【自然语言处理】论述自然语言处理的技术范畴
文章目录论述自然语言处理的技术范畴(基本全貌) 一、前言二、主要技术范畴1、语音合成(Speech Synthesis)2、语音识别(Speech Recognition)3、中文自动分词4、词性标注5、句法分析7、文本分类7、文本挖掘8、信息抽取9、 问答系统10、机器翻译11、文本情感分析12、自动摘要13、文字蕴涵三、自然语言处理的难点论述自然语言处理的技术范畴(基本全貌)一、前言&
文章目录
论述自然语言处理的技术范畴
一、前言
本片博文主要是介绍说明自然语言处理的全貌,一些主要的技术范畴。
自然语言处理(NLP)这个是一个很大的话题,,它是一个人机交互的一个过程,它涉及的学科比较广泛譬如如下所示:
1:语言学
2:计算机科学(提供模型表示,算法设计,计算机实现):
3:当然还有数学以此来提供数学模型
4:心理学(人类言语心理模型和理论)
5:哲学(提供人类思维和语言的更高层次理论)
6:统计学(提供样本数据的预测统计技术)
7:电子工程(信息论基础和语言型号处理技术)
8:生物学(人类言语行为机制理论)
总之那涉及的学科范围广泛。不言而喻在自然语言处理研究工作中是十分艰难的,博主现在也只是学习它的一个小小的分支罢了,看到此篇博文的小伙伴希望能抛出你们的建议和意见,要是如此博主甚是感激,开心呀!!!
二、主要技术范畴
1、语音合成(Speech Synthesis)
所谓的语音合成就是指用人工的方式产生人类语音。语音合成器,就是利用计算机系统作用在语音合成上。而语音合成器可以用软/硬件实现。
文字转语音(Text-To-Speech,TTS)系统则是将一般语言的文字转换为语音,其他系统可以描绘语言符号的表示方式,就像音标转换至语音一样。
语音合成器的质量: 通常取决于人声的相似度及语义是否能被了解。举个例子,对于个瞎子看不到文字,只能通过语音合成器很清楚的听到文字转换成语音的效果。
语音合成的应用包括智能仪表、智能玩具、电子地图、电子导游、电子词典等。
总结:用大白话来讲使用语音合成器可以实现文字转换为语音,音标转化为语音,并且效果如同非瞎看文字,瞎子听语音同一个效果为最好。
2、语音识别(Speech Recognition)
语音识别(Speech Recognition)技术也被称为语音转文本识别(Speech to Text,STT),目标是让计算机自动将人类的语音内容转换为相应的文字。
语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如,语音到语音的翻译。
总结:用大白话来讲语音识别就是借助计算机工具来识别人类说的话转化为可视化的东东(也就是文字啦)。
3、中文自动分词
中文自动分词指的是----->使用计算机----->自动对中文文本----->进行词语的切分。就像英文那样使得中文句子中的词之间有空格以标识。中文自动分词也是中文自然语言处理中的 最底层的一个环节。
现有的方法:
⊚ 基于词典的匹配:前向最大匹配、后向最大匹配。
⊚ 基于字的标注:最大熵模型、条件随机场模型、感知器模型。
⊚ 其他方法:与词性标注结合、与句法分析结合。
例如以下是博主写的一个简单的测试
代码
"""
author:jjk
datetime:2018/11/1
coding:utf-8
project name:Pycharm_workstation
Program function: 中文分词
结巴分词
"""
import jieba # 导入结巴分词包
import jieba.posseg as pseg
import time # 时间
time_Start = time.time()
#f=open("t_with_splitter.txt","r")#读取文本
#string=f.read().decode("utf-8")
string = '中文自动分词指的是使用计算机自动对中文文本进行词语的切分,' + \
'即像英文那样使得中文句子中的词之间有空格以标识。' + \
'中文自动分词被认为是中文自然语言处理中的一个最基本的环节'
words = pseg.cut(string) # 进行分词
result = "" #记录最终结果的变量
for w in words:
result += str(w.word) + "/" + str(w.flag) # 加词性标注
print(result) # 输出结果
f = open("result.txt","w") #将结果保存到另一个文档中
f.write(result)
f.close()
time_Stop = time.time()
print("分词及词性标注完成,耗时:"+str(time_Stop-time_Start)+"秒。")# 输出结果
结果

4、词性标注
词性标注(Part-of-Speech tagging 或POS tagging) 又称词类标注或者简称标注,是指在词性标记集已确定,并且词典中每个词都有确定词性的基础上,将一个输入词串转换成相应词性标记串的过程。如上 3、中文自动分词 中举的例子的结果所示。
在汉语中,因为汉语词汇词性多变的情况比较少见,大多词语只有一个词性,或者出现次最高的词性远远高于第二位的词性,相对比较简单。同时,它也受到一些条件约束。比如:兼类词在具体语境中的词性判定问题、未登录词即新词词性问题、兼类词问题等。
词性标注方法包括概率方法、隐马尔可夫模型的词性标注方法、机器学习规则的方法等。
5、句法分析
- 句法分析
句法分析(Parsing)就是指对句子中的词语语法功能进行分析。比如“欢迎大家使用演示平台”就可以表示为"欢迎\VV 大家\PN 使用\VV 演示\NN 平台\NN"。
句法分析在中文信息处理中的主要应用包括机器翻译、命名实体识别等。
- 自然语言生成
自然语言生成研究使计算机具有人一样的表达和写作功能,即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,自动生成一段高质量的自然语言文本。自然语言处理包括自然语言理解和自然语言生成。自然语言生成是人工智能和计算语言学的分支,相应的语言生成系统是基于语言信息处理的计算机模型,其工作过程与自然语言分析相反,从抽象的概念层次开始,通过选择并执行一定的语义和语法规则来生成文本。
6、文本分类
文本分类用计算机对文本集按照一定的分类器模型进行自动分类标记。文本分类的总体过程如下(引用自 NLPIR 汉语分词系统)。
(1) 预处理:将原始语料格式化为同一格式,便于后续的统一处理。
(2) 索引:将文档分解为基本处理单元,同时降低后续处理的开销。
(3) 统计:词频统计,项(单词、概念)与分类的相关概率。
(4) 特征抽取:从文档中抽取出反映文档主题的特征。
(5) 分类器:分类器的训练。
(6) 评价:分类器的测试结果分析。
文本分类常用算法包括决策树、朴素贝叶斯、神经网络、支持向量机、线性最小平方拟合、KNN、遗传算法、最大熵等,广泛应用于垃圾过滤、新闻分类、词性标注等。
7、文本挖掘
文本挖掘一般指在文本处理过程中产生高质量的信息。高质量的信息通常通过分类和预测来产生,如模式识别。文本挖掘通常涉及输入文本的处理过程,产生结构化数据,并最终评价和解释输出。
例如博主的这篇文章中对微信朋友圈个性签名生成词云的分析,就是一个文本挖掘。
典型的文本挖掘方法包括文本分类、文本聚类、信息抽取、概念/实体挖掘、情感分析和观点分析等。
8、信息抽取
信息抽取(Information Extraction)是从大量文字数据中自动为访问数据库而抽取特定消息的技术 。
简单点来说从给定文本中抽取重要的信息,比如时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等。大白话就是,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什么结果,涉及实体识别、时间抽取、因果关系抽取等关键技术。
9、 问答系统
问答系统(Question Answering)是当下自然语言处理研究的热点,也是未来自然语言处理的重点问题。从问答系统的外部行为来看,其与目前主流资讯检索技术有两点不同:首先是查询方式为完整而口语化的问句,再者是其回传的为高精准度网页结果或明确的答案字串。
至此不知道小伙伴你有没有想到聊天机器人呀!!!
10、机器翻译
机器翻译(Machine Translation,经常简写为MT)属于计算语言学的范畴,是计算机程序将文字或演说从一种自然语言翻译成另一种自然语言 。简单来说,机器翻译是通过将一个自然语言的字辞取代成另一个语言的字辞来实现的。借由使用语料库的技术,可达成更加复杂的自动翻译,包阔可更佳地处理不同的文法结构、辞汇辨识、惯用语的对应等。
这里用博主自己的大白话的理解就是:将一种语言(比如中文) 翻译成
11、文本情感分析
文本情感分析(也称为意见挖掘)是指用自然语言处理、文本挖掘及计算机语言学等方法来识别和提取原素材中的主观信息 。通常来说,情感分析的目的是为了找出说话者/作者在某些话题上或者针对一个文本两极的观点的态度。这个态度或许是他的个人判断或评估,或许是他当时的情感状态(也就是说,作者在做出这个言论时的情绪状态),或是作者有意向的情感交流(就是作者想要读者所体验的情绪)等。
总结:就是作者规定一些代表文本的态度词,然后使用可视化进行表现出来从而达到客户情感交流。
12、自动摘要
所谓自动摘要就是利用计算机自动地从原始文献中提取文摘,文摘是全面准确地反映某一文献中心内容的连贯短文。常用方法是自动摘要将文本作为句子的线性序列,将句子视为词的线性序列。
自动摘要可以按照技术类型和信息提取分类。
⊚ 技术应用类型:自动提取给定文章的摘要信息,自动计算文章中词的权重,自动计算
文章中句子的权重。
⊚ 信息提取:单篇文章的摘要自动提取,大规模文档的摘要自动提取,基于分类的摘要
自动提取。
举例如下所示:
"""
author:jjk
datetime:2018/10/15
coding:utf-8
project name:Pycharm_workstation
Program function: 查找关键词
思路:
1:加载已有的文档数据集
2:加载停用词表
3:对数据集中的文档进行分词
4:根据停用词表,过来干扰词
5:根据数据集训练算法
"""
import math
import jieba
import jieba.posseg as psg
from gensim import corpora, models
from jieba import analyse
import functools
import numpy as np
# 停用词加载方法
def get_stopword_list():
stop_word_path = './data/stopword.txt'
# 遍历txt文档,剔除''
stopword_list = [sw.replace('\n', '') for sw in open(stop_word_path, encoding='utf-8').readlines()]
return stopword_list
# 分词方法,调用结巴接口
# pos是判断是否采用词性标注的参数
def seg_to_list(sentence, pos=False):
if not pos:
# 不进行词性标注的分词方法
seg_list = jieba.cut(sentence)
else:
# 进行词性标注的分词方法
seg_list = psg.cut(sentence)
return seg_list
# 去除干扰词,根据pos判断是否过滤除名词外的其他词性,再判断词是否在停用词表中,长度是否大于等于2等。
def word_filter(seg_list, pos=False):
stopword_list = get_stopword_list()
filter_list = []
# 根据pos参数选择是否词性过滤
# 不进行词性过滤,则将词性都标记为n,表示全部保留
for seg in seg_list:
if not pos:
word = seg
flag = 'n'
else:
word = seg.word
flag = seg.flag
if not flag.startswith('n'):
continue
# 过滤高停用词表中的词,以及长度为<2的词
if not word in stopword_list and len(word) > 1:
filter_list.append(word)
return filter_list
# 数据加载
# corpus.txt为数据集
def load_data(pos=False, corpus_path='./data/corpus.txt'):
# 调用上面 方式对数据集进行处理,处理之后的数据集仅保留非干扰词
doc_list = []
for line in open(corpus_path, 'rb'):
content = line.strip()
seg_list = seg_to_list(content, pos)
filter_list = word_filter(seg_list, pos)
doc_list.append(filter_list)
return doc_list
# idf值统计方法
def train_idf(doc_list):
idf_dic = {}
# 总文档数
tt_count = len(doc_list)
# 每个词出现的文档数
for doc in doc_list:
for word in set(doc):
idf_dic[word] = idf_dic.get(word, 0.0) + 1.0
# 按公式转换为idf值,分母加1进行平滑处理
for k, v in idf_dic.items():
idf_dic[k] = math.log(tt_count / (1.0 + v))
# 对于没有在字典中的词,默认其尽在一个文档出现,得到默认idf值
default_idf = math.log(tt_count / (1.0))
return idf_dic, default_idf
# topK
# cmp()函数是为了输出top关键词时,先按照关键词的计算分值排序,在得分相同时,根据关键词进行排序时
def cmp(e1, e2):
# import numpy as np
res = np.sign(e1[1] - e2[1])
if res != 0:
return res
else:
a = e1[0] + e2[0]
b = e2[0] + e1[0]
if a > b:
return 1
elif a == b:
return 0
else:
return -1
# TF-IDF类
class TfIdf(object):
# 训练好的idf字典,默认idf值,处理后的待提取文本,关键词数量
def __init__(self, idf_dic, default_idf, word_list, keyword_num):
self.word_list = word_list
self.idf_dic, self.default_idf = idf_dic, default_idf
self.tf_dic = self.get_tf_dic()
self.keyword_num = keyword_num
# 统计tf值
def get_tf_dic(self):
tf_dic = {}
for word in self.word_list:
tf_dic[word] = tf_dic.get(word, 0.0) + 1.0
tt_count = len(self.word_list)
for k, v in tf_dic.items():
tf_dic[k] = float(v) / tt_count
return tf_dic
# 按公式计算tf-idf
def get_tfidf(self):
tfidf_dic = {}
for word in self.word_list:
idf = self.idf_dic.get(word, self.default_idf)
tf = self.tf_dic.get(word, 0)
tfidf = tf * idf
tfidf_dic[word] = tfidf
# 根据tf-idf排序,取排名前keyword_num的词作为关键词
for k, v in sorted(tfidf_dic.items(), key=functools.cmp_to_key(cmp), reverse=True)[:self.keyword_num]:
print(k + "/", end='')
print()
# 主题模型
class TopicModel(object):
#
def __init__(self, doc_list, keyword_num, model="LSI", num_topics=4):
# 使用gensim接口,将文本转为向量化表示
self.dictionary = corpora.Dictionary(doc_list)
# 使用BOW模型向量化
corpus = [self.dictionary.doc2bow(doc) for doc in doc_list]
# 对每个词,根据tf-idf进行加权,得到加权后的向量表示
self.tfidf_model = models.TfidfModel(corpus)
self.corpus_tfidf = self.tfidf_model[corpus]
self.keyword_num = keyword_num
self.num_topics = num_topics
# 选择加载的模型
if model == 'LSI':
self.model = self.train_lsi()
else:
self.model = self.train_lda()
# 得到数据集的主题-词分布
word_dic = self.word_dictionary(doc_list)
self.wordtopic_dic = self.get_wordtopic(word_dic)
def train_lsi(self):
lsi = models.LsiModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)
return lsi
def train_lda(self):
lda = models.LdaModel(self.corpus_tfidf, id2word=self.dictionary, num_topics=self.num_topics)
return lda
def get_wordtopic(self, word_dic):
wordtopic_dic = {}
for word in word_dic:
single_list = [word]
wordcorpus = self.tfidf_model[self.dictionary.doc2bow(single_list)]
wordtopic = self.model[wordcorpus]
wordtopic_dic[word] = wordtopic
return wordtopic_dic
# 词空间构建方法和向量化方法,在没有gensim接口时的一般处理方法
def word_dictionary(self, doc_list):
dictionary = []
for doc in doc_list:
dictionary.extend(doc)
dictionary = list(set(dictionary))
return dictionary
def doc2bowvec(self, word_list):
vec_list = [1 if word in word_list else 0 for word in self.dictionary]
return vec_list
# 计算词的分布和文档的分布的相似度,取相似度最高的keyword_num个词作为关键词
def get_simword(self, word_list):
sentcorpus = self.tfidf_model[self.dictionary.doc2bow(word_list)]
senttopic = self.model[sentcorpus]
# 余弦相似度计算
def calsim(l1, l2):
a, b, c = 0.0, 0.0, 0.0
for t1, t2 in zip(l1, l2):
x1 = t1[1]
x2 = t2[1]
a += x1 * x1
b += x1 * x1
c += x2 * x2
sim = a / math.sqrt(b * c) if not (b * c) == 0.0 else 0.0
return sim
# 计算输入文本和每个词的主题分布相似度
sim_dic = {}
for k, v in self.wordtopic_dic.items():
if k not in word_list:
continue
sim = calsim(v, senttopic)
sim_dic[k] = sim
for k, v in sorted(sim_dic.items(), key=functools.cmp_to_key(cmp), reverse=True)[:self.keyword_num]:
print(k + "/ ", end='')
print()
def tfidf_extract(word_list, pos=False, keyword_num=10):
doc_list = load_data(pos)
idf_dic, default_idf = train_idf(doc_list)
tfidf_model = TfIdf(idf_dic, default_idf, word_list, keyword_num)
tfidf_model.get_tfidf()
def textrank_extract(text, pos=False, keyword_num=10):
textrank = analyse.textrank
keywords = textrank(text, keyword_num)
# 输出抽取出的关键词
for keyword in keywords:
print(keyword + "/")
# print()
def topic_extract(word_list, model, pos=False, keyword_num=10):
doc_list = load_data(pos)
topic_model = TopicModel(doc_list, keyword_num, model=model)
topic_model.get_simword(word_list)
if __name__ == '__main__':
# 获取测试文本
text1 = 'test.txt'
text = open(text1, encoding='utf-8').read()
print(text)
pos = True
seg_list = seg_to_list(text, pos)
filter_list = word_filter(seg_list, pos)
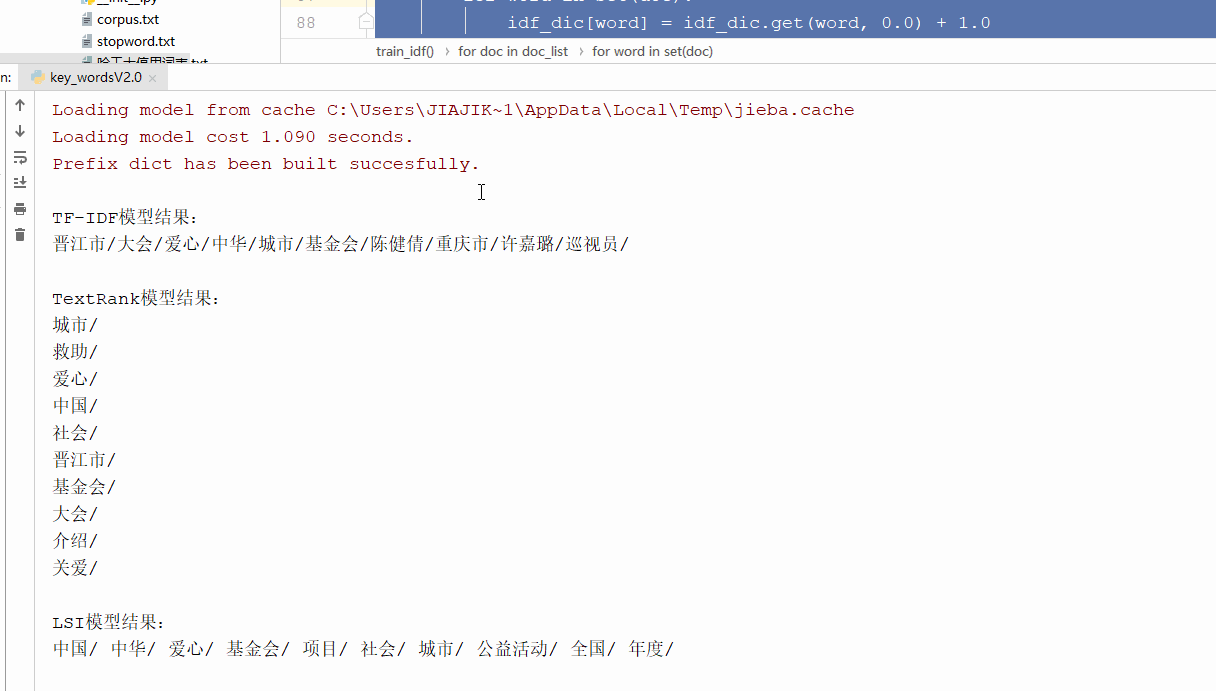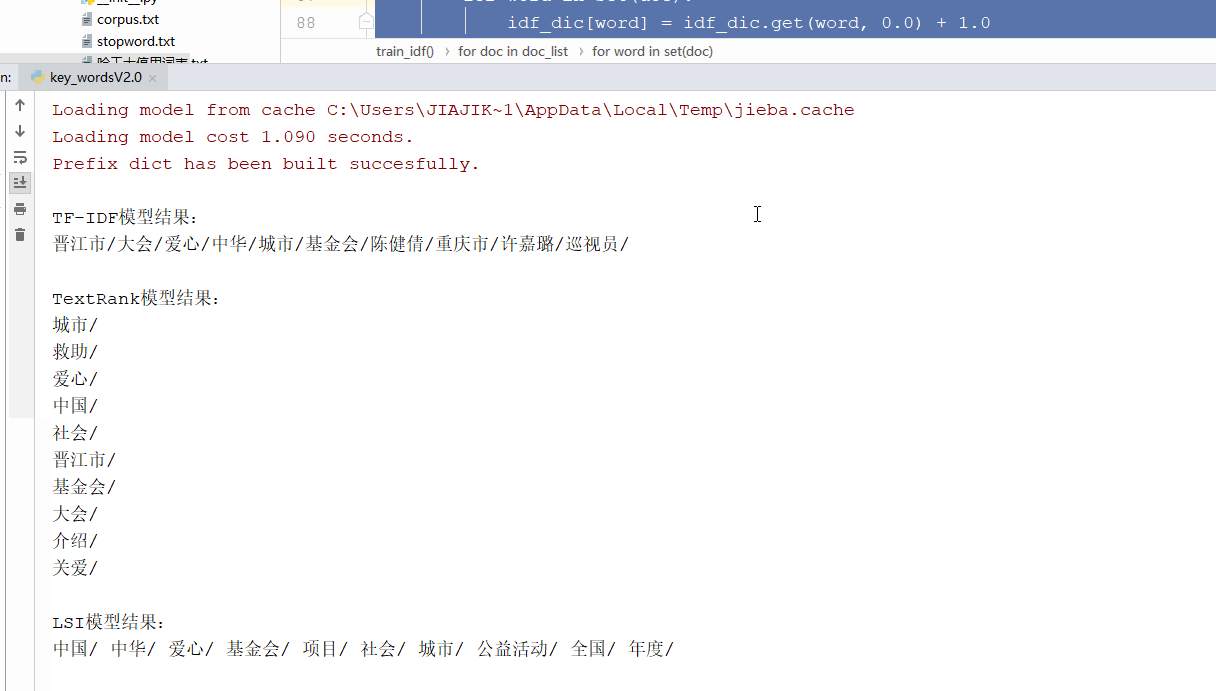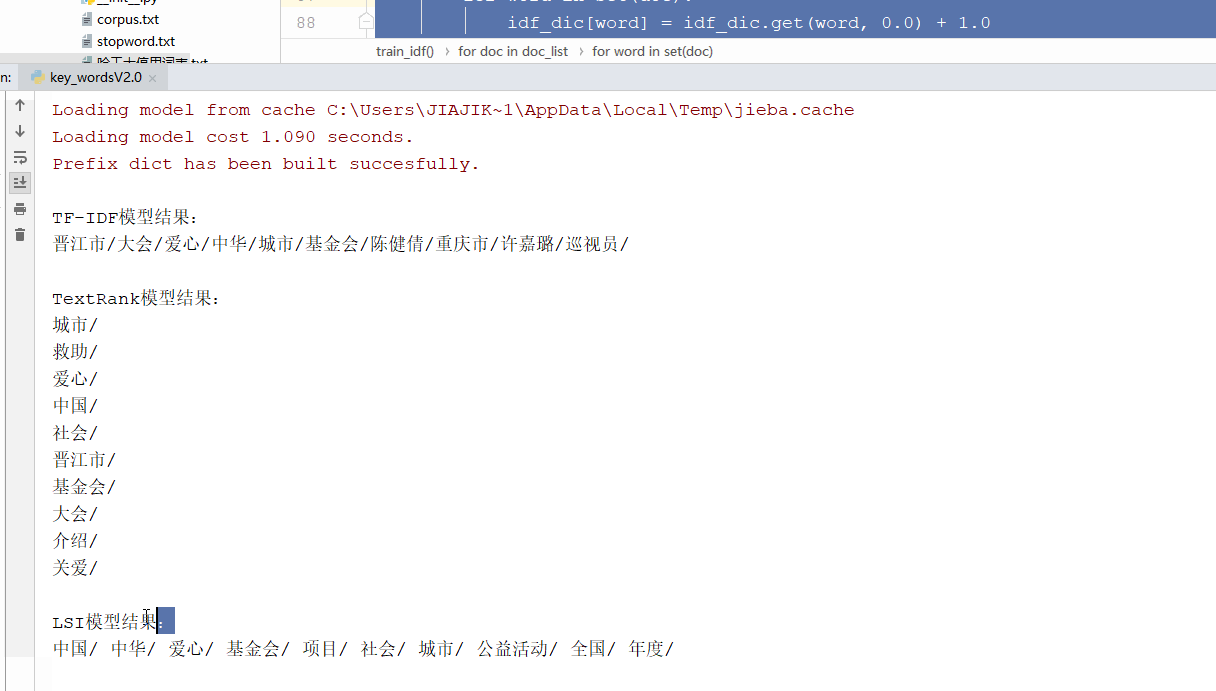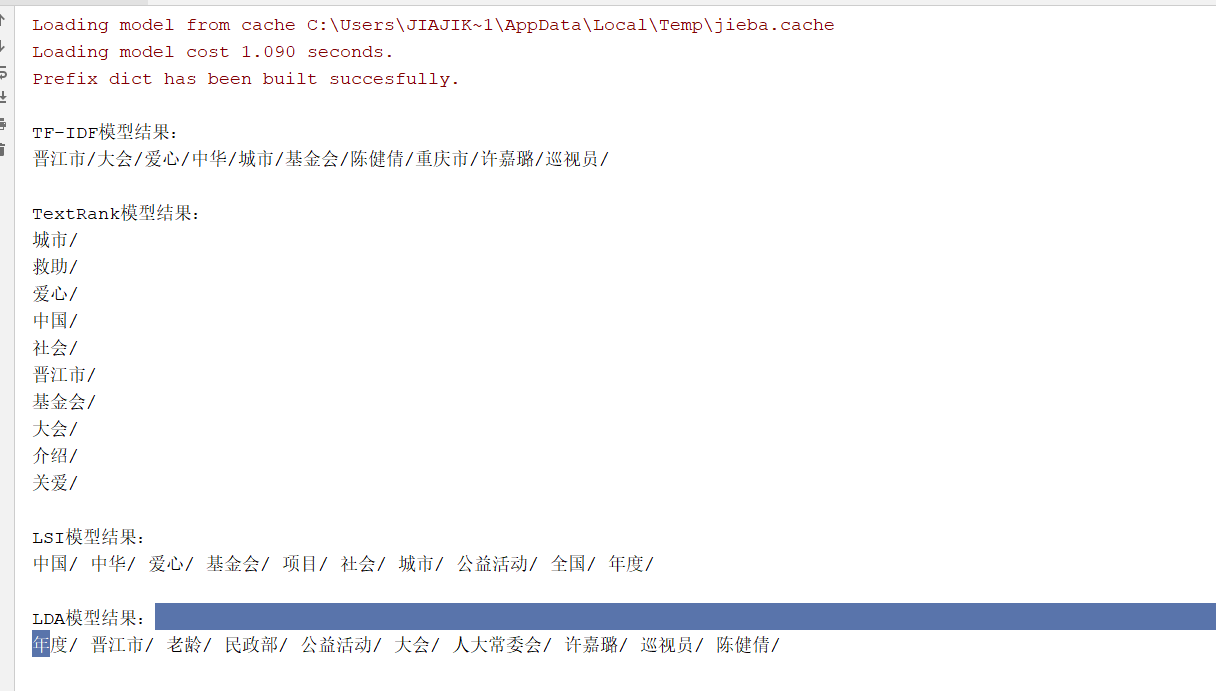
print('\nTF-IDF模型结果:')
tfidf_extract(filter_list)
print('\nTextRank模型结果:')
textrank_extract(text)
print('\nLSI模型结果:')
topic_extract(filter_list, 'LSI', pos)
print('\nLDA模型结果:')
topic_extract(filter_list, 'LDA', pos)
结果
13、文字蕴涵
文字蕴涵(Textual Entailment,TE)
文字蕴涵在自然语言处理中主要指一个文字片段之间的定向关系。
⊚ 正向蕴涵
文本T:日本时间2011 年3 日11 日,日本宫城县发生里氏震级9.0 震,造成死伤失踪约3 万多人。
假设H:日本时间2011 年3 日11 日,日本宫城县发生里氏震级9.0 强震。
⊚ 矛盾蕴涵
文本T:张学友在1961 年7 月10 日,生于香港,祖籍天津。
假设H:张学友生于1960 年。
⊚ 独立蕴涵
文本T:黎姿与“残障富豪”马廷强结婚。
假设H:马廷强为香港“东方报业集团”创办人之一马惜如之子。
三、自然语言处理的难点
1、语言环境复杂
自然语言处理的语言环境较为复杂,以命名实体识别进行分析,对于同一个汉字某些情况下可以看作实体处理,某些情况则不能看作实体。
例如,天龙八部中的“竹剑”小姐姐 在有些情况下可能就是指的是竹子做得剑。还有“湖北” 有可能指定是地点 “湖北”,也有可能指定是“湖的北边”。可见字自然语言处理过程中语言环境(根据上下文才能究其表达的意思)的复杂。
2、文本结构形式多样
文本内部结构形式多样。还是以自然语言处理中的命名实体识别任务为例子,例如:
⊚ 人名,人名由姓和名构成。其中姓氏包括单姓和复姓(如赵、钱、孙、李、慕容、东方、西门等),名由若干个汉字组成。姓氏的用字范围相对有限,比较容易识别。然而名就比较灵活,既可以用名、字、号表示,也可以使用职务名和用典。比如:“李白、李十二、李翰林、李供奉、李拾遗、李太白、青莲居士,谪仙人”都是同一个人。
⊚ 地名,一般由若干个字组成地名,可以为作为后缀关键字或者别名,都是指代一个地方。比如:“成都、蓉城、锦城、芙蓉城、锦官城、天府之国”,其中“蓉城、锦城、芙蓉城、锦官城、天府之国”为别名。除了全称的名称,还有地理位置代表地名的。比如:“河南、河南省、豫”都是指的一个省份,其中“豫”是简称。
⊚ 组织机构名,组织机构命名方式比较复杂,有些是修饰性的命名,有些表示历史典故,有些表示地理方位,有些表示地名,有些表示风俗习惯和关键字等。例如:组织名“广州恒大淘宝足球俱乐部”中,“广州”表示地名的成分,“恒大”“淘宝”表示公司名称成分,“足球”是一项体育赛事成分,“俱乐部”是关键字的成分。比如:“四川大学附属中学”(四川省成都市第十二中学)中包括另一个机构名“四川大学”。机构名还可以以简称形式表示,比如:“四川大学附属中学”简称“川大附中”,“成都信息工程大学”简称“成信大"。
3、边界识别限制
在自然语言处理任务中,边界识别最广泛应用于命名识别当中。边界识别可以分解为两大任务:如何去识别实体的边界;如何去判定实体的类别(诸如人名、地名、机构名)。中文命名实体识别要比英文命名实体识别更为复杂,一是受中文自身语言特性的限制,不同于英语文本中词间有空格界定;二是英文中的实体一般首字母大写容易区分,例如:‘Jobs wasadopted at birth in San Francisco,and raised in a hotbed of counterculture’ 中,人名乔布斯Jobs的首字母大写,地名旧金山San Francisco 的首字母也是大写,而中文不具备这样的特征。
4、词义消岐
- 词义消歧
词义消歧是一个自然语言处理和本体论的开放问题。歧义与消歧是自然语言理解中最核心的问题,在词义、句义、篇章含义层次都会出现语言根据上下文语义而产生不同含义的现象。消歧即指根据上下文确定对象语义的过程,词义消歧即在词语层次上的语义消歧。语义消歧/词义消歧是自然语言处理任务的一个核心与难点,影响了几乎所有任务的性能,比如搜索引擎、意见挖掘、文本理解与产生、推理等。 - 词性标注和词义消岐
词性标注与词义消歧是相互关联的两个问题,在语言使用者身上它们往往同时能得到满足。但是目前的计算机系统一般并不能让二者共用参数并同时输出。语义理解包括分词、词性标注、词义消歧、句法解析、语义解析等。它们并不是前馈的,是相互依赖并存在反馈的。词性标注与语义消歧都要依赖上下文来标注,但是词性标注比语义消歧处理起来要更简单,最终结果也往往较好。主要原因是词性标注的标注集合是确定的,而语义消歧并没有,并且量级上词性标注要大得多;词性标注的上下文依赖比语义消歧要短。
举例说明
许多字词不单只有一个意思,因而我们必须选出使句意最为通顺的解释。看下面歧义的句子,词义消歧就是要分析出特定上下文的词被赋予的到底是哪个意思。
(1) 川大学生上网成瘾如患绝症。歧义在于“川大学生”——四川大学的学生;四川的大学生。
(2) 两代教授,人格不同。歧义:“两代”——两位代理教授;两个时代的教授。
(3) 被控私分国有资产,专家总经理成了被告人。歧义:“专家总经理”——专家和总经理;有专家身份的总经理。
(4) 新生市场苦熬淡季。歧义:“新生”——新学生的市场;新产生的市场。
(5) 朝鲜十年走近国际社会一步。歧义:“十年走近国际社会一步”——每十年就向国际社会走近一步;最近十年间向国际社会走近了一步
(6) 新汽车牌照。歧义:“新”——新的汽车;新的牌照。
(7) 咬死了猎人的狗。歧义:——猎人的狗被咬死了;把猎人咬死了的那条狗。
(8) 菜不热了。歧义:“热”——指菜凉了;指菜不加热了。
(9) 还欠款四万元。歧义:“还”——读huai;读hai。
(10) 北京人多。歧义:——北京/人多;北京人/多。
5、指代消解
-
定义
指代消解(Anaphora Resolution)是自然语言处理的重要内容,在信息抽取时就用到了指代消解技术 -
中文的三种典型指代
(1) 人称代词:李明怕高妈妈一个人呆在家里寂寞,【他】便将家里的电视搬了过来。
(2) 指示代词:很多人都想创造一个美好的世界留给孩子,【这】可以理解,但不完全正确。
(3) 有定描述:贸易制裁似乎成了美国政府在对华关系中惯用的大棒。然而,这【大棒】果真如美国政府所希望的那样灵验吗? -
典型指代消解
⊚ 显性代词消解
所谓显性代词消解,就是指在篇章中确定显性代词指向哪个名词短语的问题,代词称为指示语或照应语(Anaphor),其所指向的名词短语一般被称为先行语(Antecedent)。根据二者之间的先后位置,可分为回指(Anaphora)与预指(Cataphora),其中:如果先行语出现在指示语之前,则称为回指,反之则称为预指。
⊚ 零代词消解
所谓零代词消解,是代词消解中针对零指代(Zero Anaphora)现象的一类特殊的消解。
⊚ 共指消解
所谓共指消解,是将篇章中指向同一现实世界客观实体(Entity)的词语划分到同一个等价集的过程,其中被划分的词语称为表述或指称语(Mention),形成的等价集称为共指链(Coreference Chain)。在共指消解中,指称语包含普通名词、专有名词和代词,因此可以将显性代词消解看作共指消解针对代词的子问题。共指消解与显性代词消解不同,它更关注在指称语集合上进行的等价划分,评测方法与显性代词消解也不尽相同,通常使用 MUC、 B-CUBED、CEAF 和 BLANC 等评价方法。
指代消解的研究方法大致可以分为基于启发式规则的、基于统计的和基于深度学习的方法。目前看来,基于有监督统计机器学习的消解算法仍然是主流算法。 -
典型例子
指代消解是解决“谁对谁做了什么”,处理如上所述的自然语言的问题,下面看看例子:
(1) 美国政府表示仍然支持强势美元,但这到底只是嘴上说说还是要采取果断措施,经济学家对此的看法是否定的。
(2) 今天老师又在班会上表扬了自己,但是我觉得还需要继续努力。
(3) 三妹拉着葛姐的手说,她老家在偏远的山区,因为和家里赌气才跑到北京打工的,接着她又哭泣起自己的遭遇来。
(4) 当他把证书发给小钱时,他对他笑了。
(5) 小明和肖华去公园玩,他摔了一跤,他急忙把他扶起来。
(6) 星期天, 小雨和小英到田老师家补习功课,她一早就打电话给她约好在红旗饭店吃早餐。
四、展望自然语言处理
关于在2017年第三届中国人工智能大会上来自哈尔滨工业大学的刘挺教授对自然语言处理的一个发展趋势的一个总结归纳。
归纳链接:http://www.sohu.com/a/163742617_610522

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)