Java 实现 Kafka Streaming API
Java 实现 Kafka Streaming API下面用几个实例简单实现一下Kafka Streaming, 几个案例都需要提前在kafka内创建对应名称的 topic,这里不做赘述,直入主题。案例一:实现直接转入本案例实现的功能为往topic A写入数据时,会同步写入topic B, 只是简单的转发功能,代码如下:import org.apache.kafka.common.serializ
·
Java 实现 Kafka Streaming API
下面用几个实例简单实现一下Kafka Streaming, 几个案例都需要提前在kafka内创建对应名称的 topic,这里不做赘述,直入主题。
案例一:实现直接转入
本案例实现的功能为 往 topic A 写入数据时,会同步写入topic B, 只是简单的转发功能,代码如下:
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class MyStreamDemo {
public static void main(String[] args) {
Properties prop=new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"mystream");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.146.222:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG,Serdes.String().getClass());
//创建 流的 构造器
StreamsBuilder builder = new StreamsBuilder();
//用构造好的builder 将mystreamin topic里面的数据写入到mystreamout topic 中
builder.stream("mystreamingin").to("mystreamingout");
//构建 拓扑
Topology topo = builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try{
streams.start();
latch.await();
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
实现的结果如图所示: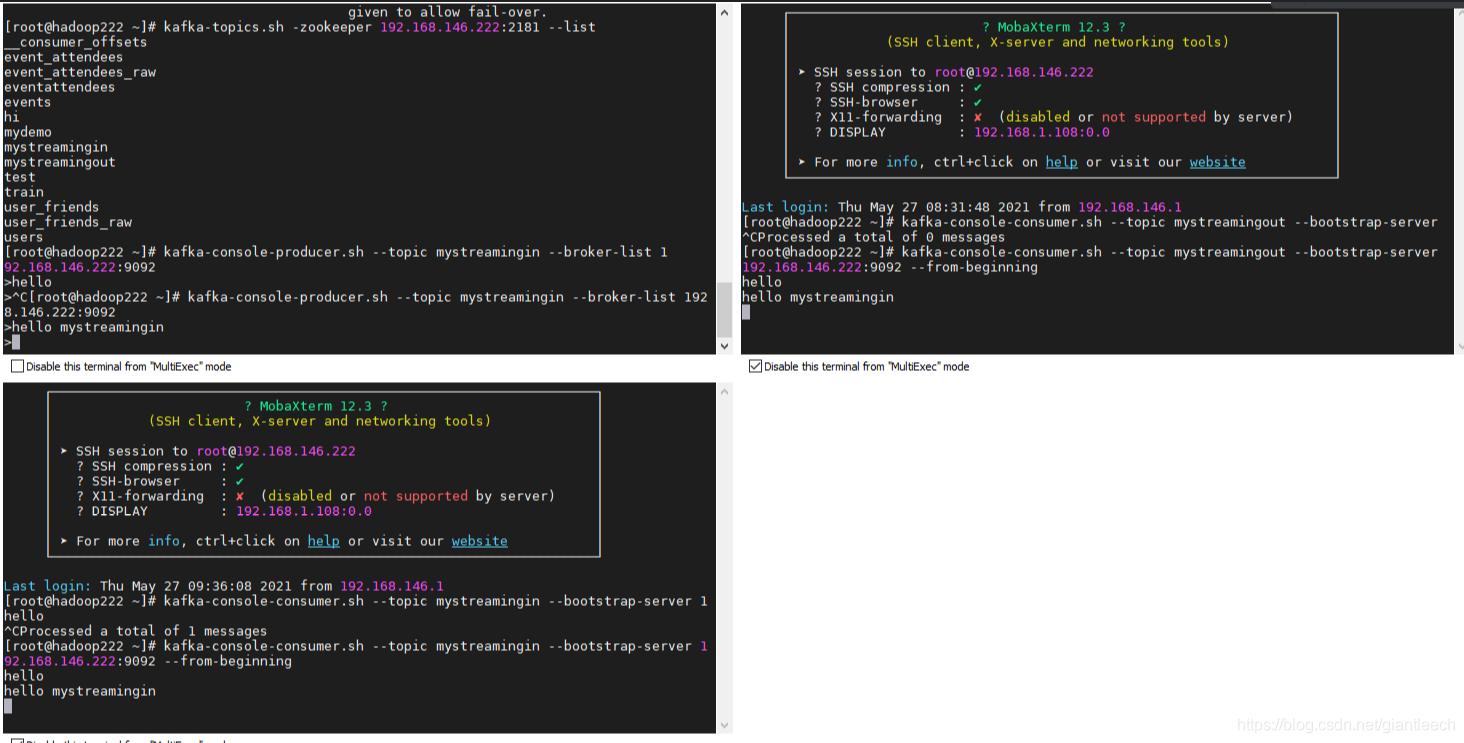
案例二,实现相加功能
例如往 topic A中 输入几个数字,会自动累计,然后把和 输入topic B 内,这里需要设置提交数据的方式以及 间隔时间,以区分边界,代码如下:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class SumStreamDemo {
public static void main(String[] args) {
Properties prop=new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"sum");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.146.222:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000); //提交时间间隔
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); //是否自动提交
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //earliest latest none
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> source = builder.stream("suminput");
//key value 数据格式 [null 4 , null 5, null 3]
KTable<String, String> sum1 = source.map((key, value) ->
new KeyValue<String, String>("sum", value.toString())
)// [sum 4, sum 5 , sum 3]
.groupByKey() //[sum , (4,5,3)]
.reduce((x, y) -> {
Integer sum = Integer.valueOf(x) + Integer.valueOf(y);
System.out.println("x:" + x + " + y:" + y + " = " + sum);
return sum.toString();
});
sum1.toStream().to("sumoutput");
//构建 拓扑
Topology topo = builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try{
streams.start();
latch.await();
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
实现的结果如图所示: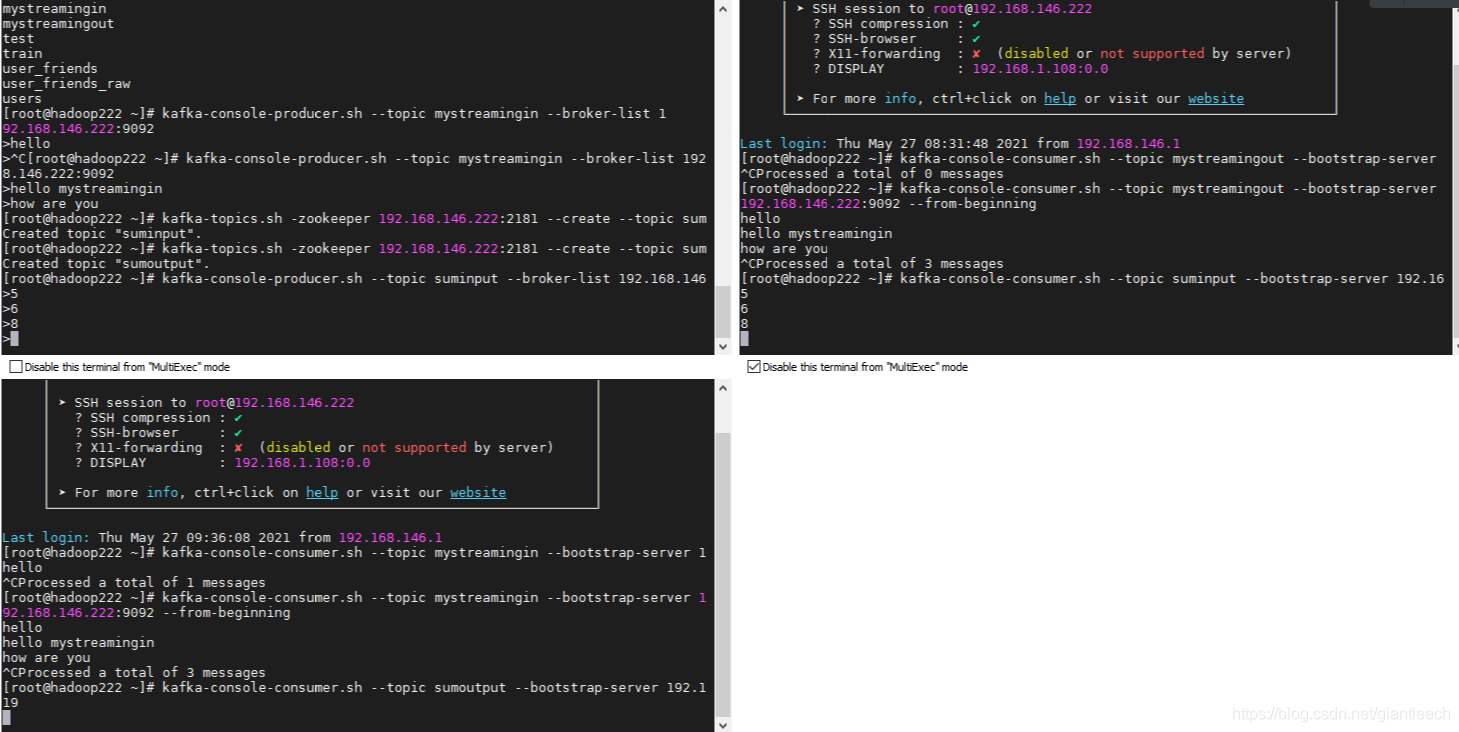
案例三,实现wordcount 功能
实现wordcount功能,即在 topic A 中 输入一组字符串,然后根据分隔符切分后,统计出每个单词出现的次数,形成新的键值对后 发送到 topic B 内。代码如下:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCountStreamDemo {
public static void main(String[] args) {
Properties prop=new Properties();
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"wordcount");
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.146.222:9092");
prop.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG,3000); //提交时间间隔
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); //是否自动提交
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //earliest latest none
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<Object, Object> count = builder.stream("wordcountin"); //hello world hello java
KTable<String, Long> count1 = count.flatMapValues(x -> {
String[] split = x.toString().split("\\s+");
List<String> strings = Arrays.asList(split);
return strings;
}) //[null hello,null world,null hello,null java ]
.map((k, v) -> {
KeyValue<String, String> keyValue = new KeyValue<>(v, "1");
return keyValue;
}) //[hello:1,world:1,hello:1,java:1]
.groupByKey() //[hello:(1,1),world:(1),java:(1)]
.count(); //[hello:2,world:1,java:1]
count1.toStream().foreach((key,value)->{
System.out.println("key:"+key+","+"value"+value);
});
// count1.toStream().to("wordcountout", Produced.with(Serdes.String(),Serdes.Long()));
count1.toStream().map((key,value)->{
return new KeyValue<String,String>(key,key+value.toString());
}).to("wordcountout");
//构建 拓扑
Topology topo = builder.build();
final KafkaStreams streams = new KafkaStreams(topo, prop);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("stream"){
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try{
streams.start();
latch.await();
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
实现的结果如图所示: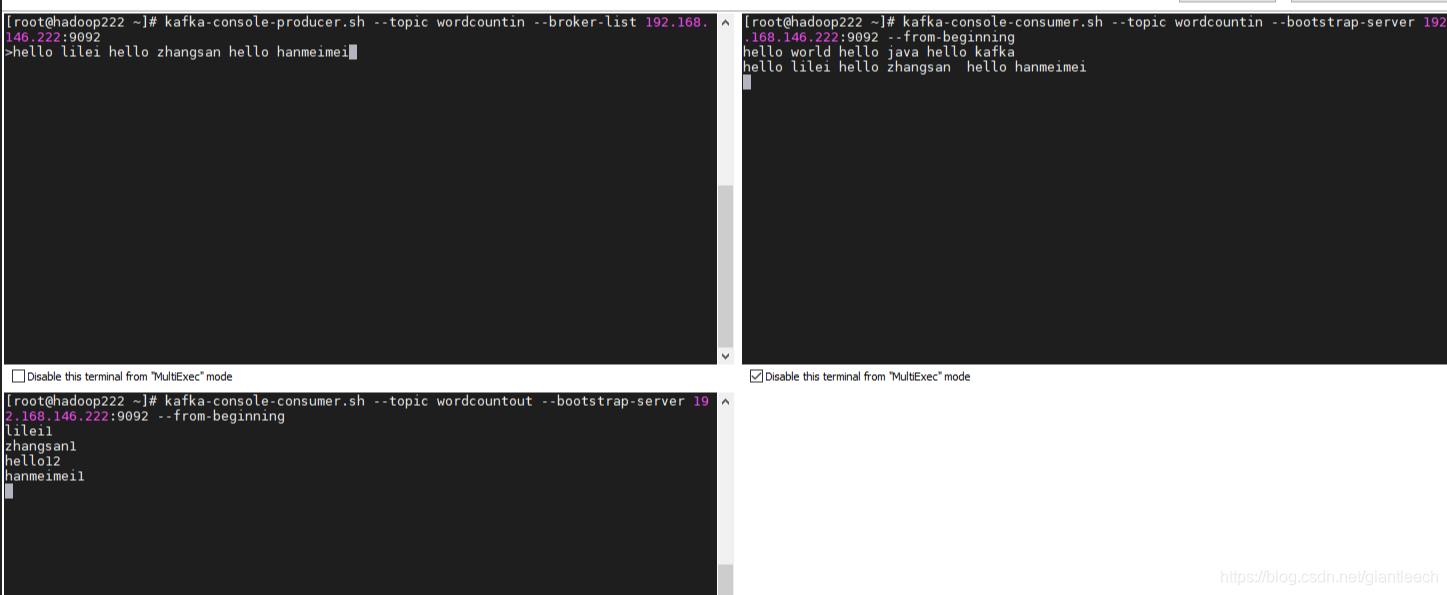

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)