[Paper Reading] Bigtable: A Distributed Storage System for Structured Data
目录===== 1. Introduction===== 2. Data Model===== 2.1 Row===== 2.2 Column Family===== 2.3 Timestamp===== 3. API===== 4. Building Blocks===== 5. Implementation===== 5.1 Tablet Location===== 5.2 Tablet As
目录
===== 6.3 Caching for read performance
===== 6.5 Commit-log implementation
===== 6.6 Speeding up tablet recovery
===== 6.7 Exploiting immutability
===== 1. Introduction
Bigtable 被设计为一个 PB级数据量、数千机器的可扩展存储系统。设计目标包括:wide applicability、scalability、high performance、high availablity
Bigtable 在 google 应用在各种场景:从 吞吐较高的批处理job 到 延迟敏感的服务,设计 60多个产品项目
在许多方面,Bigtable 类似 database:与 database 有许多相同的策略。
- Parallel databases [14] & main-memory databases [13] 实现扩展性&高性能,Bigtable 在此基础上还提供了不同的 interface
- Bigtable 没有提供一个完全 关系数据模型,而是提供一个 支持控制数据layout&formt(Dynamic control over data layout and format)、允许客户端对底层数据的位置属性进行推理(reason about the locality properties of the data) 的简单数据模型
- 使用行&列名称对数据进行索引,并将数据视为 未解析的字符串(uninterpreted strings)
- 客户端可以通过对schema的选项来控制数据的位置,schema也提供参数来动态控制从内存还是磁盘提供数据
===== 2. Data Model
【数据结构管理】Bigtable 是一个 稀疏、分布式、持久化的多维sorted map。这个map的索引key 是 row key + column key + timestamp,每个value都是一个 uninterpreted字节数组
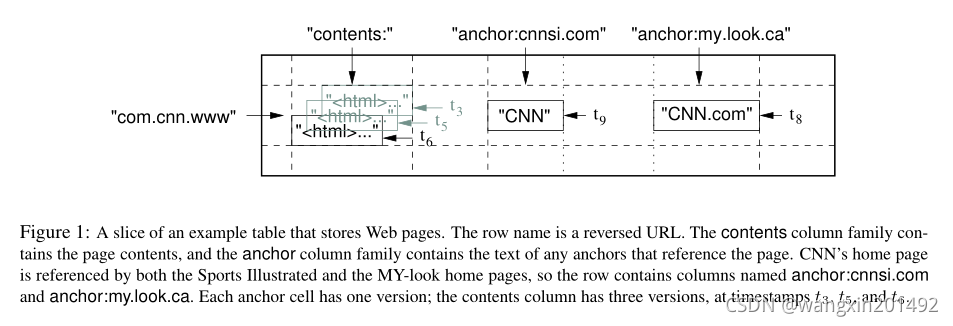
===== 2.1 Row
Row key 可以是任意的字符串,最大支持64KB,10-100B是常见大小。
对单rowKey的读写都是原子的(无论列多少),这样便于客户端对相同行的更新时推断系统行为。
Row key 按照字典序排列
【分片方式 -- tablet】数据按照行范围动态分片,每个分片称为一个 tablet,tablet 是数据分布&负载均衡的基本单元。
读取小范围的数据仅需要和少量的machine交互即可,客户端可以利用这个属性来选择row key,便于他们很好的获取数据访问位置
===== 2.2 Column Family
Column key 被分组到一个集合中,称为 column family,存储在同一个column family中的数据类型往往是相同的,这些数据会被压缩存储在一起。
访问控制 以及 内存&磁盘的管理都是在 column family 级别完成的。
Column family必须提前创建好,随后才可以向其中的任意 column key 中插入数据。因为 column family 通常比较少(最多上百个)而且极少修改,而column可能特别多。
Column key使用如下的语法命名:family:qualifier。Column family的名字必须是可打印的(printable),而qualifier可以是任意字符。
===== 2.3 Timestamp
Bigtable 中的每个 cell 都包含相同数据的多个版本,这个版本按照 timestamp 索引。
每个 timestamp 都是一个 64bit integer,这个 ts 可以由 Bigtable 生成,也可以由客户端指定。客户端如果要避免碰撞,需要指定不同的时间戳。cell中不同的version按照 ts 降序排列,所以最新的数据会先被读到
支持2种版本回收策略:保留最近n个版本、保留最近n天的版本
===== 3. API
Bigtable API 提供 创建删除 table&column family 的能力,也提供修改 cluster、table、column family metadata的能力
客户端可以写入、删除 value,也可以查询行信息并迭代读取。如下展示了 读写 的 代码

Bigtable 还支持一些其他特性:
- 支持单行事务,但不支持跨行事务
- 允许 cell 被当作 integer 计数器使用
- 支持 client定义的script 执行 — 脚本由 Sawzall [28] 语言编写,部署在 Google上
- Bigtable 可以与 MapReduce [12] 结合使用,可以作为 MR 的 input或者output
===== 4. Building Blocks
Bigtable 在 许多 Google 基础组件上构建完成。
【GFS】
Bigtable 使用 GFS [17] 来存储日志和数据。
Bigtable 与其他服务混部运行,以来管理系统调度资源实现机器共享。
【SSTable】Google SSTable 文件格式被用来存储 Bigtable 的数据。SSTable 提供持久化的、有序不可修改的map结构,key&value都是任意的字符串。
【Block】每个SSTable 包含多个block,每个block默认 64KB 大小,可配置。
【基于SSTable-Block的查找操作】block的index存储在SSTable 的最后,当 SSTable open的时候就会加载到内存中。这样查找操作只需要一次 disk seek 就可以完成:首先从内存index中查找对应的block,然后从磁盘中读取对应的block。此外, SSTable可以被映射到内存,这样查找的时候无序和磁盘交互。
【Chubby】
Bigtable 还依赖 一个高可用、分布式的锁服务,称为 Chubby [8]。Chubby 使用 Paxos 协议来保证一致性 [9, 23]。其提供 namespace 由 dir & file 组成。每个dir & file 都可以被用作lock使用,读写都是 atomic 的。Chubby 客户端维护一个 session,基于 lease 机制刷新,lease 过期就可能会被抢占锁。Chubby服务长时间不可用,则Bigtable 就会不可用。
Bigtable 使用Chubby完成各种功能:
- 确保任意时间只有一个 active master
- 存储 启动时用到的 Bigtable 数据
- 发现 tablet 节点 & tablet节点探活
- 存储 Bigtable schema 信息
- 存储 访问控制信息
===== 5. Implementation
Bigtable 有 3 个主要的组件:一个client library、master server、tablet server。
Master server负责:
- 分配 tablet 给 tablet server:assign tablet to tablet server
- 检测 tablet server 的增删:detect the addition and expiration of tablet server
- 均衡 tablet server的负载:balance tablet server load
- 对 GFS 上的文件进行 GC:garbage collection of files in GFS
- 处理 schema change:handle schema change
Tablet server可以被动态的添加&删除,每个 tablet server 负责:
- 管理tablet
- 负责其加载的 tablet 的读写
- Tablet split
与许多 single-master distributed storage system [17, 21] 相同,client的数据访问不经过 master,而是直接与tablet server交互完成。因为 client 不依赖master来获取tablet的location信息,大部分client从不和master交互,所以master会有较低的负载
Bigtable 会存储多个 table,每个table由多个 tablet 组成,每个 tablet 存储分配给他的行范围的所有数据。初始情况下,每个table 只包含一个 tablet,当table增长的时候,系统会自动分裂 tablet,分裂阈值大约为 100-200MB
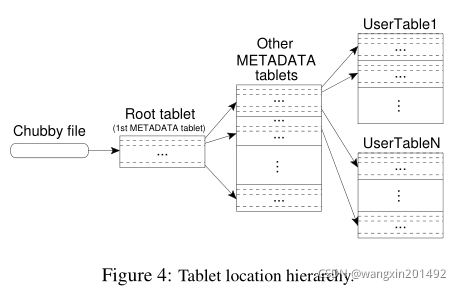
===== 5.1 Tablet Location
Bigtable 采用一个 类似B+-Tree [10] 的三级继承结构(chubby file + root tablet + metadata tablet)。
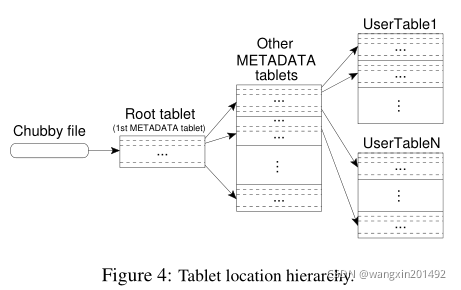
第一级为存储在 Chubby file,其中存储 root tablet 的位置。
Root tablet 中包含 METADATA 表的所有 tablet 存储位置。
每个 METADATA tablet 存储一些用户 tablet 的位置。
Root tablet是 METADATA tablet 中存储的 第一个 tablet,并且永远不会分裂,保证 tablet 的层级结构不超过三级
METADATA 表使用其 row key 来管理 tablet 的位置,row key 由 table的标识符 及 end row 编码完成。每个 METADATA 的 row 大约存储 1KB 的数据,对于 128MB 的 METADATA tablet,三级结构可以存储 2^34个 tablet。
Client library 会缓存 tablet 的位置信息。当client不清楚 tablet信息时,会递归的向上查询。
Tablet 的信息存储在内存上,以避免 GFS 访问开销,在此之上还会在每次加载 tablet 的时候进行tablet预读,进一步降低延迟。
===== 5.2 Tablet Assignment
每个 tablet 同一时间只会被分配到一个 tablet server上,master会跟踪活跃 tablet server 及其上 tablet 的分配情况(包括未分配的tablet)。master通过给 tablet server 发送一个 load请求 来分配 tablet
Bigtable 使用 Chubby 来跟踪 tablet server。Tablet server 启动的时候会持有一个 Chubby 锁,master节点会通过监听 Chubby 锁所在的 dir 来发现 tablet server。Tablet server 会保持 Chubby锁,同时提供服务,失去锁则停止服务。
【master探测tablet server的策略及reassign tablet】
master负责探测 tablet server负载提供某个 tablet 的服务,然后重分配这个 tablet。
发现机制:master定期给每个 tablet server 发送心跳获取其锁的状态。
如果心跳失败或者 tablet server 汇报失去锁,则master会获取这个server对应锁文件的排它锁
如果排它锁能成功获取,那么可以确定 Chubby 时存活的,则是tablet server 发生异常。随后master确认 tablet server 不再提供服务,并会删掉它的 server file,并将其上的 tablet 标记为未分配(unassigned)
此外,为了保证系统不会因为 master 与 Chubby 之间的网络问题存在异常而影响,master 的锁丢失的时候,会kill 自身。
【master的启动流程(探测tablet并分配)】
Master 启动后,首先探测 tablet 的分布情况:
- 抢占锁:在 Chubby上 抢占唯一的 master 锁
- 获取存活的tablet server:Scan server directory,确定存活的 tablet server
- 确定 tablet 分配情况:和 tablet server交互,确定 tablet 的分配情况
- 确定tablet信息:Scan METADATA 表,了解 tablet 信息。并和 step3 中的tablet信息对比,对未分配的 tablet 重分配
这里还需要保证 scan METADATA表前,所有的 METADATA tablet都已经被分配了。为了解决这个问题,如果在 步骤3 中发现 root tablet 未分配,那么会将其直接添加到未分配列表,来保证 root tablet 将被分配。这样 master 就可以每个 METADATA tablet 信息
【tablet 集合变化的场景】
Tablet 集合发生变化有如下场景:tablet被创建或者删除、tablet merge、tablet split
除了 split 外,其他的场景都是由 master 来出发完成的,所以master可以跟踪到这些变化。
Tablet split 被特殊对待,因为它是由 tablet server 触发完成的。Tablet server通过将split 信息 提交给METADATA表的方式来完成提交,当 split 提交以后,tablet server会通知master。
如果通知master失败了,那master会在下次分配这个tablet的时候感知这次split。
===== 5.3 Tablet Serving
tablet的持久化状态存储在 GFS 中,如图5展示
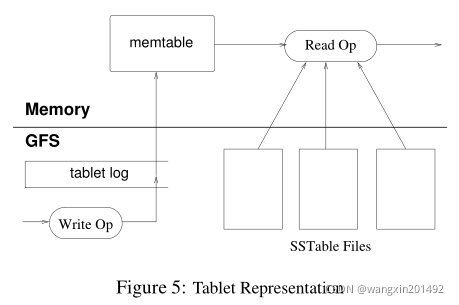
持久化的存储包括commit log & SSTable。最近的写操作被存储在内存的一个有序结构中,称为 memtable;老的写入操作存储在 SSTable 中。
【Recover tablet的方式】从 METADATA表中读取 tablet 的metadata信息(包括SSTable & redo point信息),随后加载 SSTable 到内存并重放 redo log 来重构 memtable。
【写操作流程】1. 确认其格式符合预期,并且具有相关权限;2. 将请求写入 commit log(采用 group commit 的方式 [13, 16] );3. commit的write,写入 memtable
【读操作流程】1. 同样确认格式和权限;2. 将 SSTable & memtable中的数据merge到一起,返回结果(数据按照字典序排列,所以合并相对高效)
===== 5.4 Compactions
【minor compaction】
随着数据的不断写入,memtable持续增长。memtable大小增长到阈值时,该memtable会被frozen,并创建一个新的memtable接收写入,随后frozen的memtable被flush到磁盘,这个过程叫做 minor compaction
Minor compaction有2个目的:1. 减少内存使用;2. 降低recover时需要从 commit log中读取的数据
【merging compaction】
minor compaction会不断创建新的 SSTable,为了避免读操作从多个SSTable中合并update,我们还会限制SSTable的数量,会定期将部分SSTable和memtable合并,生成新的SSTable,这个过程称为 merging compaction
【major compaction】
如果merging compaction时读取所有的SSTable,并重写到一个SSTable中,那么这个过程称为 major compaction
非 major compaction会保留在 old SSTable 中仍然活跃的被删除数据,而 major compaction不会。Major compaction可以回收被删除数据占用的资源,确保被删除数据在系统中及时消失
===== 6. Refinements
===== 6.1 Locality groups
client可以将多个 column family 组合在一起称为 locality group。同 locality group 的数据存放在一起,这样可以避免查询部分数据而需要读取整行的开销
此外,一些可调的参数可以独立作用于 locality group 级别。比如指定某个 locality group 的数据 in-memory
===== 6.2 Compression
Client 可以控制 locality group 的 SSTable 是否进行压缩以及压缩方式。用户指定的压缩方式会应用到每一个 SSTable block
许多用户会使用 two-pass(两遍)自定义压缩方式:第一遍使用 Bentley & MeIlroy [6];第二遍会使用一个快速的压缩算法
尽管对于压缩算法,我们更关注速度而不是空间压缩,但是这种 two-pass 压缩方案效果出奇的好。对网页content的场景,这种压缩算法可以达到10:1的压缩率,而Gzip只有3:1/4:1
===== 6.3 Caching for read performance
为了提升读性能,tablet server使用两级cache:
- Scan Cache 是 high-level cache,缓存SSTable返回给 tablet server的kv对,便于application重复读取相同的数据
- Block Cache 是 low-level cache,缓存GFS中的SSTable block,便于application 读取最近读取过的相邻数据
===== 6.4 Bloom filters
如5.3中提到,一个 read 操作需要读取所有的SSTable 来构建 tablet 的状态,这可能需要多次磁盘访问。
为了降低磁盘访问次数,我们允许 client 对特定的 locality group 的 SSTable 来创建 Bloom filter [7] ,来方便确认某个 SSTable 中是否存在指定的 row-column 对
这也意味着不存在的 row or column 的访问不需要读取磁盘
===== 6.5 Commit-log implementation
如果我们为每一个 tablet 都维护单独的 commit log,会导致:
- 并发写入导致大量的随机写(disk seek)
- 无法利用 group commit 优化
为了解决这个问题,我们为每个 tablet server 维护一个 commit log,在同一个物理文件上混合多个tablet的变更 [18, 20]。
使用一个 log 可以提升普通操作的性能,但是 recovery tablet 逻辑会变得复杂。
recover 一个 tablet,新的 tablet server 需要 reapply这个tablet的修改,这就需要并行读取commit log:每个 tablet server 都需要读取所有的commit log,并应用所需的部分。
为了避免这个问题,我们首先将commit log中的entry 按照<table, row name, log sequence number>来进行排序。这样每个tablet的修改都是有序的,可以通过一次disk seek + sequential read来完成。
为了提高 sort 的效率,我们将 log file 拆分成 64MB 的segment,并并发的在多个 tablet server上进行sort,这个 sort 的流程由 master 来协调完成。
Commit log 写入 GFS 又是会遇到一些性能问题,为了规避这些问题,每个 tablet server 有 2 个commit log写入线程,同一时间只有一个线程活跃,当活跃线程写入变慢的时候,会切换到另外一个线程继续写入。 // 这里并不能解决 GFS 本身慢的问题吧
===== 6.6 Speeding up tablet recovery
Tablet move的过程中为了降低从 commit log 中恢复的时间会进行2次 minor compaction:第一次 compaction 将内存态的数据 flush 到磁盘以后,tablet server 会停止对这个 tablet服务。随后在此进行 minor compaction(通常很快),来将第一次compaction后的数据再次 flush 到磁盘
===== 6.7 Exploiting immutability
除了 SSTable cache 外,其他的很多系统也因为 SSTable 的不变性而简化:
- 比如:不需要访问文件系统就可以读取SSTable,这样并发控制可以很简单的实现
- 因为不变性,清理已被删除的数据就变成了过期 SSTable GC问题,master 将过期的 SSTable 标记为 mark-and-sweep gc [25]
- Tablet 的 split 也变得高效,不需要生成新的SSTable,而让子 tablet 共用 parent 的 SSTable
唯一读写都需要访问的可变数据结构是memtable,这里采用 COW 的方式来降低读冲突,同时也允许读写并发访问。
===== 7-9 略
===== 10 Related Work
V.s. Boxwood project [24]
Boxwood项目和Bigtable的功能重叠,但是其组件提供的都是相对low-leve的服务,项目的总体目标是为了提供高级服务的基础设施
WAN Service problem
最近许多项目解决了提供分布式存储是遇到的广域网问题,这些系统解决的都是 Bigtable 不会出现的问题,例如去中心化控制、拜占庭问题、不可控带宽等
Data model
KV模型使用 B-tree 或者 hash 表示太局限了,KV是有效的构建块,但不应该是唯一的构建块,所以我们提供比 KV 复杂的模型,同时支持稀疏半结构化数据
一些数据库提供商开发可以存储大量数据的并行数据库,比如 Oracle Real Application [27],DB2 Parallel Edition [4],他们提供了完整的关系模型及事务支持
Bigtable locality group实现了与其他系统类似的压缩 & 磁盘读取性能优势,而这些系统都是基于列组织的数据
V.s. C-store
C-Store 和 Bigtable 有许多相似的特性,但是 C-store 提供关系接口,是一个读优化的关系数据库;而 Bigtable 提供低级别的读写接口,提供良好的读写性能
Bigtable 的 load balancer 必须解决一些 share-nothing结构面临的负载和内存均衡问题,但是我们的问题相对简单:
- 不需要考虑数据的多副本问题,可能由view或者索引替代
- 让用户来决定数据在内存还是磁盘
- 没有复杂的query 需要执行或者优化

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)