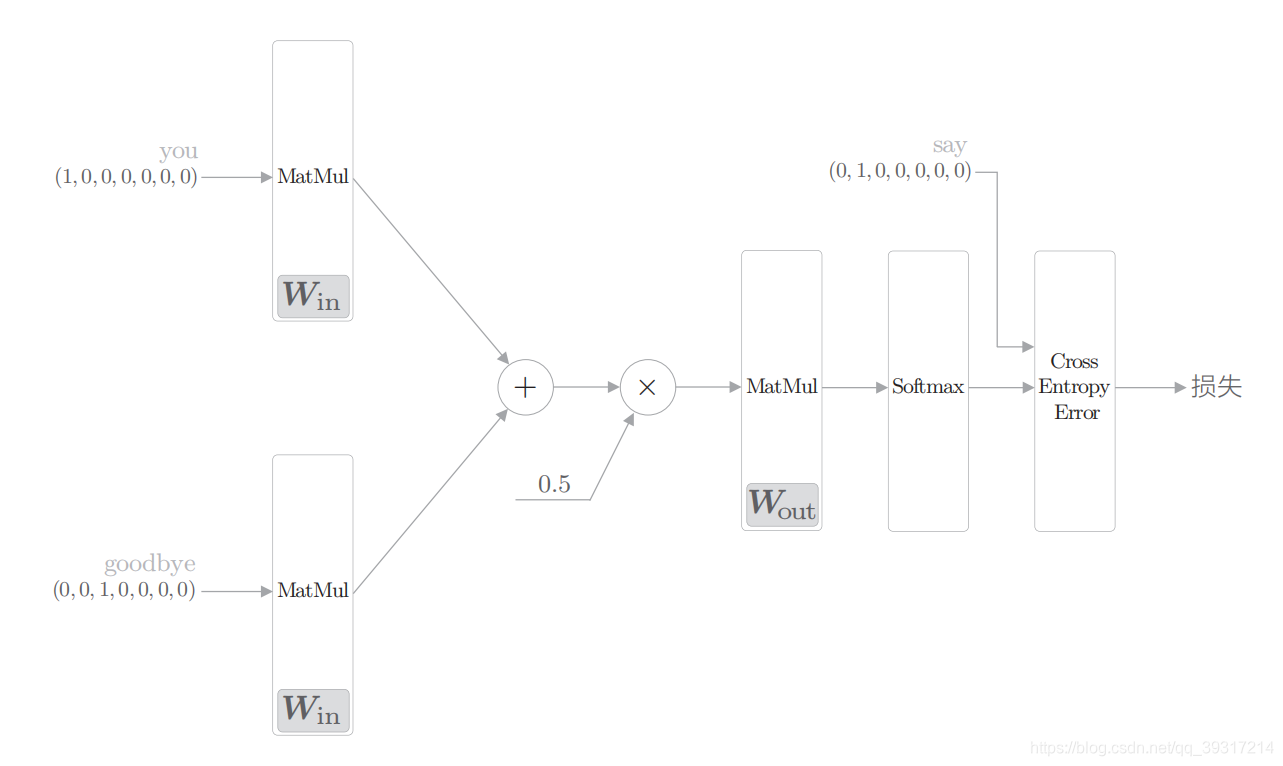
全连接层的权重 W in 是一个 7 × 3 的矩阵。这个 权重就是我们要的单词的分布式表示( 权重 W in 的各行保存着 各个单词的分布式 表示)
中间层的神经元是各个输入层经全连接层变换后得到的值的 “平均”
中间层 的神经元数量 比输入层少 这一点很重要。中间层需要将预测 单词所需的信息 压缩保存 ,从而产生密集的向量表示。
输出层的神经元是各个单词的得分, 得分是指在被解释为概率之前的值, 对这些得分应用 Softmax 函数,就可以得到概率
损失: CBOW 模型加上 Softmax 层和 Cross Entropy Error 层,就可以得到损失
单词的分布式表示:权重
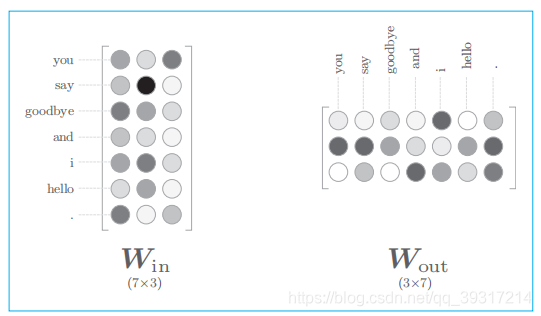
输入侧的权重 Win 的每一行对应于各个单词的分布式表示
输出侧的权重Wout在列方向上保存了各个单词的分布式表示
两个都可,也可组合表示
网络结构
3.4 计算公式
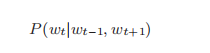 CBOW 模型公式
CBOW 模型公式
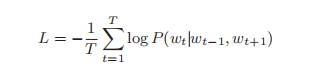 CBOW 模型优化目标
CBOW 模型优化目标
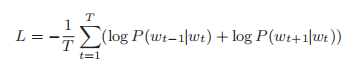 skip-gram 模型优化目标
skip-gram 模型优化目标
3.5 2个模型对比
单词分布式表示的准确度:大多数情况下,skip-grm 模型的结果更好。(特别是语料库规模增大,在低频词和类推问题的性能方面,skip-gram 模型更好)。skip-gram 模型存在 许多候选。因此,要解决的是更难的问题。经过更难的问题的锻炼,skip-gram 模型能提供更好的单词的分布式表示
学习速度:CBOW 模型比 skip-gram 模型要快。
3.6 训练方法 (近似训练法)
负采样
softmax
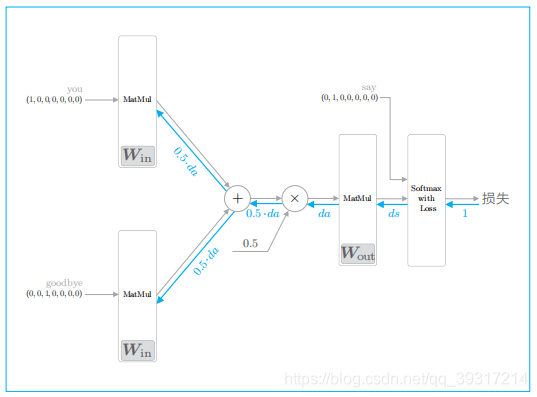
CBOW 模型的反向传播:蓝色的粗线表示反向传播的路线
优缺点
优点1:可以较好地表达不同词之间的 相似和 类比关系
思考:为什么不能用one-hot直接表示单词?
参考资料:《 Natural Language Processing》斋藤康毅

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)