Hi Azure. 从零开始打造一个语音机器人,跟你的电脑聊聊天。
这篇文章带大家来做一个简单的聊天机器人,碰巧遇到微软Azure招募开发者,可以免费试用人工智能服务,果断申请。先决条件:熟悉 Azure 服务和 Azure 门户(也可以用其它的AI开放平台)拥有 Python 编程经验熟悉API调用序言首先需要了解一下做对话机器人需要涉及到的技术,可以看一下这个流程图。理清思路之后,我们发现涉及到的技术有三种:语音识别、对话式问答、语音合成。简单解释一下这三个技
这篇文章带大家来做一个简单的聊天机器人,碰巧遇到微软Azure招募开发者,可以免费试用人工智能服务,果断申请。
先决条件:
先来看效果:
逐渐逼疯图灵机器人的聊天
序言
首先需要了解一下做对话机器人需要涉及到的技术,可以看一下这个流程图。
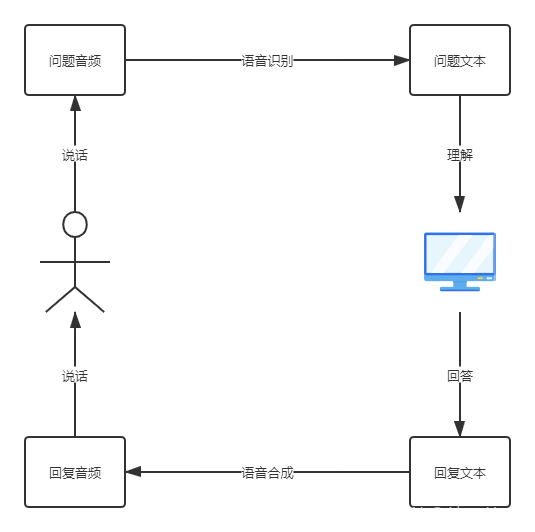
理清思路之后,我们发现涉及到的技术有三种:语音识别、对话式问答、语音合成。
简单解释一下这三个技术:
目前来说最流行的语音算法主要是依赖于深度学习的神经网络算法,深度学习的应用真正让语音识别/合成达到了商用级别。
不过如果要自己做一个语音识别系统,从零开始训练语言模型势必会非常耗时,虽然有很多预训练的模型,但是对于没有深度学习基础的同学来说还是比较困难,所以我们借助Azure的认知服务开源的语音服务API来是想这些功能。
首先需要使用你的 Microsoft 帐户登录到 Azure 门户。

然后创建一个认知服务资源。
创建并且等待部署完成后,在左侧窗格中的“资源管理”下,选择“密钥和终结点” 。

每个订阅有两个密钥;可在应用程序中使用任意一个密钥。
语音识别+语音合成
安装和导入语音 SDK
需要先安装语音 SDK,然后才能执行任何操作。
pip install azure-cognitiveservices-speech
安装语音 SDK 后,将其导入到 Python 项目中。
import azure.cognitiveservices.speech as speechsdk
创建语音识别配置
若要使用语音 SDK 调用语音服务,需要创建 SpeechConfig。 此类包含有关订阅的信息,例如密钥和关联的位置/区域、终结点、主机或授权令牌。
import azure.cognitiveservices.speech as speechsdk
# 需要填入自己的密钥和位置
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region,
speech_recognition_language="zh-cn")
# Creates a recognizer with the given settings
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
从麦克风识别
若要使用设备麦克风识别语音,只需创建 SpeechRecognizer(无需传递 AudioConfig),并传递 speech_config。
import azure.cognitiveservices.speech as speechsdk
def from_mic():
speech_config = speechsdk.SpeechConfig(subscription="<paste-your-speech-key-here>", region="<paste-your-speech-location/region-here>")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("Speak into your microphone.")
result = speech_recognizer.recognize_once_async().get()
print(result.text)
from_mic()
错误处理
前面的示例只从 result.text 获取已识别的文本,但要处理错误和其他响应,需要编写一些代码来处理结果。 以下代码评估 result.reason 属性并:
- 输出识别结果:speechsdk.ResultReason.RecognizedSpeech
- 如果没有识别匹配项,通知用户:speechsdk.ResultReason.NoMatch
- 如果遇到错误,则输出错误消息:speechsdk.ResultReason.Canceled
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
语音合成
同样,我们可以搭建一个语音合成的功能。
def speak(text_words):
speech_config.speech_synthesis_language = "zh-cn"
audio_config = AudioOutputConfig(use_default_speaker=True)
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = speech_synthesizer.speak_text_async(text_words).get()
# Checks result.
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("Speech synthesized to speaker for text [{}]".format(text_words))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))
print("Did you update the subscription info?")
图灵机器人服务构建聊天功能
对话式机器人现在已经成为相对成熟的AI解决方案,机器人以聊天的方式与用户交互,比如edge自带的小冰虚拟女友:

为了实现这种对话式的聊天功能,我们需要借助图灵机器人开放平台,通过图灵机器人开放平台,软硬件产品开发者可快速为自己的产品接入一款具备个性化身份属性特征、满足不同场景多轮对话及上下文对话的人工智能机器人,实现产品的对话式交互。
创建机器人
进入图灵机器人管理控制台后。点击“创建机器人”,按要求填写机器人名称及应用信息,即可完成创建,当前每个账号只能创建5个机器人。

然后在机器人设置中可以定义机器人的一些属性。

API接入
目前图灵机器人API接口可调用聊天对话、语料库、技能三大模块的语料:
- 聊天对话是指平台免费提供的近10亿条公有对话语料,满足用户对话娱乐需求;
- 语料库是指用户在平台上传的私有语料,仅供个人查看使用,帮助用户最便捷的搭建专业领域次的语料。
- 技能服务是指平台打包的26种实用服务技能。涵盖生活、出行、购物等多个领域,一站式满足用户需求。
编码方式
UTF-8(调用图灵API的各个环节的编码方式均为UTF-8)
接口地址
http://openapi.turingapi.com/openapi/api/v2
请求方式
HTTP POST
请求参数
请求参数格式为 json
请求示例:
{
"reqType":0,
"perception": {
"inputText": {
"text": "附近的酒店"
},
"inputImage": {
"url": "imageUrl"
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "信息路"
}
}
},
"userInfo": {
"apiKey": "",
"userId": ""
}
}
参数说明
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| reqType | int | N | - | 输入类型:0-文本(默认)、1-图片、2-音频 |
| perception | - | Y | - | 输入信息 |
| userInfo | - | Y | - | 用户参数 |
perception
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| inputText | - | N | - | 文本信息 |
| inputImage | - | N | - | 图片信息 |
| inputMedia | - | N | - | 音频信息 |
| selfInfo | - | N | - | 客户端属性 |
注意:输入参数必须包含inputText或inputImage或inputMedia!
inputText
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| text | String | Y | 1-128字符 | 直接输入文本 |
inputImage
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| url | String | Y | 图片地址 |
inputMedia
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| url | String | Y | 音频地址 |
selfInfo
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| location | - | N | - | 地理位置信息 |
location
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| city | String | Y | - | 所在城市 |
| province | String | N | - | 省份 |
| street | String | N | - | 街道 |
userInfo
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| apiKey | String | Y | 32位 | 机器人标识 |
| userId | String | Y | 长度小于等于32位 | 用户唯一标识 |
| groupId | String | N | 长度小于等于64位 | 群聊唯一标识 |
| userIdName | String | N | 长度小于等于64位 | 群内用户昵称 |
输出示例:
{
"intent": {
"code": 10005,
"intentName": "",
"actionName": "",
"parameters": {
"nearby_place": "酒店"
}
},
"results": [
{
"groupType": 1,
"resultType": "url",
"values": {
"url": "http://m.elong.com/hotel/0101/nlist/#indate=2016-12-10&outdate=2016-12-11&keywords=%E4%BF%A1%E6%81%AF%E8%B7%AF"
}
},
{
"groupType": 1,
"resultType": "text",
"values": {
"text": "亲,已帮你找到相关酒店信息"
}
}
]
}
参数说明
| 参数 | 类型 | 是否必须 | 取值范围 | 说明 |
|---|---|---|---|---|
| intent | - | Y | - | 请求意图 |
| results | - | N | - | 输出结果集 |
intent
| 参数 | 类型 | 是否包含 | 取值范围 | 说明 |
|---|---|---|---|---|
| code | int | Y | - | 输出功能code |
| intentName | String | N | - | 意图名称 |
| actionName | String | N | - | 意图动作名称 |
| parameters | Map | N | - | 功能相关参数 |
results
| 参数 | 类型 | 是否包含 | 取值范围 | 说明 |
|---|---|---|---|---|
| resultType | String | Y | 文本(text);连接(url);音频(voice);视频(video);图片(image);图文(news) | 输出类型 |
| values | - | Y | - | 输出值 |
| groupType | int | Y | - | ‘组’编号:0为独立输出,大于0时可能包含同组相关内容 (如:音频与文本为一组时说明内容一致) |
Code
def chat(text_words=""):
api_key = "1dde879fa**********1ee88269f3852"
api_url = "http://openapi.tuling123.com/openapi/api/v2"
headers = {"Content-Type": "application/json;charset=UTF-8"}
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "天津",
"province": "天津",
"street": "天津科技大学"
}
}
},
"userInfo": {
"apiKey": api_key,
"userId": "Alex"
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
汇总
最后,把语音识别、语音合成的代码放在一起,再加上一个简单的流程控制,所有的代码加起来不超过一百行,一个能跟你聊天的机器人就完成了。
import json
import requests
import azure.cognitiveservices.speech as speechsdk
from azure.cognitiveservices.speech.audio import AudioOutputConfig
speech_key, service_region = "6d5afa148**********5d8801db8e408", "chinanorth2"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region,
speech_recognition_language="zh-cn")
def record():
# Creates a recognizer with the given settings
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("Say something...")
result = speech_recognizer.recognize_once()
# Checks result.
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
return result.text
def chat(text_words=""):
api_key = "1dde879f**********f1ee88269f3852"
api_url = "http://openapi.tuling123.com/openapi/api/v2"
headers = {"Content-Type": "application/json;charset=UTF-8"}
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "天津",
"province": "天津",
"street": "天津科技大学"
}
}
},
"userInfo": {
"apiKey": api_key,
"userId": "Alex"
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
def speak(text_words):
speech_config.speech_synthesis_language = "zh-cn"
audio_config = AudioOutputConfig(use_default_speaker=True)
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = speech_synthesizer.speak_text_async(text_words).get()
# Checks result.
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("Speech synthesized to speaker for text [{}]".format(text_words))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))
print("Did you update the subscription info?")
if __name__ == '__main__':
while True:
text = record()
if "退出" in text:
break
res = chat(text)
speak(res)
代码地址:https://github.com/Matrix-King-Studio/IntelligentVoiceRobot
演示视频:https://www.bilibili.com/video/BV1BU4y1F7s7/

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 14
14 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)