数据挖掘(一)简介
为什么要数据挖掘Data: 任何事实,数字或文字都可以由计算机处理在超市出售不同商品的相关数据Information: 由数据之间的模式,关联或关系提供上个月哪些商品最畅销?通常通过查询获得**Knowledge:**信息可以转换为有关历史模式和未来趋势的知识通常一起购买哪些商品?通过分析计算机算法获得数据从TB爆炸式增长到PB,现在是数据时代不是信息时代数据...
为什么要数据挖掘
-
Data: 任何事实,数字或文字都可以由计算机处理
在超市出售不同商品的相关数据 -
Information: 由数据之间的模式,关联或关系提供
上个月哪些商品最畅销?
通常通过查询获得 -
**Knowledge:**信息可以转换为有关历史模式和未来趋势的知识
通常一起购买哪些商品?
通过分析计算机算法获得
数据从TB爆炸式增长到PB,现在是数据时代不是信息时代
- 数据收集依靠自动化数据收集工具,数据库系统,Web
- 丰富数据的主要来源
电子商务:交易,股票,…
科学:遥感,生物信息学,科学模拟,…
新闻,数码相机,YouTube
我们淹没在数据中,但渴望知识!数据挖掘之母-自动化海量数据集分析是必要的。
什么是数据挖掘
- 数据挖掘
从大量数据中提取有趣的(非平凡,隐式,以前未知且可能有用的)模式或知识 - 替代名称
数据库(KDD)中的知识发现(挖掘),知识提取,数据/模式分析,数据考古,数据挖掘,信息收集,商业智能等
知识发现(KDD)流程
- 数据挖掘在知识发现过程中起着至关重要的作用
- 数据挖掘通常用于指代整个KDD流程
例如:
- 一家杂货店使用数据挖掘来分析购买模式
- 结果:
当男人们在周四和周六购买尿布时,他们也买啤酒 - 优点:
增加收入
怎么样做?->将啤酒展示架靠近尿布展示架
多角度看数据挖掘
- 待挖掘数据
数据库数据(扩展关系,面向对象,异构,旧版),数据仓库,交易数据,流,时空,时间序列,序列,文本和网络,多媒体,图表和社交和信息网络 - 要挖掘的知识(或:数据挖掘功能)
表征,歧视,联想,分类,聚类,趋势/偏差,离群值分析等描述性与预测性数据挖掘多种/综合功能和多层次挖掘 - 运用技术
数据密集型,数据仓库(OLAP),机器学习,统计信息,模式识别,可视化,高性能等 - 适应应用
零售,电信,银行,欺诈分析,生物数据挖掘,股票市场分析,文本挖掘,Web挖掘等。
可以挖掘什么样的数据?
- 面向数据库的数据集和应用程序
关系数据库,数据仓库,事务数据库 - 高级数据集和高级应用程序
数据流和传感器数据
时间序列数据,时间数据,序列数据(包括生物序列)
结构数据,图表,社交网络和多链接数据
对象关系数据库
异构数据库和遗留数据库
空间数据和时空数据
多媒体资料库
文字数据库
万维网
可以挖掘哪些类型的模式?
数据挖掘功能
- 特征与区别
- 频繁模式,关联和关联的挖掘
- 分类与回归
- 聚类分析
- 离群值分析
数据挖掘功能种类
- 描述性的:表征数据的属性
- 预测性的:对数据进行归纳以用于将来的预测
特征与区分
- 数据可以与类或概念相关联
- 类/概念描述:描述类或概念概括的术语
数据表征:总结一类数据
例如:总结购买牛仔裤顾客的特征
数据区分:将一类数据与一个数据进行比较或更多其他类别
例如:比较购买牛仔裤顾客的特征与那些购买普通的裤子
关联和相关分析
- 频繁模式(或频繁项目集)
您经常一起购买哪些物品商店?
例如:牛奶和面包经常一起购买买(x,牛奶)→买(x,面包)
支持度:50%
如果客户有50%的机会购买牛奶,她也会购买面包
置信度:2%
2%的购物同时包含牛奶和面包
分类与回归
- 根据一些训练样本构造模型(函数)
使用带有指示标签的培训数据集(监督学习) - 使用测试数据检查分类准确性
描述和区分类别或概念以供将来预测
例如:根据气候(炎热,寒冷,多雨)对国家进行分类 - 典型方法
- 决策树,贝叶斯分类,支持向量机,神经网络等
- 典型应用信用卡欺诈检测,直接营销,星级分类,疾病,网页等
聚类分析
- 无监督学习(即类别标签未知)
没有训练数据 - 将数据分组以形成新的类别(即群集)
例如:根据那里的特征对国家进行分类 - 原理:最大化集群内相似度并最小化集群间相似度
- 许多方法和应用
离群值分析
- 目标:找到数据中的异常值
- 离群值:与常规不兼容的数据对象数据类的行为•例如:银行交易中的欺诈检测
- 噪音还是异常? ―一个人的垃圾可能是另一个人的宝贝
- 方法:通过聚类或分类
不属于任何群集或类的对象是异常值 - 在欺诈检测,罕见事件分析中很有用
时间与排序:顺序模式,趋势和进化分析
- 序列,趋势分析
趋势,时间序列和偏差分析。例如:回归与价值预测
连续型模式挖掘 (例如,第一款数字相机,然后购买大型的SD照相机)
周期性分析
生物序列分析
相似性分析 - 挖掘数据流
有序,时间变化,潜在无限,数据流
图片和网络分析
- 图片挖掘
查找频繁的子图(例如化合物),树木(XML),子结构(网络) - 信息网络分析
社交网络:参与者(对象,节点)和关系(边缘)
例如,CS中的作者网络,恐怖分子网络
多个异构网络
一个人可能是多个信息网络:朋友,家庭,同学……
链接包含很多语义信息:链接挖掘 - 网页挖掘
网页是一个大信息网络
Web信息网络分析
网络社区发现,观点挖掘,用法挖掘…
知识评估
-
所有挖掘的知识都有趣吗?
数据挖掘功能可以制作大量模式
这些模式中很有趣如果它们
容易被人理解;
在一定程度上对某些测试数据有效;
潜在有用;
一个有趣的模式代表知识 -
评估挖掘模式
有一些技术可以根据数据挖掘功能来评估。例如:支持度和可信度常用于频繁的项目集
使用什么技术?
数据挖掘:多学科融合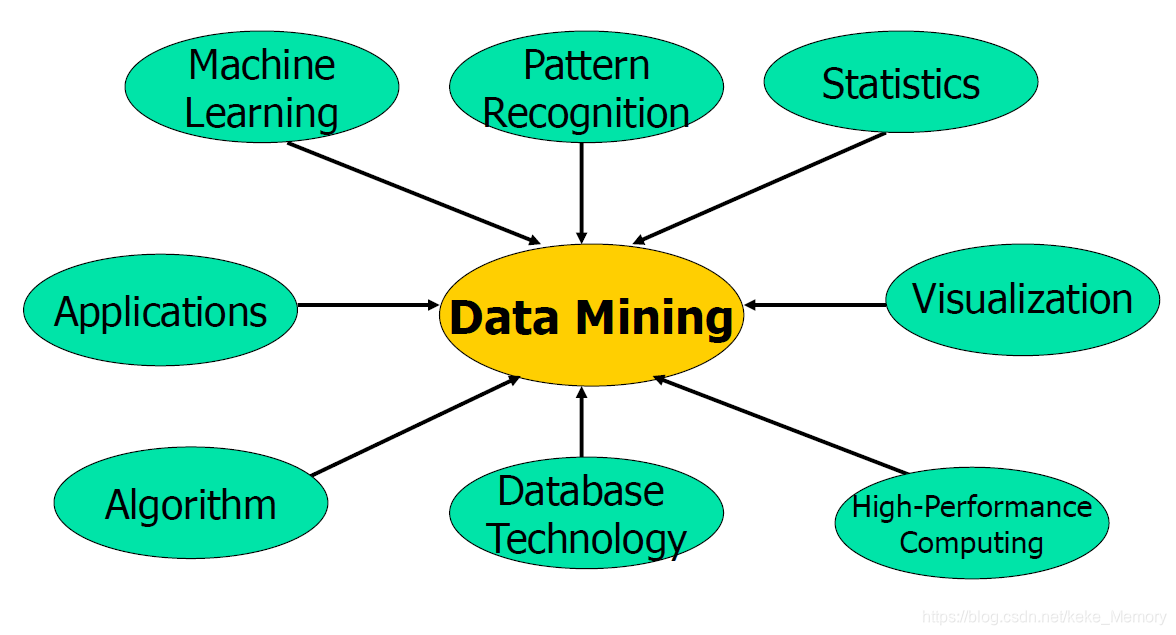
为什么要融合多个学科?
- 海量数据
算法必须具有高度的可伸缩性,以处理诸如兆字节的数据 - 数据的高维度
微阵列可能具有数万个维度 - 数据复杂度高
数据流和传感器数据
时间序列数据,时间数据,序列数据
结构数据,图表,社交网络和多链接数据
异构数据库和遗留数据库
空间,时空,多媒体,文本和Web数据
软件程序,科学模拟 - 新的和复杂的应用
目标是哪种应用?
数据挖掘的应用
- 网页分析:从网页分类,聚类到PageRank,SimRank和JacSim算法
- 协作分析和推荐系统
- 购物篮数据分析以针对性营销
- 生物医学数据分析:分类,聚类分析(微阵列数据分析),生物序列分析,生物网络分析
- 数据挖掘和软件工程(例如,IEEE计算机)
- 来自主要的专用数据挖掘系统/工具(例如SAS,MS SQL服务器分析管理器,Oracle数据挖掘工具)以隐藏数据矿业
数据挖掘中的主要问题
挖掘方法论
- 挖掘各种新知识
- 多维空间中的知识挖掘
- 数据挖掘:跨学科的工作
- 增强网络环境中的发现能力
- 处理噪声,不确定性和数据不完整性
- 模式评估和模式或约束指导的挖掘
交互
- 交互挖掘
- 结合背景知识
- 数据挖掘结果的呈现和可视化
效率和可伸缩性 - 数据挖掘算法的效率和可扩展性
- 并行,分布式,流式和增量式挖掘方法
数据类型的多样性
- 处理复杂类型的数据挖掘动态,联网和全局数据存储库
- 数据挖掘与社会
数据挖掘的社会影响
- 隐私保护数据挖掘
- 隐形数据挖掘
总结
- 数据挖掘:从大量数据中发现有趣的模式和知识
- 数据库技术的自然演进,需求巨大,应用广泛
- KDD流程包括数据清理,数据集成,数据选择,转换,数据挖掘,模式评估和知识介绍
- 可以在各种数据中进行挖掘
- 数据挖掘功能:表征,区分,关联,分类,聚类,离群值和趋势分析等。
- 数据挖掘技术与应用
- 数据挖掘中的主要问题

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)